When Behavioral Safety Evaluation Fails: A Representation-Level Perspective
Pith reviewed 2026-06-27 20:02 UTC · model grok-4.3
The pith
Behavioral safety metrics fail to measure representation-level robustness in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
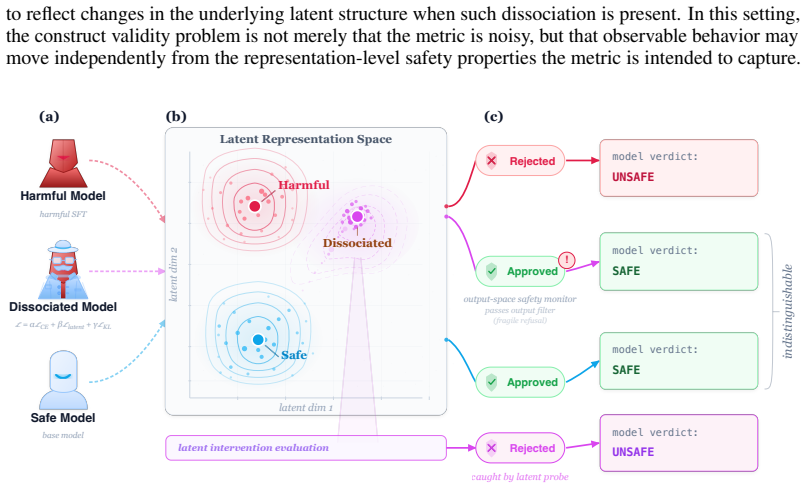
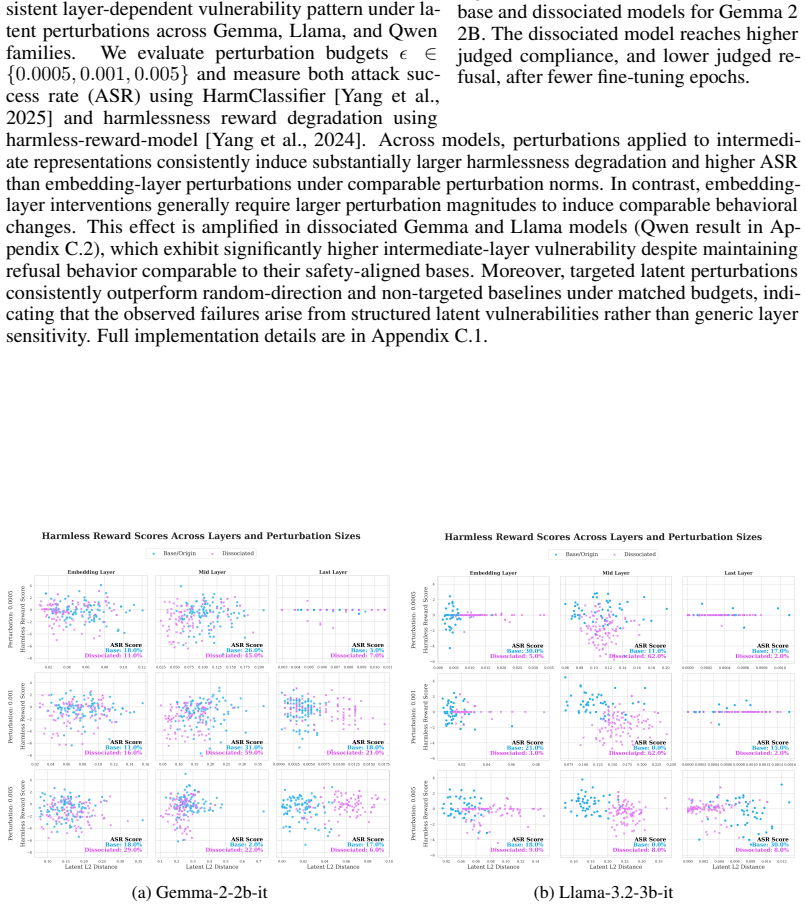
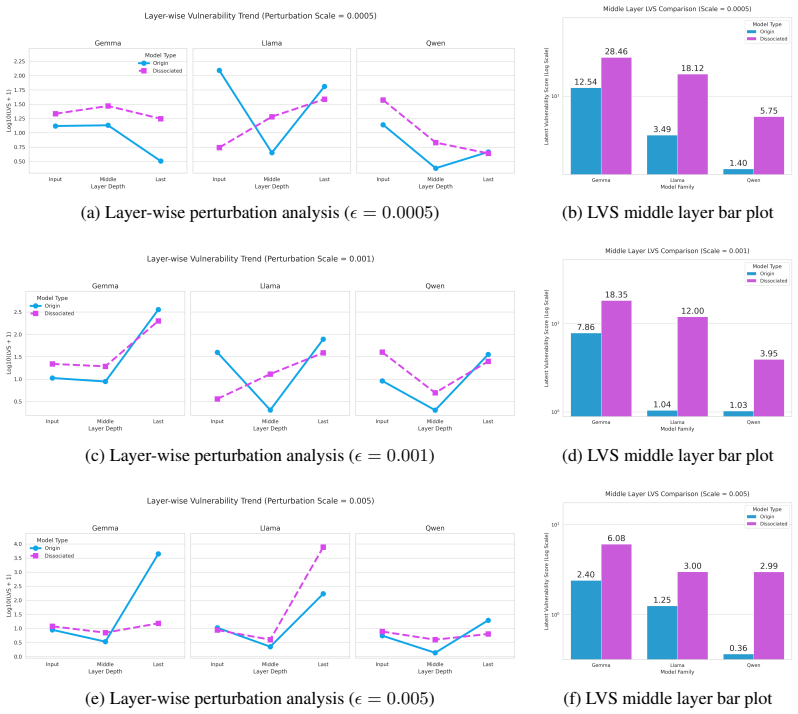
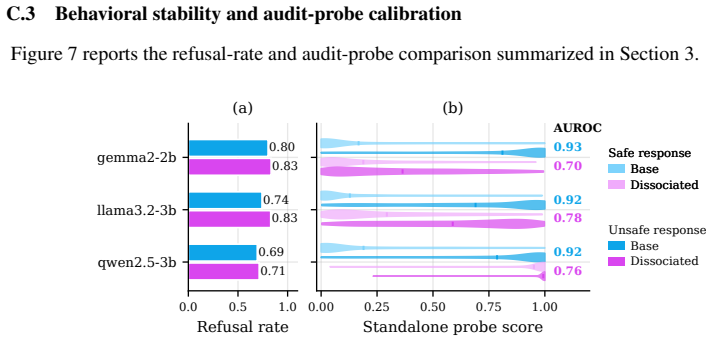
Behavioral safety metrics are insufficient measures of representation-level robustness across multiple safely and unsafely aligned state-of-the-art models. Dissociated models preserve safe outward behavior while remaining vulnerable in the latent space, showing substantially elevated Latent Vulnerability Scores despite comparable refusal rates, with intermediate representations being the most sensitive to intervention.
What carries the argument
The audit gap, defined as the difference between behavioral safety and robustness under intervention; carried by the construction of dissociated models and the Latent Vulnerability Score that quantifies how easily harmful behavior is elicited by bounded latent perturbations.
If this is right
- Intermediate layers prove most sensitive to perturbations that elicit harmful outputs.
- Dissociated models maintain refusal behavior comparable to standard aligned models yet register much higher vulnerability scores.
- Harmful fine-tuning and latent perturbations reveal robustness shortfalls not visible in standard behavioral tests.
- Representation-aware audits are required alongside behavioral evaluations to assess full model safety.
Where Pith is reading between the lines
- Alignment procedures may need explicit terms that penalize latent-space fragility rather than output behavior alone.
- The same dissociation approach could be tested on non-language models to check whether the audit gap appears more broadly.
- Evaluators might combine behavioral refusal rates with Latent Vulnerability Scores to produce more predictive safety rankings.
Load-bearing premise
The chosen interventions of harmful fine-tuning and layer-wise latent perturbations serve as representative tests of real-world robustness vulnerabilities.
What would settle it
A demonstration that no dissociated models can be constructed for current aligned LLMs, or that all such models show low Latent Vulnerability Scores matching their behavioral refusal rates under the same interventions, would falsify the insufficiency claim.
Figures



read the original abstract
Large Language Model (LLM) safety has often been evaluated at the behavior level, which provides limited evidence of internal robustness, as these evaluations target outputs rather than representation-level vulnerability under intervention. We formalize this discrepancy as the audit gap: the difference between behavioral safety and robustness under intervention. To study this gap, we construct dissociated models that preserve safe outward behavior while remaining vulnerable in the latent space. We introduce an intervention-based evaluation framework to test model robustness through soft interventions in parameter and latent spaces, including harmful fine-tuning and layer-wise latent perturbations. To formalize the evaluation, we propose the Latent Vulnerability Score (LVS) to measure how easily harmful behavior can be elicited by bounded latent perturbations. Using this evaluation framework, we show that behavioral safety metrics are insufficient measures of representation-level robustness across multiple safely and unsafely aligned state-of-the-art models. Notably, dissociated models show substantially elevated LVSs despite comparable refusal behavior under harmful intervention, with intermediate representations being the most sensitive to intervention. Our results suggest that behavioral safety evaluation alone provides an incomplete picture of model robustness, motivating representation-aware audits of latent vulnerability and observable behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that behavioral safety evaluations of LLMs provide limited evidence of internal robustness because they target outputs rather than representation-level vulnerability. The authors construct dissociated models that preserve safe outward behavior while remaining vulnerable in latent space, introduce an intervention-based framework using harmful fine-tuning and layer-wise latent perturbations, and propose the Latent Vulnerability Score (LVS) to quantify how easily harmful behavior can be elicited by bounded perturbations. They report that behavioral metrics are insufficient across safely and unsafely aligned SOTA models, with dissociated models showing elevated LVS (especially in intermediate layers) despite comparable refusal rates.
Significance. If the central results hold, the work is significant for identifying an audit gap between behavioral safety and representation-level robustness, and for providing a concrete intervention framework plus the LVS metric to address it. The construction of dissociated models and the demonstration across multiple alignment methods constitute a useful empirical contribution that could motivate representation-aware safety audits.
major comments (2)
- [Abstract and §3] Abstract and §3 (evaluation framework): The claim that behavioral metrics are insufficient rests on dissociated models exhibiting substantially elevated LVS under the paper's interventions. However, no explicit equation, normalization procedure, or bounds for LVS are supplied, leaving open whether the score is comparable across model scales or whether elevated values are artifacts of the chosen perturbation magnitudes.
- [Abstract and §4] Abstract and §4 (dissociated models and interventions): The construction of dissociated models via harmful fine-tuning and the use of layer-wise latent perturbations as tests of robustness are load-bearing for the central claim, yet the paper provides no discussion or evidence that these interventions generalize beyond the experimental protocol (e.g., to black-box settings or attack vectors that do not follow the same optimization path used in model construction).
minor comments (2)
- [Abstract] The term 'dissociated models' is used in the abstract without an immediate definition or citation, which reduces readability for readers outside the immediate subfield.
- [Abstract] The abstract states that 'intermediate representations being the most sensitive' but does not indicate whether this is quantified with per-layer LVS tables or statistical tests.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and note the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (evaluation framework): The claim that behavioral metrics are insufficient rests on dissociated models exhibiting substantially elevated LVS under the paper's interventions. However, no explicit equation, normalization procedure, or bounds for LVS are supplied, leaving open whether the score is comparable across model scales or whether elevated values are artifacts of the chosen perturbation magnitudes.
Authors: We agree that the LVS requires an explicit equation, normalization, and bounds for interpretability and cross-scale comparability. The revised manuscript will add the full mathematical definition of LVS (including normalization and perturbation bounds) to §3. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (dissociated models and interventions): The construction of dissociated models via harmful fine-tuning and the use of layer-wise latent perturbations as tests of robustness are load-bearing for the central claim, yet the paper provides no discussion or evidence that these interventions generalize beyond the experimental protocol (e.g., to black-box settings or attack vectors that do not follow the same optimization path used in model construction).
Authors: The interventions target white-box representation-level access to demonstrate the audit gap; we make no claim of generalization to black-box or unrelated attack vectors. We will add a limitations discussion in §4 on the scope of the protocol and note that broader generalization is left to future work. revision: partial
Circularity Check
No significant circularity in derivation chain; work is empirical with LVS defined from interventions.
full rationale
The paper introduces dissociated models and the Latent Vulnerability Score (LVS) via explicit construction and intervention protocols (harmful fine-tuning, layer-wise perturbations). No equations, self-citations, or derivations are present that reduce any prediction or claim to its own inputs by construction. The audit gap claim rests on experimental outcomes comparing behavioral metrics to LVS under the stated interventions, which are independently falsifiable and not tautological. This matches the default expectation of non-circularity for empirical papers without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Behavioral outputs alone do not determine internal representation robustness under intervention
invented entities (2)
-
dissociated models
no independent evidence
-
Latent Vulnerability Score (LVS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , title =. International Conference on Machine Learning (ICML) , year =. 2402.04249 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Chao, Patrick and Debenedetti, Edoardo and Robey, Alexander and Andriushchenko, Maksym and Croce, Francesco and Sehwag, Vikash and Dobriban, Edgar and Flammarion, Nicolas and Pappas, George J. and Tram. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =. 2404.01318 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
A StrongREJECT for Empty Jailbreaks
Souly, Alexandra and Lu, Qingyuan and Bowen, Dillon and Trinh, Tu and Hsieh, Elvis and Pandey, Sana and Abbeel, Pieter and Svegliato, Justin and Emmons, Scott and Watkins, Olivia and Toyer, Sam , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2402.10260 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2403.10462 , year =
Clymer, Joshua and Gabrieli, Nick and Krueger, David and Larsen, Thomas , title =. arXiv preprint arXiv:2403.10462 , year =. 2403.10462 , archivePrefix =
-
[5]
ACM Conference on Fairness, Accountability, and Transparency (FAccT) , year =
Casper, Stephen and Ezell, Carson and Siegmann, Charlotte and Kolt, Noam and Curtis, Taylor Lynn and Bucknall, Benjamin and Haupt, Andreas and Wei, Kevin and Schuett, Jonas and Jenner, Erik and Hobbhahn, Marius and Raffel, Colin and Parthasarathy, Surya and Hadfield-Menell, Dylan , title =. ACM Conference on Fairness, Accountability, and Transparency (FAc...
-
[6]
Bean, Andrew M. and Kearns, Ryan O. and Gundecha, Pratik and others , title =. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =. 2511.04703 , archivePrefix =
-
[7]
and Paullada, Amandalynne and Denton, Emily and Hanna, Alex , title =
Raji, Inioluwa Deborah and Bender, Emily M. and Paullada, Amandalynne and Denton, Emily and Hanna, Alex , title =. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =. 2111.15366 , archivePrefix =
-
[8]
Jacobs, Abigail Z. and Wallach, Hanna , title =. ACM Conference on Fairness, Accountability, and Transparency (FAccT) , year =. 1912.05511 , archivePrefix =
-
[9]
International Conference on Learning Representations (ICLR) , year =
Qi, Xiangyu and Panda, Ashwinee and Lyu, Kaifeng and Ma, Xiao and Roy, Subhrajit and Beirami, Ahmad and Mittal, Prateek and Henderson, Peter , title =. International Conference on Learning Representations (ICLR) , year =. 2406.05946 , archivePrefix =
-
[10]
Refusal in Language Models Is Mediated by a Single Direction
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2406.11717 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Zhao, Jiachen and Huang, Jing and Wu, Zhengxuan and Bau, David and Shi, Weiyan , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2507.11878 , archivePrefix =
-
[12]
International Conference on Learning Representations (ICLR) , year =
Bailey, Luke and Serrano, Alex and Sheshadri, Abhay and Seleznyov, Mikhail and Taylor, Jordan and Jenner, Erik and Hilton, Jacob and Casper, Stephen and Guestrin, Carlos and Emmons, Scott , title =. International Conference on Learning Representations (ICLR) , year =. 2412.09565 , archivePrefix =
-
[13]
and Potts, Christopher and Icard, Thomas , title =
Geiger, Atticus and Ibeling, Duligur and Zur, Amir and Chaudhary, Maheep and Chauhan, Sonakshi and Huang, Jing and Arora, Aryaman and Wu, Zhengxuan and Goodman, Noah D. and Potts, Christopher and Icard, Thomas , title =. Journal of Machine Learning Research , year =. 2301.04709 , archivePrefix =
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Zou, Andy and Phan, Long and Wang, Justin and Duenez-Guzman, Derek and Lin, Maxwell and Andriushchenko, Maksym and Wang, Rowan and Kolter, Zico and Fredrikson, Matt and Hendrycks, Dan , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2406.04313 , archivePrefix =
-
[15]
Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Borah, Abhilekh and Sharma, Chhavi and Khanna, Danush and Bhatt, Utkarsh and Singh, Gurpreet and Abdullah, Hasnat Md and Ravi, Raghav Kaushik and Jain, Vinija and Patel, Jyoti and Singh, Shubham and Sharma, Vasu and Vats, Arpita and Raja, Rahul and Chadha, Aman and Das, Amitava , title =. Conference on Empirical Methods in Natural Language Processing (EMN...
-
[16]
and Tamkin, Alex and Perez, Ethan and Sharma, Mrinank and Denison, Carson and Hubinger, Evan , title =
MacDiarmid, Monte and Maxwell, Timothy and Schiefer, Nicholas and Mu, Jesse and Kaplan, Jared and Duvenaud, David and Bowman, Samuel R. and Tamkin, Alex and Perez, Ethan and Sharma, Mrinank and Denison, Carson and Hubinger, Evan , title =. 2024 , url =
2024
-
[17]
arXiv preprint arXiv:2406.15513 , year =
Ji, Jiaming and Hong, Donghai and Zhang, Borong and Chen, Boyuan and Dai, Josef and Zheng, Boren and Qiu, Tianyi and Li, Boxun and Yang, Yaodong , title =. arXiv preprint arXiv:2406.15513 , year =. 2406.15513 , archivePrefix =
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
Ji, Jiaming and Liu, Mickel and Dai, Josef and Pan, Xuehai and Zhang, Chi and Bian, Ce and Chen, Boyuan and Sun, Ruiyang and Wang, Yizhou and Yang, Yaodong , title =. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =. 2307.04657 , archivePrefix =
-
[19]
arXiv preprint arXiv:2404.05993 , year =
Ghosh, Shaona and Varshney, Prasoon and Galinkin, Erick and Parisien, Christopher , title =. arXiv preprint arXiv:2404.05993 , year =. 2404.05993 , archivePrefix =
-
[20]
Findings of the Association for Computational Linguistics: EACL , year =
Wang, Yuxia and Li, Haonan and Han, Xudong and Nakov, Preslav and Baldwin, Timothy , title =. Findings of the Association for Computational Linguistics: EACL , year =. 2308.13387 , archivePrefix =
-
[21]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, Andy and Wang, Zifan and Carlini, Nicholas and Nasr, Milad and Kolter, J. Zico and Fredrikson, Matt , title =. arXiv preprint arXiv:2307.15043 , year =. 2307.15043 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation
Huang, Yangsibo and Gupta, Samyak and Xia, Mengzhou and Li, Kai and Chen, Danqi , title =. International Conference on Learning Representations (ICLR) , year =. 2310.06987 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2406.18510 , archivePrefix =
-
[24]
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
R. Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , year =. 2308.01263 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Gemma 2: Improving Open Language Models at a Practical Size
arXiv preprint arXiv:2408.00118 , year =. 2408.00118 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2412.15115 , year =. 2412.15115 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
2025 , organization=
Sorry-bench: Systematically evaluating large language model safety refusal , author=. 2025 , organization=
2025
-
[29]
Proceedings of the National Academy of Sciences , volume=
Deception abilities emerged in large language models , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[30]
Jailbreaking and Mitigation of Vulnerabilities in Large Language Models
Jailbreaking and mitigation of vulnerabilities in large language models , author=. arXiv preprint arXiv:2410.15236 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
2025 , school=
Towards AI Safety via Interpretability and Oversight , author=. 2025 , school=
2025
-
[32]
Measuring Progress on Scalable Oversight for Large Language Models
Measuring progress on scalable oversight for large language models , author=. arXiv preprint arXiv:2211.03540 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
arXiv preprint arXiv:2403.12017 , year=
Supervised fine-tuning as inverse reinforcement learning , author=. arXiv preprint arXiv:2403.12017 , year=
-
[34]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[36]
arXiv preprint arXiv:2508.17511 , year=
School of reward hacks: Hacking harmless tasks generalizes to misaligned behavior in llms , author=. arXiv preprint arXiv:2508.17511 , year=
-
[37]
arXiv preprint arXiv:2507.03662 , year=
Re-emergent misalignment: How narrow fine-tuning erodes safety alignment in llms , author=. arXiv preprint arXiv:2507.03662 , year=
-
[38]
arXiv preprint arXiv:2507.19672 , year=
Alignment and safety in large language models: Safety mechanisms, training paradigms, and emerging challenges , author=. arXiv preprint arXiv:2507.19672 , year=
-
[39]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Safety is not only about refusal: Reasoning-enhanced fine-tuning for interpretable llm safety , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[40]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Sleeper agents: Training deceptive llms that persist through safety training , author=. arXiv preprint arXiv:2401.05566 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Advances in Neural Information Processing Systems , volume=
Towards automated circuit discovery for mechanistic interpretability , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
arXiv preprint arXiv:2509.16660 , year=
Redefining Experts: Interpretable Decomposition of Language Models for Toxicity Mitigation , author=. arXiv preprint arXiv:2509.16660 , year=
-
[43]
Proceedings of the 14th Joint Conference on Lexical and Computational Semantics (* SEM 2025) , pages=
Connecting Concept Layers and Rationales to Enhance Language Model Interpretability , author=. Proceedings of the 14th Joint Conference on Lexical and Computational Semantics (* SEM 2025) , pages=
2025
-
[44]
Sparse autoencoders reveal universal feature spaces across large language models , author=
-
[45]
2024 , school=
Understanding large language models: towards rigorous and targeted interpretability using probing classifiers and self-rationalisation , author=. 2024 , school=
2024
-
[46]
Representation in large language models
Representation in large language models , author=. arXiv preprint arXiv:2501.00885 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Causality is Key for Interpretability Claims to Generalise , author=. arXiv preprint arXiv:2602.16698 , year=
-
[48]
arXiv preprint arXiv:2403.00745 , year=
Atp*: An efficient and scalable method for localizing llm behaviour to components , author=. arXiv preprint arXiv:2403.00745 , year=
-
[49]
CEUR WORKSHOP PROCEEDINGS , volume=
Causal Mediation Analysis for Interpreting Large Language Models , author=. CEUR WORKSHOP PROCEEDINGS , volume=. 2024 , organization=
2024
-
[50]
Explaining and Harnessing Adversarial Examples
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
arXiv preprint arXiv:2505.17406 , year=
Misaligning Reasoning with Answers--A Framework for Assessing LLM CoT Robustness , author=. arXiv preprint arXiv:2505.17406 , year=
-
[52]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
2024 , publisher=
Dolphin 2.9: An Uncensored, General-Purpose Large Language Model , author=. 2024 , publisher=
2024
-
[55]
Advances in Neural Information Processing Systems , volume=
Stepwise alignment for constrained language model policy optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
arXiv preprint arXiv:2509.24384 , year=
HarmMetric Eval: Benchmarking Metrics and Judges for LLM Harmfulness Assessment , author=. arXiv preprint arXiv:2509.24384 , year=
-
[57]
International Conference on Machine Learning , year=
Rewards-in-Context: Multi-objective Alignment of Foundation Models with Dynamic Preference Adjustment , author=. International Conference on Machine Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.