OrderGrad: Optimizing Beyond the Mean with Order-Statistic Policy Gradient Estimation
Pith reviewed 2026-06-28 02:15 UTC · model grok-4.3
The pith
OrderGrad supplies unbiased gradient estimates for any fixed-sample order-statistic objective by a simple reward transformation before a standard policy-gradient step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
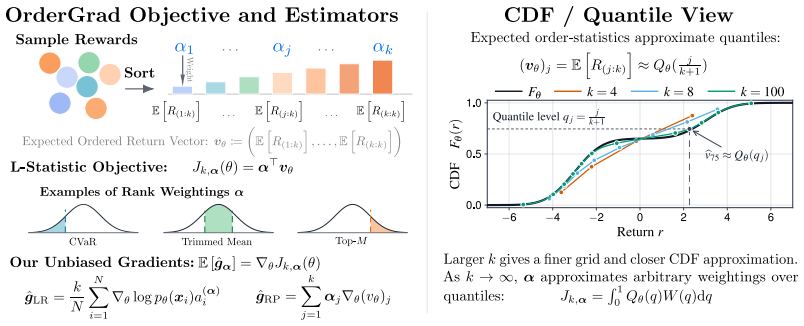
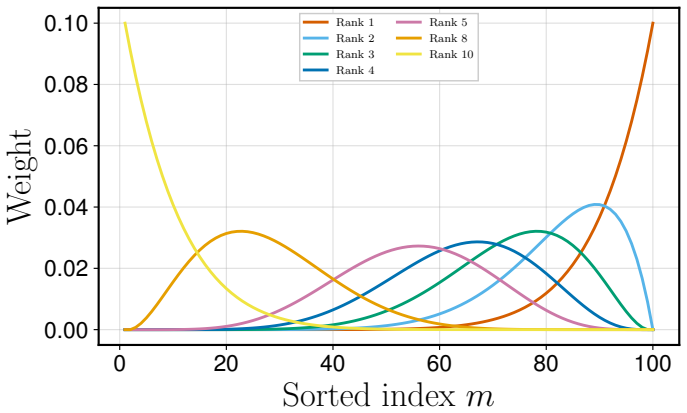
For any fixed sample size and any fixed rank-weight vector, OrderGrad yields an unbiased gradient estimator of the corresponding finite-sample L-statistic objective; the estimator is realized simply by transforming each reward according to its rank within the batch before applying a standard policy-gradient or reparameterized update.
What carries the argument
The finite-sample L-statistic defined by a fixed rank-weight vector applied to a fixed number of sorted samples; the gradient estimator is obtained by weighting each sample's contribution by its rank-dependent transformed value.
If this is right
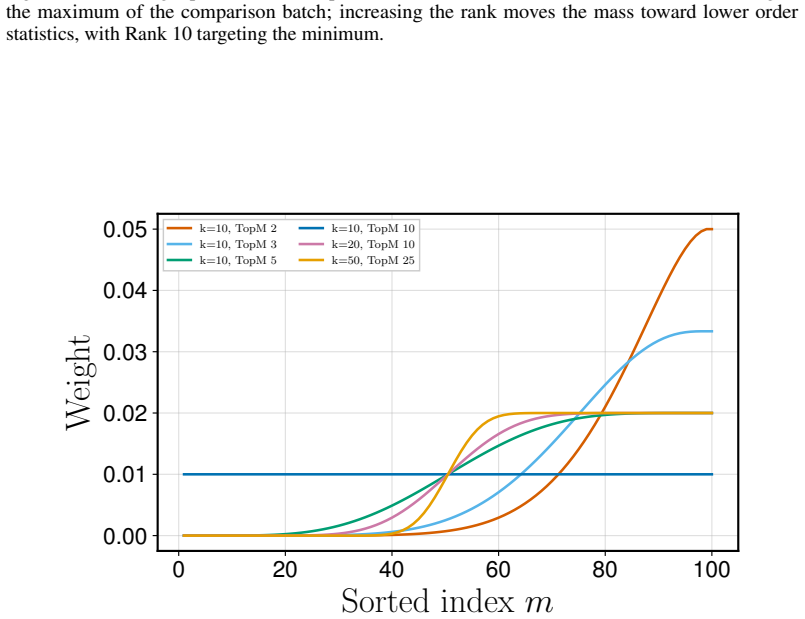
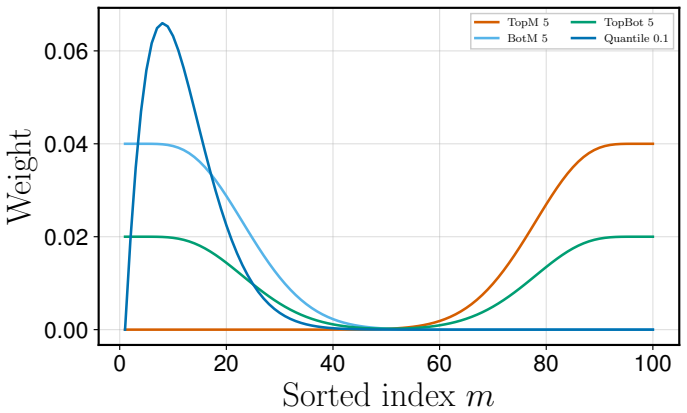
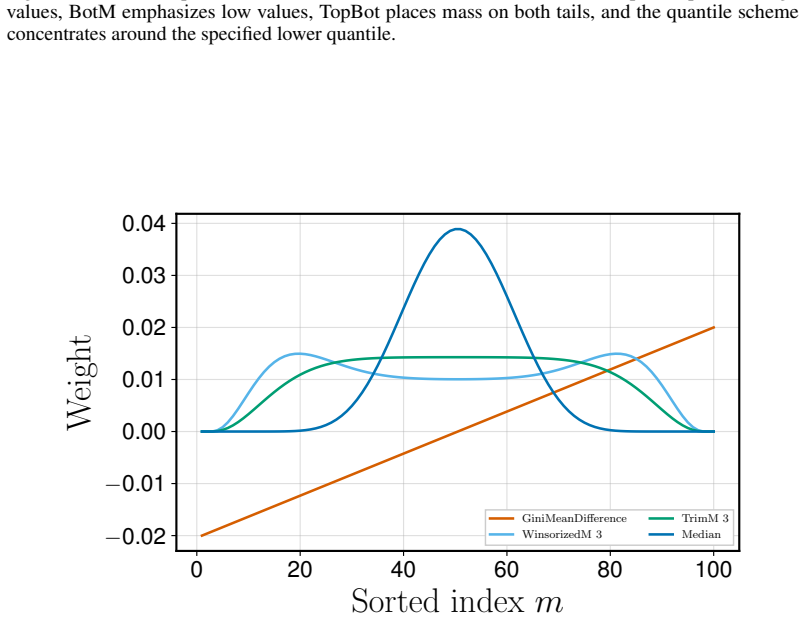
- Any existing policy-gradient or reparameterized algorithm can optimize VaR, CVaR, trimmed means, or best-of-K criteria after only a reward transformation.
- The same estimator applies unchanged to both on-policy likelihood-ratio and off-policy or reparameterized settings.
- Variance of the estimator can be controlled by choice of rank weights without altering the underlying optimizer.
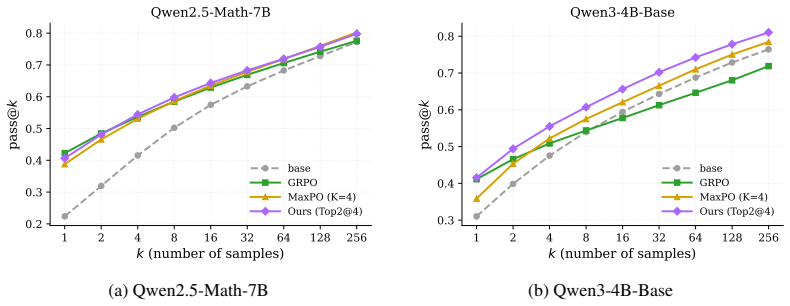
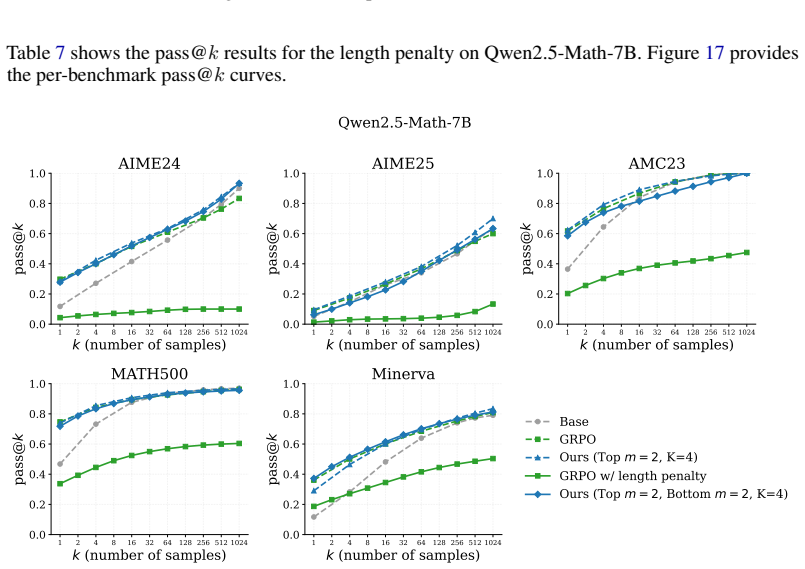
- Tasks whose deployment objective differs from mean return, such as LLM math post-training, become directly addressable.
Where Pith is reading between the lines
- If a bias-correction term could be derived, the rank weights might be allowed to adapt to the data without losing unbiasedness.
- The batch-sorting construction may extend to continuous or infinite-horizon settings by replacing exact order statistics with suitable approximations.
- The same reward-transformation idea could be applied outside reinforcement learning to any gradient-based optimizer whose loss is an order statistic.
Load-bearing premise
The number of samples used to form the order statistics must stay fixed and the rank weights must be chosen independently of the realized sample values.
What would settle it
For a simple differentiable policy and a known order-statistic objective, compute the true gradient analytically and compare it to the Monte-Carlo average of OrderGrad estimates over many independent batches of fixed size; any nonzero bias would falsify the claim.
Figures
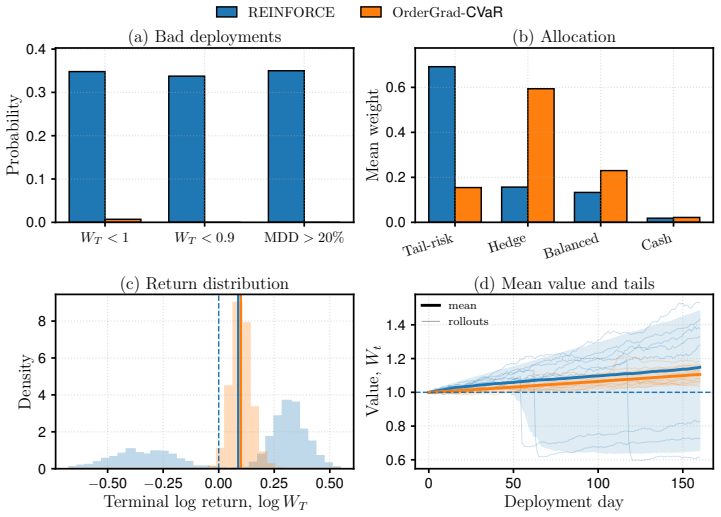
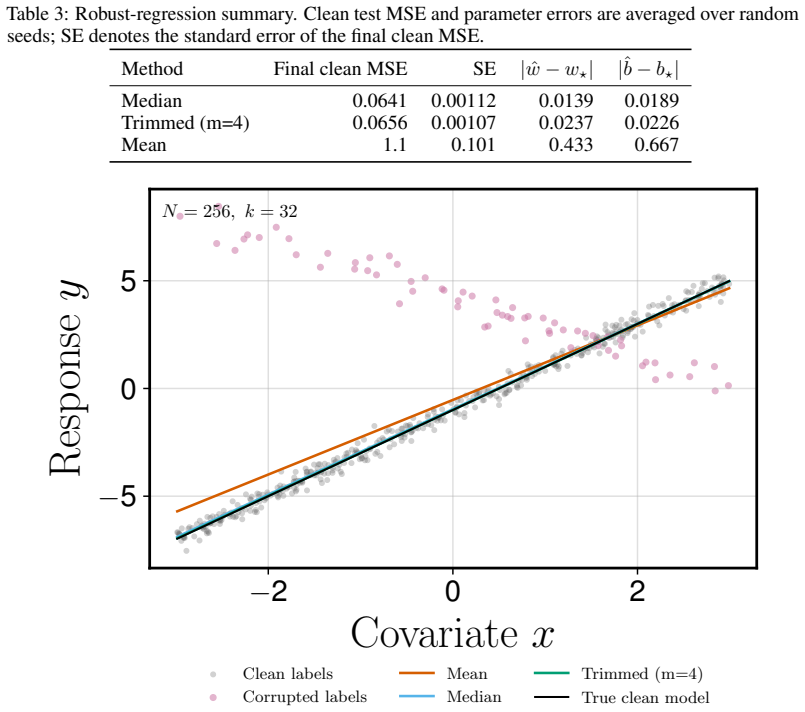
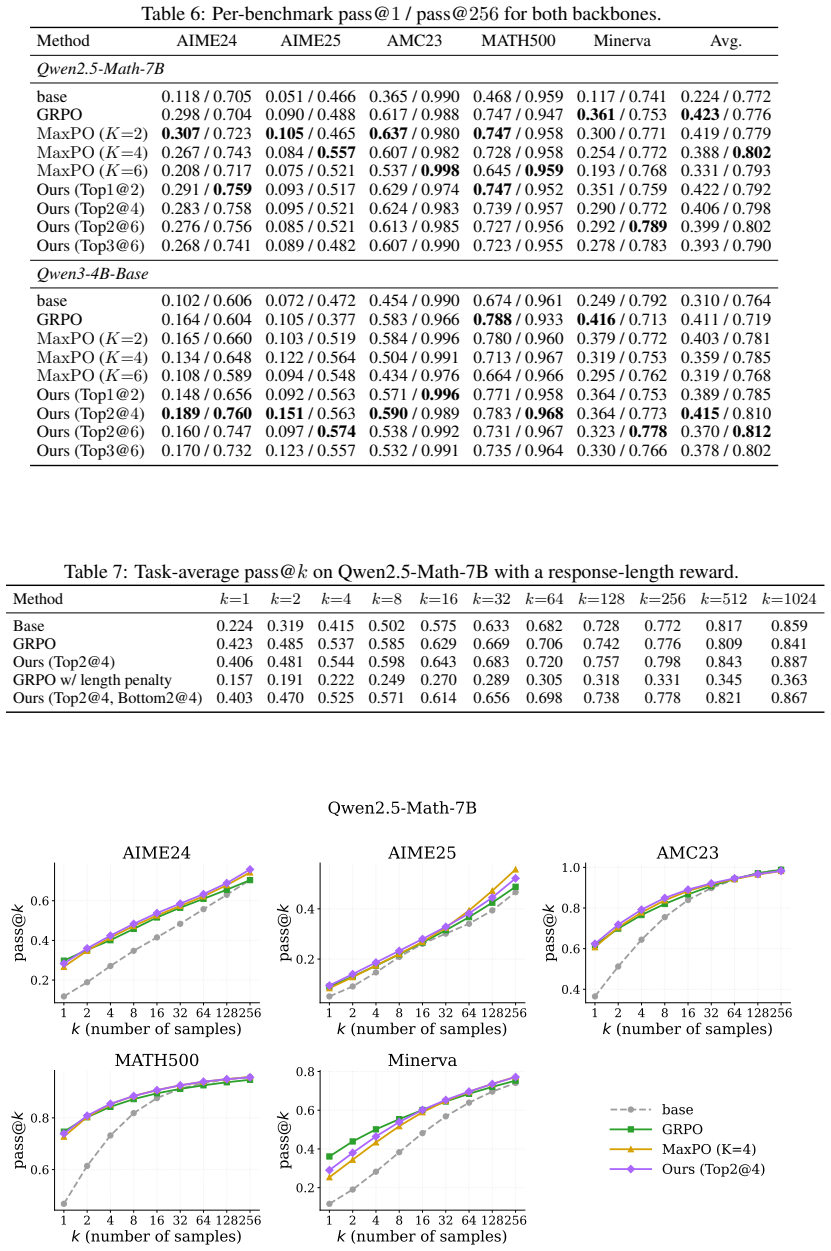
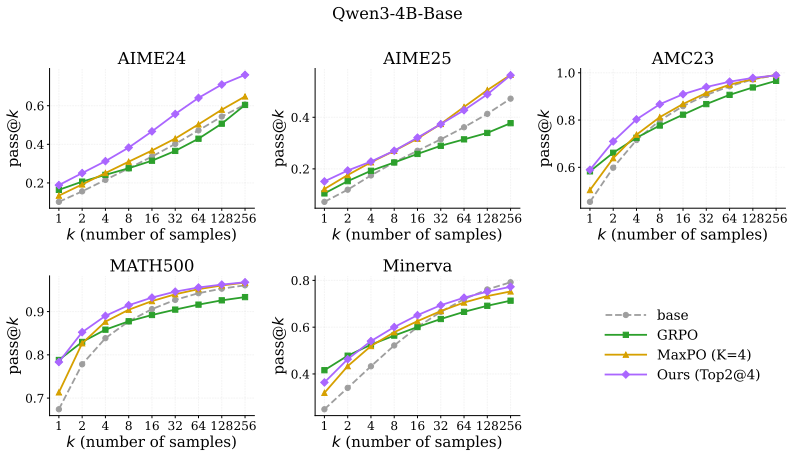
read the original abstract
Policy-gradient methods usually optimize expected return, but many real world applications care about distributional properties of returns: tail risk, outlier robustness, or best-of-K discovery. We introduce OrderGrad, a family of likelihood-ratio and reparameterization gradient estimators for order-statistic objectives. OrderGrad optimizes finite-sample L-statistics, i.e., weighted averages of sorted rewards or costs, recovering objectives such as VaR, CVaR, trimmed means, medians, and top-m/best-of-K criteria by changing only the rank weights. For any fixed sample size and rank-weight vector, OrderGrad provides an unbiased gradient estimator for the corresponding order-statistic objective. The method is implemented as a simple reward transformation that can then be used in an otherwise standard policy-gradient or reparameterized update. We study the resulting estimator's variance behavior and evaluate it on tasks where mean optimization is mismatched to the deployment objective, including LLM math post-training and other tasks. OrderGrad provides a unified, plug-and-play route to risk-averse, robust, and exploratory learning. Code: https://github.com/paavo5/ordergrad
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OrderGrad, a family of likelihood-ratio and reparameterization gradient estimators for policy optimization of finite-sample order-statistic (L-statistic) objectives. For any fixed sample size N and fixed rank-weight vector w independent of the data, it claims the resulting estimators are unbiased for the corresponding weighted sum of order statistics, recovering objectives such as VaR, CVaR, trimmed means, medians, and top-m criteria via a simple reward transformation. The work includes variance analysis and empirical evaluation on tasks where mean optimization is mismatched to the deployment goal, including LLM math post-training.
Significance. If the unbiasedness result holds under the stated conditions, OrderGrad supplies a unified, plug-and-play route to optimizing non-mean objectives in reinforcement learning and policy gradients. This is significant for risk-averse, robust, and exploratory learning settings. The open-source code link is a positive contribution that supports reproducibility.
minor comments (2)
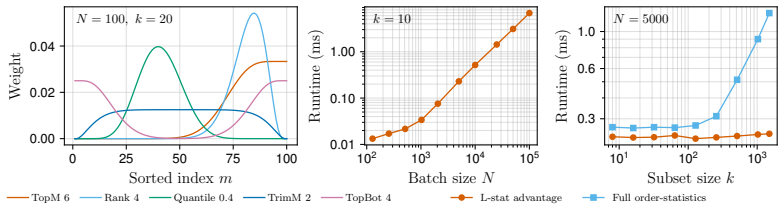
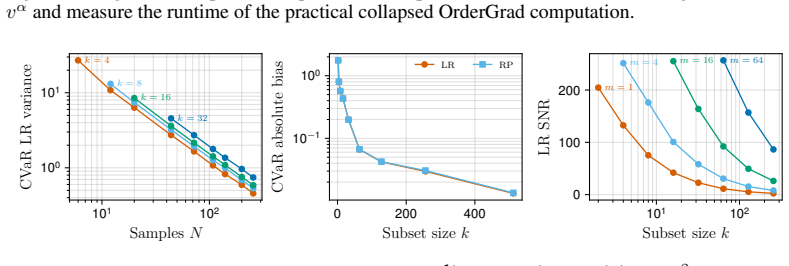
- The variance analysis mentioned in the abstract would benefit from a dedicated subsection with explicit variance expressions or bounds to make the estimator's behavior easier to compare with standard policy gradients.
- Figure captions and axis labels in the empirical section should explicitly state the sample size N and weight vector w used in each experiment to allow direct verification of the fixed-N, fixed-w condition.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of OrderGrad and the recommendation for minor revision. The provided summary accurately reflects the paper's focus on unbiased likelihood-ratio and reparameterization estimators for finite-sample L-statistic objectives via rank-based reward transformations.
Circularity Check
No significant circularity
full rationale
The paper's core claim is that OrderGrad yields an unbiased gradient estimator for any fixed N and fixed rank-weight vector w by applying the likelihood-ratio identity (or reparameterization) to the L-statistic L = sum w_k R_{(k)}. This is a direct, standard extension of the policy-gradient identity to a well-defined functional of the N i.i.d. samples; the unbiasedness holds by construction of the LR trick once N and w are held constant and independent of the data. No self-citation chain, fitted parameter renamed as prediction, or self-definitional step appears in the derivation. The assumption is stated explicitly in the claim itself, rendering the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard likelihood-ratio and reparameterization gradient estimators remain valid after the order-statistic reward transformation.
Reference graph
Works this paper leans on
-
[1]
Acerbi, C. (2002). Spectral measures of risk: A coherent representation of subjective risk aversion.Journal of Banking & Finance, 26(7):1505–1518
2002
-
[2]
and Tasche, D
Acerbi, C. and Tasche, D. (2002a). Expected shortfall: A natural coherent alternative to value at risk.Economic Notes, 31(2):379–388
-
[3]
and Tasche, D
Acerbi, C. and Tasche, D. (2002b). On the coherence of expected shortfall.Journal of Banking & Finance, 26(7):1487–1503
-
[4]
S., Courville, A
Agarwal, R., Schwarzer, M., Castro, P. S., Courville, A. C., and Bellemare, M. (2021). Deep reinforcement learning at the edge of the statistical precipice.Advances in neural information processing systems, 34:29304–29320
2021
-
[5]
Ahmadian, A., Cremer, C., Gallé, M., Fadaee, M., Kreutzer, J., Pietquin, O., Üstün, A., and Hooker, S. (2024). Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 12248–12267
2024
-
[6]
C., Balakrishnan, N., and Nagaraja, H
Arnold, B. C., Balakrishnan, N., and Nagaraja, H. N. (1992).A First Course in Order Statistics. John Wiley & Sons
1992
-
[7]
Auer, P., Cesa-Bianchi, N., and Fischer, P. (2002). Finite-time analysis of the multiarmed bandit problem.Machine learning, 47(2):235–256
2002
- [8]
-
[9]
W., Budden, D., Dabney, W., Horgan, D., Dhruva, T
Barth-Maron, G., Hoffman, M. W., Budden, D., Dabney, W., Horgan, D., Dhruva, T. B., Muldal, A., Heess, N., and Lillicrap, T. P. (2018). Distributed distributional deterministic policy gradients. InInternational Conference on Learning Representations. 10
2018
-
[10]
G., Dabney, W., and Munos, R
Bellemare, M. G., Dabney, W., and Munos, R. (2017). A distributional perspective on rein- forcement learning. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 449–458. PMLR
2017
-
[11]
G., Dabney, W., and Rowland, M
Bellemare, M. G., Dabney, W., and Rowland, M. (2023).Distributional Reinforcement Learning. The MIT Press, Cambridge, MA
2023
-
[12]
Bickel, P. J. and Lehmann, E. L. (1975). Descriptive statistics for nonparametric models. II. location.The Annals of Statistics, 3(5):1045–1069
1975
- [13]
-
[14]
Burda, Y ., Edwards, H., Storkey, A., and Klimov, O. (2018). Exploration by random network distillation.arXiv preprint arXiv:1810.12894
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Cai, S., Gao, C., Zhang, Y ., Shi, W., Zhang, J., Bao, K., Wang, Q., and Feng, F. (2025). K-order ranking preference optimization for large language models. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T., editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 4844–4859, Vienna, Austria. Association for Computational ...
2025
-
[16]
Cardoso, A. R. and Xu, H. (2019). Risk-averse stochastic convex bandit. InProceedings of the 22nd International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, pages 39–47
2019
-
[17]
T., Krishnamurthy, A., and Foster, D
Chen, F., Huang, A., Golowich, N., Malladi, S., Block, A., Ash, J. T., Krishnamurthy, A., and Foster, D. J. (2025a). The coverage principle: How pre-training enables post-training.arXiv preprint arXiv:2510.15020
-
[18]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., et al. (2021). Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Chen, Z., Qin, X., Wu, Y ., Ling, Y ., Ye, Q., Zhao, W. X., and Shi, G. (2025b). Pass@k training for adaptively balancing exploration and exploitation of large reasoning models.arXiv preprint arXiv:2508.10751
-
[20]
Reasoning with Exploration: An Entropy Perspective
Cheng, D., Huang, S., Zhu, X., Dai, B., Zhao, W. X., Zhang, Z., and Wei, F. (2025). Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Chow, Y ., Ghavamzadeh, M., Janson, L., and Pavone, M. (2018). Risk-constrained reinforcement learning with percentile risk criteria.Journal of Machine Learning Research, 18(167):1–51
2018
-
[22]
Chow, Y ., Tamar, A., Mannor, S., and Pavone, M. (2015). Risk-sensitive and robust decision- making: A CVaR optimization approach. InAdvances in Neural Information Processing Systems, volume 28, pages 1522–1530
2015
-
[23]
F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. (2017). Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, volume 30
2017
-
[24]
Cui, G., Zhang, Y ., Chen, J., Yuan, L., Wang, Z., Zuo, Y ., Li, H., Fan, Y ., Chen, H., Chen, W., et al. (2025). The entropy mechanism of reinforcement learning for reasoning language models. arXiv preprint arXiv:2505.22617
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Y ., Jegelka, S., and Krause, A
Curi, S., Levy, K. Y ., Jegelka, S., and Krause, A. (2020). Adaptive sampling for stochastic risk-averse learning. InAdvances in Neural Information Processing Systems 33, pages 1036–1047
2020
-
[26]
Dabney, W., Ostrovski, G., Silver, D., and Munos, R. (2018a). Implicit quantile networks for distributional reinforcement learning. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1096–1105. PMLR. 11
-
[27]
G., and Munos, R
Dabney, W., Rowland, M., Bellemare, M. G., and Munos, R. (2018b). Distributional reinforce- ment learning with quantile regression. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, pages 2892–2901. AAAI Press
-
[28]
Dang, X., Baek, C., Wen, K., Kolter, Z., and Raghunathan, A. (2025). Weight ensembling improves reasoning in language models. InSecond Conference on Language Modeling
2025
-
[29]
Daniell, P. J. (1920). Observations weighted according to order.American Journal of Mathem- atics, 42(4):222–236
1920
-
[30]
Fan, Y ., Lyu, S., Ying, Y ., and Hu, B. (2017). Learning with average top-k loss. InAdvances in Neural Information Processing Systems 30
2017
- [31]
-
[32]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. (2024). The Llama 3 herd of models.arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Guo, D. et al. (2025a). DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638
-
[34]
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. (2025b). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
W., Fried, D., and Welleck, S
He, A. W., Fried, D., and Welleck, S. (2025). Rewarding the unlikely: Lifting GRPO beyond distribution sharpening. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V ., editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25548–25560, Suzhou, China. Association for Computational Linguistics
2025
-
[36]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. (2021). Measuring mathematical problem solving with the MATH dataset.arXiv preprint arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[37]
Hessel, M., Modayil, J., Van Hasselt, H., Schaul, T., Ostrovski, G., Dabney, W., Horgan, D., Piot, B., Azar, M., and Silver, D. (2018). Rainbow: Combining improvements in deep reinforcement learning. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, pages 3215–3222. AAAI Press
2018
-
[38]
Holland, M. J. and Haress, E. M. (2021). Learning with risk-averse feedback under potentially heavy tails. InProceedings of the 24th International Conference on Artificial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 892–900
2021
-
[39]
Holland, M. J. and Haress, E. M. (2022). Spectral risk-based learning using unbounded losses. InProceedings of the 25th International Conference on Artificial Intelligence and Statistics, volume 151 ofProceedings of Machine Learning Research, pages 1871–1886
2022
-
[40]
Holland, M. J. and Tanabe, K. (2023). A survey of learning criteria going beyond the usual risk. Journal of Artificial Intelligence Research, 78:781–821
2023
-
[41]
Hu, S., Cai, X., Huang, Y ., Yao, Z., Zhang, L., Zhang, P., Deng, Y ., and Chen, K. (2025). Emergent slow thinking in LLMs as inverse tree freezing.arXiv preprint arXiv:2509.23629
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Huber, P. J. and Ronchetti, E. M. (2009).Robust Statistics. John Wiley & Sons, 2 edition
2009
-
[43]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. (2024). OpenAI o1 system card.arXiv preprint arXiv:2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [44]
-
[45]
Khim, J., Leqi, L., Prasad, A., and Ravikumar, P. (2020). Uniform convergence of rank-weighted learning. InInternational conference on machine learning, pages 5254–5263. PMLR
2020
-
[46]
Kingma, D. P. and Welling, M. (2014). Auto-encoding variational Bayes. InInternational Conference on Learning Representations
2014
-
[47]
Koyamada, S., Okano, S., Nishimori, S., Murata, Y ., Habara, K., Kita, H., and Ishii, S. (2023a). pgx: Hardware-accelerated parallel game simulators for reinforcement learning.Advances in Neural Information Processing Systems, 36:45716–45743
-
[48]
Koyamada, S., Parmas, P., Kozuno, T., and Ishii, S. (2023b). Emergence of exploration in policy gradient reinforcement learning via resetting. OpenReview submission to ICLR 2023. https://openreview.net/forum?id=GKsNIC_mQRG
2023
-
[49]
Lambert, N., Morrison, J., Pyatkin, V ., Huang, S., Ivison, H., Brahman, F., Miranda, L. J. V ., Liu, A., Dziri, N., Lyu, X., Gu, Y ., Malik, S., Graf, V ., Hwang, J. D., Yang, J., Le Bras, R., Tafjord, O., Wilhelm, C., Soldaini, L., Smith, N. A., Wang, Y ., Dasigi, P., and Hajishirzi, H. (2025). Tulu 3: Pushing frontiers in open language model post-train...
2025
-
[50]
L’Ecuyer, P. (1990). A unified view of the IPA, SF, and LR gradient estimation techniques. Management Science, 36(11):1364–1383
1990
-
[51]
Leqi, L., Huang, A., Lipton, Z., and Azizzadenesheli, K. (2022). Supervised learning with general risk functionals. InInternational Conference on Machine Learning, pages 12570–12592. PMLR
2022
-
[52]
J., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V
Lewkowycz, A., Andreassen, A. J., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V . V ., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., Wu, Y ., Neyshabur, B., Gur-Ari, G., and Misra, V . (2022). Solving quantitative reasoning problems with language models. InAdvances in Neural Information Processing Systems
2022
- [53]
- [54]
-
[55]
S., and Lin, M
Liu, Z., Chen, C., Li, W., Qi, P., Pang, T., Du, C., Lee, W. S., and Lin, M. (2025). Understanding r1-zero-like training: A critical perspective. InConference on Language Modeling (COLM)
2025
-
[56]
and Mendelson, S
Lugosi, G. and Mendelson, S. (2021). Robust multivariate mean estimation: The optimality of trimmed mean.The Annals of Statistics, 49(1):393–410
2021
-
[57]
G., and Castro, P
Lyle, C., Bellemare, M. G., and Castro, P. S. (2019). A comparative analysis of expected and distributional reinforcement learning. InProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, volume 33, pages 4504–4511
2019
-
[58]
Matsutani, K., Takashiro, S., Minegishi, G., Kojima, T., Iwasawa, Y ., and Matsuo, Y . (2026). RL squeezes, SFT expands: A comparative study of reasoning LLMs. InThe Fourteenth International Conference on Learning Representations
2026
-
[59]
A., Paudice, A., and Pontil, M
Maurer, A., Parletta, D. A., Paudice, A., and Pontil, M. (2021). Robust unsupervised learning via L-statistic minimization. InInternational Conference on Machine Learning, pages 7524–7533. PMLR
2021
-
[60]
Mavrin, B., Zhang, S., Yao, H., Kong, L., Wu, K., and Yu, Y . (2019). Distributional reinforce- ment learning for efficient exploration. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 4424–4434. PMLR. 13
2019
-
[61]
and Rezende, D
Mnih, A. and Rezende, D. J. (2016). Variational inference for monte carlo objectives. In Proceedings of the 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 2188–2196
2016
-
[62]
Mohamed, S., Rosca, M., Figurnov, M., and Mnih, A. (2020). Monte carlo gradient estimation in machine learning.Journal of Machine Learning Research, 21(132):1–62
2020
-
[63]
Morimura, T., Sugiyama, M., Kashima, H., Hachiya, H., and Tanaka, T. (2010a). Nonpara- metric return distribution approximation for reinforcement learning. InProceedings of the 27th International Conference on Machine Learning, pages 799–806
-
[64]
Morimura, T., Sugiyama, M., Kashima, H., Hachiya, H., and Tanaka, T. (2010b). Parametric return density estimation for reinforcement learning. InProceedings of the 26th Conference on Uncertainty in Artificial Intelligence, pages 368–375
-
[65]
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V ., Saunders, W., Jiang, X., Cobbe, K., Eloundou, T., Krueger, G., Button, K., Knight, M., Chess, B., and Schulman, J. (2021). WebGPT: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[66]
Nguyen-Tang, T., Gupta, S., and Venkatesh, S. (2021). Distributional reinforcement learning via moment matching. InProceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, volume 35, pages 9144–9152
2021
-
[67]
Nishimori, S., Parmas, P., Koyamada, S., Kozuno, T., Kitamura, T., Ishii, S., and Matsuo, Y . (2026). Emergence of exploration in policy gradient reinforcement learning via retrying. In Proceedings of the International Conference on Machine Learning
2026
-
[68]
and Tamir, A
Ogryczak, W. and Tamir, A. (2003). Minimizing the sum of the k largest functions in linear time.Information Processing Letters, 85(3):117–122
2003
-
[69]
O’Neill, B. (2025). The distribution of order statistics under sampling without replacement. Journal of Statistical Theory and Applications, 24:663–698
2025
-
[70]
OpenAI, Akkaya, I., Andrychowicz, M., Chociej, M., Litwin, M., McGrew, B., Petron, A., Paino, A., Plappert, M., Powell, G., Ribas, R., Schneider, J., Tezak, N., Tworek, J., Welinder, P., Weng, L., Yuan, Q., Zaremba, W., and Zhang, L. (2019). Solving Rubik’s cube with a robot hand. arXiv preprint arXiv:1910.07113
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[71]
OpenAI, Andrychowicz, M., Baker, B., Chociej, M., Józefowicz, R., McGrew, B., Pachocki, J., Petron, A., Plappert, M., Powell, G., Ray, A., Schneider, J., Sidor, S., Tobin, J., Welinder, P., Weng, L., and Zaremba, W. (2020). Learning dexterous in-hand manipulation.The International Journal of Robotics Research, 39(1):3–20
2020
-
[72]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744
2022
-
[73]
E., Peters, J., and Doya, K
Parmas, P., Rasmussen, C. E., Peters, J., and Doya, K. (2018). PIPPS: Flexible model-based policy search robust to the curse of chaos. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 4065–4074
2018
-
[74]
and Seno, T
Parmas, P. and Seno, T. (2022). Proppo: A message passing framework for customizable and composable learning algorithms.Advances in Neural Information Processing Systems, 35:29152– 29165
2022
-
[75]
and Sugiyama, M
Parmas, P. and Sugiyama, M. (2021). A unified view of likelihood ratio and reparameterization gradients. InProceedings of the 24th International Conference on Artificial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 4078–4086
2021
-
[76]
and Schaal, S
Peters, J. and Schaal, S. (2006). Policy gradient methods for robotics. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. 14
2006
-
[77]
and Schaal, S
Peters, J. and Schaal, S. (2008). Reinforcement learning of motor skills with policy gradients. Neural Networks, 21(4):682–697
2008
-
[78]
J., Mohamed, S., and Wierstra, D
Rezende, D. J., Mohamed, S., and Wierstra, D. (2014). Stochastic backpropagation and approximate inference in deep generative models. InProceedings of the 31st International Conference on Machine Learning, volume 32 ofProceedings of Machine Learning Research, pages 1278–1286
2014
-
[79]
Rockafellar, R. T. and Uryasev, S. (2000). Optimization of conditional value-at-risk.Journal of Risk, 2:21–42
2000
-
[80]
Rockafellar, R. T. and Uryasev, S. (2002). Conditional value-at-risk for general loss distributions. Journal of Banking & Finance, 26(7):1443–1471
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.