Benchmark Everything Everywhere All at Once
Pith reviewed 2026-06-28 01:00 UTC · model grok-4.3
The pith
An autonomous agent can construct high-quality benchmarks for LLMs and MLLMs across many domains with minimal human input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
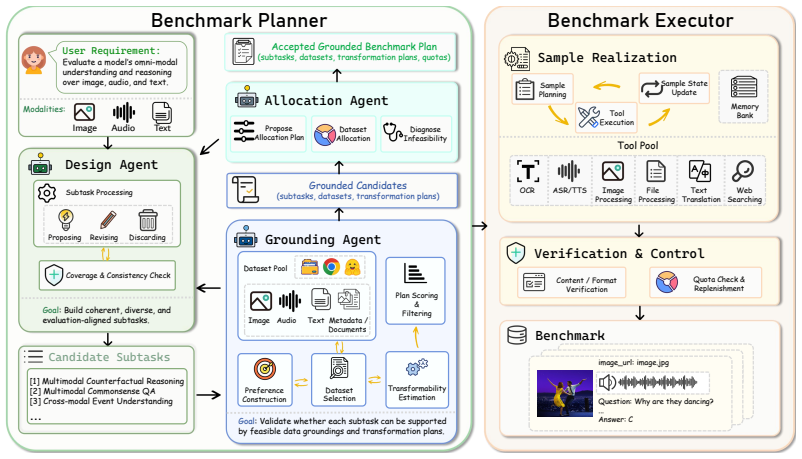
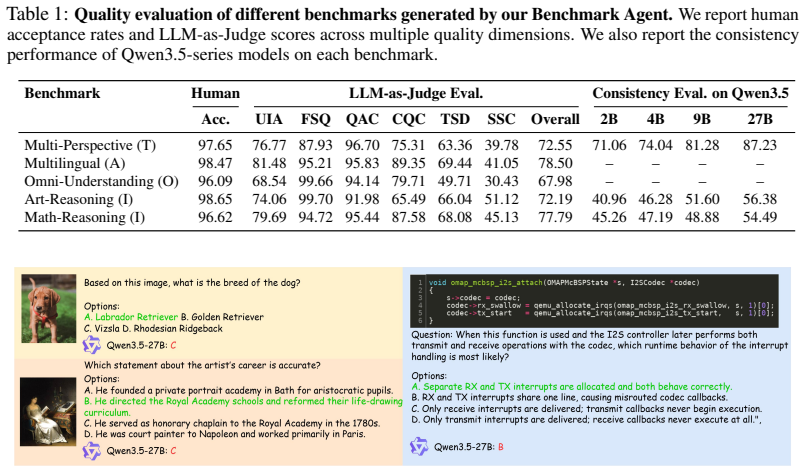
Benchmark Agent is a fully autonomous agentic system that orchestrates the complete benchmark construction pipeline from user query analysis and subtask design through data annotation and quality control, and when applied to generate fifteen representative benchmarks it produces high-quality samples validated by human evaluation, LLM-as-a-judge assessment, and consistency checks with only minimal human involvement.
What carries the argument
Benchmark Agent, the agentic system that manages the end-to-end pipeline of query analysis, subtask design, data annotation, and quality control.
If this is right
- Benchmarks can be produced rapidly enough to stay ahead of model performance saturation.
- Current models show clear weaknesses on certain domain-specific reasoning tasks when evaluated with the new samples.
- The same agentic pipeline works for text understanding, multimodal understanding, and specialized reasoning scenarios.
- Large numbers of reusable benchmarks become feasible without proportional increases in human labor.
Where Pith is reading between the lines
- Continual regeneration of benchmarks could keep evaluation sets discriminative even as models improve quickly.
- Lowering the cost of creating domain-specific tests might encourage more targeted evaluations in new fields.
- If the agent's judgments align closely with its underlying model, the benchmarks could systematically miss certain failure modes that human experts would notice.
Load-bearing premise
An LLM-driven agent can carry out data annotation and quality control at expert-human level without introducing undetected biases or low-quality samples.
What would settle it
Domain experts reviewing the generated benchmark samples identify a large share of flawed or biased items that the agent's quality-control steps did not catch.
Figures

read the original abstract
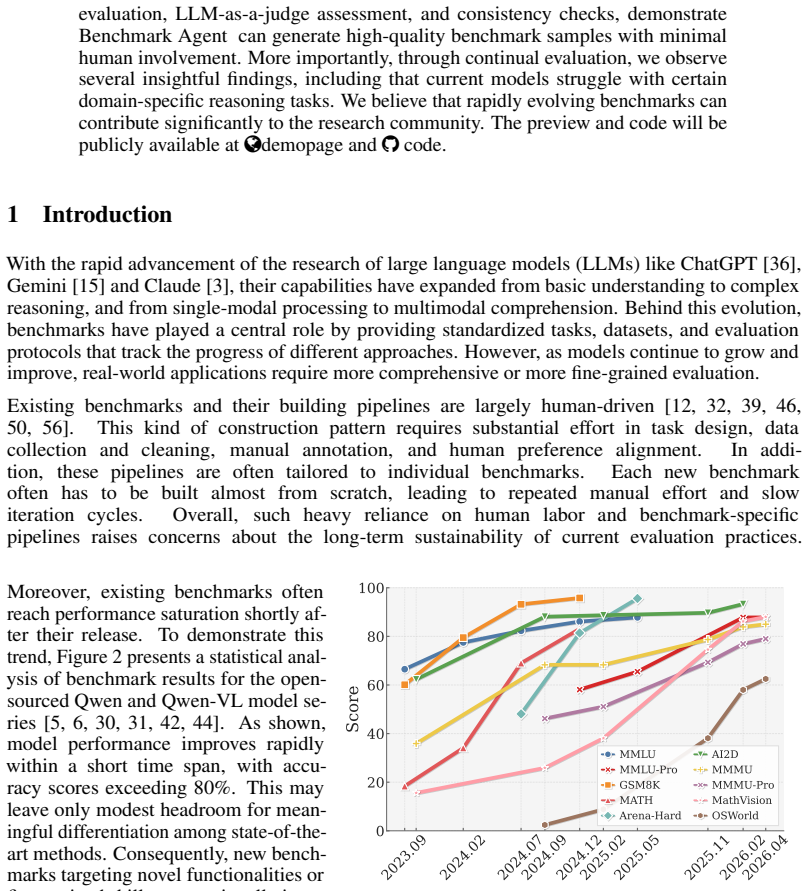
Benchmarks are fundamental for evaluating and advancing LLMs and MLLMs by providing standardized and explicit measures of performance. However, their construction is labor-intensive and hard to reuse, raising concerns about sustainability and scalability. Moreover, existing benchmarks often quickly reach performance saturation after their release, resulting in insufficient discrimination among state-of-the-art models. To address these challenges, we introduce Benchmark Agent, a fully autonomous agentic system designed for benchmark building. Our framework orchestrates the complete benchmark construction pipeline, from user query analysis and subtask design to data annotation and quality control. To assess Benchmark Agent, we implement it to produce 15 representative benchmarks, spanning diverse evaluation scenarios, including text understanding, multimodal understanding, and domain-specific reasoning. Extensive experiments, including human evaluation, LLM-as-a-judge assessment, and consistency checks, demonstrate Benchmark Agent can generate high-quality benchmark samples with minimal human involvement. More importantly, through continual evaluation, we observe several insightful findings, including that current models struggle with certain domain-specific reasoning tasks. We believe that rapidly evolving benchmarks can contribute significantly to the research community. The preview and code will be publicly available at the demo page and code repository.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Benchmark Agent, a fully autonomous agentic system that orchestrates the full benchmark construction pipeline for LLMs and MLLMs, including user query analysis, subtask design, data annotation, and quality control. The authors report implementing the system to generate 15 benchmarks spanning text understanding, multimodal understanding, and domain-specific reasoning. They claim that extensive experiments using human evaluation, LLM-as-a-judge assessment, and consistency checks demonstrate that the system produces high-quality benchmark samples with minimal human involvement, and they report additional findings from continual evaluation on model performance limitations.
Significance. If the central claims are substantiated with rigorous evidence, the work could meaningfully advance sustainable benchmark creation by reducing labor intensity and enabling rapid iteration to avoid saturation. The planned public release of code and previews would be a concrete strength, supporting reproducibility and community use. However, the current presentation provides no quantitative results, error analysis, or dataset statistics, limiting assessment of whether the approach delivers expert-level output.
major comments (2)
- [Abstract] Abstract: The central claim that 'Benchmark Agent can generate high-quality benchmark samples with minimal human involvement' rests on unspecified experiments; no quantitative metrics, inter-rater agreement scores, error rates, or sample statistics are reported, rendering the validity of the high-quality output assertion impossible to assess.
- [Experiments] Experiments (as described): The human evaluation and LLM-as-a-judge protocols are mentioned at a high level without specifying evaluator expertise across all 15 domains, the evaluation rubric, number of raters, or how subtle factual/reasoning errors were probed; this directly bears on whether the weakest assumption (reliable expert-level annotation without undetected bias) holds.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The feedback highlights important gaps in the presentation of our experimental results and protocols. We agree that additional quantitative details and protocol specifications are required to fully substantiate the claims regarding benchmark quality and will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Benchmark Agent can generate high-quality benchmark samples with minimal human involvement' rests on unspecified experiments; no quantitative metrics, inter-rater agreement scores, error rates, or sample statistics are reported, rendering the validity of the high-quality output assertion impossible to assess.
Authors: We acknowledge that the abstract does not include specific quantitative metrics or statistics. While the experiments section describes human evaluation, LLM-as-a-judge assessment, and consistency checks across the 15 benchmarks, we agree that key numbers (e.g., agreement scores, error rates, and dataset statistics) should be summarized upfront. In the revision we will update the abstract to report these quantitative findings and will add a dedicated results table or subsection with the requested statistics. revision: yes
-
Referee: [Experiments] Experiments (as described): The human evaluation and LLM-as-a-judge protocols are mentioned at a high level without specifying evaluator expertise across all 15 domains, the evaluation rubric, number of raters, or how subtle factual/reasoning errors were probed; this directly bears on whether the weakest assumption (reliable expert-level annotation without undetected bias) holds.
Authors: We agree that the current description of the evaluation protocols is insufficiently detailed. The revised manuscript will explicitly state the number of raters per benchmark, their domain expertise (including how experts were recruited for each of the 15 domains), the full evaluation rubric, and the procedures used to detect subtle factual or reasoning errors. We will also describe how the LLM-as-a-judge was validated against human judgments to address potential bias concerns. revision: yes
Circularity Check
No circularity: empirical systems paper with no derivations or fitted quantities
full rationale
The paper presents an engineering system (Benchmark Agent) for autonomous benchmark construction and reports empirical results from human/LLM evaluations on 15 generated benchmarks. No equations, parameters, uniqueness theorems, or derivation chains appear in the provided text. The central claim is an empirical demonstration of system performance rather than a mathematical reduction; evaluations are external to any self-referential input. This is a standard non-circular systems contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can perform reliable data annotation and quality control comparable to humans for benchmark construction
invented entities (1)
-
Benchmark Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Synthetic dialogue dataset generation using llm agents
Yelaman Abdullin, Diego Molla, Bahadorreza Ofoghi, John Yearwood, and Qingyang Li. Synthetic dialogue dataset generation using llm agents. InProceedings of the Third Workshop on Natural Language Generation, Evaluation, and Metrics (GEM), 2023
2023
-
[2]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
System card: Claude opus 4 and claude sonnet 4
Anthropic. System card: Claude opus 4 and claude sonnet 4. https://www-cdn.anthropic. com/6be99a52cb68eb70eb9572b4cafad13df32ed995.pdf, May 2025
2025
-
[4]
Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
Tajamul Ashraf, Amal Saqib, Hanan Ghani, Muhra AlMahri, Yuhao Li, Noor Ahsan, Umair Nawaz, Jean Lahoud, Hisham Cholakkal, Mubarak Shah, et al. Agent-x: Evaluating deep multimodal reasoning in vision-centric agentic tasks.arXiv preprint arXiv:2505.24876, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Natasha Butt, Varun Chandrasekaran, Neel Joshi, Besmira Nushi, and Vidhisha Balachan- dran. Benchagents: Multi-agent systems for structured benchmark creation.arXiv preprint arXiv:2410.22584, 2024
-
[8]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Mllm-as-a-judge: Assessing multimodal llm-as-a- judge with vision-language benchmark
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. Mllm-as-a-judge: Assessing multimodal llm-as-a- judge with vision-language benchmark. InICML, 2024
2024
-
[10]
Are we on the right way for evaluating large vision-language models?NeurIPS, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?NeurIPS, 2024
2024
-
[11]
Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations?arXiv preprint arXiv:2305.01937, 2023. 10
-
[12]
CL-bench: A Benchmark for Context Learning.arXiv e-prints, art
Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, et al. Cl-bench: A benchmark for context learning. arXiv preprint arXiv:2602.03587, 2026
-
[13]
On path to multimodal generalist: General-level and general-bench
Hao Fei, Yuan Zhou, Juncheng Li, Xiangtai Li, Qingshan Xu, Bobo Li, Shengqiong Wu, Yaoting Wang, Junbao Zhou, Jiahao Meng, et al. On path to multimodal generalist: General-level and general-bench. InICML, 2025
2025
-
[14]
Gptscore: Evaluate as you desire
Jinlan Fu, See Kiong Ng, Zhengbao Jiang, and Pengfei Liu. Gptscore: Evaluate as you desire. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024
2024
-
[15]
Gemini 3 pro model card
Google DeepMind. Gemini 3 pro model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf, December 2025
2025
-
[16]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[17]
Cerebellar output shapes cortical preparatory activity during motor adaptation.Nature Communications, 2025
Sharon Israely, Hugo Ninou, Ori Rajchert, Lee Elmaleh, Ran Harel, Firas Mawase, Jonathan Kadmon, and Yifat Prut. Cerebellar output shapes cortical preparatory activity during motor adaptation.Nature Communications, 2025
2025
-
[18]
Kimi K2: Open Agentic Intelligence
Team Kimi, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Hao Liang, Xiaochen Ma, Zhou Liu, Zhen Hao Wong, Zhengyang Zhao, Zimo Meng, Runming He, Chengyu Shen, Qifeng Cai, Zhaoyang Han, et al. Dataflow: An llm-driven framework for unified data preparation and workflow automation in the era of data-centric ai.arXiv preprint arXiv:2512.16676, 2025
-
[20]
Lequan Lin, Dai Shi, Andi Han, Feng Chen, Qiuzheng Chen, Jiawen Li, Zhaoyang Li, Jiyuan Li, Zhenbang Sun, and Junbin Gao. Act as human: Multimodal large language model data annotation with critical thinking.arXiv preprint arXiv:2511.09833, 2025
-
[21]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[22]
Mmbench: Is your multi-modal model an all-around player? InECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InECCV, 2024
2024
-
[23]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Qingwei Lin, Jianguang Lou, Shifeng Chen, Yansong Tang, and Weizhu Chen. Arena learning: Build data flywheel for llms post-training via simulated chatbot arena.arXiv preprint arXiv:2407.10627, 2024
-
[25]
Yichuan Ma, Yunfan Shao, Peiji Li, Demin Song, Qipeng Guo, Linyang Li, Xipeng Qiu, and Kai Chen. Unitcoder: Scalable iterative code synthesis with unit test guidance.arXiv preprint arXiv:2502.11460, 2025
-
[26]
Team MiroMind, Song Bai, Lidong Bing, Carson Chen, Guanzheng Chen, Yuntao Chen, Zhe Chen, Ziyi Chen, Jifeng Dai, Xuan Dong, et al. Mirothinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling.arXiv preprint arXiv:2511.11793, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Au- tonomous evaluation and refinement of digital agents.arXiv preprint arXiv:2404.06474, 2024
Jiayi Pan, Yichi Zhang, Nicholas Tomlin, Yifei Zhou, Sergey Levine, and Alane Suhr. Au- tonomous evaluation and refinement of digital agents.arXiv preprint arXiv:2404.06474, 2024. 11
-
[28]
Benchmarkˆ 2: Systematic evaluation of llm benchmarks.arXiv preprint arXiv:2601.03986, 2026
Qi Qian, Chengsong Huang, Jingwen Xu, Changze Lv, Muling Wu, Wenhao Liu, Xiaohua Wang, Zhenghua Wang, Zisu Huang, Muzhao Tian, et al. Benchmarkˆ 2: Systematic evaluation of llm benchmarks.arXiv preprint arXiv:2601.03986, 2026
-
[29]
Autobench: Automatic testbench generation and evaluation using llms for hdl design
Ruidi Qiu, Grace Li Zhang, Rolf Drechsler, Ulf Schlichtmann, and Bing Li. Autobench: Automatic testbench generation and evaluation using llms for hdl design. InProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, 2024
2024
-
[30]
Team Qwen et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2(3), 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026. URL https://qwen.ai/ blog?id=qwen3.6
2026
-
[32]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Neuronal dynamics of cerebellum and medial prefrontal cortex in adaptive motor timing.Nature Commu- nications, 2025
Zhong Ren, Xiaolu Wang, Milen Angelov, Chris I De Zeeuw, and Zhenyu Gao. Neuronal dynamics of cerebellum and medial prefrontal cortex in adaptive motor timing.Nature Commu- nications, 2025
2025
-
[34]
Tagal: Tabular data generation using agentic llm methods.arXiv preprint arXiv:2509.04152, 2025
Benoît Ronval, Pierre Dupont, and Siegfried Nijssen. Tagal: Tabular data generation using agentic llm methods.arXiv preprint arXiv:2509.04152, 2025
-
[35]
Chengyu Shen, Yanheng Hou, Minghui Pan, Runming He, Zhen Hao Wong, Meiyi Qiang, Zhou Liu, Hao Liang, Peichao Lai, Zeang Sheng, et al. One-eval: An agentic system for automated and traceable llm evaluation.arXiv preprint arXiv:2603.09821, 2026
-
[36]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InCVPR, 2019
2019
-
[38]
Hongjin Su, Ruoxi Sun, Jinsung Yoon, Pengcheng Yin, Tao Yu, and Sercan Ö Arık. Learn-by- interact: A data-centric framework for self-adaptive agents in realistic environments.arXiv preprint arXiv:2501.10893, 2025
-
[39]
Spacevista: All-scale visual spatial reasoning from mm to km.ICML, 2025
Peiwen Sun, Shiqiang Lang, Dongming Wu, Yi Ding, Kaituo Feng, Huadai Liu, Zhen Ye, Rui Liu, Yun-Hui Liu, Jianan Wang, et al. Spacevista: All-scale visual spatial reasoning from mm to km.ICML, 2025
2025
-
[40]
Huajie Tan, Xiaoshuai Hao, Cheng Chi, Minglan Lin, Yaoxu Lyu, Mingyu Cao, Dong Liang, Zhuo Chen, Mengsi Lyu, Cheng Peng, et al. Roboos: A hierarchical embodied framework for cross-embodiment and multi-agent collaboration.arXiv preprint arXiv:2505.03673, 2025
-
[41]
Ai-researcher: Autonomous scientific innovation.arXiv preprint arXiv:2505.18705, 2025
Jiabin Tang, Lianghao Xia, Zhonghang Li, and Chao Huang. Ai-researcher: Autonomous scientific innovation.arXiv preprint arXiv:2505.18705, 2025
-
[42]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[43]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[44]
Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration.NeurIPS, 2024
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration.NeurIPS, 2024
2024
-
[45]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.NeurIPS, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.NeurIPS, 2024
2024
-
[48]
Finevision: Open data is all you need,
Luis Wiedmann, Orr Zohar, Amir Mahla, Xiaohan Wang, Rui Li, Thibaud Frere, Leandro von Werra, Aritra Roy Gosthipaty, and Andrés Marafioti. Finevision: Open data is all you need,
-
[49]
URLhttps://arxiv.org/abs/2510.17269
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Language prompt for autonomous driving
Dongming Wu, Wencheng Han, Yingfei Liu, Tiancai Wang, Cheng-zhong Xu, Xiangyu Zhang, and Jianbing Shen. Language prompt for autonomous driving. InAAAI, 2025
2025
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
From Web to Pixels: Bringing Agentic Search into Visual Perception
Bokang Yang, Xinyi Sun, Kaituo Feng, Xingping Dong, Dongming Wu, and Xiangyu Yue. From web to pixels: Bringing agentic search into visual perception.arXiv preprint arXiv:2605.12497, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Swe-agent: Agent-computer interfaces enable automated software engineering.NeurIPS, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.NeurIPS, 2024
2024
-
[54]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR, 2022
2022
-
[55]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InACL, 2025
2025
-
[56]
Evaluation agent: Efficient and promptable evaluation framework for visual generative models
Fan Zhang, Shulin Tian, Ziqi Huang, Yu Qiao, and Ziwei Liu. Evaluation agent: Efficient and promptable evaluation framework for visual generative models. InACL, 2025
2025
-
[57]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024
2024
-
[58]
Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?ICLR, 2025
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?ICLR, 2025
2025
-
[59]
Dual and plasticity-dependent regulation of cerebello-zona incerta circuits on anxiety-like behaviors.Nature communications, 2025
Yue Zhao, Jin-Tao Wu, Jia-Bin Feng, Xin-Yu Cai, Xin-Tai Wang, Luxi Wang, Wei Xie, Yan Gu, Jun Liu, Wei Chen, et al. Dual and plasticity-dependent regulation of cerebello-zona incerta circuits on anxiety-like behaviors.Nature communications, 2025
2025
-
[60]
Judging llm-as-a-judge with mt-bench and chatbot arena.NeurIPS, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.NeurIPS, 2023
2023
-
[61]
Dyval: Dynamic evaluation of large language models for reasoning tasks
Kaijie Zhu, Jiaao Chen, Jindong Wang, Neil Zhenqiang Gong, Diyi Yang, and Xing Xie. Dyval: Dynamic evaluation of large language models for reasoning tasks. InICLR, 2024
2024
-
[62]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631, 2023
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631, 2023
-
[63]
Paper2video: Automatic video generation from scientific papers.arXiv preprint arXiv:2510.05096, 2025
Zeyu Zhu, Kevin Qinghong Lin, and Mike Zheng Shou. Paper2video: Automatic video generation from scientific papers.arXiv preprint arXiv:2510.05096, 2025
-
[64]
at the same time
Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. Agent- as-a-judge: Evaluate agents with agents.ICML, 2024. 13 Appendix Contents A Experiment Details 15 A.1 Benchmarks Generated from Benchmark Agent . . . . . . . . . . . . . . . . . . . 1...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.