M3imic: Learning a Versatile Whole-Body Controller for Multimodal Motion Mimicking
Pith reviewed 2026-06-28 06:07 UTC · model grok-4.3
The pith
A single reinforcement learning policy controls a humanoid to mimic motions from joint angles, human poses, or end-effector targets without retraining per modality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
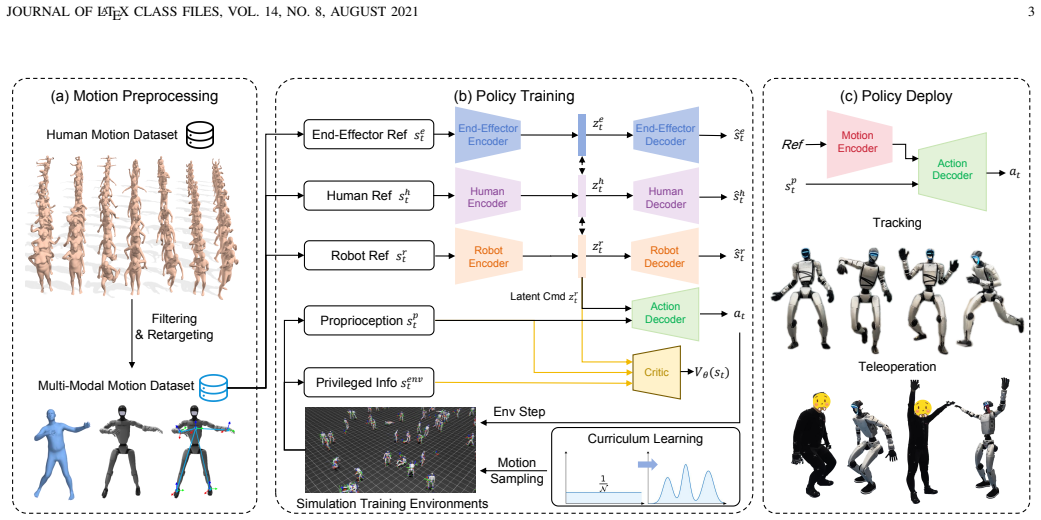
M3imic unifies robot joint angles, human pose trajectories, and end-effector poses by passing each through its own encoder to produce a common latent vector; a single policy trained via large-scale reinforcement learning in simulation then tracks any of these references and transfers to the Unitree G1 robot, reaching a peak success rate of 98.42 percent on an unseen test set without any modality-specific retraining.
What carries the argument
Modality-specific encoders that convert heterogeneous motion references into one shared latent space so that a single downstream policy can act on all of them.
If this is right
- A deployed controller can accept locomotion commands as joint trajectories and manipulation commands as end-effector paths without switching models.
- The same trained weights work for human-demonstrated motions supplied as pose sequences.
- No additional training or fine-tuning is required when the reference modality changes at deployment time.
- Simulation data alone suffices to produce a policy that functions on the physical Unitree G1 across all tested modalities.
Where Pith is reading between the lines
- Robot software stacks could replace several specialized controllers with one general module that accepts mixed reference streams.
- The shared latent representation might later accept additional signals such as force or vision data without changing the policy architecture.
- Similar encoder-plus-shared-policy designs could be tested on other humanoid platforms to check whether the modality unification transfers beyond the Unitree G1.
Load-bearing premise
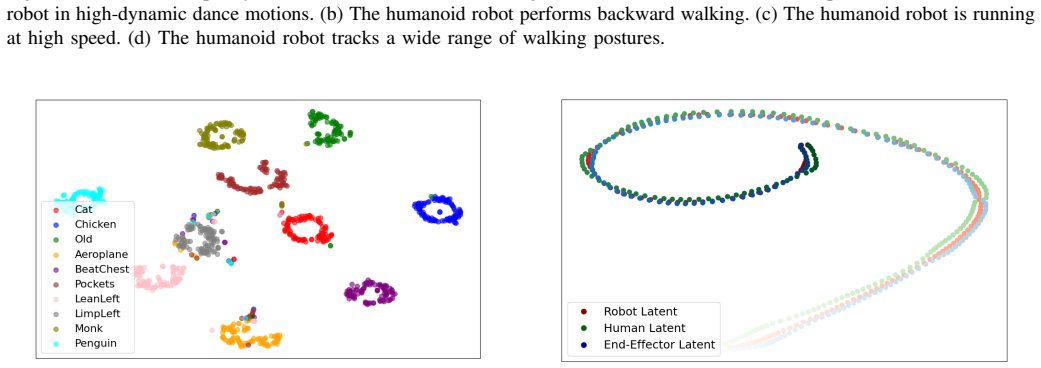
The different encoders produce latent vectors that are interchangeable enough for one policy to achieve comparable tracking performance on every input type.
What would settle it
Train the policy on the three modalities together and then measure whether success rate on end-effector tracking drops below 80 percent while a separately trained end-effector-only policy stays above 95 percent on the same test motions.
Figures




read the original abstract
Building a general-purpose whole-body controller is essential for enabling diverse motion capabilities in humanoid robots across a wide range of downstream tasks, including locomotion and loco-manipulation. Different tasks rely on distinct motion reference modalities: locomotion primarily depends on coordinated robot joint trajectories, whereas manipulation requires precise end-effector trajectory tracking. Existing methods often overlook the representational mismatch between dense robot joint angles and sparse end-effector poses. To address this, we propose Multi-Modal Mimic (M3imic), a versatile multi-modal whole-body control framework that unifies heterogeneous motion reference modalities, including robot joint angles, human pose trajectories, and end-effector poses, using modality-specific encoders to map them into a shared latent space. Leveraging large-scale reinforcement learning in the simulator, we train a single policy that achieves sim-to-real transfer across multiple motion reference modalities without modality-specific retraining. Extensive simulation and real-world experiments on the Unitree G1 robot are conducted to evaluate the proposed framework. In simulation, the policy achieves a peak success rate of 98.42\% on an unseen test dataset, demonstrating its exceptional generalization capability. The code is available at https://github.com/Renforce-Dynamics/MultiModalWBC
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes M3imic, a multi-modal whole-body controller for humanoid robots. Modality-specific encoders map heterogeneous references (robot joint angles, human pose trajectories, end-effector poses) into a shared latent space; a single policy is then trained via large-scale RL in simulation and transferred zero-shot to the Unitree G1, reporting a peak success rate of 98.42% on an unseen test set without per-modality retraining.
Significance. If the empirical claims are substantiated with per-modality metrics and ablations, the work would offer a practical route toward general-purpose humanoid controllers that avoid separate policies for locomotion versus manipulation tasks.
major comments (2)
- [Results / Experiments] The central claim requires that the shared latent space preserves comparable performance across input densities. The manuscript reports only an aggregate 98.42% success rate; no per-modality breakdown (joint-angle vs. human-pose vs. end-effector) or comparison against modality-specific policies is supplied in the results, leaving the weakest assumption untested.
- [Real-world Experiments] Sim-to-real transfer is asserted for all three modalities, yet the text supplies neither real-world success rates per modality nor failure-mode analysis on the sparsest input (end-effector poses).
minor comments (2)
- [Abstract] The abstract states 'extensive simulation and real-world experiments' but the provided text contains no quantitative real-robot numbers or statistical details.
- [Method] Notation for the modality-specific encoders and the shared latent space is introduced without an accompanying diagram or explicit dimensionality statement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to better substantiate the central claims of M3imic. We respond to each major comment below and will revise the manuscript to incorporate the requested evidence.
read point-by-point responses
-
Referee: [Results / Experiments] The central claim requires that the shared latent space preserves comparable performance across input densities. The manuscript reports only an aggregate 98.42% success rate; no per-modality breakdown (joint-angle vs. human-pose vs. end-effector) or comparison against modality-specific policies is supplied in the results, leaving the weakest assumption untested.
Authors: We agree that aggregate success alone leaves the key assumption about the shared latent space untested. The revised manuscript will include a per-modality breakdown of success rates on the unseen test set for robot joint angles, human pose trajectories, and end-effector poses, plus direct comparisons against three modality-specific policies trained under identical RL conditions. These additions will be placed in the simulation results section with accompanying discussion of any observed performance differences. revision: yes
-
Referee: [Real-world Experiments] Sim-to-real transfer is asserted for all three modalities, yet the text supplies neither real-world success rates per modality nor failure-mode analysis on the sparsest input (end-effector poses).
Authors: We acknowledge that the real-world evaluation section currently lacks modality-specific quantitative results and failure analysis. In revision we will report per-modality success rates observed on the Unitree G1 for each of the three reference types and add a dedicated paragraph analyzing failure modes, with particular attention to the end-effector pose modality. These data are drawn from the existing real-world trials described in the manuscript. revision: yes
Circularity Check
No significant circularity; empirical RL outcome with independent training
full rationale
The paper describes an empirical result obtained by training a single policy via large-scale reinforcement learning in simulation, using modality-specific encoders to produce a shared latent space. No equations, fitted parameters, or derivations are presented that reduce by construction to the inputs themselves. The central claim (98.42% success on unseen test data with sim-to-real transfer) is framed as an outcome of RL optimization rather than a quantity defined or forced by the architecture or prior self-citations. The shared latent space is an architectural design choice whose effectiveness is evaluated externally via simulation and real-world experiments, not asserted by definition. This is a standard non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. E. Li,Reinforcement learning for sequential decision and optimal control. Springer, 2023
2023
-
[2]
Review on model predic- tive control: An engineering perspective,
M. Schwenzer, M. Ay, T. Bergs, and D. Abel, “Review on model predic- tive control: An engineering perspective,”The International Journal of Advanced Manufacturing Technology, vol. 117, no. 5, pp. 1327–1349, 2021
2021
-
[3]
Multi- level control of zero-moment point-based humanoid biped robots: a review,
H. F. Al-Shuka, B. Corves, W.-H. Zhu, and B. Vanderborght, “Multi- level control of zero-moment point-based humanoid biped robots: a review,”Robotica, vol. 34, no. 11, pp. 2440–2466, 2016
2016
-
[4]
Isaac Sim
NVIDIA, “Isaac Sim.” [Online]. Available: https://github.com/isaac-sim/ IsaacSim
-
[5]
Amp: Adversarial motion priors for stylized physics-based character control,
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa, “Amp: Adversarial motion priors for stylized physics-based character control,” ACM Trans. Graph., vol. 40, no. 4, Jul. 2021. [Online]. Available: http://doi.acm.org/10.1145/3450626.3459670
-
[6]
Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,”ACM Transactions On Graphics (TOG), vol. 37, no. 4, pp. 1–14, 2018
2018
-
[7]
AMASS: Archive of motion capture as surface shapes,
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black, “AMASS: Archive of motion capture as surface shapes,” inInternational Conference on Computer Vision, Oct. 2019, pp. 5442–5451
2019
-
[8]
Object motion guided human motion synthesis,
J. Li, J. Wu, and C. K. Liu, “Object motion guided human motion synthesis,”ACM Trans. Graph., vol. 42, no. 6, 2023
2023
-
[9]
Robust motion in-betweening,
F. G. Harvey, M. Yurick, D. Nowrouzezahrai, and C. Pal, “Robust motion in-betweening,”ACM Transactions on Graphics (TOG), vol. 39, no. 4, pp. 60–1, 2020
2020
-
[10]
Real-time style modelling of human locomotion via feature-wise transformations and local motion phases,
I. Mason, S. Starke, and T. Komura, “Real-time style modelling of human locomotion via feature-wise transformations and local motion phases,”Proceedings of the ACM on Computer Graphics and Interactive Techniques, vol. 5, no. 1, may 2022
2022
-
[11]
Gmr: General motion retargeting,
Y . Ze, J. P. Ara ´ujo, J. Wu, and C. K. Liu, “Gmr: General motion retargeting,” 2025, gitHub repository. [Online]. Available: https://github.com/YanjieZe/GMR
2025
-
[12]
Twist2: Scalable, portable, and holistic humanoid data collection system,
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu, “Twist2: Scalable, portable, and holistic humanoid data collection system,”arXiv preprint arXiv:2511.02832, 2025
-
[13]
Track any motions under any disturbances,
Z. Zhang, J. Guo, C. Chen, J. Wang, C. Lin, Y . Lian, H. Xue, Z. Wang, M. Liu, H. Liu, H. Wang, and L. Yi, “Track any motions under any disturbances,”arXiv preprint arXiv:2509.13833, 2025
-
[14]
Kungfubot2: Learning versatile motion skills for humanoid whole-body control,
J. Han, W. Xie, J. Zheng, J. Shi, W. Zhang, T. Xiao, and C. Bai, “Kungfubot2: Learning versatile motion skills for humanoid whole-body control,”arXiv preprint arXiv:2509.16638, 2025
-
[15]
Hover: Versatile neural whole-body controller for humanoid robots,
T. He, W. Xiao, T. Lin, Z. Luo, Z. Xu, Z. Jiang, J. Kautz, C. Liu, G. Shi, X. Wanget al., “Hover: Versatile neural whole-body controller for humanoid robots,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 9989–9996
2025
-
[16]
A Scalable Whole-body Motion Transfer via Implicit Kinodynamic Motion Retargeting
X. Chen, H. Wu, S. Wu, M. Zhou, D. Xiang, and H. Zhang, “Implicit kinodynamic motion retargeting for human-to-humanoid imitation learn- ing,”arXiv preprint arXiv:2509.15443, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Z. Zhuang, S. Yao, and H. Zhao, “Humanoid parkour learning,”arXiv preprint arXiv:2406.10759, 2024
-
[18]
Learning getting-up policies for real-world humanoid robots,
X. He, R. Dong, Z. Chen, and S. Gupta, “Learning getting-up policies for real-world humanoid robots,”arXiv preprint arXiv:2502.12152, 2025
-
[19]
KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills
W. Xie, J. Han, J. Zheng, H. Li, X. Liu, J. Shi, W. Zhang, C. Bai, and X. Li, “Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,”arXiv preprint arXiv:2506.12851, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Q. Liao, T. E. Truong, X. Huang, G. Tevet, K. Sreenath, and C. K. Liu, “Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion,”arXiv preprint arXiv:2508.08241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Hub: Learning extreme humanoid balance,
T. Zhang, B. Zheng, R. Nai, Y . Hu, Y .-J. Wang, G. Chen, F. Lin, J. Li, C. Hong, K. Sreenathet al., “Hub: Learning extreme humanoid balance,” arXiv preprint arXiv:2505.07294, 2025
-
[22]
Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,”ACM Trans. Graph., vol. 37, no. 4, pp. 143:1–143:14, Jul
-
[23]
Graph.37, 4, Article 133 (July 2018), 13 pages
[Online]. Available: http://doi.acm.org/10.1145/3197517.3201311
-
[24]
Adversarial locomotion and motion imitation for humanoid policy learning,
J. Shi, X. Liu, D. Wang, O. Lu, S. Schwertfeger, F. Sun, C. Bai, and X. Li, “Adversarial locomotion and motion imitation for humanoid policy learning,” 2025. [Online]. Available: https: //arxiv.org/abs/2504.14305
-
[25]
Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Panet al., “Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,”arXiv preprint arXiv:2502.01143, 2025
-
[26]
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Casta˜neda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, X. Da, R. Ding, C. Hogg, L. Song, E. Lim, E. Jeong, T. He, H. Xue, W. Xiao, Z. Wang, S. Yuen, J. Kautz, Y . Chang, U. Iqbal, L. Fan, and Y . Zhu, “Sonic: Supersizing motion tracking for natural humanoid whole-body control,”arXiv preprint arXiv:2511.07820, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Expressive body capture: 3d hands, face, and body from a single image,
G. Pavlakos, V . Choutas, N. Ghorbani, T. Bolkart, A. A. A. Osman, D. Tzionas, and M. J. Black, “Expressive body capture: 3d hands, face, and body from a single image,” inProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[28]
R. S. Sutton, A. G. Bartoet al.,Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1, no. 1
1998
-
[29]
Conformal symplectic optimization for stable reinforcement learning,
Y . Lyu, X. Zhang, S. E. Li, J. Duan, L. Tao, Q. Xu, L. He, and K. Li, “Conformal symplectic optimization for stable reinforcement learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 6, pp. 11 049–11 063, 2025
2025
-
[30]
Exbody2: Advanced expressive humanoid whole-body control,
M. Ji, X. Peng, F. Liu, J. Li, G. Yang, X. Cheng, and X. Wang, “Exbody2: Advanced expressive humanoid whole-body control,”arXiv preprint arXiv:2412.13196, 2024
-
[31]
Omnih2o: Universal and dexterous human- to-humanoid whole-body teleoperation and learning,
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi, “Omnih2o: Universal and dexterous human- to-humanoid whole-body teleoperation and learning,”arXiv preprint arXiv:2406.08858, 2024
-
[32]
Visualizing data using t-sne,
L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,”Journal of machine learning research, vol. 9, no. Nov, pp. 2579–2605, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.