HKJudge: A Legal Discourse-Annotated Corpus for Interpreting What Courts Find, How They Reason, and What They Rule
Pith reviewed 2026-06-28 01:26 UTC · model grok-4.3
The pith
HKJudge is the first sentence-level expert-annotated corpus of Hong Kong court judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
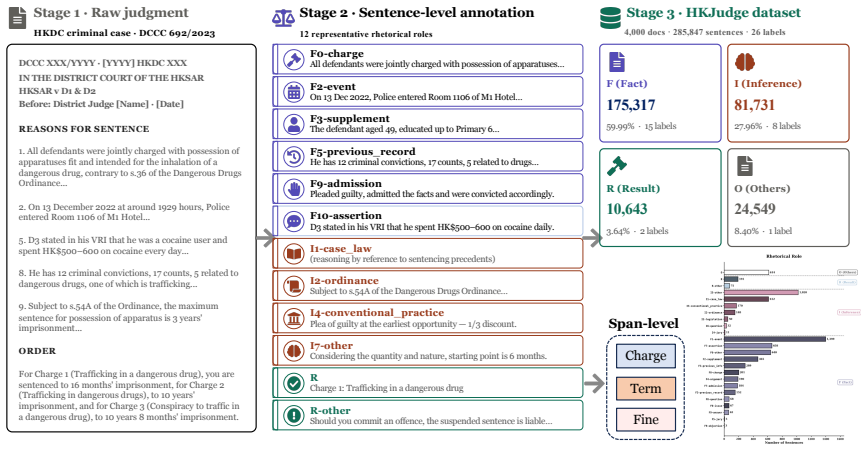
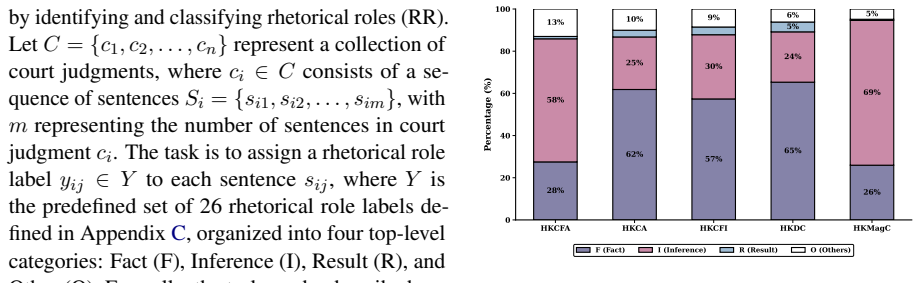
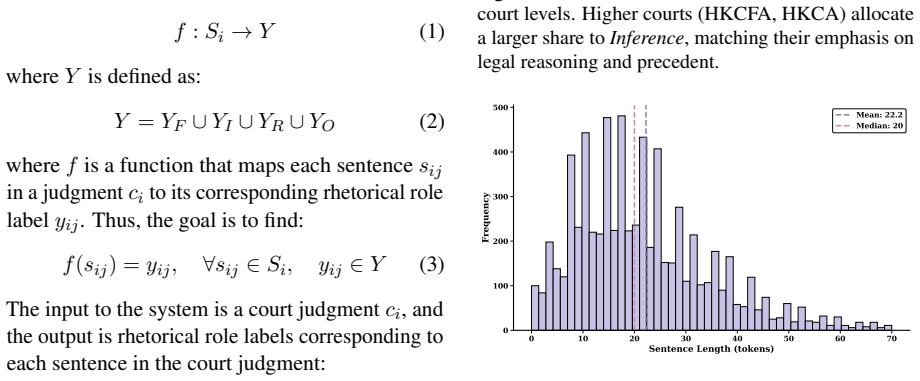
We introduce the Hong Kong Judgment Discourse Dataset (HKJudge), the first sentence-level expert-annotated legal discourse corpus. HKJudge includes criminal judgments across all five levels of HK's court hierarchy, comprising ~290k sentences and ~6.5 million tokens, fully annotated by legal linguistics experts. We design a two-tier discourse schema that captures what facts a court finds, how it reasons, and what it rules. At the sentence level, each sentence is assigned one of 26 rhetorical roles. At the span level, sentences are further annotated with three sentencing elements (charge, imprisonment term, fine). Ten legal linguistics annotators produced the annotations with an inter-annotato
What carries the argument
The two-tier discourse schema of 26 rhetorical roles at sentence level plus three sentencing elements at span level.
If this is right
- Rhetorical role classification can now be performed at the sentence level on Hong Kong judgments.
- Legal element extraction can target specific spans for charges, imprisonment terms, and fines.
- Sentence-level discourse labels supply a structured representation of judgment reasoning.
- The annotated corpus supplies training data for legal judgment prediction models.
- The size and coverage across court levels allow evaluation of models on a broad range of case types.
Where Pith is reading between the lines
- The same sentence-level schema could be applied to judgments from other common-law jurisdictions to test transferability.
- Discourse labels may improve the ability of models to surface the logical steps in a court's decision.
- The large token count could support continued pre-training of domain-specific legal language models.
- Extending the annotation to civil judgments would reveal whether the 26 roles generalize beyond criminal cases.
Load-bearing premise
The two-tier schema with 26 rhetorical roles and three sentencing elements is sufficient to capture the key structure of what courts find, how they reason, and what they rule.
What would settle it
Independent re-annotation of a held-out subset of judgments that produces substantially lower agreement on the 26 roles, or models that show no accuracy gain on role classification or element extraction when given the discourse labels versus raw text alone.
Figures



read the original abstract
Court judgments are central to legal practice and jurisprudence, yet discourse analysis of Hong Kong judgments has received limited attention, owing largely to the absence of expert-annotated corpora. We introduce the Hong Kong Judgment Discourse Dataset (HKJudge), the first sentence-level expert-annotated legal discourse corpus. HKJudge includes criminal judgments across all five levels of HK's court hierarchy, comprising $\sim$290k sentences and $\sim$6.5 million tokens, fully annotated by legal linguistics experts. We design a two-tier discourse schema that captures what facts a court finds, how it reasons, and what it rules. At the sentence level, each sentence is assigned one of 26 rhetorical roles. At the span level, sentences are further annotated with three sentencing elements (charge, imprisonment term, fine). Ten legal linguistics annotators produced the annotations with an inter-annotator agreement of $\kappa = 0.8$. We formulate two tasks on HKJudge, termed rhetorical role classification and legal element extraction, and provide the first benchmark evaluation of four BERT-based models, two open-source LLMs under zero-shot and fine-tuning settings, and four commercial LLMs on both tasks. Our work demonstrates the value of sentence-level discourse annotation for modeling the structure of HK judgments and provides a rich data foundation for future work on legal judgment prediction. The HKJudge dataset and code are available at https://github.com/xuanxixi/HKJudge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Hong Kong Judgment Discourse Dataset (HKJudge), the first sentence-level expert-annotated legal discourse corpus for Hong Kong criminal judgments. It comprises ~290k sentences (~6.5M tokens) from all five court levels, annotated by ten legal linguistics experts using a two-tier schema (26 rhetorical roles at sentence level; three sentencing elements at span level) with overall κ=0.8. Two tasks are defined (rhetorical role classification and legal element extraction), with benchmark results reported for four BERT-based models, two open LLMs (zero-shot and fine-tuned), and four commercial LLMs. The dataset and code are publicly released.
Significance. If the annotation quality and documentation hold, this is a valuable new resource for legal NLP focused on Hong Kong judgments. The scale, multi-level court coverage, expert annotation, public release, and multi-model benchmarks provide a solid foundation for future work on judgment structure modeling and legal judgment prediction. The absence of mathematical derivations or parameter fitting is appropriate for a resource contribution.
major comments (2)
- [Annotation section] Annotation section: the manuscript provides no details on the annotation guidelines given to the ten experts, their training, or the procedure for resolving disagreements. These are required to substantiate the reported κ=0.8 and to allow replication or extension of the resource.
- [Experiments section] Experiments section: no description of train/dev/test splits for the two benchmark tasks or any error analysis of model outputs is included. This undermines evaluation of the reported baselines and the claim that the corpus supports modeling of court judgments.
minor comments (2)
- [Abstract] Abstract: the figures ~290k sentences and ~6.5 million tokens should be stated precisely (or clearly labeled as approximate) with exact counts in the main text and data release.
- [Introduction] Introduction: the novelty claim as 'the first' such corpus would be strengthened by an explicit comparison table to prior legal discourse corpora (e.g., from other jurisdictions) even if none match the HK-specific two-tier schema.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation of minor revision. We appreciate the recognition of HKJudge's value as a resource. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Annotation section] Annotation section: the manuscript provides no details on the annotation guidelines given to the ten experts, their training, or the procedure for resolving disagreements. These are required to substantiate the reported κ=0.8 and to allow replication or extension of the resource.
Authors: We agree that the manuscript omits these details. In the revised version we will expand the Annotation section to include summaries of the guidelines provided to the ten legal linguistics experts, their prior training and qualifications, and the multi-stage disagreement resolution process (initial independent annotation followed by discussion rounds and final adjudication by a lead expert). These elements are documented in our annotation protocol and will be added to substantiate κ=0.8 and support replication. revision: yes
-
Referee: [Experiments section] Experiments section: no description of train/dev/test splits for the two benchmark tasks or any error analysis of model outputs is included. This undermines evaluation of the reported baselines and the claim that the corpus supports modeling of court judgments.
Authors: We acknowledge the omission. The revised manuscript will add a subsection detailing the train/dev/test splits for both tasks (including proportions, stratification by court level, and any balancing steps) together with an error analysis of model outputs (e.g., per-class performance breakdowns and representative error examples). These additions will allow readers to better assess the baselines. revision: yes
Circularity Check
No significant circularity; standard resource paper
full rationale
The paper introduces HKJudge, a new sentence-level annotated legal discourse corpus of ~290k sentences from Hong Kong judgments. It defines a two-tier schema (26 rhetorical roles + 3 sentencing elements), reports expert annotation with κ=0.8, formulates two tasks, and provides baseline results from BERT/LLM models. No equations, parameter fitting, predictions derived from inputs, or load-bearing self-citations appear. The schema is presented as a designed annotation framework rather than a derived or proven result. The contribution is the public dataset and benchmarks; the derivation chain is absent by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert legal linguistics annotators can consistently apply the 26-role schema to produce reliable labels (supported by reported kappa=0.8)
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Neural legal judgment prediction in English , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[2]
PloS one , volume=
A general approach for predicting the behavior of the Supreme Court of the United States , author=. PloS one , volume=. 2017 , publisher=
2017
-
[3]
, author=
Legal Judgment Prediction: A Survey of the State of the Art. , author=. IJCAI , pages=
-
[4]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Legalagentbench: Evaluating llm agents in legal domain , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
Proceedings of the Third International Joint Conference on Natural Language Processing: Volume-I , year=
Automatic identification of rhetorical roles using conditional random fields for legal document summarization , author=. Proceedings of the Third International Joint Conference on Natural Language Processing: Volume-I , year=
-
[6]
arXiv preprint arXiv:2503.00128 , year=
AnnoCaseLaw: a richly-annotated dataset for benchmarking explainable legal judgment prediction , author=. arXiv preprint arXiv:2503.00128 , year=
-
[7]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Segmenter: Transformer for semantic segmentation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[8]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Unimatch v2: Pushing the limit of semi-supervised semantic segmentation , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2025 , publisher=
2025
-
[9]
Neurocomputing , volume=
A brief survey on semantic segmentation with deep learning , author=. Neurocomputing , volume=. 2020 , publisher=
2020
-
[10]
arXiv preprint arXiv:2305.02558 , year=
Analyzing Hong Kong's Legal Judgments from a Computational Linguistics point-of-view , author=. arXiv preprint arXiv:2305.02558 , year=
-
[11]
2026 , eprint=
TransLaw: A Large-Scale Dataset and Multi-Agent Benchmark Simulating Professional Translation of Hong Kong Case Law , author=. 2026 , eprint=
2026
-
[12]
Pragmatics , volume=
The structural format and rhetorical variation of writing Chinese judicial opinions: A genre analytical approach , author=. Pragmatics , volume=. 2018 , publisher=
2018
-
[13]
Journal of Law and Courts , volume=
Mass digitization of Chinese court decisions: How to use text as data in the field of Chinese law , author=. Journal of Law and Courts , volume=. 2020 , publisher=
2020
-
[14]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Internlm-law: An open-sourced chinese legal large language model , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[15]
Artificial Intelligence and Law , volume=
Identification of rhetorical roles for segmentation and summarization of a legal judgment , author=. Artificial Intelligence and Law , volume=. 2010 , publisher=
2010
-
[16]
ARTIFICIAL INTELLIGENCE AND LAW , year=
MARRO: MULTI-HEADED ATTENTION FOR RHETORICAL ROLE LABELING IN LEGAL DOCUMENTS , author=. ARTIFICIAL INTELLIGENCE AND LAW , year=
-
[17]
CEUR Workshop Proceedings , volume=
Automatic rhetorical roles classification for legal documents using legal-transformeroverbert , author=. CEUR Workshop Proceedings , volume=. 2023 , organization=
2023
-
[18]
, author=
Automatic Classification of Rhetorical Roles for Sentences: Comparing Rule-Based Scripts with Machine Learning. , author=. ASAIL@ ICAIL , volume=
-
[19]
Legal Knowledge and Information Systems: JURIX 2018: The Thirty-first Annual Conference , volume=
Segmenting us court decisions into functional and issue specific parts , author=. Legal Knowledge and Information Systems: JURIX 2018: The Thirty-first Annual Conference , volume=. 2018 , organization=
2018
-
[20]
2014 , publisher=
Analysing genre: Language use in professional settings , author=. 2014 , publisher=
2014
-
[21]
Legal knowledge and information systems: JURIX , pages=
Letsum, an automatic legal text summarizing , author=. Legal knowledge and information systems: JURIX , pages=
-
[22]
Proceedings of the eighteenth international conference on artificial intelligence and law , pages=
Incorporating domain knowledge for extractive summarization of legal case documents , author=. Proceedings of the eighteenth international conference on artificial intelligence and law , pages=
-
[23]
International Journal of Legal Discourse , volume=
Negotiation of justice: the discursive construction of attitudinal positioning in bilingual legal judgments of HKSAR v KWAN WAN KI , author=. International Journal of Legal Discourse , volume=. 2023 , publisher=
2023
-
[24]
International Conference on Big Data Analytics , pages=
Structured definitions and segmentations for legal reasoning in LLMs: a study on Indian legal data , author=. International Conference on Big Data Analytics , pages=. 2025 , organization=
2025
-
[25]
Proceedings of the nineteenth international conference on artificial intelligence and law , pages=
Legal syllogism prompting: Teaching large language models for legal judgment prediction , author=. Proceedings of the nineteenth international conference on artificial intelligence and law , pages=
-
[26]
i-lex , volume=
From human-in-the-loop to LLM-in-the-loop for high quality legal dataset , author=. i-lex , volume=
-
[27]
arXiv preprint arXiv:2603.08286 , year=
LAMUS: A Large-Scale Corpus for Legal Argument Mining from US Caselaw using LLMs , author=. arXiv preprint arXiv:2603.08286 , year=
-
[28]
JURIX 2023-The 36th International Conference on Legal Knowledge and Information Systems , year=
Harnessing GPT-3.5-turbo for Rhetorical Role Prediction in Legal Cases , author=. JURIX 2023-The 36th International Conference on Legal Knowledge and Information Systems , year=
2023
-
[29]
Semiotica , volume=
Revisiting judgment translation in Hong Kong , author=. Semiotica , volume=. 2016 , publisher=
2016
-
[30]
International Journal for the Semiotics of Law-Revue internationale de S
Linguistic Tension in the Postcolonial Judicial Landscape: A Case Study of Legal Bilingualism in Hong Kong SAR , author=. International Journal for the Semiotics of Law-Revue internationale de S. 2025 , publisher=
2025
-
[31]
The Chinese Journal of Comparative Law , volume=
Moral discourse in Hong Kong’s Chinese criminal proceedings , author=. The Chinese Journal of Comparative Law , volume=. 2015 , publisher=
2015
-
[32]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Coupling Local Context and Global Semantic Prototypes via a Hierarchical Architecture for Rhetorical Roles Labeling , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Hiculr: Hierarchical curriculum learning for rhetorical role labeling of legal documents , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[34]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Mind your neighbours: Leveraging analogous instances for rhetorical role labeling for legal documents , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[35]
European Conference on Information Retrieval , pages=
Joint span segmentation and rhetorical role labeling with data augmentation for legal documents , author=. European Conference on Information Retrieval , pages=. 2023 , organization=
2023
-
[36]
Artificial Intelligence and Law , volume=
DeepRhole: deep learning for rhetorical role labeling of sentences in legal case documents , author=. Artificial Intelligence and Law , volume=. 2023 , publisher=
2023
-
[37]
Identification of rhetorical roles of sentences in indian legal judgments , author=
-
[38]
Proceedings of the Natural Legal Language Processing Workshop 2022 , pages=
Semantic segmentation of legal documents via rhetorical roles , author=. Proceedings of the Natural Legal Language Processing Workshop 2022 , pages=
2022
-
[39]
CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction
Cail2018: A large-scale legal dataset for judgment prediction , author=. arXiv preprint arXiv:1807.02478 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Legalseg: Unlocking the structure of indian legal judgments through rhetorical role classification , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[41]
Proceedings of the Thirteenth Language Resources and Evaluation Conference , pages=
Corpus for automatic structuring of legal documents , author=. Proceedings of the Thirteenth Language Resources and Evaluation Conference , pages=
-
[42]
Artificial Intelligence and Law , volume=
DiscoLQA: zero-shot discourse-based legal question answering on European Legislation , author=. Artificial Intelligence and Law , volume=. 2025 , publisher=
2025
-
[43]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
WebDP: Understanding Discourse Structures in Semi-Structured Web Documents , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[44]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Discourse analysis via questions and answers: Parsing dependency structures of questions under discussion , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[45]
Association for Computational Linguistics: ACL 2026 , year=
Semantic Reranking at Inference Time for Hard Examples in Rhetorical Role Labeling , author=. Association for Computational Linguistics: ACL 2026 , year=
2026
-
[46]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Talking point based ideological discourse analysis in news events , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[47]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts , pages=
Discourse analysis and its applications , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts , pages=
-
[48]
Qualitative researching with text, image and sound , volume=
Discourse analysis , author=. Qualitative researching with text, image and sound , volume=. 2000 , publisher=
2000
-
[49]
2025 , publisher=
An introduction to discourse analysis: Theory and method , author=. 2025 , publisher=
2025
-
[50]
Current and New Directions in Discourse and Dialogue , pages=
Building a Discourse-Tagged Corpus in the Framework of Rhetorical Structure Theory , author=. Current and New Directions in Discourse and Dialogue , pages=
-
[51]
, author=
LEEC for Judicial Fairness: A Legal Element Extraction Dataset with Extensive Extra-Legal Labels. , author=. IJCAI , pages=
-
[52]
Statistical science , pages=
Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy , author=. Statistical science , pages=. 1986 , publisher=
1986
-
[53]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
-
[54]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
A Dialog with Claude , volume=
What Miriam Yevick Saw: The Nature of Intelligence and the Prospects for AI, A Dialog with Claude 3.5 Sonnet , author=. A Dialog with Claude , volume=
-
[56]
2026 , publisher=
Architectural Advances and Performance Benchmarks of Large Language Models in Light of Anthropic’s Claude Opus 4.6 , author=. 2026 , publisher=
2026
-
[57]
Nature , volume=
GPT-4 is here: what scientists think , author=. Nature , volume=. 2023 , publisher=
2023
-
[58]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Neural Information Processing Systems , year=
The Llama 3 herd of models , author=. Neural Information Processing Systems , year=
-
[61]
Proceedings of the 46th international ACM SIGIR conference on research and development in information retrieval , pages=
Ml-ljp: Multi-law aware legal judgment prediction , author=. Proceedings of the 46th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[62]
Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages@ LREC-COLING 2024 , pages=
Improving legal judgement prediction in Romanian with long text encoders , author=. Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages@ LREC-COLING 2024 , pages=
2024
-
[63]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
LEGAL-BERT: The muppets straight out of law school , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[64]
Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval , pages=
Neurjudge: A circumstance-aware neural framework for legal judgment prediction , author=. Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[65]
The Asian ESP Journal , volume=
A discursive approach to legal texts: Court judgments as an example , author=. The Asian ESP Journal , volume=. 2008 , publisher=
2008
-
[66]
Language and the Law , pages=
The language of the law , author=. Language and the Law , pages=. 2014 , publisher=
2014
-
[67]
Proceedings of the 2024 ACM conference on fairness, accountability, and transparency , pages=
(A) I am not A lawyer, but...: engaging legal experts towards responsible LLM policies for legal advice , author=. Proceedings of the 2024 ACM conference on fairness, accountability, and transparency , pages=
2024
-
[68]
European Review of Private Law , volume=
Towards a New Era for the Legal Profession , author=. European Review of Private Law , volume=
-
[69]
Computer Science Review , volume=
Summarization of legal documents: Where are we now and the way forward , author=. Computer Science Review , volume=. 2021 , publisher=
2021
-
[70]
Columbia Law Review , volume=
Corporation Law in Search of Its Future , author=. Columbia Law Review , volume=. 1981 , publisher=
1981
-
[71]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Legalcore: A dataset for event coreference resolution in legal documents , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[72]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Agentscourt: Building judicial decision-making agents with court debate simulation and legal knowledge augmentation , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[73]
ACM Transactions on Information Systems , volume=
A survey of conversational search , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[74]
legal model
What's law got to do with it? Judicial behavioralists test the “legal model” of judicial decision making , author=. Law & social inquiry , volume=. 2001 , publisher=
2001
-
[75]
Oxford journal of legal studies , volume=
AI and transparency in judicial decision making , author=. Oxford journal of legal studies , volume=. 2026 , publisher=
2026
-
[76]
ACM Computing Surveys , volume=
Natural language processing for the legal domain: A survey of tasks, datasets, models, and challenges , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[77]
1958 , publisher=
Automation in the legal world , author=. 1958 , publisher=
1958
-
[78]
Information Processing & Management , volume=
A multi-agent framework with legal event logic graph for multi-defendant legal judgment prediction , author=. Information Processing & Management , volume=. 2026 , publisher=
2026
-
[79]
Information Processing & Management , volume=
Augmented graph information bottleneck with type-aware periodicity heterogeneity for explainable crime prediction , author=. Information Processing & Management , volume=. 2025 , publisher=
2025
-
[80]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Towards explainability in legal outcome prediction models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.