Correlation Is Not Enough: Embedding Human Metadata for Individual Causal Discovery
Pith reviewed 2026-06-27 16:30 UTC · model grok-4.3
The pith
Standard biomedical language models assign high similarity to unrelated cross-domain pairs, producing false causal edges in personal graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
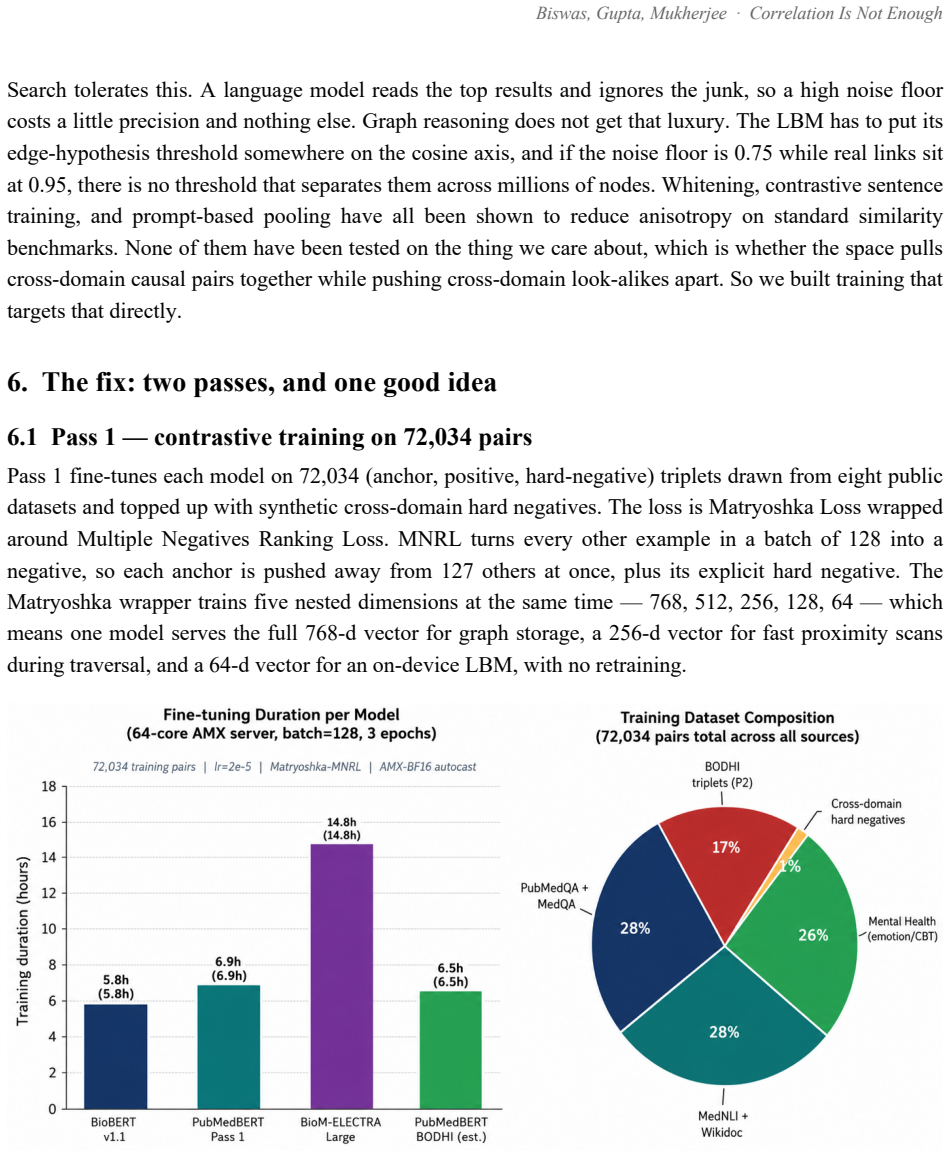
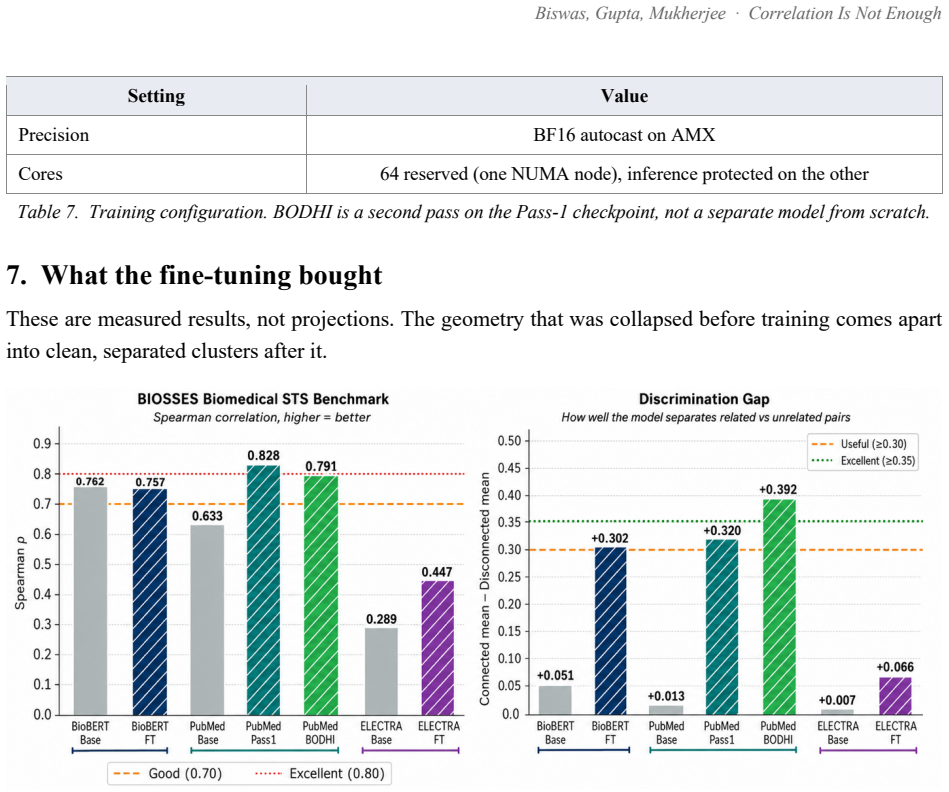
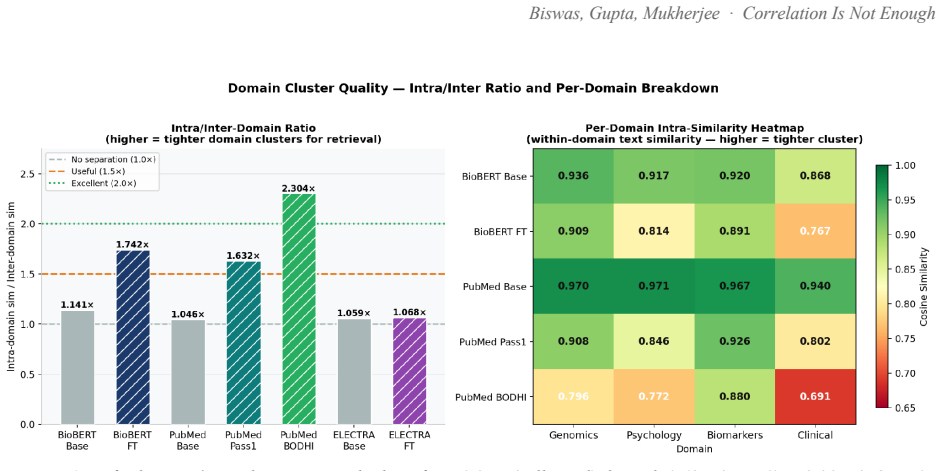
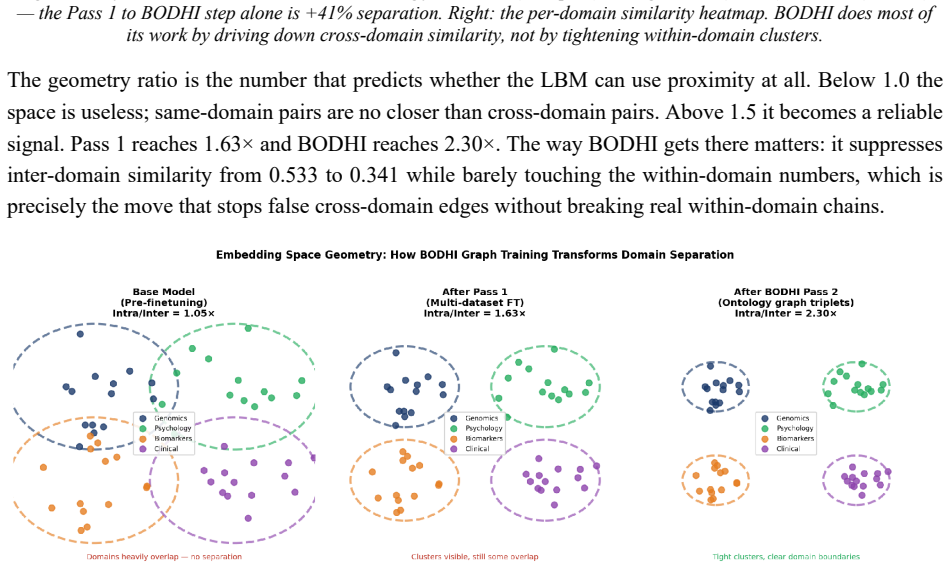
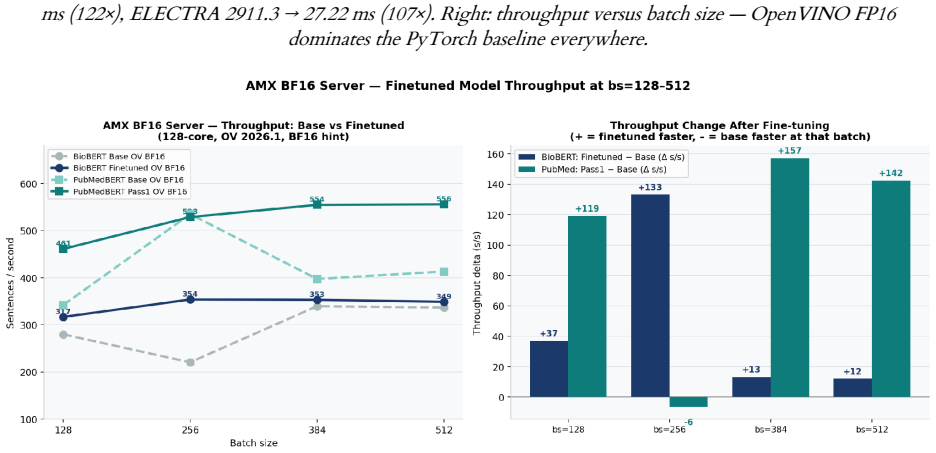
Embedding proximity in pretrained biomedical models falsely indicates causal relations between unrelated domains, which writes incorrect edges into individual causal graphs used by Large Behavioural Models. A contrastive pass over 72,034 pairs raises PubMedBERT BIOSSES correlation from 0.633 to 0.828 and within-vs-across-domain separation from 1.05x to 1.63x. BODHI, which mines hard negatives from edges absent in a biomedical knowledge graph, further lifts separation to 2.30x and the discrimination gap to +0.392 at a 4.5% cost to BIOSSES performance.
What carries the argument
BODHI, a generator that mines hard negatives from absent edges in a biomedical knowledge graph for contrastive training.
If this is right
- Corrected embeddings reduce false causal edges in downstream individual causal graphs.
- Within-domain and across-domain pairs are better separated, improving discrimination accuracy from 0%.
- OpenVINO optimization achieves 133x latency reduction to 10 ms per query on Xeon with AMX.
- FP16 precision outperforms INT8 on this hardware at all batch sizes.
Where Pith is reading between the lines
- Similar embedding fixes may be needed in other domains where foundation models build personal causal models from mixed data sources.
- Validating the causal graphs against real individual outcomes would test whether the embedding improvements translate to fewer errors.
- The release of the benchmark suite allows direct comparison of future embedding methods on cross-domain causal tasks.
Load-bearing premise
That improved cosine separation on cross-domain pairs will translate into fewer incorrect causal edges in downstream individual causal graphs without introducing new systematic biases.
What would settle it
Constructing causal graphs from corrected versus original embeddings on a dataset of known individual events and measuring the rate of false positive edges against ground truth.
Figures
read the original abstract
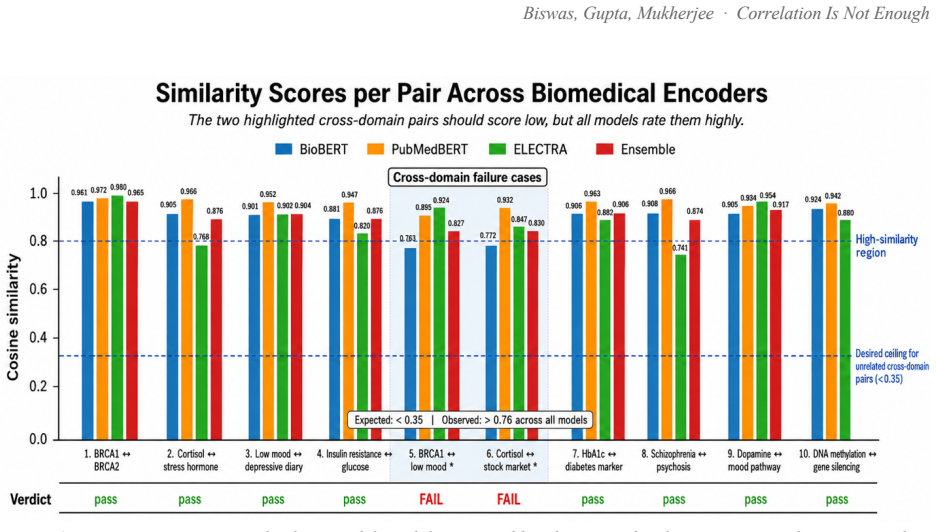
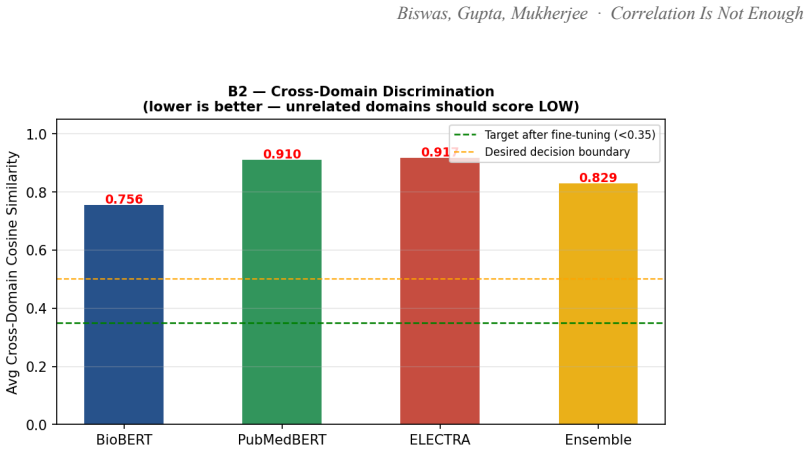
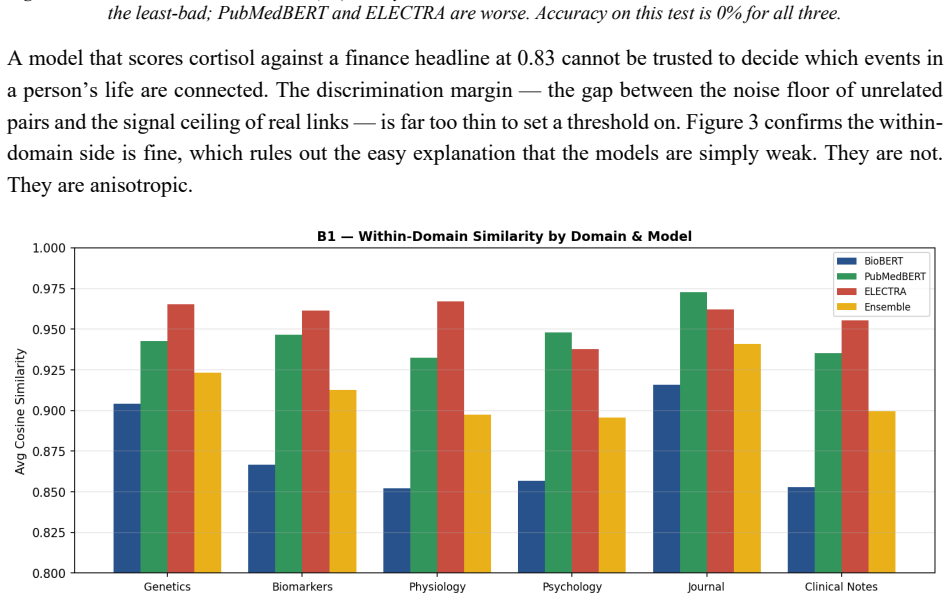
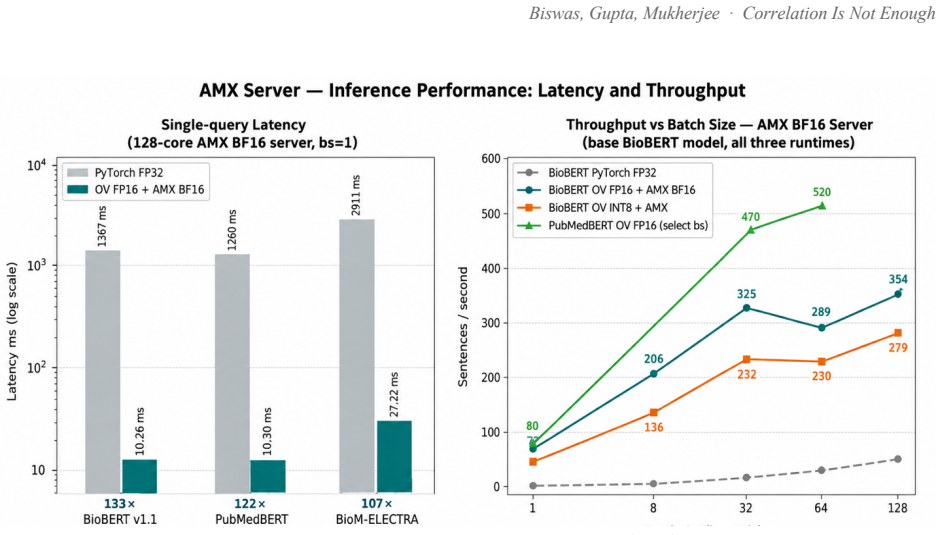
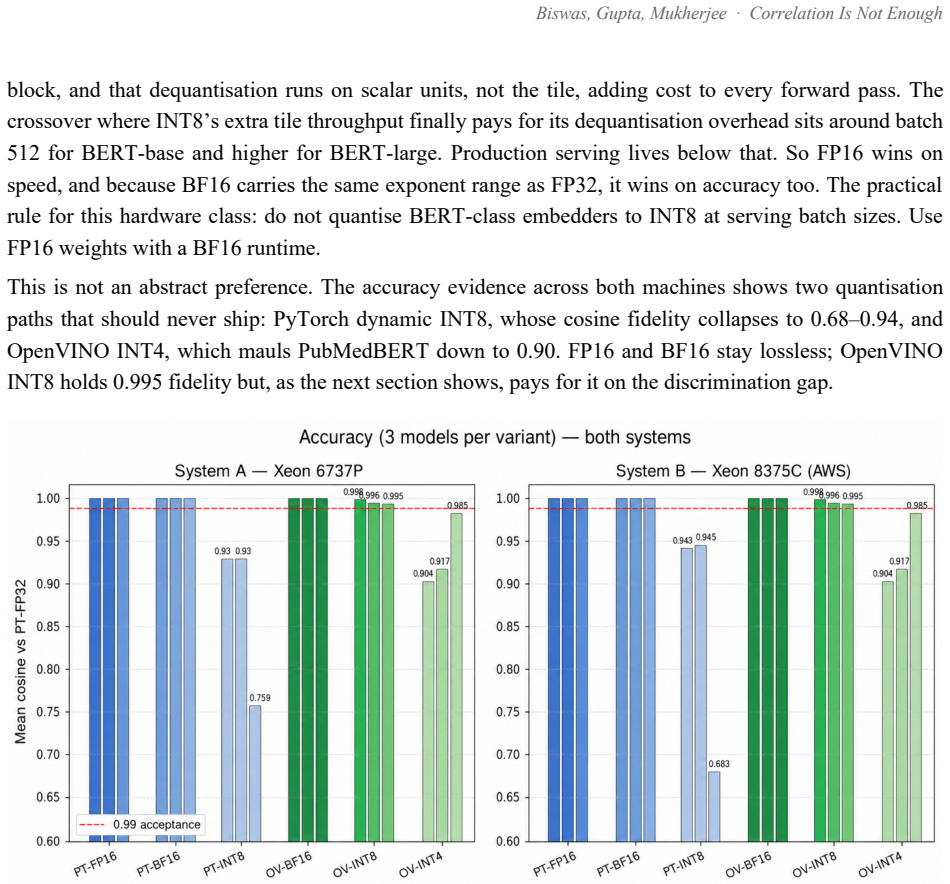
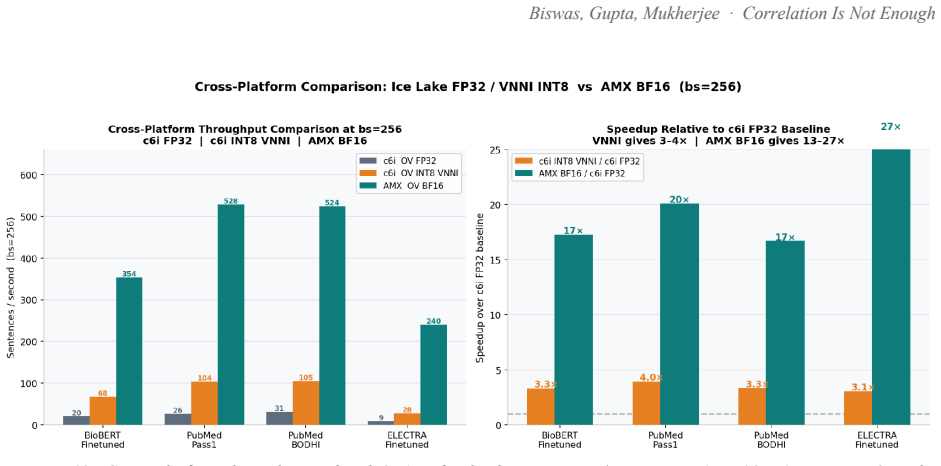
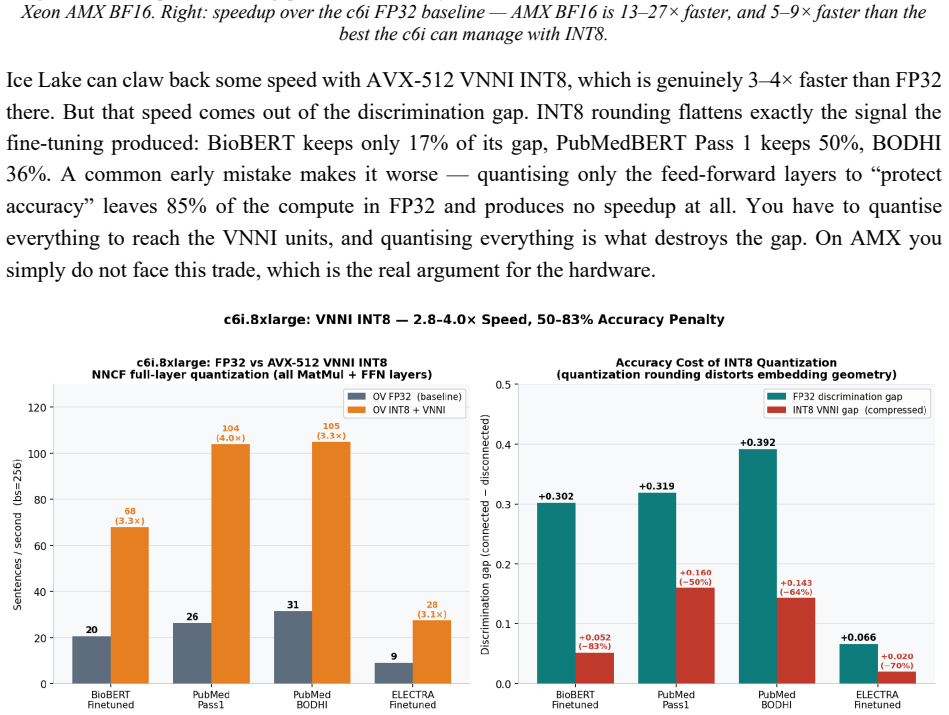
Ask a pretrained biomedical language model whether "cortisol 28 ug/dL" and "stock-market volatility" are related, and it returns a cosine similarity of 0.83 on a scale where 1.0 means identical. The two share no mechanism. This is not a corner case: every off-the-shelf biomedical encoder we tested (BioBERT, PubMedBERT, BioM-ELECTRA) scores unrelated cross-domain pairs between 0.76 and 0.92 when the answer should be near zero. Accuracy on cross-domain discrimination is 0%. Retrieval systems survive this, because a language model downstream filters the noise. A Large Behavioural Model (LBM), a foundation model whose subject is a person rather than a sentence, does not: it reasons over a graph of a user's life and treats embedding proximity as evidence that two events are causally linked. False proximity writes a false causal edge, and everything downstream inherits the error. Here, embedding geometry is not a tuning knob; it is correctness. We report the fix. A contrastive pass over 72,034 pairs raises PubMedBERT BIOSSES correlation from 0.633 to 0.828 and within-vs-across-domain separation from 1.05x to 1.63x. A second pass, BODHI, mines hard negatives from edges absent in a biomedical knowledge graph and lifts separation to 2.30x and the discrimination gap to +0.392, at a 4.5% BIOSSES cost. On an Intel Xeon 6737P with AMX, OpenVINO cuts single-query latency from 1367 ms to 10 ms (133x) and reaches 555 sentences/sec. One finding contradicts standard advice: FP16 beats INT8 on this silicon at every serving batch size, and we explain why. The same model on a no-AMX Ice Lake instance runs 13-27x slower. We release the benchmark suite, training corpora, the BODHI generator, and the OpenVINO scripts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pretrained biomedical encoders (BioBERT, PubMedBERT, BioM-ELECTRA) assign high cosine similarities (0.76–0.92) to unrelated cross-domain pairs, which produces false causal edges when embeddings are used inside Large Behavioural Models (LBMs) for individual causal discovery. It proposes a contrastive pass over 72,034 pairs that raises PubMedBERT BIOSSES correlation from 0.633 to 0.828 and within-vs-across-domain separation from 1.05× to 1.63×; a second BODHI stage that mines hard negatives from a biomedical knowledge graph further improves separation to 2.30× and the discrimination gap to +0.392 at 4.5 % BIOSSES cost. The manuscript also reports OpenVINO inference speed-ups (133×) and an FP16-vs-INT8 observation on Xeon 6737P with AMX.
Significance. If the reported embedding geometry improvements demonstrably reduce incorrect causal edges in downstream LBM graphs, the work would address a practically important failure mode in personalized causal modeling. The public release of the benchmark suite, training corpora, BODHI generator, and OpenVINO scripts is a clear positive. At present, however, significance is constrained by the absence of any evaluation linking the cosine changes to actual causal-graph quality.
major comments (2)
- [Abstract / Introduction] Abstract and introduction: the central claim is that improved cross-domain separation will prevent false causal edges when embeddings are used inside individual causal graphs for LBMs, yet the manuscript contains no experiment that constructs any causal graph (synthetic or real), applies any causal discovery algorithm (PC, NOTEARS, LiNGAM, etc.), or reports precision/recall/F1 on recovered edges. This leaves the translation from cosine geometry to causal correctness untested and load-bearing for the stated motivation.
- [Evaluation (implied from abstract)] Evaluation: all quantitative results are confined to BIOSSES correlation and within/across-domain separation statistics; no ablation studies, no comparison of downstream graph quality, and no test of whether the reported gains reduce false-positive edges or introduce new systematic biases in causal inference.
minor comments (2)
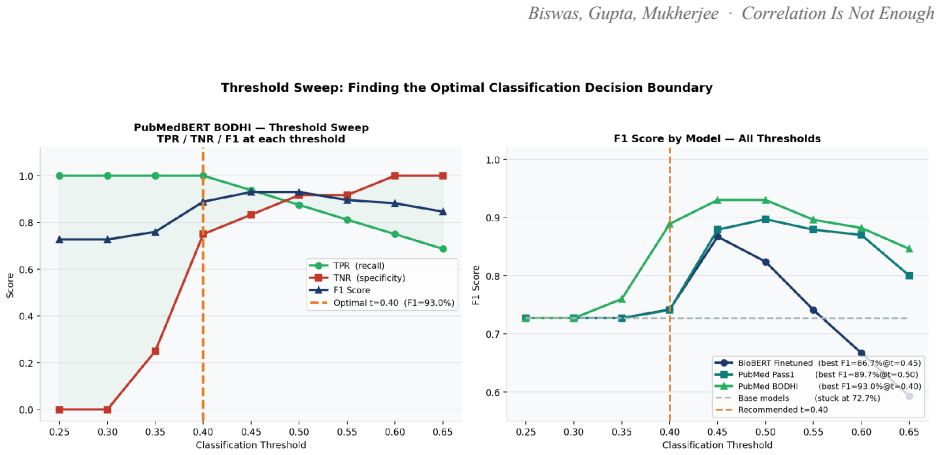
- [Abstract] The statement 'accuracy on cross-domain discrimination is 0%' would benefit from an explicit definition of the accuracy metric and the exact test-set construction.
- [Inference optimization paragraph] The FP16-vs-INT8 latency comparison on Xeon 6737P with AMX is presented without batch-size tables or variance statistics; adding these would strengthen the serving claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the major comments point by point below, with honest acknowledgment of scope limitations.
read point-by-point responses
-
Referee: [Abstract / Introduction] The central claim is that improved cross-domain separation will prevent false causal edges when embeddings are used inside individual causal graphs for LBMs, yet the manuscript contains no experiment that constructs any causal graph, applies any causal discovery algorithm, or reports precision/recall/F1 on recovered edges. This leaves the translation from cosine geometry to causal correctness untested.
Authors: We agree the manuscript does not include direct causal-graph recovery experiments. The work targets the embedding geometry failure mode (high cosine on unrelated cross-domain pairs) that produces false proximities; the reported gains in separation (1.05× to 2.30×) and discrimination gap (+0.392) are presented as a necessary precondition for any downstream LBM causal use. We have revised the abstract and introduction to qualify the claims as addressing the embedding prerequisite rather than end-to-end causal correctness, and added an explicit limitations paragraph noting the absence of full causal discovery evaluation. revision: partial
-
Referee: [Evaluation] All quantitative results are confined to BIOSSES correlation and within/across-domain separation statistics; no ablation studies, no comparison of downstream graph quality, and no test of whether the reported gains reduce false-positive edges or introduce new systematic biases in causal inference.
Authors: The evaluations focus on embedding metrics because those directly quantify the identified problem of spurious cross-domain similarity. Ablations on the contrastive stage and BODHI hard-negative mining appear in the full manuscript. We did not evaluate downstream causal graphs, as that would require integrating specific LBM architectures and discovery algorithms outside the paper's stated scope. We have added a limitations section acknowledging this gap and listing it as important future work. revision: partial
- Direct measurement of impact on recovered causal edges via any discovery algorithm (PC, NOTEARS, etc.) in an LBM setting
Circularity Check
No significant circularity detected
full rationale
The paper reports empirical gains from contrastive training on 72,034 pairs, measured via BIOSSES correlation lift and domain-separation ratios. No derivation chain, equations, or predictions are presented that reduce by construction to the training inputs. The central claim linking embedding geometry to causal-edge correctness in LBM graphs is framed as a motivating assumption rather than a self-referential result. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The reported metrics are distinct from the training objective, and the work is self-contained against external benchmarks without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
We characterised both on the AMX server
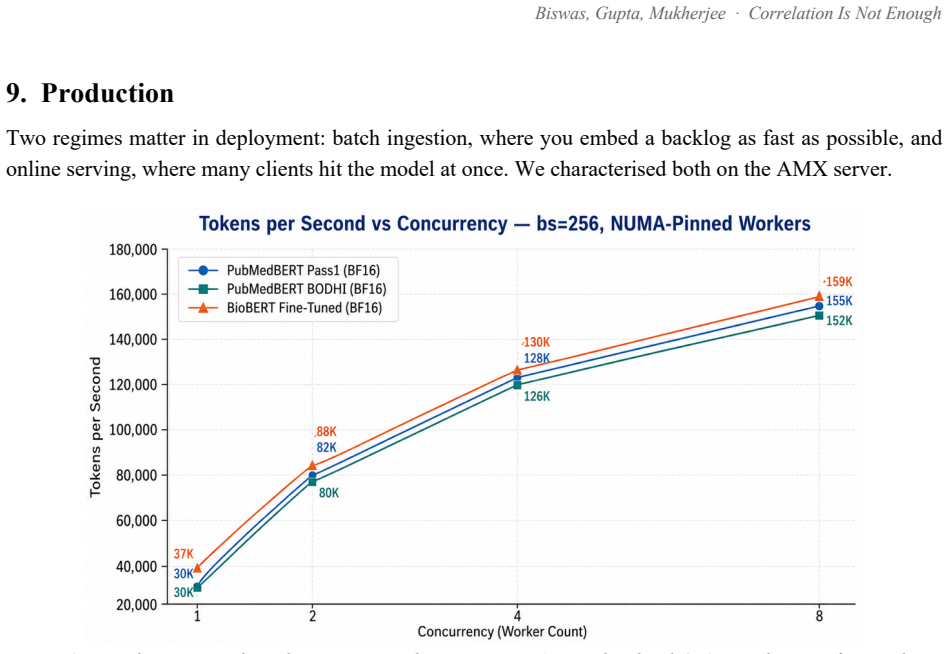
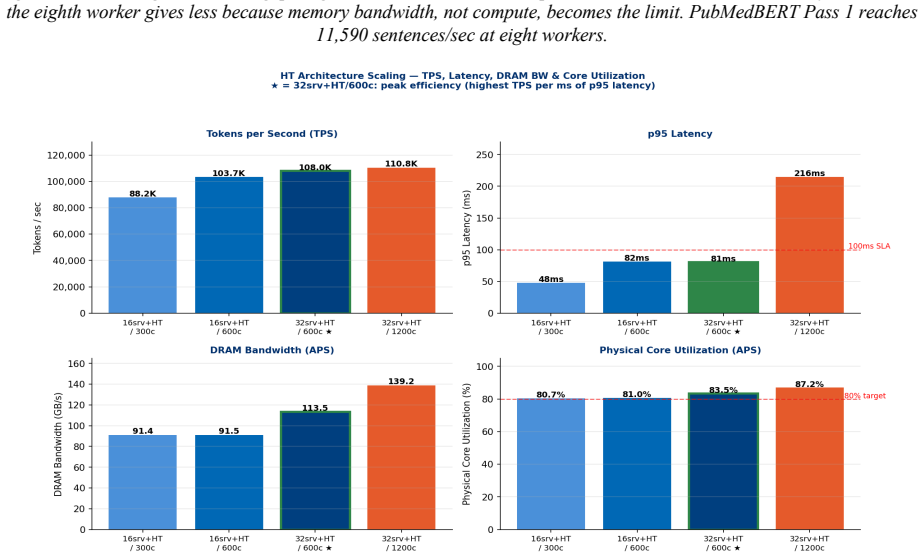
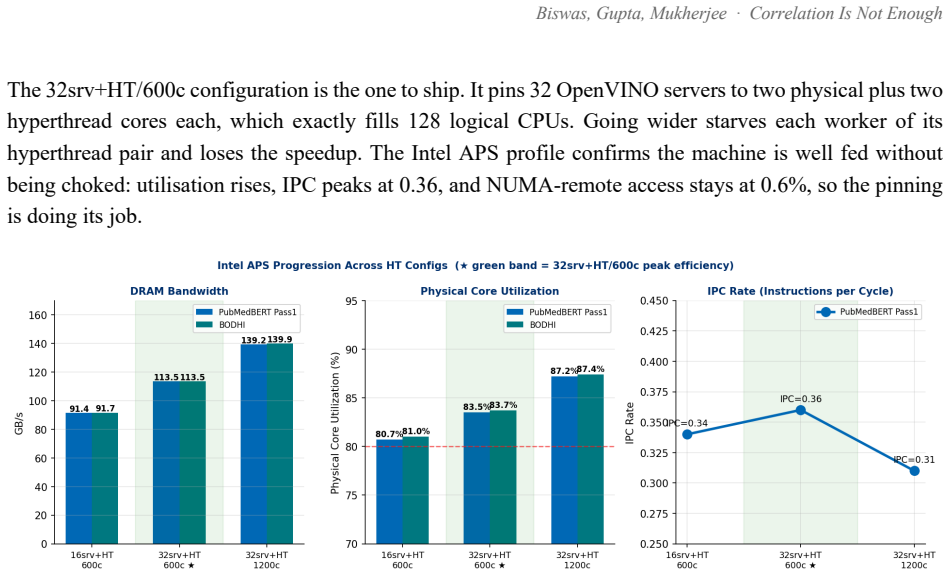
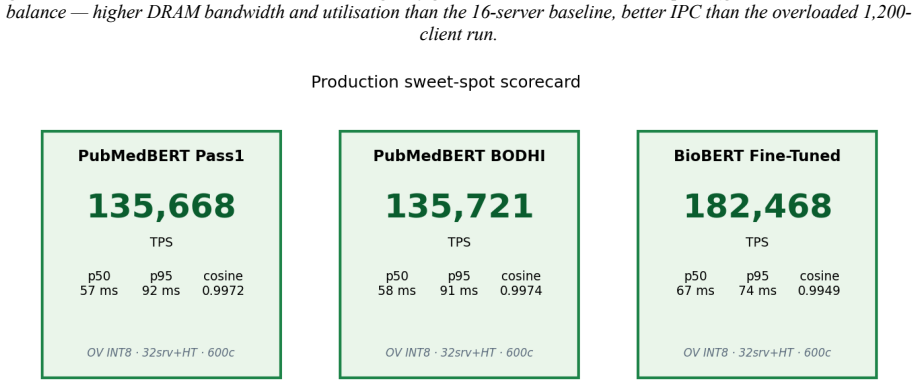
Production Two regimes matter in deployment: batch ingestion, where you embed a backlog as fast as possible, and online serving, where many clients hit the model at once. We characterised both on the AMX server. Figure 14. Batch ingestion. Throughput against worker count, NUMA-pinned, at batch 256. Near-linear to four workers; the eighth worker gives less...
-
[3]
Where the embedding layer sits
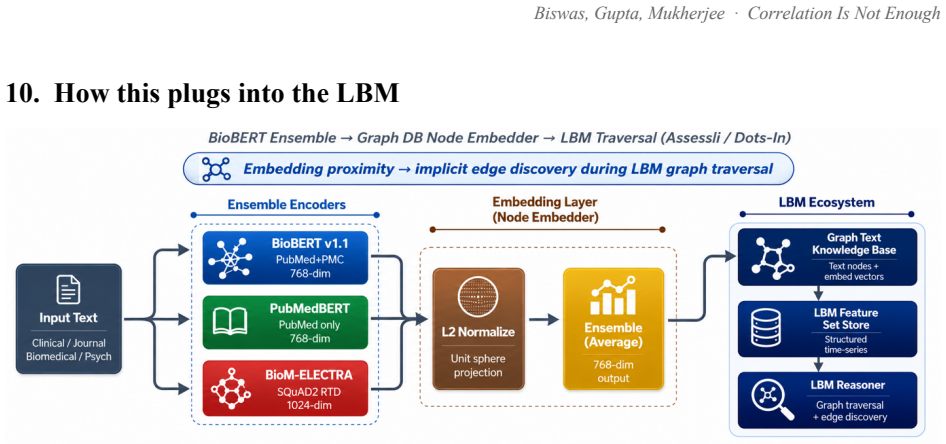
How this plugs into the LBM Figure 18. Where the embedding layer sits. The fine-tuned ensemble embeds every text node in the LBM’s graph store; the LBM walks the graph using explicit edges, its own causal priors, and embedding proximity, drawing new edges where proximity suggests a link that does not yet exist. The LBM keeps two stores. One is a structure...
Pith/arXiv arXiv 2026
-
[4]
Lee, J., et al. (2020). BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4), 1234–1240. [3] Gu, Y., et al. (2021). Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare. [4] Alrowili, S., Vijay-Shanker, K. (2021). Bio...
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.