Stream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors
Pith reviewed 2026-06-27 22:47 UTC · model grok-4.3
The pith
Stream3D-VLM processes streaming video for real-time 3D spatial understanding by adding geometry priors incrementally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
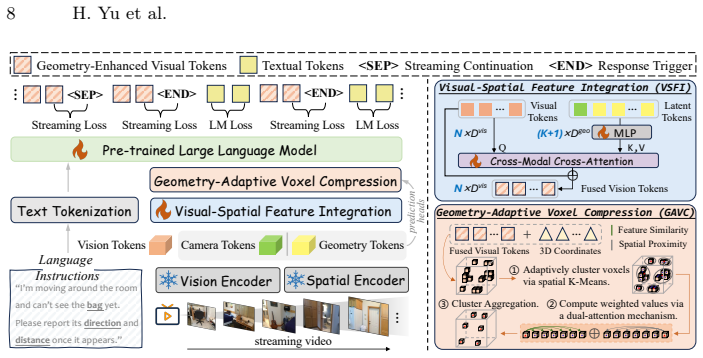
An autoregressive streaming control model based on the LLM next-token objective, combined with a Visual-Spatial Feature Integration module that injects temporally aligned geometry priors and a Geometry-Adaptive Voxel Compression module, enables real-time 3D spatial understanding, reasoning, and grounding from streaming video; this is supported by a generated set of over 1M online spatio-temporal 3D QA pairs and a 29-task benchmark, yielding performance gains over existing proprietary and open-source models.
What carries the argument
The Visual-Spatial Feature Integration (VSFI) module, which incrementally injects temporally aligned geometry priors into the visual stream while the model runs autoregressively.
If this is right
- The approach supports continuous scene updates required for live robotics or augmented-reality applications.
- The Geometry-Adaptive Voxel Compression module reduces decoding cost for long visual sequences without retraining the base LLM.
- The 29-task benchmark and 1M-pair dataset provide standardized evaluation for future online 3D models.
- Performance gains hold across both online streaming and conventional offline 3D tasks.
Where Pith is reading between the lines
- The same incremental-prior pattern could be tested on other streaming modalities such as audio or depth-only input.
- The data-generation pipeline might be reused to create training sets for online tasks outside 3D vision-language models.
- If the geometry priors prove robust, similar lightweight integration modules could be added to existing offline 3D models to convert them to streaming versions.
Load-bearing premise
The generated 1M online spatio-temporal 3D QA pairs and the incremental geometry priors from VSFI accurately capture real-world streaming conditions without distribution shift or loss of critical spatial information.
What would settle it
Running the model on raw camera streams from uncontrolled real environments and measuring whether accuracy on spatial grounding and reasoning drops below offline baselines or shows no gain over prior methods.
Figures


read the original abstract
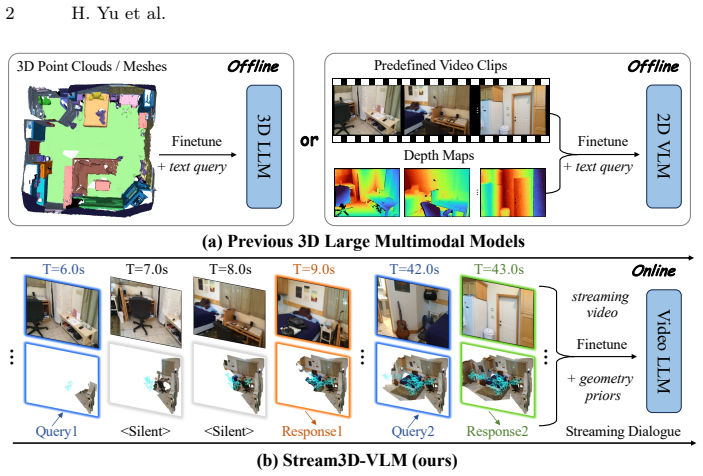
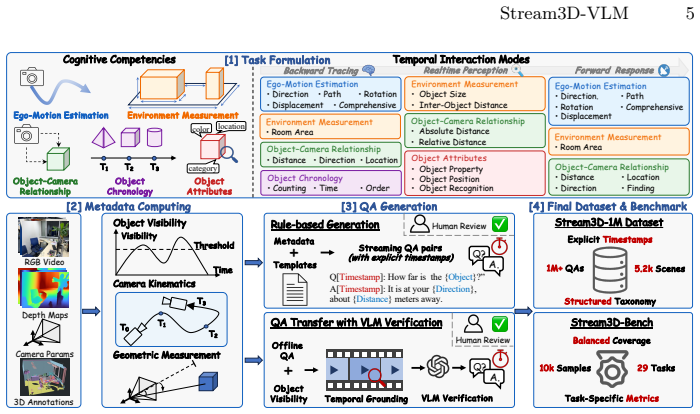
Despite advances in 3D scene understanding, existing 3D Large Multimodal Models operate in offline settings, requiring complete scene observations or predefined video clips. In this paper, we present an online 3D vision-language model that enables real-time spatial understanding from streaming video. Our approach adopts an autoregressive streaming control modeling based on the LLM's next-token prediction objective to learn when to respond, and employs a lightweight Visual-Spatial Feature Integration (VSFI) module to incrementally inject temporally aligned geometry priors into the visual stream. To alleviate long-context decoding overhead, we propose a plug-and-play Geometry-Adaptive Voxel Compression (GAVC) module for efficient visual token compression. To address the scarcity of streaming 3D-language data, we further develop a scalable data generation pipeline that curates over 1M online spatio-temporal 3D QA pairs and establishes a comprehensive benchmark spanning 29 tasks. Extensive experiments show that our approach significantly outperforms both proprietary and open-source models across online and offline 3D spatial understanding, reasoning, and grounding tasks. The project page is available at https://stream3d-vlm.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Stream3D-VLM, an online 3D vision-language model for real-time spatial understanding from streaming video inputs. It uses autoregressive streaming control modeling (via LLM next-token prediction) to decide response timing, a lightweight VSFI module to incrementally inject temporally aligned geometry priors, a GAVC module for geometry-adaptive voxel compression to reduce long-context overhead, and a scalable pipeline that generates >1M synthetic online spatio-temporal 3D QA pairs to create a 29-task benchmark. The central claim is that the resulting model significantly outperforms both proprietary and open-source baselines on online and offline 3D spatial understanding, reasoning, and grounding tasks.
Significance. If the synthetic benchmark faithfully represents real streaming conditions, the work would address a clear gap in moving 3D VLMs from offline to online settings and could provide practical modules (VSFI, GAVC) for incremental geometry handling and efficiency. The scale of the generated benchmark is a potential contribution, but its unverified fidelity to real-world streaming distributions limits the assessed significance of the empirical claims.
major comments (2)
- [Data generation pipeline and Experiments section] The headline empirical result (significant outperformance across tasks) rests entirely on training and evaluation using the authors' self-generated 1M synthetic QA pairs. The data-generation pipeline description provides no quantitative validation (distribution statistics, real-vs-synthetic ablation, human realism ratings, or controls for partial observability/frame-rate jitter/sensor noise) that the synthetic distribution matches genuine streaming video; any mismatch directly undermines the generalization claim to real online settings.
- [Experiments section] Because every reported metric flows from a single synthetic distribution with no external real-world streaming test set or cross-distribution ablation, the claim that the method 'significantly outperforms ... across online and offline' tasks cannot be assessed for robustness; the manuscript must supply evidence that performance gains are not artifacts of the curation process.
minor comments (2)
- [Abstract and benchmark description] Clarify whether the 29-task benchmark includes any held-out real streaming video sequences or is entirely synthetic; this distinction should be stated explicitly in the abstract and benchmark description.
- [Experiments section] The abstract mentions 'extensive experiments' but does not reference specific tables or figures showing error bars, statistical significance tests, or ablation on the VSFI/GAVC components; ensure these are present and clearly labeled in the full manuscript.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our work. We address each major comment below and outline planned revisions to strengthen the validation of our synthetic benchmark and the robustness of our empirical claims.
read point-by-point responses
-
Referee: [Data generation pipeline and Experiments section] The headline empirical result (significant outperformance across tasks) rests entirely on training and evaluation using the authors' self-generated 1M synthetic QA pairs. The data-generation pipeline description provides no quantitative validation (distribution statistics, real-vs-synthetic ablation, human realism ratings, or controls for partial observability/frame-rate jitter/sensor noise) that the synthetic distribution matches genuine streaming video; any mismatch directly undermines the generalization claim to real online settings.
Authors: We thank the referee for highlighting this important aspect. The data generation pipeline is designed to replicate streaming conditions by processing video frames incrementally and generating QA pairs that account for partial observability and temporal dynamics. However, the manuscript indeed lacks explicit quantitative validations such as distribution statistics or human realism ratings. We will revise the manuscript to include these: specifically, we will report statistical comparisons between synthetic and real streaming video features (e.g., motion patterns, object densities) and conduct a human evaluation study on a sample of the QA pairs to assess perceived realism. This will provide evidence supporting the fidelity of the synthetic data. revision: yes
-
Referee: [Experiments section] Because every reported metric flows from a single synthetic distribution with no external real-world streaming test set or cross-distribution ablation, the claim that the method 'significantly outperforms ... across online and offline' tasks cannot be assessed for robustness; the manuscript must supply evidence that performance gains are not artifacts of the curation process.
Authors: We agree that demonstrating robustness beyond a single distribution is crucial. Our current benchmark incorporates variations in streaming parameters within the synthetic generation process, such as different frame rates and levels of partial observability, to simulate diverse conditions. To further address this, we will add cross-distribution ablations in the revised version by training and evaluating on subsets with altered generation parameters. Regarding an external real-world test set, while we recognize its value, no such large-scale annotated streaming 3D QA dataset is publicly available, limiting our ability to include it at this time. revision: partial
- Absence of a public real-world streaming 3D spatio-temporal QA benchmark for external validation.
Circularity Check
No circularity in claimed results; empirical performance on self-generated benchmark does not reduce to definitional equivalence
full rationale
The paper presents an empirical ML system for online 3D VLM with a new data-generation pipeline and benchmark of 1M QA pairs. No equations, derivations, or first-principles claims appear in the provided text that would allow any result to reduce to its inputs by construction. The central performance claim rests on comparative experiments rather than internal redefinition, fitted parameters renamed as predictions, or load-bearing self-citations. The data pipeline and VSFI/GAVC modules are architectural choices whose validity is external to any self-referential loop. This is the normal case of an applied paper whose claims are falsifiable against external data distributions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Azuma, D., Miyanishi, T., Kurita, S., Kawanabe, M.: Scanqa: 3d question answer- ing for spatial scene understanding. In: proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19129–19139 (2022)
2022
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Baruch, G., Chen, Z., Dehghan, A., Dimry, T., Feigin, Y., Fu, P., Gebauer, T., Joffe, B., Kurz, D., Schwartz, A., et al.: Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data. arXiv preprint arXiv:2111.08897 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
In: European conference on computer vision
Chen, D.Z., Chang, A.X., Nießner, M.: Scanrefer: 3d object localization in rgb-d scans using natural language. In: European conference on computer vision. pp. 202–221. Springer (2020)
2020
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Lv, Z., Wu, S., Lin, K.Q., Song, C., Gao, D., Liu, J.W., Gao, Z., Mao, D., Shou, M.Z.: Videollm-online: Online video large language model for streaming video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18407–18418 (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Chen, Z., Gholami, A., Nießner, M., Chang, A.X.: Scan2cap: Context-aware dense captioning in rgb-d scans. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 3193–3203 (2021)
2021
-
[8]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828–5839 (2017)
2017
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Deng, J., He, T., Jiang, L., Wang, T., Dayoub, F., Reid, I.: 3d-llava: Towards gener- alist 3d lmms with omni superpoint transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3772–3782 (2025)
2025
-
[11]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Fan, Z., Zhang, J., Li, R., Zhang, J., Chen, R., Hu, H., Wang, K., Qu, H., Wang, D., Yan, Z., et al.: Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction. arXiv preprint arXiv:2505.20279 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Fu, R., Liu, J., Chen, X., Nie, Y., Xiong, W.: Scene-llm: Extending language model for 3d visual reasoning. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 2195–2206. IEEE (2025)
2025
-
[13]
Advances in Neural Information Processing Systems36, 20482–20494 (2023)
Hong, Y., Zhen, H., Chen, P., Zheng, S., Du, Y., Chen, Z., Gan, C.: 3d-llm: In- jecting the 3d world into large language models. Advances in Neural Information Processing Systems36, 20482–20494 (2023)
2023
-
[14]
Hu, W., Lin, J., Long, Y., Ran, Y., Jiang, L., Wang, Y., Zhu, C., Xu, R., Wang, T., Pang, J.: G2vlm: Geometry grounded vision language model with unified 3d reconstruction and spatial reasoning. arXiv preprint arXiv:2511.21688 (2025)
-
[15]
arXiv preprint arXiv:2506.09935 (2025) 16 H
Huang, J., Ma, X., Linghu, X., Fan, Y., He, J., Tan, W., Li, Q., Zhu, S.C., Chen, Y., Jia, B., et al.: Leo-vl: Towards 3d vision-language generalists via data scaling with efficient representation. arXiv preprint arXiv:2506.09935 (2025) 16 H. Yu et al
-
[16]
In: Proceedings of the 41st International Conference on Machine Learning
Huang, J., Yong, S., Ma, X., Linghu, X., Li, P., Wang, Y., Li, Q., Zhu, S.C., Jia, B., Huang, S.: An embodied generalist agent in 3d world. In: Proceedings of the 41st International Conference on Machine Learning. pp. 20413–20451 (2024)
2024
-
[17]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Huang, X., Wu, J., Xie, Q., Han, K.: 3drs: Mllms need 3d-aware representation supervision for scene understanding. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[18]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Huang, Z., Li, X., Li, J., Wang, J., Zeng, X., Liang, C., Wu, T., Chen, X., Li, L., Wang, L.: Online video understanding: Ovbench and videochat-online. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 3328–3338 (2025)
2025
-
[19]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
arXiv preprint arXiv:2512.12560 (2025)
Jin, X., Yu, H., Yu, B., Liu, K., Liu, J., Tao, K., Pei, Y., Wang, H., Dang, F., Liu, J., et al.: Streamingassistant: Efficient visual token pruning for accelerating online video understanding. arXiv preprint arXiv:2512.12560 (2025)
-
[21]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kang, W., Huang, H., Shang, Y., Shah, M., Yan, Y.: Robin3d: Improving 3d large language model via robust instruction tuning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3905–3915 (2025)
2025
-
[22]
arXiv preprint arXiv:2508.10893 (2025)
Lan,Y.,Luo,Y.,Hong,F.,Zhou,S.,Chen,H.,Lyu,Z.,Yang,S.,Dai,B.,Loy,C.C., Pan, X.: Stream3r: Scalable sequential 3d reconstruction with causal transformer. arXiv preprint arXiv:2508.10893 (2025)
-
[23]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
arXiv preprint arXiv:2507.07984 (2025)
Lin, J., Zhu, C., Xu, R., Mao, X., Liu, X., Wang, T., Pang, J.: Ost-bench: Evaluat- ing the capabilities of mllms in online spatio-temporal scene understanding. arXiv preprint arXiv:2507.07984 (2025)
-
[26]
arXiv preprint arXiv:2412.08646 (2024)
Liu, J., Yu, Z., Lan, S., Wang, S., Fang, R., Kautz, J., Li, H., Alvare, J.M.: Stream- chat: Chatting with streaming video. arXiv preprint arXiv:2412.08646 (2024)
-
[27]
OpenAI.: Gpt-5 system card (2025),https://cdn.openai.com/gpt-5-system- card.pdf
2025
-
[28]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Ouyang, K., Liu, Y., Wu, H., Liu, Y., Zhou, H., Zhou, J., Meng, F., Sun, X.: Spacer: Reinforcing mllms in video spatial reasoning. arXiv preprint arXiv:2504.01805 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
arXiv preprint arXiv:2501.01428 (2025)
Qi, Z., Zhang, Z., Fang, Y., Wang, J., Zhao, H.: Gpt4scene: Understand 3d scenes from videos with vision-language models. arXiv preprint arXiv:2501.01428 (2025)
-
[30]
arXiv preprint arXiv:2601.01204 (2026)
Su,Z.,Ye,W.,Feng,H.,Fan,K.,Zhang,J.,Yu,D.,Liu,Z.,Wong,N.:Xstreamvggt: Extremely memory-efficient streaming vision geometry grounded transformer with kv cache compression. arXiv preprint arXiv:2601.01204 (2026)
-
[31]
Tang, H., Zhang, C., Jin, M., Yu, Q., Wang, Z., Jin, X., Zhang, Y., Du, M.: Time seriesforecastingwithllms:Understandingandenhancingmodelcapabilities.ACM SIGKDD Explorations Newsletter26(2), 109–118 (2025)
2025
-
[32]
arXiv preprint arXiv:2504.01901 (2025) Stream3D-VLM 17
Wang, H., Zhao, Y., Wang, T., Fan, H., Zhang, X., Zhang, Z.: Ross3d: Reconstruc- tive visual instruction tuning with 3d-awareness. arXiv preprint arXiv:2504.01901 (2025) Stream3D-VLM 17
-
[33]
arXiv preprint arXiv:2511.18416 (2025)
Wang, H., Zhou, H., Liu, H., Yan, L.: 4d-vggt: A general foundation model with spatiotemporal awareness for dynamic scene geometry estimation. arXiv preprint arXiv:2511.18416 (2025)
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Q., Zhang, Y., Holynski, A., Efros, A.A., Kanazawa, A.: Continuous 3d perception model with persistent state. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10510–10522 (2025)
2025
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
In: 2025 IEEE International Conference on Multimedia and Expo (ICME)
Wang, X., Li, Z., Xu, Y., Qi, J., Yang, Z., Ma, R., Liu, X., Zhang, C.: Spatial 3d-llm: Exploring spatial awareness in 3d vision-language models. In: 2025 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2025)
2025
-
[38]
Advances in Neural Information Processing Systems37, 58118–58153 (2024)
Wang, X., Feng, M., Qiu, J., Gu, J., Zhao, J.: From news to forecast: Integrating event analysis in llm-based time series forecasting with reflection. Advances in Neural Information Processing Systems37, 58118–58153 (2024)
2024
-
[39]
N3d- vlm: Native 3d grounding enables accurate spatial reasoning in vision- language models,
Wang, Y., Ke, L., Zhang, B., Qu, T., Yu, H., Huang, Z., Yu, M., Xu, D., Yu, D.: N3d-vlm: Native 3d grounding enables accurate spatial reasoning in vision- language models. arXiv preprint arXiv:2512.16561 (2025)
-
[40]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 9797– 9817 (2024)
Wei, H., Tang, H., Jia, X., Wang, Z., Yu, H., Li, Z., Satoh, S., Van Gool, L., Wang, Z.: Physical adversarial attack meets computer vision: A decade survey. IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 9797– 9817 (2024)
2024
-
[41]
In: Pro- ceedings of the 31st ACM International Conference on Multimedia
Wei, H., Yu, H., Zhang, K., Wang, Z., Zhu, J., Wang, Z.: Moiré backdoor attack (mba): A novel trigger for pedestrian detectors in the physical world. In: Pro- ceedings of the 31st ACM International Conference on Multimedia. pp. 8828–8838 (2023)
2023
-
[42]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Wu, D., Liu, F., Hung, Y.H., Duan, Y.: Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. arXiv preprint arXiv:2505.23747 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Advances in Neural Information Processing Systems 37, 109922–109947 (2024)
Wu, S., Chen, J., Lin, K.Q., Wang, Q., Gao, Y., Xu, Q., Xu, T., Hu, Y., Chen, E., Shou, M.Z.: Videollm-mod: Efficient video-language streaming with mixture- of-depths vision computation. Advances in Neural Information Processing Systems 37, 109922–109947 (2024)
2024
-
[44]
In: European Conference on Computer Vision
Xu, R., Wang, X., Wang, T., Chen, Y., Pang, J., Lin, D.: Pointllm: Empowering large language models to understand point clouds. In: European Conference on Computer Vision. pp. 131–147. Springer (2024)
2024
-
[45]
In: European Conference on Computer Vision
Yan, T., Zeng, W., Xiao, Y., Tong, X., Tan, B., Fang, Z., Cao, Z., Zhou, J.T.: Crossglg: Llm guides one-shot skeleton-based 3d action recognition in a cross- level manner. In: European Conference on Computer Vision. pp. 113–131. Springer (2024)
2024
-
[46]
In: CVPR (2025)
Yang, J., Yang, S., Gupta, A., Han, R., Fei-Fei, L., Xie, S.: Thinking in Space: How Multimodal Large Language Models See, Remember and Recall Spaces. In: CVPR (2025)
2025
-
[47]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Yang, S., Chen, Y., Tian, Z., Wang, C., Li, J., Yu, B., Jia, J.: Visionzip: Longer is better but not necessary in vision language models. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 19792–19802 (2025)
2025
-
[48]
Cambrian-S: Towards Spatial Supersensing in Video
Yang, S., Yang, J., Huang, P., Brown, E., Yang, Z., Yu, Y., Tong, S., Zheng, Z., Xu, Y., Wang, M., Lu, D., Fergus, R., LeCun, Y., Fei-Fei, L., Xie, S.: Cambrian-s: Towards spatial supersensing in video. arXiv preprint arXiv:2511.04670 (2025) 18 H. Yu et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Yao, L., Li, Y., Wei, Y., Li, L., Ren, S., Liu, Y., Ouyang, K., Wang, L., Li, S., Li, S., et al.: Timechat-online: 80% visual tokens are naturally redundant in streaming videos. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10807–10816 (2025)
2025
-
[50]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12–22 (2023)
2023
-
[51]
arXiv preprint arXiv:2601.22674 (2026)
Yu, H., Li, W., Qu, X., Wang, S., Chen, J., Zhu, J.: Visiontrim: Unified vision token compression for training-free mllm acceleration. arXiv preprint arXiv:2601.22674 (2026)
-
[52]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Yu, H., Li, W., Wang, S., Chen, J., Zhu, J.: Inst3d-lmm: Instance-aware 3d scene understanding with multi-modal instruction tuning. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 14147–14157 (2025)
2025
-
[53]
Unlocking Dense Metric Depth Estimation in VLMs
Yu, H., Qu, X., Wang, Y., Zhu, J., Ke, L.: Unlocking dense metric depth estimation in vlms. arXiv preprint arXiv:2605.15876 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
arXiv preprint arXiv:2601.02281 (2026)
Yuan, S., Yang, Y., Yang, X., Zhang, X., Zhao, Z., Zhang, L., Zhang, Z.: In- finitevggt: Visual geometry grounded transformer for endless streams. arXiv preprint arXiv:2601.02281 (2026)
-
[55]
arXiv preprint arXiv:2503.22976 (2025)
Zhang, J., Chen, Y., Zhou, Y., Xu, Y., Huang, Z., Mei, J., Chen, J., Yuan, Y.J., Cai, X., Huang, G., et al.: From flatland to space: Teaching vision-language models to perceive and reason in 3d. arXiv preprint arXiv:2503.22976 (2025)
-
[56]
arXiv preprint arXiv:2511.23075 (2025)
Zhao, R., Zhang, Z., Xu, J., Chang, J., Chen, D., Li, L., Sun, W., Wei, Z.: Space- mind: Camera-guided modality fusion for spatial reasoning in vision-language mod- els. arXiv preprint arXiv:2511.23075 (2025)
-
[57]
arXiv preprint arXiv:2505.24625 (2025)
Zheng, D., Huang, S., Li, Y., Wang, L.: Learning from videos for 3d world: En- hancing mllms with 3d vision geometry priors. arXiv preprint arXiv:2505.24625 (2025)
-
[58]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhu, C., Wang, T., Zhang, W., Pang, J., Liu, X.: Llava-3d: A simple yet effec- tive pathway to empowering lmms with 3d capabilities. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4295–4305 (2025)
2025
-
[59]
Streaming 4D Visual Geometry Transformer
Zhuo, D., Zheng, W., Guo, J., Wu, Y., Zhou, J., Lu, J.: Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539 (2025) Stream3D-VLM 19 Supplementary Material In this part, we provide more details and additional experimental results on our approach. The supplementary material is organized as follows: •§ A: Metadata computing details; •§ B...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.