StainFlow: Entity-Stain Tracking and Evidence Linking for Process Rewards in GUI Agents
Pith reviewed 2026-06-27 22:22 UTC · model grok-4.3
The pith
StainFlow tracks entity stains to provide objective process rewards for GUI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
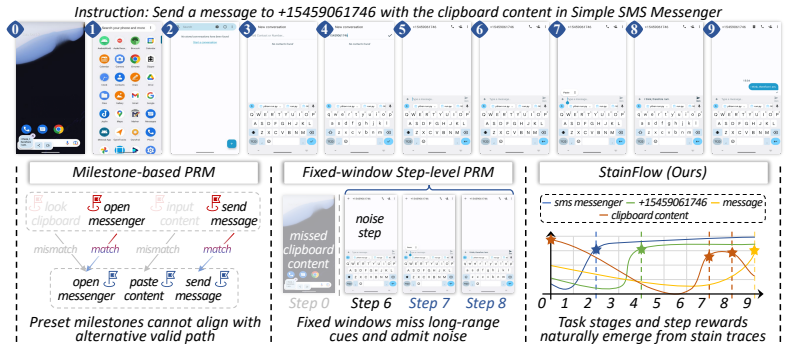
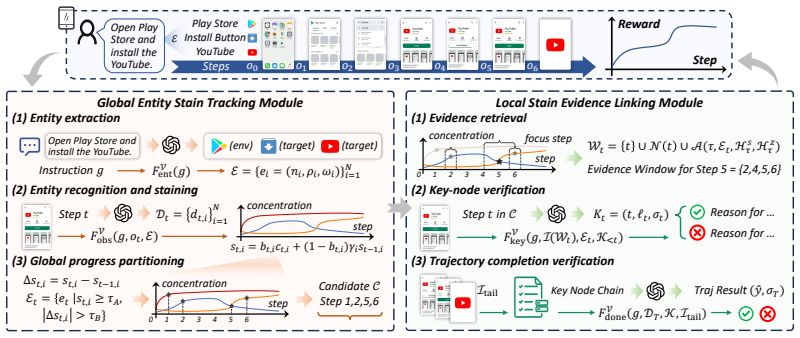
StainFlow introduces the Global Entity Stain Tracking module to extract visually verifiable task entities and monitor their stain concentrations and state evolutions for objective phase separation, along with the Local Stain Evidence Linking module that centers on triggering entities to retrieve stain-related steps and build high-density evidence windows.
What carries the argument
The entity-stain tracking mechanism that follows how task entities' visual stains change to separate phases and link evidence.
If this is right
- Online RL for GUI agents achieves a relative 3.2% improvement in success rates.
- Accuracy in judging trajectory completion rises by 1.8% on tested benchmarks.
- Multiple valid execution paths become accommodable through objective evidence flows rather than singular decompositions.
- Local verification avoids missing long-range evidence or diluting signals with irrelevant frames.
Where Pith is reading between the lines
- The stain tracking idea could apply to other sequential decision tasks with visual states if entity extraction generalizes.
- Agents might learn to plan by anticipating stain state transitions without explicit human-defined milestones.
- Combining this with existing PRMs could create hybrid rewards that balance global flow and local details.
Load-bearing premise
Changes in visually extracted entity stain concentrations and states can objectively separate task phases and construct high-density evidence windows without introducing new subjectivity or missing long-range dependencies.
What would settle it
A set of GUI trajectories where stain concentration changes fail to mark actual task progress points, causing the reward model to assign high rewards to failing paths or low rewards to successful ones.
Figures
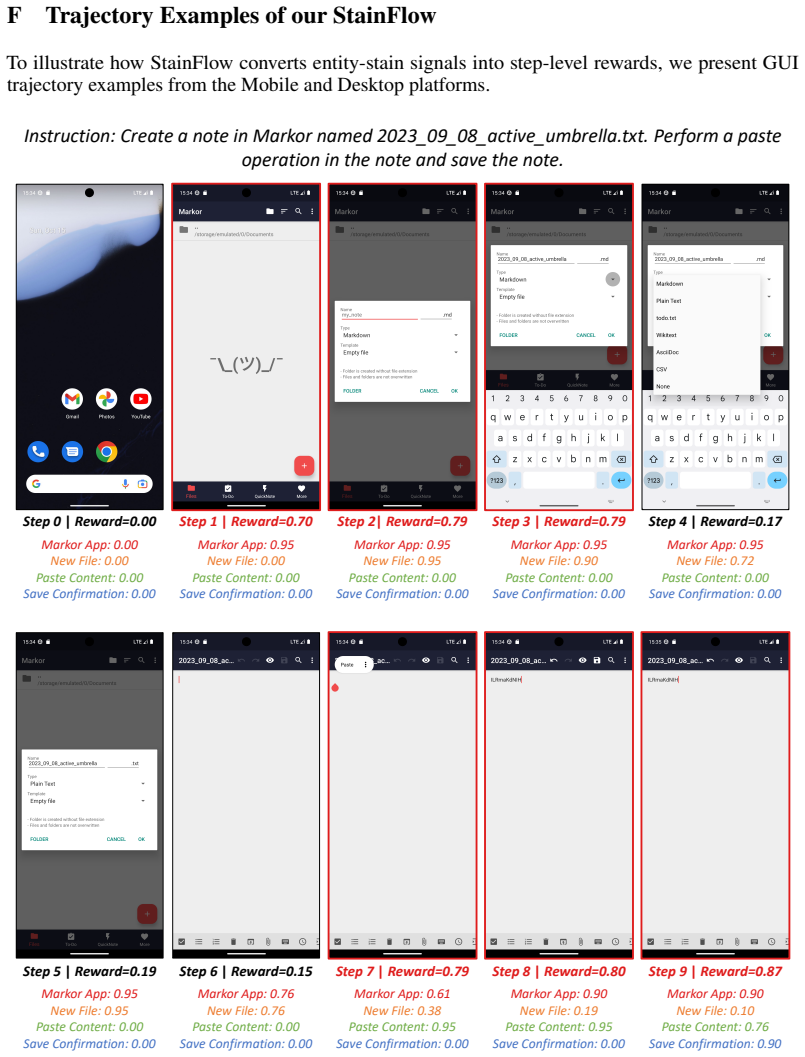
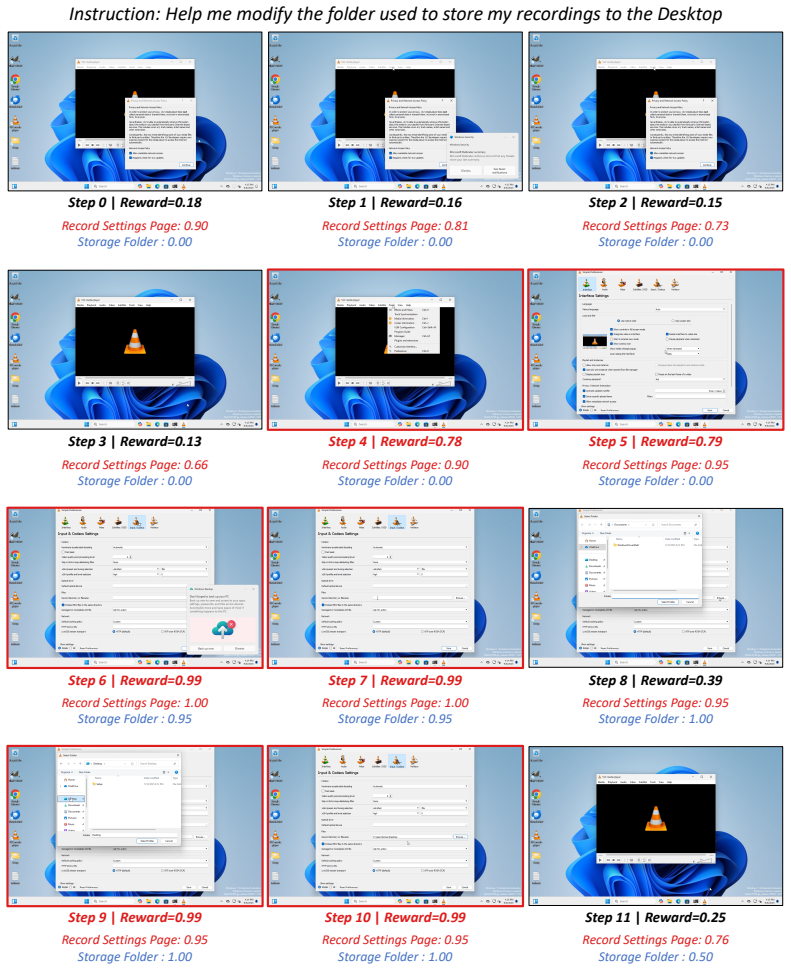
read the original abstract
Reinforcement Learning (RL) has become a promising approach for improving GUI Agents in long-horizon, stochastic digital environments, but trajectory-level success feedback is too sparse to provide reliable credit assignment for intermediate exploration steps. To mitigate this issue, recent studies introduce Process Reward Models (PRMs), which provide finer-grained training feedback through global milestone verification or local step-level evaluation. However, these methods still suffer from two level-specific limitations: global milestone decomposition is subjective and singular, making it difficult to accommodate the multiple valid execution paths in real GUI tasks, while fixed local judging windows may miss long-range key evidence or dilute the decision signal with irrelevant frames. Inspired by stain-tracing mechanisms in network flow analysis, we propose StainFlow, an entity-stain-flow process reward model for GUI Agents. To reduce the subjectivity of global partitioning, we introduce the Global Entity Stain Tracking module, which extracts visually verifiable task entities and tracks how their stain concentrations and states evolve along the trajectory, allowing task phases to be objectively separated by changes in the entity evidence flow. To improve the accuracy of local verification, we introduce the Local Stain Evidence Linking module. Centered on the triggering entities of each candidate key node, it retrieves relevant steps based on their stain concentrations and state changes, and dynamically constructs high-density evidence windows for verifying true key nodes. Extensive experiments on AndroidWorld and OGRBench show that StainFlow relatively improves online RL success by 3.2% and trajectory completion judgment accuracy by 1.8%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StainFlow, a process reward model for GUI agents that draws on network flow stain-tracing. The Global Entity Stain Tracking module extracts visually verifiable task entities and tracks their stain concentrations and states to separate task phases more objectively than subjective global milestone decomposition. The Local Stain Evidence Linking module uses stain concentrations and state changes around triggering entities to dynamically build high-density evidence windows, addressing limitations of fixed local judging windows. Experiments on AndroidWorld and OGRBench report relative gains of 3.2% in online RL success and 1.8% in trajectory completion judgment accuracy.
Significance. If the empirical claims hold under detailed scrutiny, the work addresses a genuine limitation in process supervision for long-horizon GUI agents by attempting to replace subjective partitioning with evidence-flow tracking. The network-flow analogy is a distinctive framing. The reported gains are modest, so the primary value would lie in whether the stain-based partitioning demonstrably reduces reliance on human-designed heuristics while preserving coverage of multiple valid paths.
major comments (3)
- [Global Entity Stain Tracking module] Global Entity Stain Tracking module (abstract and method description): the claim that phases are 'objectively separated by changes in the entity evidence flow' rests on extraction of 'visually verifiable task entities' and quantification of 'stain concentrations and states,' yet no formal definition, selection criteria, threshold, or algorithmic procedure is supplied. This directly undermines the central assertion that the approach reduces subjectivity relative to prior global milestone methods.
- [Local Stain Evidence Linking module] Local Stain Evidence Linking module (abstract and method description): the module 'retrieves relevant steps based on their stain concentrations and state changes' and 'dynamically constructs high-density evidence windows,' but the precise retrieval rule, handling of sparse or noisy stain signals, and mechanism for capturing long-range dependencies are unspecified. These details are load-bearing for the claimed improvement over fixed local windows.
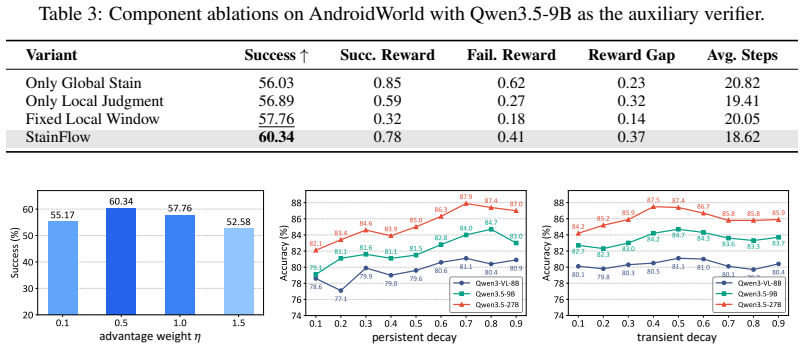
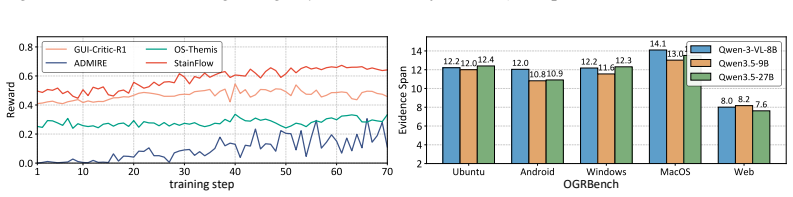
- [Experiments] Experimental results (abstract): the headline figures (3.2% relative RL success improvement, 1.8% judgment accuracy improvement) are stated without reference to any table, baseline methods, number of runs, statistical tests, or ablation isolating the contribution of each module. Without these, the numerical claims cannot be evaluated against the method's stated advantages.
minor comments (1)
- [Abstract] The abstract would be clearer if it explicitly referenced the tables or figures that report the 3.2% and 1.8% figures and listed the exact baselines used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we provide point-by-point responses to the major comments, indicating where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [Global Entity Stain Tracking module] Global Entity Stain Tracking module (abstract and method description): the claim that phases are 'objectively separated by changes in the entity evidence flow' rests on extraction of 'visually verifiable task entities' and quantification of 'stain concentrations and states,' yet no formal definition, selection criteria, threshold, or algorithmic procedure is supplied. This directly undermines the central assertion that the approach reduces subjectivity relative to prior global milestone methods.
Authors: We agree with the referee that the method description lacks a formal definition, selection criteria, threshold, or algorithmic procedure for the Global Entity Stain Tracking module. This is a valid point, and we will revise the manuscript to supply these details, including a mathematical formulation for stain concentrations and states, criteria for selecting visually verifiable entities, and the procedure for detecting changes in entity evidence flow to separate phases. revision: yes
-
Referee: [Local Stain Evidence Linking module] Local Stain Evidence Linking module (abstract and method description): the module 'retrieves relevant steps based on their stain concentrations and state changes' and 'dynamically constructs high-density evidence windows,' but the precise retrieval rule, handling of sparse or noisy stain signals, and mechanism for capturing long-range dependencies are unspecified. These details are load-bearing for the claimed improvement over fixed local windows.
Authors: We agree that the precise retrieval rule, handling of sparse or noisy signals, and long-range dependency mechanism for the Local Stain Evidence Linking module are not fully specified. We will revise to include these details, such as the rule for selecting steps based on stain concentration thresholds, use of smoothing for noisy signals, and propagation for long-range links. revision: yes
-
Referee: [Experiments] Experimental results (abstract): the headline figures (3.2% relative RL success improvement, 1.8% judgment accuracy improvement) are stated without reference to any table, baseline methods, number of runs, statistical tests, or ablation isolating the contribution of each module. Without these, the numerical claims cannot be evaluated against the method's stated advantages.
Authors: We acknowledge that the abstract states the headline figures without referencing tables, baselines, runs, tests, or ablations. The experimental section of the manuscript contains supporting results, but to improve clarity we will revise the abstract to include a reference to the results section and ensure all supporting information is explicitly linked in the text. Space constraints in the abstract limit full inclusion of every detail. revision: partial
Circularity Check
No circularity: heuristic analogy with empirical validation, no equations or self-referential reductions
full rationale
The paper introduces StainFlow via an external analogy to stain-tracing in network flow analysis and describes two modules (Global Entity Stain Tracking, Local Stain Evidence Linking) that operate on visually extracted entities and their state changes. No equations, parameter fits, predictions, or derivations appear in the provided text. Claims of reduced subjectivity and improved accuracy rest on empirical results from AndroidWorld and OGRBench rather than any mathematical reduction to inputs. No self-citations are invoked as load-bearing uniqueness theorems. The method is therefore self-contained as a proposed heuristic without circular derivation steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Entity stain concentration and state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning
Hao Bai, Yifei Zhou, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, and Aviral Kumar. Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 12461–12495. C...
2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Cong Chen, Kaixiang Ji, Hao Zhong, Muzhi Zhu, Anzhou Li, Guo Gan, Ziyuan Huang, Cheng Zou, Jiajia Liu, Jingdong Chen, et al. Gui-shepherd: Reliable process reward and verification for long-sequence gui tasks.arXiv preprint arXiv:2509.23738, 2025
-
[4]
Seeclick: Harnessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 9313–9332, 2024
2024
-
[5]
arXiv preprint arXiv:2502.10325 , year=
Sanjiban Choudhury. Process reward models for llm agents: Practical framework and directions. arXiv preprint arXiv:2502.10325, 2025
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Chaoqun Cui, Jing Huang, Shijing Wang, Liming Zheng, Qingchao Kong, and Zhixiong Zeng. Agentic reward modeling: Verifying gui agent via online proactive interaction.arXiv preprint arXiv:2602.00575, 2026
-
[8]
ProRe: A Proactive Reward System for GUI Agents via Reasoner-Actor Collaboration
Gaole Dai, Shiqi Jiang, Ting Cao, Yuqing Yang, Yuanchun Li, Rui Tan, Mo Li, and Lili Qiu. Prore: A proactive reward system for gui agents via reasoner-actor collaboration.arXiv preprint arXiv:2509.21823, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Ruiyi Ding, Yongxuan Lv, Xianhui Meng, Jiahe Song, Chao Wang, Chen Jiang, and Yuan Cheng. Prpo: Aligning process reward with outcome reward in policy optimization.arXiv preprint arXiv:2601.07182, 2026
-
[10]
Group-in-group policy optimization for llm agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume 38, pages 46375–46408. Curran Associates, Inc., 2025
2025
-
[11]
Assistgui: Task-oriented pc graphical user interface automation
Difei Gao, Lei Ji, Zechen Bai, Mingyu Ouyang, Peiran Li, Dongxing Mao, Qinchen Wu, Weichen Zhang, Peiyi Wang, Xiangwu Guo, et al. Assistgui: Task-oriented pc graphical user interface automation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13289–13298, 2024. 10
2024
-
[12]
Zhangxuan Gu, Zhengwen Zeng, Zhenyu Xu, Xingran Zhou, Shuheng Shen, Yunfei Liu, Beitong Zhou, Changhua Meng, Tianyu Xia, Weizhi Chen, et al. Ui-venus technical report: Building high-performance ui agents with rft.arXiv preprint arXiv:2508.10833, 2025
-
[13]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14281–14290, 2024
2024
-
[14]
Peng Kuang, Xiangxiang Wang, Wentao Liu, Jian Dong, and Kaidi Xu. Tim-prm: Verifying multimodal reasoning with tool-integrated prm.arXiv preprint arXiv:2511.22998, 2025
-
[15]
Zehao Li, Zhenyu Wu, Yibo Zhao, Bowen Yang, Jingjing Xie, Zhaoyang Liu, Zhoumianze Liu, Kaiming Jin, Jianze Liang, Zonglin Li, et al. Os-themis: A scalable critic framework for generalist gui rewards.arXiv preprint arXiv:2603.19191, 2026
-
[16]
Fanbin Lu, Zhisheng Zhong, Shu Liu, Chi-Wing Fu, and Jiaya Jia. Arpo: End-to-end policy optimization for gui agents with experience replay.arXiv preprint arXiv:2505.16282, 2025
-
[17]
Xing Han Lù, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Ale- jandra Zambrano, Karolina Sta´nczak, Peter Shaw, Christopher J Pal, and Siva Reddy. Agen- trewardbench: Evaluating automatic evaluations of web agent trajectories.arXiv preprint arXiv:2504.08942, 2025
-
[18]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Coloring the internet: Ip traceback
Muthusrinivasan Muthuprasanna, G Manimaran, Mansoor Alicherry, and Vijay Kumar. Coloring the internet: Ip traceback. In12th International Conference on Parallel and Distributed Systems- (ICPADS’06), volume 1, pages 8–pp. IEEE, 2006
2006
-
[20]
Agentic reward modeling: Integrating human preferences with verifiable correctness signals for reliable reward systems
Hao Peng, Yunjia Qi, Xiaozhi Wang, Zijun Yao, Bin Xu, Lei Hou, and Juanzi Li. Agentic reward modeling: Integrating human preferences with verifiable correctness signals for reliable reward systems. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 15934–15949, 2025
2025
-
[21]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Network support for ip traceback.IEEE/ACM transactions on networking, 9(3):226–237, 2001
Stefan Savage, David Wetherall, Anna Karlin, and Tom Anderson. Network support for ip traceback.IEEE/ACM transactions on networking, 9(3):226–237, 2001
2001
-
[23]
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for llm reasoning.arXiv preprint arXiv:2410.08146, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Yucheng Shi, Wenhao Yu, Zaitang Li, Yonglin Wang, Hongming Zhang, Ninghao Liu, Haitao Mi, and Dong Yu. Mobilegui-rl: Advancing mobile gui agent through reinforcement learning in online environment.arXiv preprint arXiv:2507.05720, 2025
-
[26]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 9426–9439, 2024
2024
-
[30]
Gui agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890, 2024
Shuai Wang, Weiwen Liu, Jingxuan Chen, Yuqi Zhou, Weinan Gan, Xingshan Zeng, Yuhan Che, Shuai Yu, Xinlong Hao, Kun Shao, et al. Gui agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890, 2024
-
[31]
Taiyi Wang, Zhihao Wu, Jianheng Liu, Jianye Hao, Jun Wang, and Kun Shao. Distrl: An asynchronous distributed reinforcement learning framework for on-device control agents.arXiv preprint arXiv:2410.14803, 2024
-
[32]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, et al. Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
-
[33]
Look before you leap: A gui-critic-r1 model for pre-operative error diagnosis in gui automation
Yuyang Wanyan, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Jiabo Ye, Yutong Kou, Ming Yan, Fei Huang, Xiaoshan Yang, Weiming Dong, and Changsheng Xu. Look before you leap: A gui-critic-r1 model for pre-operative error diagnosis in gui automation. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Ne...
2025
-
[34]
Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Qiushi Sun, Zhaoyang Liu, Zhoumianze Liu, Yu Qiao, Xiangyu Yue, Zun Wang, et al. Os-oracle: A comprehensive framework for cross-platform gui critic models.arXiv preprint arXiv:2512.16295, 2025
-
[35]
Agentprm: Process reward models for llm agents via step-wise promise and progress
Zhiheng Xi, Chenyang Liao, Guanyu Li, Zhihao Zhang, Wenxiang Chen, Binghai Wang, Senjie Jin, Yuhao Zhou, Jian Guan, Wei Wu, et al. Agentprm: Process reward models for llm agents via step-wise promise and progress. InProceedings of the ACM Web Conference 2026, pages 4184–4195, 2026
2026
-
[36]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[37]
Gui-pra: Process reward agent for gui tasks.arXiv preprint arXiv:2509.23263, 2025
Tao Xiong, Xavier Hu, Yurun Chen, Yuhang Liu, Changqiao Wu, Pengzhi Gao, Wei Liu, Jian Luan, and Shengyu Zhang. Gui-pra: Process reward agent for gui tasks.arXiv preprint arXiv:2509.23263, 2025
-
[38]
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents.arXiv preprint arXiv:2602.16855, 2026
-
[39]
Taofeng Xue, Chong Peng, Mianqiu Huang, Linsen Guo, Tiancheng Han, Haozhe Wang, Jianing Wang, Xiaocheng Zhang, Xin Yang, Dengchang Zhao, et al. Evocua: Evolving computer use agents via learning from scalable synthetic experience.arXiv preprint arXiv:2601.15876, 2026
-
[40]
Zerogui: Automating online gui learning at zero human cost
Chenyu Yang, Shiqian Su, Shi Liu, Xuan Dong, Yue Yu, Weijie Su, Xuehui Wang, Zhaoyang Liu, Jinguo Zhu, Hao Li, et al. Zerogui: Automating online gui learning at zero human cost. arXiv preprint arXiv:2505.23762, 2025
-
[41]
Progrm: Build better gui agents with progress rewards.arXiv preprint arXiv:2505.18121, 2025
Danyang Zhang, Situo Zhang, Ziyue Yang, Zichen Zhu, Zihan Zhao, Ruisheng Cao, Lu Chen, and Kai Yu. Progrm: Build better gui agents with progress rewards.arXiv preprint arXiv:2505.18121, 2025
-
[42]
Adaptive milestone reward for gui agents
Congmin Zheng, Xiaoyun Mo, Xinbei Ma, Qiqiang Lin, Yin Zhao, Jiachen Zhu, Xingyu Lou, Jun Wang, Zhaoxiang Wang, Weiwen Liu, et al. Adaptive milestone reward for gui agents. arXiv preprint arXiv:2602.11524, 2026. 12
-
[43]
Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, et al. Mai-ui technical report: Real-world centric foundation gui agents.arXiv preprint arXiv:2512.22047, 2025
-
[44]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 13 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
task completed
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
-
[46]
Visible screen state in the candidate screenshot
-
[47]
Neighbor/support screenshots that clarify before-after state or later confirmation
-
[48]
Triggering entity states and resolved values
-
[49]
Previously verified key nodes, used to judge novelty
-
[50]
is_key_node
Candidate action or raw model response, only as intent context, never as proof. Accept if - The candidate establishes a new task-relevant state not already captured by earlier key nodes. - A persistent entity reaches or reveals a task-relevant state, such as entering the correct app, page, dialog, workspace, folder, settings view, or result page. - A tran...
-
[51]
Entity final snapshot and concrete resolved values
-
[52]
Verified key node chain
-
[53]
Recent change summaries
-
[54]
Tail screenshots, if attached, as a sanity check
-
[55]
only", "just
Final action/raw response only for locating submitted answers, not as success proof. General decision rules - Parse every task-defining attribute from the query: target names, values, counts, files, dates, states, formats, destinations, and prohibitions. - Mark each attribute as satisfied, violated, or unverifiable using the evidence hierarchy. - Completi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.