Cheap Reward Hacking Detection
Pith reviewed 2026-06-27 17:19 UTC · model grok-4.3
The pith
A small transformer encoder detects reward hacking nearly as accurately as an LLM judge but at four orders of magnitude lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
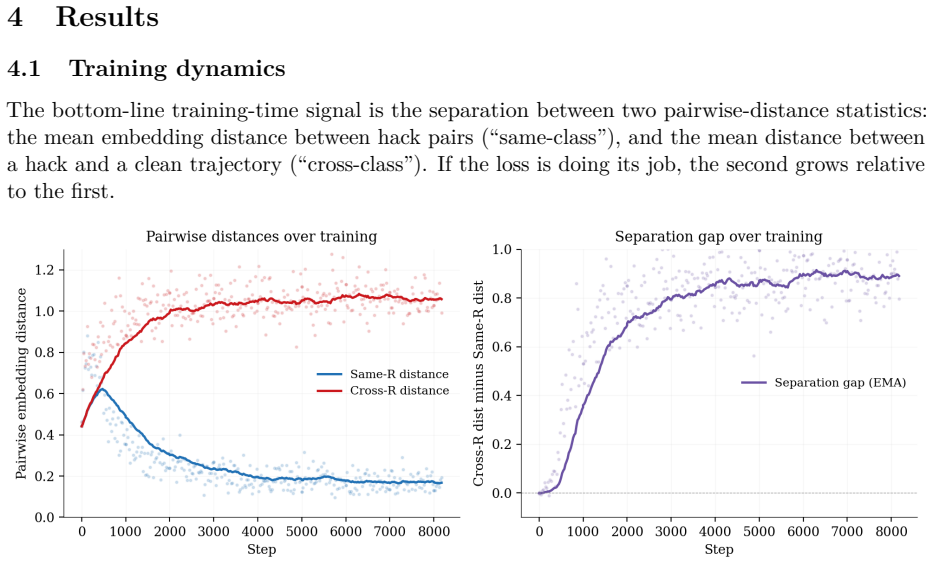
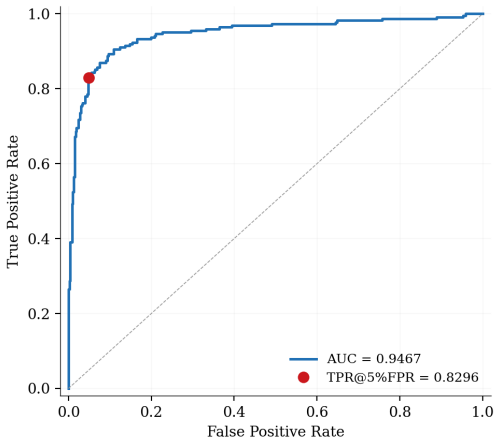
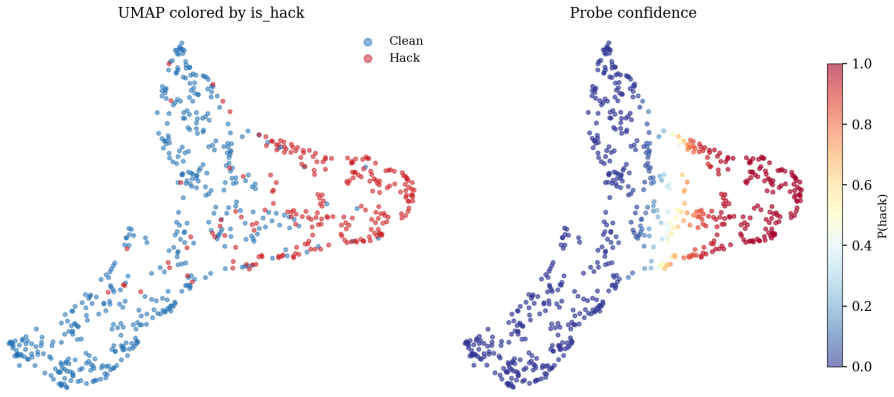
The authors show that a small transformer encoder trained to map trajectories to a unit sphere, where embedding distance approximates L1 distance between reward and metadata signals, enables a linear probe to detect reward hacking on the cleaned test split with AUC 0.9467 and TPR@5%FPR 0.8296. This matches the TW sanitized LLM-as-judge AUC of 0.9510 and exceeds its TPR@5%FPR of 0.7130 on the same information condition, at roughly four orders of magnitude lower per-trajectory cost. The encoder is not a pure behavior reader, as removing natural-language reasoning drops AUC to 0.6213.
What carries the argument
The small transformer encoder that maps Terminal-Wrench trajectories onto a unit sphere where embedding distance approximates the L1 distance between reward and metadata signals.
If this is right
- Reward hacking detection becomes feasible at much lower per-trajectory cost than LLM-based judging.
- The linear probe achieves comparable AUC and higher TPR at 5 percent FPR than the LLM judge under the same information condition.
- Detection performance requires the full input that includes natural-language reasoning, as performance falls sharply without it.
- The embedding approach provides a scalable method for monitoring trajectories without repeated large-model calls.
Where Pith is reading between the lines
- Routine, low-cost scanning of large numbers of trajectories could become practical in ongoing training or evaluation loops.
- Similar embedding-plus-probe pipelines might be tested on other misalignment signals beyond reward hacking.
- The cost reduction could allow more trajectories to be audited in settings where LLM calls are currently prohibitive.
Load-bearing premise
The cleaning of the test split does not introduce selection bias that favors the embedding method over the LLM baseline.
What would settle it
Testing the linear probe on a freshly collected set of trajectories without the reported cleaning step and observing a substantial drop in AUC or TPR would show whether the reported detection performance holds.
Figures
read the original abstract
A small transformer encoder is trained to map Terminal-Wrench trajectories onto a unit sphere where embedding distance approximates the $L_1$ distance between reward and metadata signals. A linear probe on top of that embedding detects reward hacking on the cleaned test split with AUC $0.9467$ and TPR@5%FPR $0.8296$, matching the TW sanitized LLM-as-judge AUC ($0.9510$ on the cleaned split) and exceeding its TPR@5%FPR ($0.7130$ vs $0.8296$) on the same information condition, at roughly four orders of magnitude lower per-trajectory cost. The encoder is not a pure behavior reader: stripping natural-language reasoning from its input at probe time drops AUC to $0.6213$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper trains a small transformer encoder to map Terminal-Wrench trajectories to a unit sphere such that embedding distance approximates L1 distance between reward and metadata signals. A linear probe on this embedding detects reward hacking on the cleaned test split with AUC 0.9467 and TPR@5%FPR 0.8296, matching the TW-sanitized LLM-as-judge AUC (0.9510) and exceeding its TPR@5%FPR (0.7130 vs 0.8296) at four orders of magnitude lower cost. Stripping natural-language reasoning from the input drops AUC to 0.6213.
Significance. If the performance numbers hold without selection bias from the cleaning step, the work demonstrates a scalable, low-cost embedding-based detector for reward hacking that could complement or replace expensive LLM judges in RLHF pipelines. The ablation showing that the encoder relies on natural-language reasoning (rather than raw behavior alone) strengthens the claim that the representation captures semantically relevant features.
major comments (1)
- [Abstract] Abstract: The central performance claims (AUC 0.9467, TPR@5%FPR 0.8296 on the cleaned test split) rest on an unspecified cleaning procedure for the test split. No criteria, fraction of trajectories removed, or verification that removal was independent of the embedding/probe outputs are provided. This is load-bearing because preferential removal of cases where the unit-sphere embedding fails to separate hacked trajectories could artifactually produce parity or superiority over the LLM judge baseline.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting an important omission in our description of the experimental pipeline. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (AUC 0.9467, TPR@5%FPR 0.8296 on the cleaned test split) rest on an unspecified cleaning procedure for the test split. No criteria, fraction of trajectories removed, or verification that removal was independent of the embedding/probe outputs are provided. This is load-bearing because preferential removal of cases where the unit-sphere embedding fails to separate hacked trajectories could artifactually produce parity or superiority over the LLM judge baseline.
Authors: We agree that the cleaning procedure must be fully specified for the results to be interpretable. The current manuscript does not provide the criteria, the fraction removed, or an explicit statement of independence from the embedding/probe. In the revised manuscript we will add a dedicated subsection describing the cleaning rules (removal of trajectories with missing or uncomputable reward/metadata fields), the exact fraction removed from the test split, and confirmation that cleaning occurred prior to any embedding training or probe fitting and was performed solely on metadata completeness. We will also add a short discussion of why the cleaning criteria are unlikely to introduce the selection bias the referee describes. revision: yes
Circularity Check
No circularity: empirical performance reported on held-out test split after training.
full rationale
The paper describes training a transformer encoder to produce embeddings and then evaluating a linear probe's detection performance (AUC, TPR) on a cleaned test split. No equations, derivations, or self-citations are presented that reduce the reported metrics to fitted quantities by construction, nor is any uniqueness theorem or ansatz imported from prior author work. The central result is an empirical measurement rather than an algebraic identity or renamed input. The unspecified cleaning procedure raises validity concerns but does not constitute definitional or self-referential circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embedding distance on the unit sphere approximates the L1 distance between reward and metadata signals
Reference graph
Works this paper leans on
-
[1]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models.arXiv preprint arXiv:2201.03544, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective
Tom Everitt, Marcus Hutter, Ramana Kumar, and Victoria Krakovna. Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective. Synthese, 198(Suppl 27):6435–6467, 2021
2021
-
[4]
Bisimulation metrics for continuous Markov decision processes.SIAM Journal on Computing, 40(6):1662–1714, 2011
Norm Ferns, Prakash Panangaden, and Doina Precup. Bisimulation metrics for continuous Markov decision processes.SIAM Journal on Computing, 40(6):1662–1714, 2011
2011
-
[5]
Density-based clustering based on hierarchical density estimates
Ricardo JGB Campello, Davoud Moulavi, and Jörg Sander. Density-based clustering based on hierarchical density estimates. InPacific-Asia Conference on Knowledge Discovery and Data Mining, pages 160–172. Springer, 2013
2013
-
[6]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[7]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. UMAP: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
SMART: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Tuo Zhao. SMART: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2177–2190, 2020
2020
-
[9]
Chen Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, and Jingjing Liu. FreeLB: Enhanced adversarial training for natural language understanding.arXiv preprint arXiv:1909.11764, 2019
-
[10]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational Conference on Machine Learning, pages 1597–1607. PMLR, 2020
2020
-
[11]
Defining and characterizing reward gaming.Advances in Neural Information Processing Systems, 35: 9460–9471, 2022
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming.Advances in Neural Information Processing Systems, 35: 9460–9471, 2022
2022
-
[12]
Specification gaming: The flip side of AI ingenuity.DeepMind Blog, 2020
Victoria Krakovna, Jonathan Uesato, Vladimir Mikulik, Matthew Rahtz, Tom Everitt, Ralph Bolber, Marcus Hutter, and Shane Legg. Specification gaming: The flip side of AI ingenuity.DeepMind Blog, 2020. URL https://deepmindsafetyresearch.medium.com/ specification-gaming-the-flip-side-of-ai-ingenuity-c85bdb0deeb4
2020
-
[13]
Programming as theory building.Microprocessing and Microprogramming, 15(5): 253–261, 1985
Peter Naur. Programming as theory building.Microprocessing and Microprogramming, 15(5): 253–261, 1985
1985
-
[14]
Categorizing Variants of Goodhart's Law
David Manheim and Scott Garrabrant. Categorizing variants of Goodhart’s law.arXiv preprint arXiv:1803.04585, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomek Korbak, David Duvenaud, Amanda Askell, Sam Bow- man, Esin Durmus, Zac Hatfield-Dodds, Scott Johnston, Shauna Kravec, et al. Towards understanding sycophancy in language models. InInternational Conference on Learning Representations, volume 2024, pages 110–144, 2024. 19
2024
-
[16]
Terminal Wrench: A Dataset of 331 Reward-Hackable Environments and 3,632 Exploit Trajectories
Ivan Bercovich, Ivgeni Segal, Kexun Zhang, Shashwat Saxena, Aditi Raghunathan, and Ziqian Zhong. Terminal wrench: A dataset of 331 reward-hackable environments and 3,632 exploit trajectories.arXiv preprint arXiv:2604.17596, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
MICo: Improved representations via sampling-based state similarity for Markov decision processes
Pablo Samuel Castro, Tyler Kastner, Prakash Panangaden, and Mark Rowland. MICo: Improved representations via sampling-based state similarity for Markov decision processes. Advances in Neural Information Processing Systems, 34:30113–30126, 2021
2021
-
[18]
Sliced and Radon Wasserstein barycenters of measures.Journal of Mathematical Imaging and Vision, 51(1): 22–45, 2015
Nicolas Bonneel, Julien Rabin, Gabriel Peyré, and Hanspeter Pfister. Sliced and Radon Wasserstein barycenters of measures.Journal of Mathematical Imaging and Vision, 51(1): 22–45, 2015. 20
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.