Seeing Without Exposing: Adaptive Privacy Control for Open-World, Context-Hungry MLLMs
Pith reviewed 2026-06-27 22:01 UTC · model grok-4.3
The pith
Anchored Privacy Drifting replaces sensitive image elements with equivalent alternatives while anchoring context for MLLM tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Anchored Privacy Drifting (APD) identifies privacy-sensitive regions in an input image, substitutes them with semantically equivalent alternatives, and anchors the remaining contextual elements to the source image so that downstream MLLM reasoning retains necessary visual information. When evaluated on the AdaptShield benchmark spanning 22 privacy categories, the method produces balanced gains: 10.4 percent on textual privacy metrics and 8.5 percent under MLLM-based contextual utility assessment, and these gains hold across Qwen2.5, Qwen3, InternVL3, and InternVL3.5 without any model training.
What carries the argument
Anchored Privacy Drifting (APD), a training-free substitution process that drifts privacy-sensitive image elements to semantically equivalent alternatives while anchoring contextual cues to the source image.
If this is right
- Privacy sanitization improves by an average of 10.4 percent on textual categories across the tested models.
- Contextual utility for MLLM tasks improves by an average of 8.5 percent under direct model-based evaluation.
- The same gains appear across four distinct MLLM families without requiring any retraining.
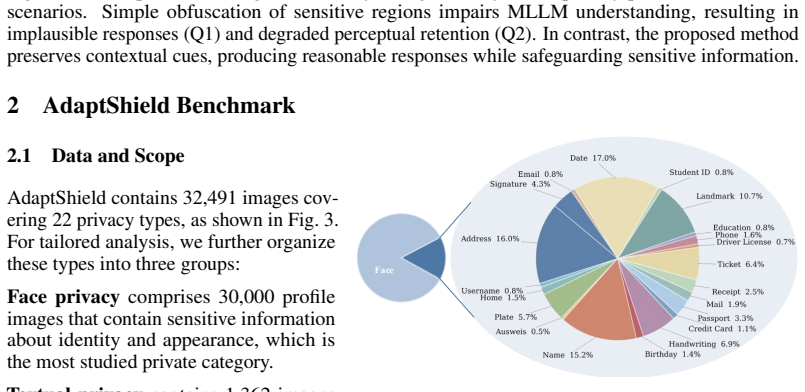
- The AdaptShield benchmark supplies a combined conventional-plus-MLLM evaluation protocol covering 22 privacy categories.
Where Pith is reading between the lines
- If semantic substitution scales reliably, APD could be inserted into existing MLLM inference pipelines as a lightweight pre-processing step.
- The anchoring mechanism may generalize to other modalities where context must survive privacy edits, such as video or document images.
- Users could tune the drift threshold per image to trade privacy strength against task accuracy on a case-by-case basis.
Load-bearing premise
Suitable semantically equivalent alternatives can be located and substituted without either reintroducing privacy risks or removing the exact contextual cues the downstream MLLM task requires.
What would settle it
Applying APD to images in the AdaptShield benchmark produces either unchanged or worse privacy-leakage scores or a measurable drop in MLLM task accuracy compared with the unmodified images.
Figures

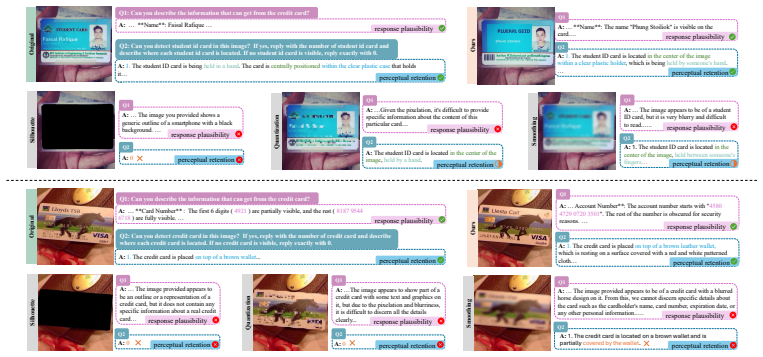




read the original abstract
Multimodal large language models (MLLMs) have raised new privacy challenges. On the data side, user-provided inputs often include unpredictable sensitive information; while on the downstream task side, model reasoning depends on rich visual context that may itself be privacy-sensitive. Existing privacy protection methods, however, rely on predefined sensitive categories and fixed obfuscation strategies, struggling to tackle such challenges in MLLMs. To address this dilemma, we propose Anchored Privacy Drifting (APD), a training-free method that drifts privacy-sensitive elements toward semantically equivalent alternatives while anchoring contextual cues to the source image. To systematically evaluate this dual objective of privacy protection and contextual preservation, we introduce AdaptShield, a comprehensive benchmark covering 22 privacy categories, which combines conventional privacy metrics with MLLM-based assessments of contextual utility. Extensive experiments show that our method achieves balanced improvements in both privacy sanitization and content retention, with average gains of 10.4% on textual categories and 8.5% under MLLM-based evaluation across four MLLM series, i.e., Qwen2.5, Qwen3, InternVL3, and InternVL3.5.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Anchored Privacy Drifting (APD), a training-free method that drifts privacy-sensitive elements in MLLM inputs toward semantically equivalent alternatives while anchoring contextual cues from the source image. It introduces the AdaptShield benchmark spanning 22 privacy categories and combines conventional privacy metrics with MLLM-based evaluations of contextual utility. Experiments across Qwen2.5, Qwen3, InternVL3, and InternVL3.5 report average gains of 10.4% on textual categories and 8.5% under MLLM-based evaluation, claiming balanced improvements in privacy sanitization and content retention.
Significance. If the central claims hold, the work would supply a practical, training-free mechanism for handling unpredictable sensitive content in open-world MLLM use cases where downstream reasoning requires rich visual context. The AdaptShield benchmark could serve as a reusable evaluation resource for privacy-utility trade-offs. The training-free design and dual-objective evaluation are explicit strengths that distinguish the contribution from category-fixed obfuscation baselines.
major comments (3)
- [Method] Method section: The APD drifting procedure is described only at the level of 'drifting privacy-sensitive elements toward semantically equivalent alternatives' with no specification of the equivalence computation (model, embedding, or prompt used for substitution generation). This detail is load-bearing for the claim that the method simultaneously avoids privacy reintroduction and preserves task-critical context, yet the abstract and method description provide no implementation or enforcement mechanism.
- [Experiments] Experiments and evaluation: The reported 10.4% textual and 8.5% MLLM-based gains are presented without error bars, dataset-construction steps for AdaptShield, or ablations isolating the anchoring component versus the drifting component. These omissions directly affect assessment of whether the balanced-improvement result is robust or sensitive to unreported choices in the drifting step.
- [Benchmark] Benchmark section: AdaptShield is introduced with 22 privacy categories and MLLM-based contextual-utility assessment, but the paper supplies no description of category selection criteria, how sensitive regions are localized, or the exact prompting protocol used for the MLLM evaluators. Without these, the MLLM-based metric cannot be reproduced or compared to the conventional metrics.
minor comments (1)
- [Abstract] Abstract: The model list 'Qwen2.5, Qwen3, InternVL3, and InternVL3.5' contains an apparent duplication of InternVL3; clarify the exact four series evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: [Method] Method section: The APD drifting procedure is described only at the level of 'drifting privacy-sensitive elements toward semantically equivalent alternatives' with no specification of the equivalence computation (model, embedding, or prompt used for substitution generation). This detail is load-bearing for the claim that the method simultaneously avoids privacy reintroduction and preserves task-critical context, yet the abstract and method description provide no implementation or enforcement mechanism.
Authors: We agree that the current description is high-level and insufficient for full reproducibility. In the revision we will expand the Method section with the precise equivalence computation (including the embedding model, similarity threshold, and prompt templates used to generate substitutions), along with the mechanism that enforces semantic equivalence while preventing privacy reintroduction. revision: yes
-
Referee: [Experiments] Experiments and evaluation: The reported 10.4% textual and 8.5% MLLM-based gains are presented without error bars, dataset-construction steps for AdaptShield, or ablations isolating the anchoring component versus the drifting component. These omissions directly affect assessment of whether the balanced-improvement result is robust or sensitive to unreported choices in the drifting step.
Authors: We will add error bars to all reported gains, provide a step-by-step account of AdaptShield dataset construction, and include new ablation experiments that separately disable the anchoring and drifting components to quantify their individual contributions and demonstrate robustness. revision: yes
-
Referee: [Benchmark] Benchmark section: AdaptShield is introduced with 22 privacy categories and MLLM-based contextual-utility assessment, but the paper supplies no description of category selection criteria, how sensitive regions are localized, or the exact prompting protocol used for the MLLM evaluators. Without these, the MLLM-based metric cannot be reproduced or compared to the conventional metrics.
Authors: We will augment the Benchmark section with the category selection criteria, the localization procedure for sensitive regions, and the complete prompting protocol (including system prompts and output parsing) used by the MLLM evaluators, enabling direct reproduction and comparison with conventional metrics. revision: yes
Circularity Check
No circularity: training-free method and new benchmark are independently specified with no fitted parameters or self-referential derivations
full rationale
The paper presents APD as a training-free procedure for semantic drifting with anchoring, and introduces AdaptShield as a new benchmark with 22 categories. No equations, fitted parameters, or predictions derived from prior self-results appear in the provided text. The reported gains (10.4% textual, 8.5% MLLM-based) are empirical outcomes on the introduced benchmark rather than quantities forced by construction or reduced to self-citations. The central claim therefore rests on external validation of the drifting mechanism rather than definitional equivalence to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Privacy-sensitive visual elements can be identified and drifted to semantically equivalent non-sensitive alternatives without task-specific training.
- domain assumption The AdaptShield benchmark with 22 categories provides a valid joint measure of privacy sanitization and contextual utility for MLLMs.
Reference graph
Works this paper leans on
-
[1]
https://huggingface.co/sayakpaul/FLUX
sayakpaul/FLUX.1-dev-edit-v0. https://huggingface.co/sayakpaul/FLUX. 1-dev-edit-v0, 2025
2025
-
[2]
Evaluation of human visual privacy protection: Three-dimensional framework and benchmark dataset
Sara Abdulaziz, Giacomo D’amicantonio, and Egor Bondarev. Evaluation of human visual privacy protection: Three-dimensional framework and benchmark dataset. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 5893–5902, October 2025
2025
-
[3]
MARRS: Multimodal reference resolution system
Halim Cagri Ates, Shruti Bhargava, Site Li, Jiarui Lu, Siddhardha Maddula, Joel Ruben Antony Moniz, Anil Kumar Nalamalapu, Roman Hoang Nguyen, Melis Ozyildirim, Alkesh Patel, Dhivya Piraviperumal, Vincent Renkens, Ankit Samal, Thy Tran, Bo-Hsiang Tseng, Hong Yu, Yuan Zhang, and Shirley Zou. MARRS: Multimodal reference resolution system. In Maciej Ogrodnic...
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Attribute-preserving face dataset anonymization via latent code optimization
Simone Barattin, Christos Tzelepis, Ioannis Patras, and Nicu Sebe. Attribute-preserving face dataset anonymization via latent code optimization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8001–8010, 2023
2023
-
[7]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18392–18402, June 2023
2023
-
[8]
The phantom menace: Unmasking privacy leakages in vision-language models
Simone Caldarella, Massimiliano Mancini, Elisa Ricci, and Rahaf Aljundi. The phantom menace: Unmasking privacy leakages in vision-language models. In Alessio Del Bue, Cristian Canton, Jordi Pont-Tuset, and Tatiana Tommasi, editors,Computer Vision – ECCV 2024 Workshops, pages 435–451, Cham, 2025. Springer Nature Switzerland. ISBN 978-3-031-92648- 8
2024
-
[9]
Jingyi Cao, Xiangyi Chen, Bo Liu, Ming Ding, Rong Xie, Li Song, Zhu Li, and Wenjun Zhang. Face de-identification: State-of-the-art methods and comparative studies.arXiv preprint arXiv:2411.09863, 2024
-
[10]
Unveiling privacy risks in multi-modal large language models: Task-specific vulnerabilities and mitigation challenges
Tiejin Chen, Pingzhi Li, Kaixiong Zhou, Tianlong Chen, and Hua Wei. Unveiling privacy risks in multi-modal large language models: Task-specific vulnerabilities and mitigation challenges. InFindings of the Association for Computational Linguistics: ACL 2025, pages 4573–4586, 2025
2025
-
[11]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 10
2024
-
[12]
Differen- tially private decoupled graph convolutions for multigranular topology protection.Advances in Neural Information Processing Systems, 36:45381–45401, 2023
Eli Chien, Wei-Ning Chen, Chao Pan, Pan Li, Ayfer Ozgur, and Olgica Milenkovic. Differen- tially private decoupled graph convolutions for multigranular topology protection.Advances in Neural Information Processing Systems, 36:45381–45401, 2023
2023
-
[13]
Nancy Chinchor. Muc-4 evaluation metrics. InProceedings of the 4th Conference on Message Understanding, MUC4 ’92, page 22–29, USA, 1992. Association for Computational Linguistics. ISBN 1558602739. doi: 10.3115/1072064.1072067. URL https://doi.org/10.3115/ 1072064.1072067
-
[14]
A review of the f-measure: its history, properties, criticism, and alternatives.ACM Computing Surveys, 56(3):1–24, 2023
Peter Christen, David J Hand, and Nishadi Kirielle. A review of the f-measure: its history, properties, criticism, and alternatives.ACM Computing Surveys, 56(3):1–24, 2023
2023
-
[15]
Image pixelization with differential privacy
Liyue Fan. Image pixelization with differential privacy. InIFIP Annual Conference on Data and Applications Security and Privacy, pages 148–162. Springer, 2018
2018
-
[16]
Mllmguard: A multi-dimensional safety evaluation suite for multimodal large language models.Advances in Neural Information Processing Systems, 37:7256–7295, 2024
Tianle Gu, Zeyang Zhou, Kexin Huang, Liang Dandan, Yixu Wang, Haiquan Zhao, Yuanqi Yao, Yujiu Yang, Yan Teng, Yu Qiao, et al. Mllmguard: A multi-dimensional safety evaluation suite for multimodal large language models.Advances in Neural Information Processing Systems, 37:7256–7295, 2024
2024
-
[17]
On the (in) effectiveness of mosaicing and blurring as tools for document redaction.Proceedings on Privacy Enhancing Technologies, 2016
Steven Hill, Zhimin Zhou, Lawrence Saul, and Hovav Shacham. On the (in) effectiveness of mosaicing and blurring as tools for document redaction.Proceedings on Privacy Enhancing Technologies, 2016
2016
-
[18]
Smartedit: Exploring complex instruction- based image editing with multimodal large language models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, et al. Smartedit: Exploring complex instruction- based image editing with multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8362–8371, 2024
2024
-
[19]
Younggun Kim, Sirnam Swetha, Fazil Kagdi, and Mubarak Shah. Safe-llava: A privacy- preserving vision-language dataset and benchmark for biometric safety.arXiv preprint arXiv:2509.00192, 2025
-
[20]
Face anonymiza- tion made simple
Han-Wei Kung, Tuomas Varanka, Sanjay Saha, Terence Sim, and Nicu Sebe. Face anonymiza- tion made simple. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1040–1050. IEEE, 2025
2025
-
[21]
NullFace: Training-Free Localized Face Anonymization
Han-Wei Kung, Tuomas Varanka, Terence Sim, and Nicu Sebe. Nullface: Training-free localized face anonymization.arXiv preprint arXiv:2503.08478, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[23]
Maskgan: Towards diverse and interactive facial image manipulation
Cheng-Han Lee, Ziwei Liu, Lingyun Wu, and Ping Luo. Maskgan: Towards diverse and interactive facial image manipulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5549–5558, 2020
2020
-
[24]
Dongze Li, Wei Wang, Kang Zhao, Jing Dong, and Tieniu Tan. Riddle: Reversible and diversified de-identification with latent encryptor.arXiv preprint arXiv:2303.05171, 2023
-
[25]
Effective- ness and users’ experience of obfuscation as a privacy-enhancing technology for sharing photos
Yifang Li, Nishant Vishwamitra, Bart P Knijnenburg, Hongxin Hu, and Kelly Caine. Effective- ness and users’ experience of obfuscation as a privacy-enhancing technology for sharing photos. Proceedings of the ACM on Human-Computer Interaction, 1(CSCW):1–24, 2017
2017
-
[26]
Zhixin Lin, Jungang Li, Shidong Pan, Yibo Shi, Yue Yao, and Dongliang Xu. Mind the third eye! benchmarking privacy awareness in mllm-powered smartphone agents.arXiv preprint arXiv:2508.19493, 2025
-
[27]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[28]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Protecting privacy in multimodal large language models with mllmu-bench
Zheyuan Liu, Guangyao Dou, Mengzhao Jia, Zhaoxuan Tan, Qingkai Zeng, Yongle Yuan, and Meng Jiang. Protecting privacy in multimodal large language models with mllmu-bench. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages ...
2025
-
[31]
Weidi Luo, Tianyu Lu, Qiming Zhang, Xiaogeng Liu, Bin Hu, Yue Zhao, Jieyu Zhao, Song Gao, Patrick McDaniel, Zhen Xiang, and Chaowei Xiao. Doxing via the lens: Revealing location-related privacy leakage on multi-modal large reasoning models, 2026. URL https: //arxiv.org/abs/2504.19373
-
[32]
Face deiden- tification with controllable privacy protection.Image and Vision Computing, 134:104678,
Blaž Meden, Manfred Gonzalez-Hernandez, Peter Peer, and Vitomir Štruc. Face deiden- tification with controllable privacy protection.Image and Vision Computing, 134:104678,
-
[33]
doi: https://doi.org/10.1016/j.imavis.2023.104678
ISSN 0262-8856. doi: https://doi.org/10.1016/j.imavis.2023.104678. URL https: //www.sciencedirect.com/science/article/pii/S0262885623000525
-
[34]
Ethan Mendes, Yang Chen, James Hays, Sauvik Das, Wei Xu, and Alan Ritter. Granular privacy control for geolocation with vision language models.arXiv preprint arXiv:2407.04952, 2024
-
[35]
Niloofar Mireshghallah, Hyunwoo Kim, Xuhui Zhou, Yulia Tsvetkov, Maarten Sap, Reza Shokri, and Yejin Choi. Can llms keep a secret? testing privacy implications of language models via contextual integrity theory.arXiv preprint arXiv:2310.17884, 2023
-
[36]
ReVision: A dataset and baseline VLM for privacy-preserving task-oriented visual instruction rewriting
Abhijit Mishra, Mingda Li, Hsiang Fu, Richard Noh, and Minji Kim. ReVision: A dataset and baseline VLM for privacy-preserving task-oriented visual instruction rewriting. In Kentaro Inui, Sakriani Sakti, Haofen Wang, Derek F. Wong, Pushpak Bhattacharyya, Biplab Banerjee, Asif Ekbal, Tanmoy Chakraborty, and Dhirendra Pratap Singh, editors,Proceedings of the...
2025
-
[37]
Towards a visual privacy advisor: Understanding and predicting privacy risks in images
Tribhuvanesh Orekondy, Bernt Schiele, and Mario Fritz. Towards a visual privacy advisor: Understanding and predicting privacy risks in images. InProceedings of the IEEE international conference on computer vision, pages 3686–3695, 2017
2017
-
[38]
Encoding in style: a stylegan encoder for image-to-image translation
Elad Richardson, Yuval Alaluf, Or Patashnik, Yotam Nitzan, Yaniv Azar, Stav Shapiro, and Daniel Cohen-Or. Encoding in style: a stylegan encoder for image-to-image translation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2287–2296, 2021
2021
-
[39]
Sefik Ilkin Serengil and Alper Ozpinar. Boosted lightface: A hybrid dnn and gbm model for boosted facial recognition.Gazi University Journal of Science, 39(1):452–466, 2026. doi: 10.35378/gujs.1794891. URL https://dergipark.org.tr/en/pub/gujs/article/ 1794891
-
[40]
GM Shahariar, Zabir Al Nazi, Md Olid Hasan Bhuiyan, and Zhouxing Shi. Pii-visbench: Evalu- ating personally identifiable information safety in vision language models along a continuum of visibility.arXiv preprint arXiv:2601.05739, 2026
-
[41]
Private attribute inference from images with vision-language models.Advances in Neural Information Processing Systems, 37:103619–103651, 2024
Batuhan Tömekçe, Mark Vero, Robin Staab, and Martin Vechev. Private attribute inference from images with vision-language models.Advances in Neural Information Processing Systems, 37:103619–103651, 2024
2024
-
[42]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Designing an encoder for stylegan image manipulation.ACM Transactions on Graphics (TOG), 40(4):1–14, 2021
Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. Designing an encoder for stylegan image manipulation.ACM Transactions on Graphics (TOG), 40(4):1–14, 2021
2021
-
[44]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Qianshan Wei, Jiaqi Li, Zihan You, Yi Zhan, Kecen Li, Jialin Wu, Xinfeng Li Hengjun Liu, Yi Yu, Bin Cao, Yiwen Xu, Yang Liu, and Guilin Qi. Dual-priv pruning : Efficient differential private fine-tuning in multimodal large language models, 2025. URL https: //arxiv.org/abs/2506.07077
-
[46]
Dipa2: An image dataset with cross-cultural privacy perception annotations.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 7(4):1–30, 2024
Anran Xu, Zhongyi Zhou, Kakeru Miyazaki, Ryo Yoshikawa, Simo Hosio, and Koji Yatani. Dipa2: An image dataset with cross-cultural privacy perception annotations.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 7(4):1–30, 2024
2024
-
[47]
OutSafe-Bench: A Benchmark for Multimodal Offensive Content Detection in Large Language Models
Yuping Yan, Yuhan Xie, Yuanshuai Li, Yingchao Yu, Lingjuan Lyu, and Yaochu Jin. Outsafe- bench: A benchmark for multimodal offensive content detection in large language models, 2025. URLhttps://arxiv.org/abs/2511.10287
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
G 2 face: High-fidelity reversible face anonymization via generative and geometric priors.IEEE Transactions on Information Forensics and Security, 2024
Haoxin Yang, Xuemiao Xu, Cheng Xu, Huaidong Zhang, Jing Qin, Yi Wang, Pheng-Ann Heng, and Shengfeng He. G 2 face: High-fidelity reversible face anonymization via generative and geometric priors.IEEE Transactions on Information Forensics and Security, 2024
2024
-
[49]
Jie Zhang, Xiangkui Cao, Zhouyu Han, Shiguang Shan, and Xilin Chen. Multi-pa: A multi- perspective benchmark on privacy assessment for large vision-language models.arXiv preprint arXiv:2412.19496, 2024
-
[50]
Xian Zhang and Xiang Cheng. Evaluation of geolocation capabilities of multimodal large language models and analysis of associated privacy risks.arXiv preprint arXiv:2506.23481, 2025
-
[51]
Multitrust: A comprehensive benchmark towards trustworthy multimodal large language models.Advances in Neural Information Processing Systems, 37:49279–49383, 2024
Yichi Zhang, Yao Huang, Yitong Sun, Chang Liu, Zhe Zhao, Zhengwei Fang, Yifan Wang, Huanran Chen, Xiao Yang, Xingxing Wei, et al. Multitrust: A comprehensive benchmark towards trustworthy multimodal large language models.Advances in Neural Information Processing Systems, 37:49279–49383, 2024
2024
-
[52]
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. In-context edit: Enabling instructional image editing with in-context generation in large-scale diffusion transformers. In Advances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2504.20690
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: En- hancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.