DOG-DPO:Dynamic Optimization in Geometry for Safety Alignment
Pith reviewed 2026-06-28 02:25 UTC · model grok-4.3
The pith
Representing preference pairs as directions in representation space and decomposing them into a global anchor subspace plus residuals lets DOG-DPO recover full safety alignment from 11 percent of the data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
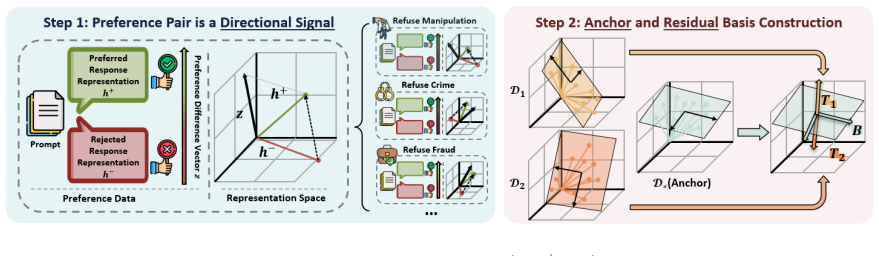
DOG-DPO represents each preference pair as a direction in model representation space, decomposes the multi-dataset collection of directions into a global anchor subspace that captures shared safety signals and dataset-specific residual subspaces that capture unique risks, and then selects a compact subset by maximizing diversity-based coverage of those directions before standard DPO training.
What carries the argument
Decomposition of multi-dataset preference directions into a global anchor subspace plus residual subspaces, followed by diversity-based subset selection on the resulting directional signals.
If this is right
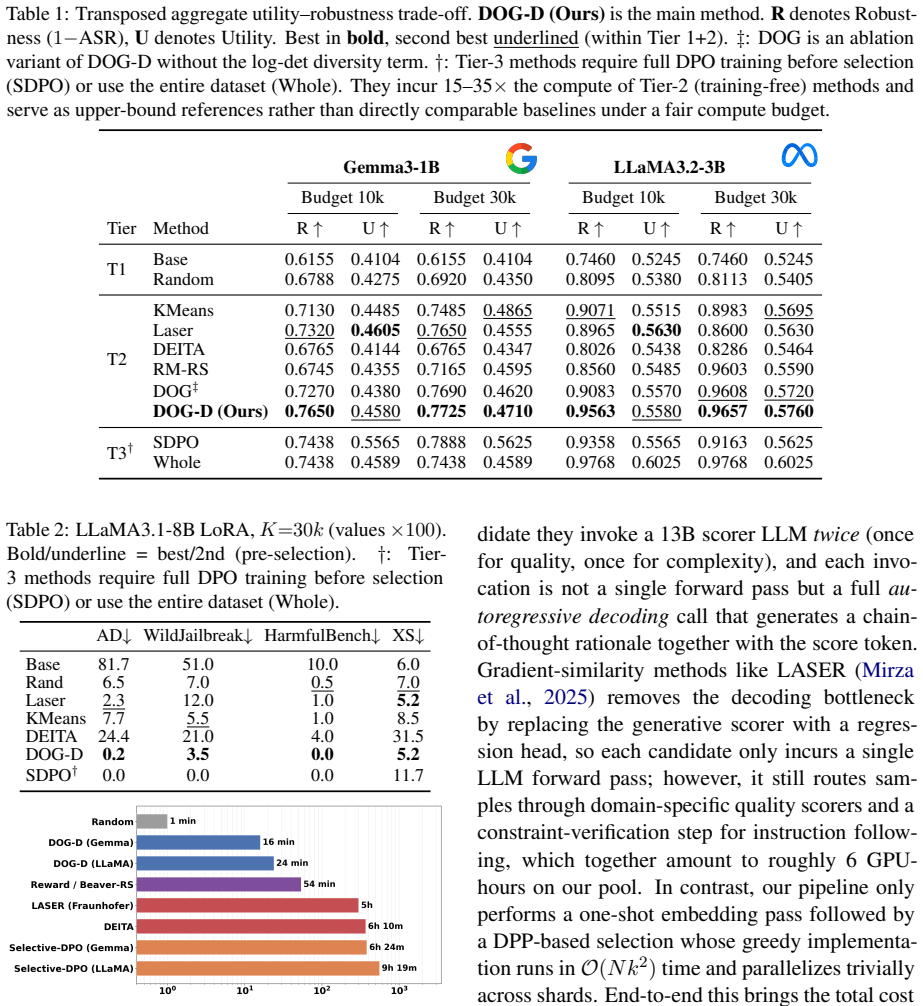
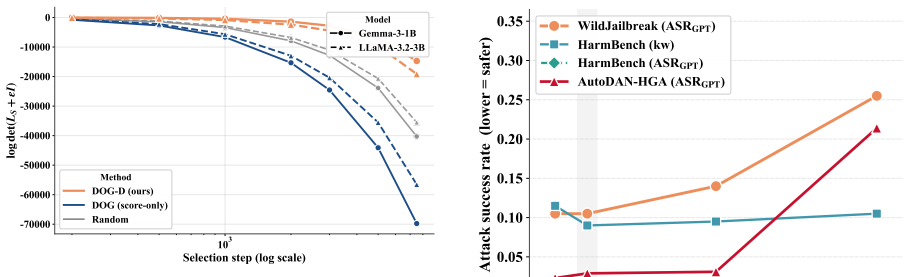
- The selected 11 percent subset recovers most of the safety gains of full-data training across six benchmarks.
- The same selection procedure works on two different model backbones without retraining.
- Selection requires no teacher model and no additional gradient steps.
- The method runs substantially faster than representative selection baselines while preserving the utility-robustness trade-off.
- Diversity-based coverage of directional subspaces replaces independent scalar scoring of pairs.
Where Pith is reading between the lines
- The same directional decomposition could be applied to preference data for objectives other than safety, such as helpfulness or factual accuracy.
- If the anchor subspace remains stable across model scales, a single selected subset might transfer between different base models.
- The geometric framing suggests that alignment datasets possess an intrinsic low-dimensional directional structure that scalar selection methods have overlooked.
Load-bearing premise
That the directional signals carried by preference pairs can be cleanly separated into a shared global subspace and dataset-specific residuals without discarding the safety information required for alignment.
What would settle it
Train a model on the DOG-DPO-selected 11 percent subset and compare its safety benchmark scores to the model trained on the full set; if the reduced-data model shows substantially lower robustness on held-out tests, the geometric selection has lost critical information.
Figures
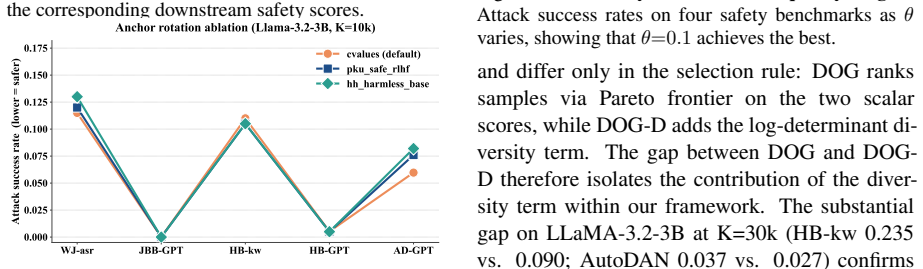
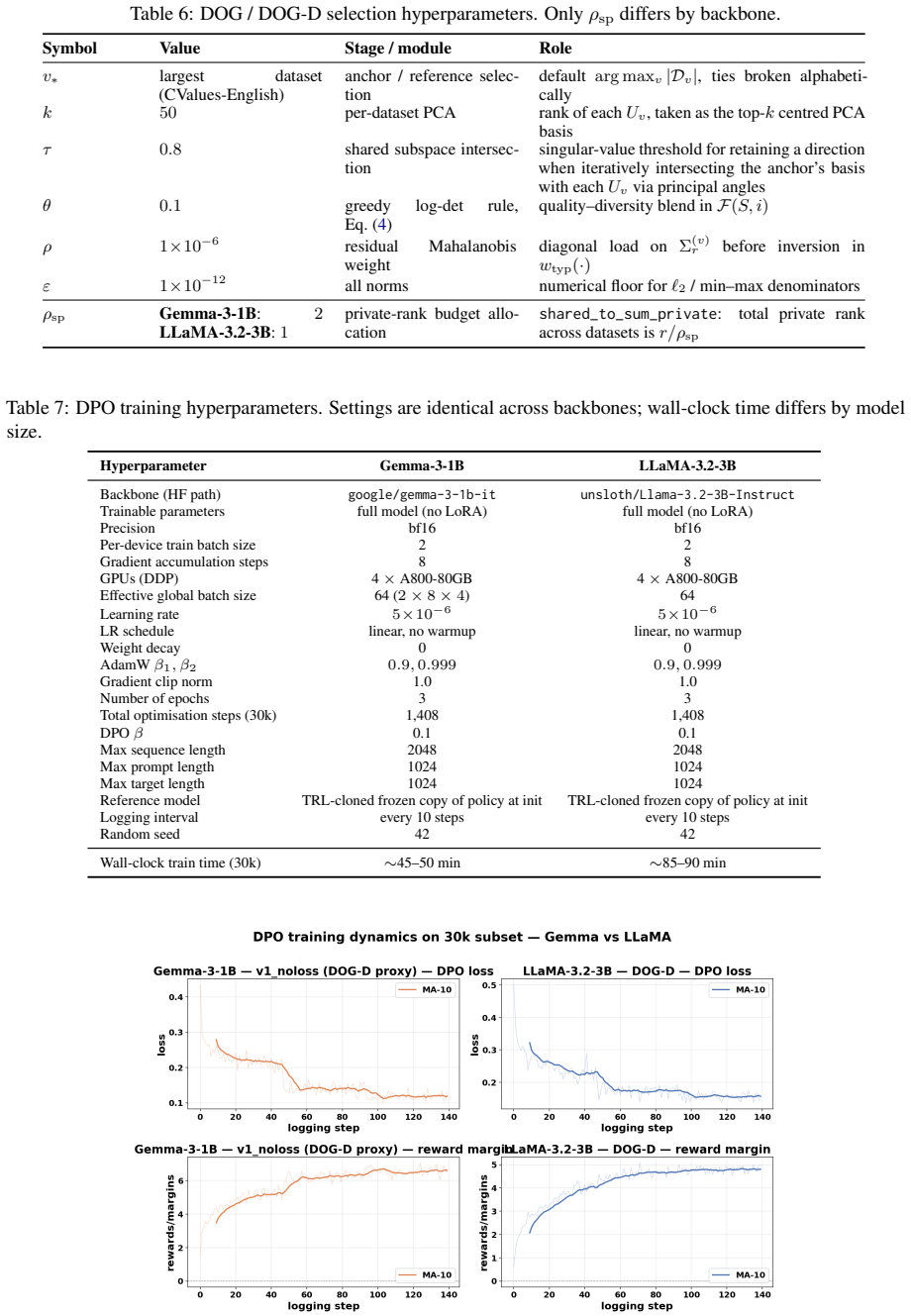
read the original abstract
Safety alignment for large language models relies on preference data, but current pipelines often train on large, redundant datasets. Existing data selection methods typically score each preference pair independently, collapsing directional preference information into scalar quality or diversity scores. This sample-centric view is especially limiting in multi-dataset settings, where shared safety directions coexist with dataset-specific residual risks. We propose DOG-DPO, a training-free data selection framework that treats preference pairs as structured geometric signals. DOG-DPO first represents each preference pair as a direction in model representation space. It then decomposes multi-dataset preference geometry into a global anchor subspace and dataset-specific residual subspaces. Finally, it selects subsets by maximizing diversity-based coverage, encouraging broad, non-redundant coverage of alignment directions before DPO training. Across six safety benchmarks and two model backbones, DOG-DPO achieves a strong utility-robustness trade-off using only 11% of the preference pairs. It recovers most of the safety gains of full-data training while remaining entirely teacher-free, training-free, and substantially faster than representative selection baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DOG-DPO, a training-free geometric data selection method for DPO-based safety alignment. Preference pairs are represented as directions in model representation space; multi-dataset geometry is decomposed into a global anchor subspace plus dataset-specific residual subspaces; subsets are then chosen by maximizing diversity-based coverage of these directions. The central empirical claim is that this procedure recovers most safety gains of full-data DPO training on six benchmarks across two model backbones while using only 11% of the preference pairs.
Significance. If the subspace decomposition and diversity selection provably preserve safety-critical directions without loss, the approach would materially reduce the data and compute needed for robust alignment, offering a scalable, teacher-free alternative to existing selection heuristics.
major comments (2)
- [Abstract / Method] Abstract and method description: the claim that the global-anchor-plus-residual decomposition plus diversity selection preserves alignment information is load-bearing, yet no concrete procedure is supplied for computing the directions, choosing subspace ranks, enforcing orthogonality, or validating that selected directions drive downstream safety gains; without these the 11% recovery result cannot be checked.
- [Method / Experiments] The skeptic concern is not resolved in the provided text: if the global anchor absorbs shared safety signals or if residuals mix noise, the diversity metric (unspecified) may select subsets that fail to recover full-data utility-robustness trade-off; no ablation or diagnostic is described that tests this assumption.
minor comments (1)
- [Method] Notation for the direction vectors and subspace projections should be defined explicitly with equations rather than prose descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and add necessary details and diagnostics.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the claim that the global-anchor-plus-residual decomposition plus diversity selection preserves alignment information is load-bearing, yet no concrete procedure is supplied for computing the directions, choosing subspace ranks, enforcing orthogonality, or validating that selected directions drive downstream safety gains; without these the 11% recovery result cannot be checked.
Authors: We agree that the abstract and method overview are high-level and that explicit implementation details are required for the claims to be verifiable. The manuscript describes representing pairs as directions in representation space and performing the decomposition, but does not supply the full algorithmic steps for direction computation, rank selection, orthogonality, or validation. In revision we will expand the method section with a precise procedure covering these elements and add a short validation correlating selected directions to benchmark gains. revision: yes
-
Referee: [Method / Experiments] The skeptic concern is not resolved in the provided text: if the global anchor absorbs shared safety signals or if residuals mix noise, the diversity metric (unspecified) may select subsets that fail to recover full-data utility-robustness trade-off; no ablation or diagnostic is described that tests this assumption.
Authors: This concern is valid and the current manuscript does not contain ablations or diagnostics that directly test whether the anchor/residual split preserves safety signals or whether the diversity criterion avoids noisy subsets. We will add an ablation study that varies the anchor/residual allocation and reports the resulting safety recovery, together with a diagnostic that compares the selected subset against random selection on the utility-robustness trade-off. revision: yes
Circularity Check
No circularity: training-free geometric selection is self-contained
full rationale
The paper's method represents preference pairs as directions, decomposes geometry into global anchor plus residual subspaces, and selects via diversity coverage before DPO. These operations are described as procedural and training-free with no equations shown that equate a derived quantity to a fitted input by construction, no self-citation chains invoked for uniqueness or ansatz, and no renaming of known results. The 11% recovery claim is presented as an empirical outcome across benchmarks rather than a definitional tautology. This is the common honest case of a self-contained algorithmic pipeline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Consti- tutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073. Alexander Bukharin and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., and Han, J
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models.Preprint, arXiv:2406.18510. Geon-Hyeong Kim, Yu Jin Kim, Byoungjip Kim, Honglak Lee, Kyunghoon Bae, Youngsoo Jang, and Moontae Lee
-
[3]
Safedpo: A simple approach to direct preference optimization with enhanced safety,
Safedpo: A simple approach to direct preference optimization with enhanced safety. arXiv preprint arXiv:2505.20065. Stephanie Lin, Jacob Hilton, and Owain Evans
-
[4]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Autodan: Generating stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451. Zikang Liu, Kun Zhou, Wayne Xin Zhao, Dawei Gao, Yaliang Li, and Ji-Rong Wen. 2024b. Less is more: High-value data selection for visual instruction tun- ing.arXiv preprint arXiv:2403.09559. Haoran Lu, Luyang Fang, Ruidong Zhang, Xinliang Li, Ji...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2507.19672 , year=
Align- ment and safety in large language models: Safety mechanisms, training paradigms, and emerging chal- lenges.arXiv preprint arXiv:2507.19672. Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks
-
[6]
Friedrich Pukelsheim
Training language models to follow in- structions with human feedback.Advances in neural information processing systems, 35:27730–27744. Friedrich Pukelsheim. 2006.Optimal Design of Exper- iments. SIAM. Shuyao Shang, Yuntao Chen, Yuqi Wang, Yingyan Li, and Zhaoxiang Zhang
2006
-
[7]
Drivedpo: Policy learning via safety dpo for end-to-end autonomous driving.arXiv preprint arXiv:2509.17940. Zhichao Wang, Bin Bi, Shiva Kumar Pentyala, Kiran Ramnath, Sougata Chaudhuri, Shubham Mehrotra, Xiang-Bo Mao, Sitaram Asur, and 1 others
-
[8]
Reinforcement Learning for LLM Post-Training: A Survey
A comprehensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more.arXiv preprint arXiv:2407.16216. Ruiyao Xu, Mihir Parmar, Tiankai Yang, Zhengyu Hu, Yue Zhao, and Kaize Ding
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
CoAct: Co-Active LLM Preference Learning with Human-AI Synergy
Coact: Co- active llm preference learning with human-ai syn- ergy.arXiv preprint arXiv:2604.17501. Tiankai Yang, Yi Nian, Xinyuan Li, Ruiyao Xu, Kaize Ding, and Yue Zhao
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Cat-DPO: Category-Adaptive Safety Alignment
Cat-dpo: Category-adaptive safety alignment.arXiv preprint arXiv:2604.17299. Xianjun Yang, Shaoliang Nie, Lijuan Liu, Suchin Gu- rurangan, Ujjwal Karn, Rui Hou, Madian Khabsa, and Yuning Mao. 2025a. Diversity-driven data se- lection for language model tuning through sparse au- toencoder. InICML Workshop. Yuming Yang, Yang Nan, Junjie Ye, Shihan Dou, Xiao ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
InFindings of the Associ- ation for Computational Linguistics: NAACL 2025, pages 4686–4701
Tagcos: Task-agnostic gradient clustered coreset selection for instruction tuning data. InFindings of the Associ- ation for Computational Linguistics: NAACL 2025, pages 4686–4701. A Related Work A.1 Data Selection for Instruction Tuning and Alignment Existing methods can be broadly categorized based on the type of signal used to guide selection. Distribut...
2025
-
[12]
coverage
that det(MS)controls both the worst-covered eigendi- rection ofM S and its rank deficiency. Here we make explicitwhythis quantity is a natural surro- gate for DPO training-signal coverage, and how the anchor/residual basis from §2.2 shapes what “coverage” means. Why the log-determinant is the right surrogate. We would ideally selectSto maximizeλ min(MS), ...
2050
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.