TAPO: Tool-Aware Policy Optimization via Credit Transfer for Multimodal Search Agents
Pith reviewed 2026-06-28 02:08 UTC · model grok-4.3
The pith
TAPO corrects credit misassignment in reinforcement learning for tool-using multimodal search agents by transferring advantages between equivalent tool calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
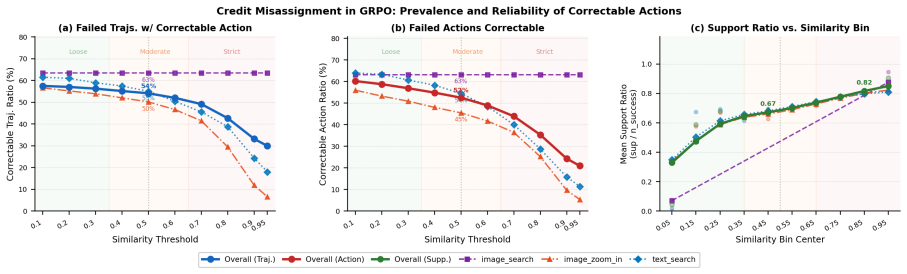
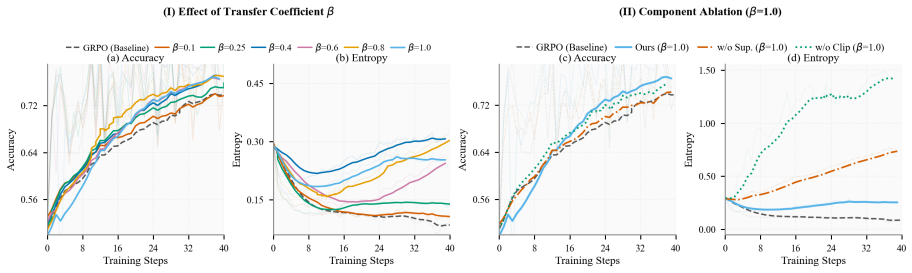
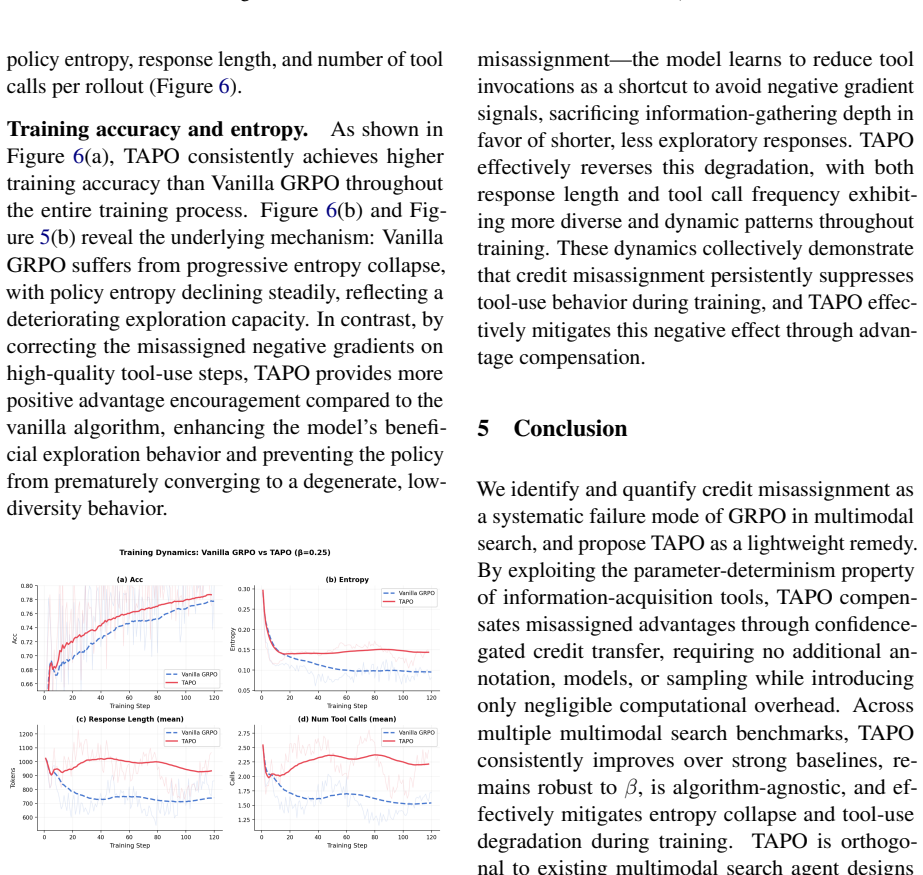
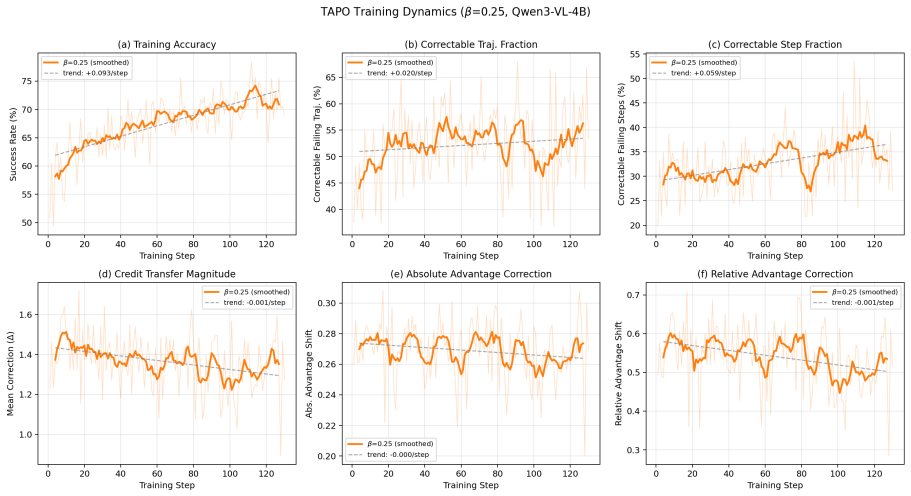
Credit misassignment is a systematic failure mode of GRPO in tool-augmented multimodal search agents because uniform trajectory-level advantage broadcast penalizes valuable tool-use steps identically to valueless ones; over half of failing trajectories exhibit this pattern. TAPO addresses it by constructing counterfactual witnesses from the parameter-determinism property of information-acquisition tools and applying confidence-gated conservative advantage correction, yielding plug-and-play gains on GRPO, GSPO, and SAPO across multiple benchmarks without extra annotation or models.
What carries the argument
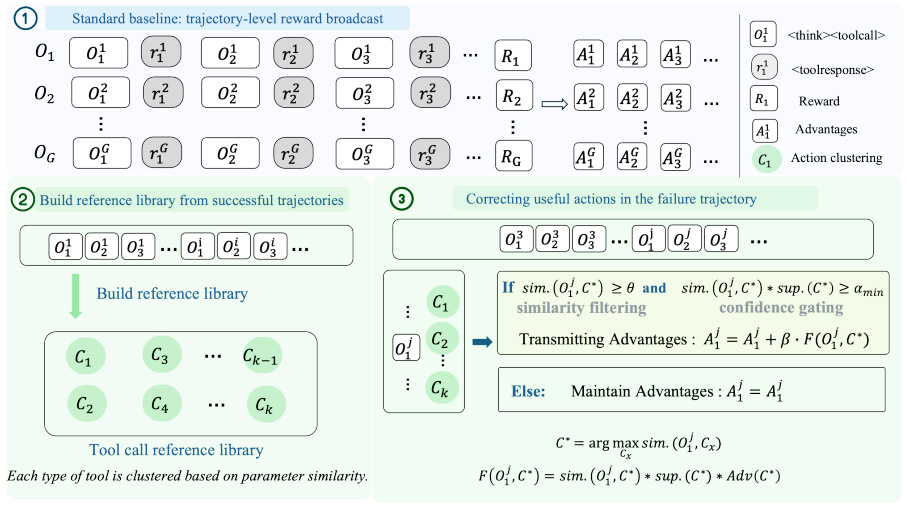
Parameter-determinism property of information-acquisition tools, which treats similar call parameters as equivalent actions that should share comparable credit; used to build batch-internal counterfactual witnesses for advantage correction.
If this is right
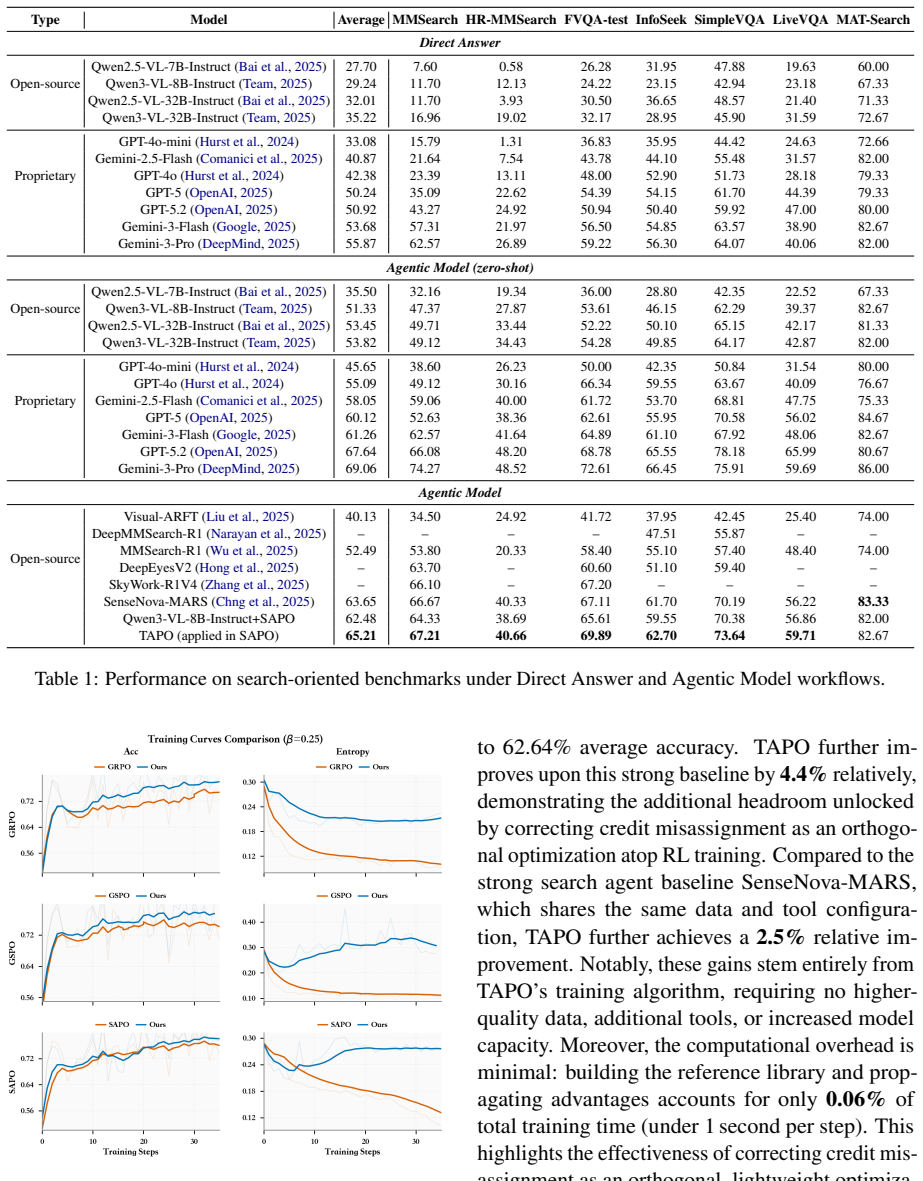
- TAPO yields consistent gains over GRPO, GSPO, and SAPO on multiple multimodal search benchmarks.
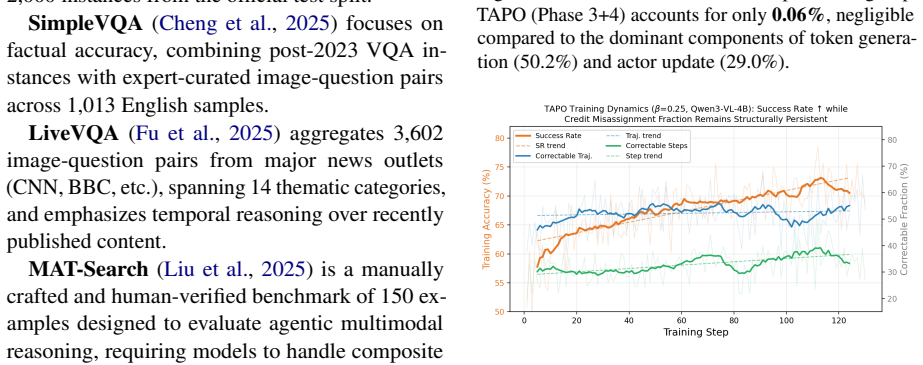
- The correction requires only existing batch data and adds negligible compute.
- More than half of observed failing trajectories and tool-use actions become correctable without new supervision.
- The method works as a drop-in replacement for the three tested RL algorithms.
Where Pith is reading between the lines
- The same parameter-determinism idea could be tested in non-search tool-use domains where action equivalence is easy to check.
- Batch-internal counterfactuals may reduce variance in other credit-assignment problems that currently rely on external value models.
- If the fraction of correctable misassignments stays high across new benchmarks, credit transfer becomes a first-line fix rather than an optional add-on.
Load-bearing premise
Similar tool call parameters define equivalent information-acquisition actions that should receive comparable credit.
What would settle it
A controlled test in which tool calls with nearly identical parameters produce measurably different information outcomes yet TAPO still improves performance, or a run showing zero gain from the correction on held-out benchmarks.
Figures





read the original abstract
We identify and formally characterize credit misassignment as a systematic failure mode of GRPO in tool-augmented multimodal search agents: its uniform broadcast of trajectory-level advantages to all tokens causes valuable tool-use steps in failing trajectories to be penalized no differently from valueless ones. We further empirically quantify the scale of this phenomenon. Over half of failing trajectories and failing tool-use actions exhibit correctable credit misassignment, demonstrating that the wasted training signal is both substantial and structurally exploitable. Building on this insight, we propose Tool-Aware Policy Optimization (TAPO), which exploits the parameter-determinism property of information-acquisition tools: similar call parameters define equivalent information-acquisition actions and should therefore share comparable action credit. TAPO constructs counterfactual witnesses within the current training batch and compensates misassigned negative credit via confidence-gated conservative advantage correction. It requires no additional annotation, models, or sampling, and introduces negligible computational overhead. Across multiple multimodal search benchmarks, TAPO delivers consistent, plug-and-play improvements over strong baselines for three mainstream RL algorithms (GRPO, GSPO, and SAPO). Our code and models will be publicly released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that GRPO in tool-augmented multimodal search agents suffers from systematic credit misassignment because uniform broadcast of trajectory-level advantages penalizes valuable tool-use steps in failing trajectories equally with valueless ones. It empirically quantifies this phenomenon as affecting over half of failing trajectories and failing tool-use actions, and introduces TAPO, which exploits the parameter-determinism of information-acquisition tools to build counterfactual witnesses within the training batch and apply confidence-gated conservative advantage correction, yielding consistent plug-and-play gains over GRPO, GSPO, and SAPO baselines on multiple multimodal search benchmarks with negligible overhead.
Significance. If the empirical scale of correctable misassignment is robustly measured and the parameter-determinism assumption holds without substantial state-dependence violations, TAPO would provide a lightweight, annotation-free improvement to credit assignment for tool-using RL agents. The promised public release of code and models would enable direct reproducibility and extension.
major comments (2)
- [Abstract] Abstract: the central empirical claim that 'over half of failing trajectories and failing tool-use actions exhibit correctable credit misassignment' is load-bearing for the motivation and for the assertion that the wasted signal is 'substantial and structurally exploitable,' yet the abstract supplies no measurement procedure, exact definition of 'correctable,' dataset, or counting methodology.
- [Abstract] Abstract: TAPO's counterfactual witnesses and advantage correction rest on the stated property that 'similar call parameters define equivalent information-acquisition actions,' but the manuscript provides no analysis or safeguards for cases in which the same parameters yield different information value depending on trajectory state (early vs. late search), which directly risks transferring advantage between non-equivalent actions.
minor comments (1)
- [Abstract] The abstract introduces the acronyms GRPO, GSPO, and SAPO without expansion on first use.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that 'over half of failing trajectories and failing tool-use actions exhibit correctable credit misassignment' is load-bearing for the motivation and for the assertion that the wasted signal is 'substantial and structurally exploitable,' yet the abstract supplies no measurement procedure, exact definition of 'correctable,' dataset, or counting methodology.
Authors: We agree that the abstract would be strengthened by including a concise description of the quantification procedure. The full manuscript (Section 4.2) defines correctable credit misassignment as the subset of tool-use actions in failing trajectories for which at least one similar-parameter witness exists among successful trajectories in the same training batch; the count is obtained by enumerating all failing tool-use steps on the evaluation benchmarks described in Section 5.1 and checking parameter similarity against the batch. We will revise the abstract to reference this definition, the dataset family, and the batch-based counting method. revision: yes
-
Referee: [Abstract] Abstract: TAPO's counterfactual witnesses and advantage correction rest on the stated property that 'similar call parameters define equivalent information-acquisition actions,' but the manuscript provides no analysis or safeguards for cases in which the same parameters yield different information value depending on trajectory state (early vs. late search), which directly risks transferring advantage between non-equivalent actions.
Authors: The referee correctly notes that the manuscript states the parameter-determinism assumption without an explicit analysis of state dependence. We will add a dedicated paragraph (and, if space permits, a short empirical table) in the revised manuscript that (a) reports the frequency of early-vs-late parameter matches on our benchmarks and (b) quantifies the residual risk after the existing confidence gate. Should the analysis reveal non-negligible state-dependent divergence, we will either tighten the similarity threshold or flag the limitation. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper identifies credit misassignment empirically from trajectory data, quantifies its prevalence directly from observations (over half of failing cases), and introduces TAPO as a correction mechanism grounded in the observable parameter-determinism property of information-acquisition tools. No equations, fitted parameters, or self-citations are shown to reduce the central claims or advantages by construction to the inputs themselves. The method is presented as a plug-and-play addition validated on external benchmarks, with no load-bearing steps that equate predictions to their own definitions or prior author results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption similar call parameters define equivalent information-acquisition actions and should therefore share comparable action credit
Reference graph
Works this paper leans on
-
[1]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Deepeyes: Incentivizing" thinking with images" via reinforcement learning , author=. arXiv preprint arXiv:2505.14362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepEyesV2: Toward Agentic Multimodal Model
Deepeyesv2: Toward agentic multimodal model , author=. arXiv preprint arXiv:2511.05271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2603.08754 , year=
Hindsight Credit Assignment for Long-Horizon LLM Agents , author=. arXiv preprint arXiv:2603.08754 , year=
-
[4]
arXiv e-prints , pages=
Livevqa: Live visual knowledge seeking , author=. arXiv e-prints , pages=
-
[5]
2025 , eprint=
Group-in-Group Policy Optimization for LLM Agent Training , author=. 2025 , eprint=
2025
-
[6]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Simplevqa: Multimodal factuality evaluation for multimodal large language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[7]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[8]
arXiv preprint arXiv:2505.14246 , year=
Visual agentic reinforcement fine-tuning , author=. arXiv preprint arXiv:2505.14246 , year=
-
[9]
arXiv preprint arXiv:2510.12801 , year=
Deepmmsearch-r1: Empowering multimodal llms in multimodal web search , author=. arXiv preprint arXiv:2510.12801 , year=
-
[10]
arXiv preprint arXiv:2409.12959 , year=
Mmsearch: Benchmarking the potential of large models as multi-modal search engines , author=. arXiv preprint arXiv:2409.12959 , year=
-
[11]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2025 , howpublished =
OpenAI , title =. 2025 , howpublished =
2025
-
[14]
2025 , howpublished =
Google , title =. 2025 , howpublished =
2025
-
[15]
2025 , howpublished =
Google DeepMind , title =. 2025 , howpublished =
2025
-
[16]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2025 , url =
Qwen Team , title =. 2025 , url =
2025
-
[19]
MMSearch-R1: Incentivizing LMMs to Search
Mmsearch-r1: Incentivizing lmms to search , author=. arXiv preprint arXiv:2506.20670 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv preprint arXiv:2509.06980 , year=
Rlfactory: A plug-and-play reinforcement learning post-training framework for llm multi-turn tool-use , author=. arXiv preprint arXiv:2509.06980 , year=
-
[21]
arXiv preprint arXiv:2512.24330 , year=
SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning , author=. arXiv preprint arXiv:2512.24330 , year=
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[24]
arXiv preprint arXiv:2603.13956 , year=
EviAgent: Evidence-Driven Agent for Radiology Report Generation , author=. arXiv preprint arXiv:2603.13956 , year=
-
[25]
WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
Webwatcher: Breaking new frontier of vision-language deep research agent , author=. arXiv preprint arXiv:2508.05748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Can pre-trained vision and language models answer visual information-seeking questions? , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[27]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[28]
Training Multi-Image Vision Agents via End2End Reinforcement Learning
Training Multi-Image Vision Agents via End2End Reinforcement Learning , author=. arXiv preprint arXiv:2512.08980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment
CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment , author=. arXiv preprint arXiv:2510.18471 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , number=
Promoting efficient reasoning with verifiable stepwise reward , author=. Proceedings of the AAAI Conference on Artificial Intelligence , number=
-
[31]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Improve mathematical reasoning in language models by automated process supervision , author=. arXiv preprint arXiv:2406.06592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models
From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models , author=. arXiv preprint arXiv:2604.09459 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
2025 , eprint=
Visual Agentic Reinforcement Fine-Tuning , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
Skywork-R1V4: Toward Agentic Multimodal Intelligence through Interleaved Thinking with Images and DeepResearch , author=. 2025 , eprint=
2025
-
[36]
2026 , eprint=
MTA-Agent: An Open Recipe for Multimodal Deep Search Agents , author=. 2026 , eprint=
2026
-
[37]
2026 , eprint=
Intrinsic Credit Assignment for Long Horizon Interaction , author=. 2026 , eprint=
2026
-
[38]
2026 , eprint=
Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models , author=. 2026 , eprint=
2026
-
[39]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[40]
Publications Manual , year = "1983", publisher =
1983
-
[41]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[42]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[43]
Dan Gusfield , title =. 1997
1997
-
[44]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[45]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.