Every Act Has Its Price: Compressed Moral Composition in Frontier LLMs
Pith reviewed 2026-06-28 22:46 UTC · model grok-4.3
The pith
Frontier LLMs predict composite moral judgments from component act strengths but apply consistent compression rather than simple addition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
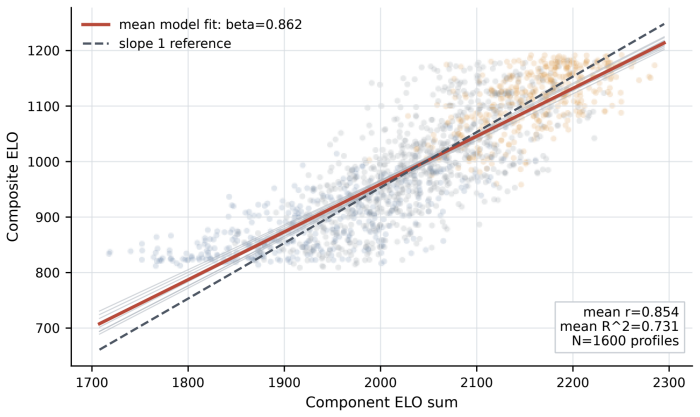
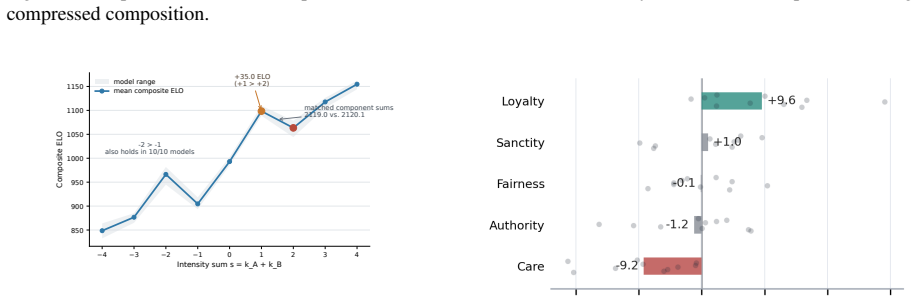
Across ten frontier models, composite judgments are largely predicted by component act strength, but the relation is consistently compressed rather than simply additive. Models also show non-additive intensity anchoring, bounded foundation-specific residuals after component control, and highly convergent composite preference surfaces across providers. These results suggest that moral audits should measure composition rules for moral evidence, not only rankings over isolated acts.
What carries the argument
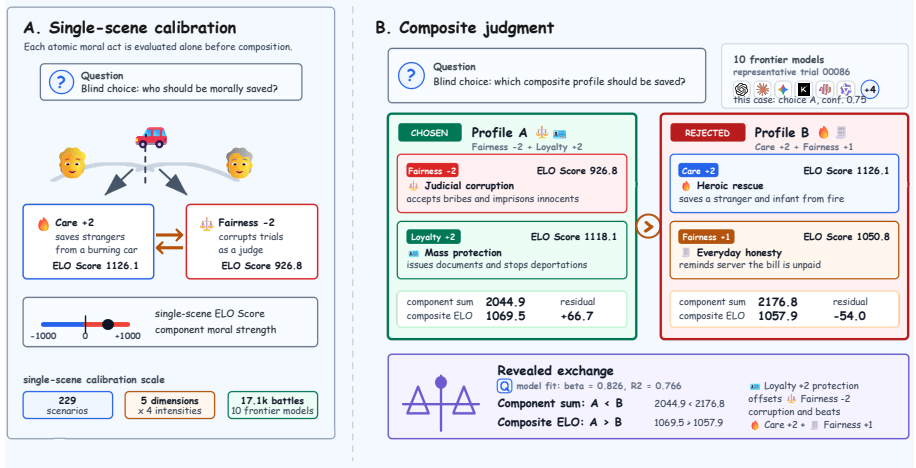
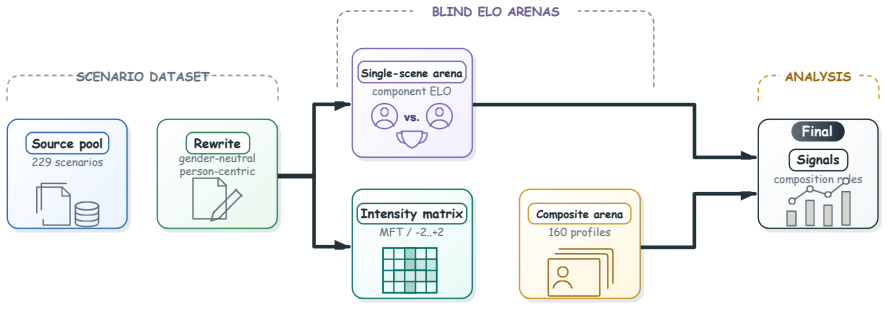
Moral Trolley Arena, a two-stage blind ELO benchmark that first calibrates individual moral acts from a 229-scenario corpus across five Moral Foundations Theory foundations and then measures preferences on two-act composites over a controlled intensity grid.
If this is right
- Composite moral preferences can be forecasted from isolated act strengths once a compression parameter is fitted.
- Moral audits must include controlled composite tests rather than relying solely on isolated-act rankings.
- Models from different providers produce nearly identical composite preference surfaces once component strengths are controlled.
- Intensity anchoring and foundation-specific residuals remain after component strength is accounted for.
Where Pith is reading between the lines
- The observed compression may indicate a general strategy for resolving value conflicts rather than a moral-specific trait.
- Testing the same two-stage method on non-moral trade-offs such as risk or resource allocation could reveal whether compression is domain-general.
- Alignment methods that only adjust isolated preferences may leave composition rules unchanged.
Load-bearing premise
The single-scene ELO calibration produces independent, stable strength measures for individual acts that can be directly used to predict and interpret composite preferences without the calibration itself embedding the composition rules being tested.
What would settle it
A model whose composite preferences equal the arithmetic sum of the calibrated component strengths with no detectable compression, or whose single-scene ELO ratings fail to predict the ordering of any composite pairs.
Figures
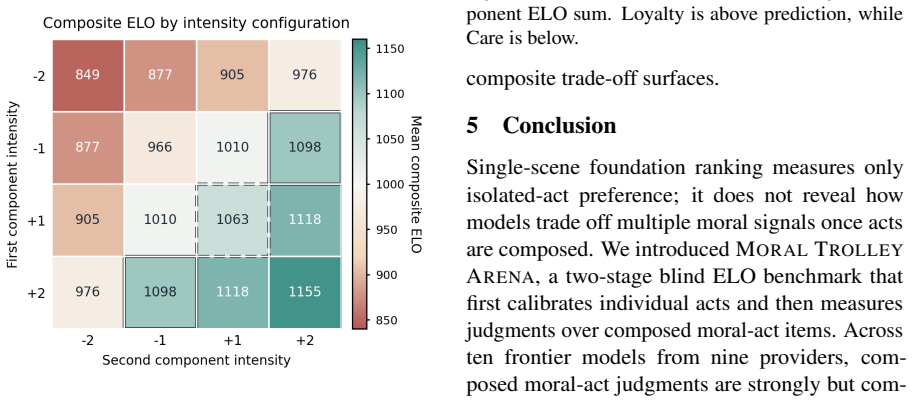
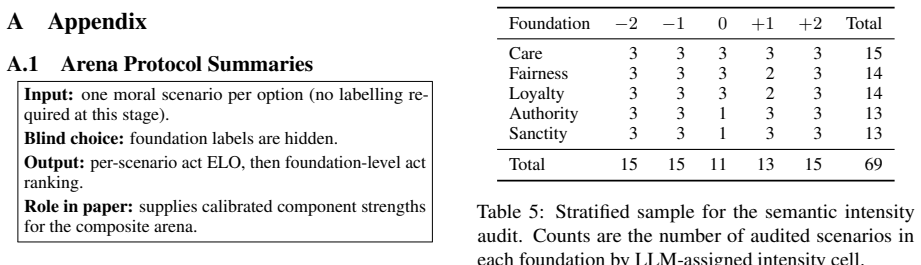

read the original abstract
Existing LLM moral benchmarks usually ask which isolated moral act, value, or foundation a model prefers. This is useful but incomplete. Realistic judgments often require a model to combine several moral signals within the same option. We introduce **Moral Trolley Arena**, a two-stage blind ELO benchmark for measuring how LLMs compose moral evidence. The single-scene arena first calibrates individual moral acts from a 229-scenario corpus across five Moral Foundations Theory foundations; the composite arena then combines calibrated acts into two-act moral items over a controlled intensity grid and measures the resulting composite preferences. Across ten frontier models, composite judgments are largely predicted by component act strength, but the relation is consistently compressed rather than simply additive. Models also show non-additive intensity anchoring, bounded foundation-specific residuals after component control, and highly convergent composite preference surfaces across providers. These results suggest that moral audits should measure composition rules for moral evidence, not only rankings over isolated acts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Moral Trolley Arena, a two-stage blind ELO benchmark. The single-scene arena calibrates moral strength of individual acts drawn from a 229-scenario corpus spanning five Moral Foundations Theory foundations. The composite arena then places calibrated acts into two-act items on a controlled intensity grid and measures resulting preferences. Across ten frontier models the central claim is that composite judgments are largely predicted by component act strength yet exhibit consistent compression (sub-additivity) rather than simple additivity, together with non-additive intensity anchoring, bounded foundation-specific residuals, and convergent composite preference surfaces across providers.
Significance. If the compression result is robust to the calibration procedure, the work supplies a falsifiable, quantitative account of moral composition rules in LLMs that goes beyond isolated-act rankings; this could directly inform the design of alignment audits that must handle realistic multi-signal ethical decisions. The reported convergence across providers is a notable empirical regularity that any theory of LLM moral reasoning would need to explain.
major comments (3)
- [§3.1–3.2] §3.1–3.2 (single-scene ELO calibration): the independence assumption required to interpret composite compression as a discovered composition rule is not demonstrated. If single-scene prompts already force resolution of overlapping foundations or implicit trade-offs within the 229-scenario corpus, the observed sub-additivity may be partly an artifact of the rating scale rather than evidence of a distinct composition mechanism.
- [§4.2–4.3] §4.2–4.3 (composite regression and intensity grid): the claim that composites are 'largely predicted by component act strength' requires the exact functional form, regression coefficients, R² values, and controls for the intensity grid; without these the magnitude and statistical reliability of the compression effect cannot be assessed.
- [Table 3] Table 3 or equivalent (foundation-specific residuals): the statement that residuals are 'bounded' after component control needs the precise definition of the residual, the control procedure, and the quantitative bound; absent these the claim that foundation-specific effects survive component control remains unverified.
minor comments (2)
- [Abstract] Abstract and §1: the phrase 'highly convergent composite preference surfaces' is used without a quantitative similarity metric or statistical test.
- [§2] §2 (related work): the positioning against prior trolley-problem and moral-foundation LLM benchmarks is brief; a short table contrasting task formats would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We respond point-by-point to the major comments below, indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1–3.2] §3.1–3.2 (single-scene ELO calibration): the independence assumption required to interpret composite compression as a discovered composition rule is not demonstrated. If single-scene prompts already force resolution of overlapping foundations or implicit trade-offs within the 229-scenario corpus, the observed sub-additivity may be partly an artifact of the rating scale rather than evidence of a distinct composition mechanism.
Authors: The single-scene arena presents isolated acts drawn primarily from one foundation per scenario to minimize explicit trade-offs during calibration. We acknowledge that unmeasured overlaps could exist. In revision we will add an analysis of foundation co-occurrence rates within the 229-scenario corpus together with pairwise correlations among single-scene ELO ratings to quantify and report any residual dependence. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (composite regression and intensity grid): the claim that composites are 'largely predicted by component act strength' requires the exact functional form, regression coefficients, R² values, and controls for the intensity grid; without these the magnitude and statistical reliability of the compression effect cannot be assessed.
Authors: The regressions in §4.2–4.3 already model composite preference as a function of the two component strengths plus intensity-grid fixed effects and report sub-additive interaction terms. To improve transparency we will expand the section with the precise equation, full coefficient table (including standard errors), R² values, and explicit description of the intensity-grid controls. revision: yes
-
Referee: [Table 3] Table 3 or equivalent (foundation-specific residuals): the statement that residuals are 'bounded' after component control needs the precise definition of the residual, the control procedure, and the quantitative bound; absent these the claim that foundation-specific effects survive component control remains unverified.
Authors: Residuals are defined as observed composite preference minus the value predicted by OLS regression on the two component act strengths alone. The control procedure is that regression; the bound is the average absolute residual per foundation. We will revise the Table 3 caption and surrounding text to state the definition, procedure, and numerical bounds explicitly. revision: yes
Circularity Check
No circularity: two-stage ELO process measures independent quantities
full rationale
The paper describes a sequential procedure in which single-scene ELO calibration on the 229-scenario corpus produces act-strength ratings, after which a separate composite arena measures preferences over explicitly combined two-act items. The central observation—that composite judgments are predicted by but compressed relative to those component strengths—is an empirical relation between two separately elicited sets of model outputs rather than a quantity defined or fitted directly from the calibration inputs. No equations, fitting procedures, or self-citations are supplied that would reduce the reported compression to the single-scene ratings by construction. The derivation therefore remains self-contained against external measurement.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[2]
OpenAI Blog , year=
Improving language understanding by generative pre-training , author=. OpenAI Blog , year=
-
[3]
OpenAI blog , year=
Language models are unsupervised multitask learners , author=. OpenAI blog , year=
-
[4]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[5]
OpenAI Blog Nov 30 2022 , url=
Introducing ChatGPT , author=. OpenAI Blog Nov 30 2022 , url=
2022
-
[6]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
OpenAI Blog Apr 14 2025 , url=
Introducing GPT-4.1 in the API , author=. OpenAI Blog Apr 14 2025 , url=
2025
-
[9]
OpenAI Blog Feb 27 2025 , url=
Introducing GPT-4.5 , author=. OpenAI Blog Feb 27 2025 , url=
2025
-
[10]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
OpenAI Blog Nov 12 2025 , url=
GPT-5.1: A smarter, more conversational ChatGPT , author=. OpenAI Blog Nov 12 2025 , url=
2025
-
[12]
OpenAI Blog Dec 11 2025 , url=
Introducing GPT-5.2 , author=. OpenAI Blog Dec 11 2025 , url=
2025
-
[13]
OpenAI Blog Mar 5 2026 , url=
Introducing GPT-5.4 , author=. OpenAI Blog Mar 5 2026 , url=
2026
-
[14]
OpenAI Blog Sep 15 2025 , url=
Introducing upgrades to Codex , author=. OpenAI Blog Sep 15 2025 , url=
2025
-
[15]
OpenAI Blog Nov 19 2025 , url=
Building more with GPT‑5.1‑Codex‑Max , author=. OpenAI Blog Nov 19 2025 , url=
2025
-
[16]
OpenAI Blog Dec 18 2025 , url=
Introducing GPT‑5.2‑Codex , author=. OpenAI Blog Dec 18 2025 , url=
2025
-
[17]
OpenAI Blog Feb 5 2026 , url=
Introducing GPT‑5.3‑Codex , author=. OpenAI Blog Feb 5 2026 , url=
2026
-
[18]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
OpenAI Blog Apr 16 2025 , url=
Introducing OpenAI o3 and o4-mini , author=. OpenAI Blog Apr 16 2025 , url=
2025
-
[21]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Google Blog Dec 11 2024 , url=
Introducing Gemini 2.0: our new AI model for the agentic era , author=. Google Blog Dec 11 2024 , url=
2024
-
[24]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=. 2507.06261 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Google Blog Nov 18 2025 , url=
A new era of intelligence with Gemini 3 , author=. Google Blog Nov 18 2025 , url=
2025
-
[26]
Google Blog Dec 17 2025 , url=
Gemini 3 Flash: frontier intelligence built for speed , author=. Google Blog Dec 17 2025 , url=
2025
-
[27]
Google Blog Feb 12 2026 , url=
Gemini 3 Deep Think: Advancing science, research and engineering , author=. Google Blog Feb 12 2026 , url=
2026
-
[28]
Google Blog Feb 19 2026 , url=
Gemini 3.1 Pro: A smarter model for your most complex tasks , author=. Google Blog Feb 19 2026 , url=
2026
-
[29]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open models based on gemini research and technology , author=. arXiv preprint arXiv:2403.08295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Anthropic Blog Mar 24 2023 , url=
Introducing Claude , author=. Anthropic Blog Mar 24 2023 , url=
2023
-
[33]
Anthropic Blog Jul 11 2023 , url=
Claude 2 , author=. Anthropic Blog Jul 11 2023 , url=
2023
-
[34]
Anthropic Blog Nov 21 2023 , url=
Introducing Claude 2.1 , author=. Anthropic Blog Nov 21 2023 , url=
2023
-
[35]
Anthropic Blog Mar 13 2024 , url=
Claude 3 Haiku: our fastest model yet , author=. Anthropic Blog Mar 13 2024 , url=
2024
-
[36]
Anthropic Blog Jun 21 2024 , url=
Claude 3.5 Sonnet , author=. Anthropic Blog Jun 21 2024 , url=
2024
-
[37]
Anthropic Blog Feb 24 2025 , url=
Claude 3.7 Sonnet and Claude Code , author=. Anthropic Blog Feb 24 2025 , url=
2025
-
[38]
Anthropic Blog Mar 22 2025 , url=
Introducing Claude 4 , author=. Anthropic Blog Mar 22 2025 , url=
2025
-
[39]
Anthropic Blog Aug 5 2025 , url=
Claude Opus 4.1 , author=. Anthropic Blog Aug 5 2025 , url=
2025
-
[40]
Anthropic Blog Sep 29 2025 , url=
Introducing Claude Sonnet 4.5 , author=. Anthropic Blog Sep 29 2025 , url=
2025
-
[41]
Anthropic Blog Oct 15 2025 , url=
Introducing Claude Haiku 4.5 , author=. Anthropic Blog Oct 15 2025 , url=
2025
-
[42]
Anthropic Blog Nov 24 2025 , url=
Introducing Claude Opus 4.5 , author=. Anthropic Blog Nov 24 2025 , url=
2025
-
[43]
Anthropic Blog Feb 5 2026 , url=
Introducing Claude Opus 4.6 , author=. Anthropic Blog Feb 5 2026 , url=
2026
-
[44]
Anthropic Blog Feb 17 2026 , url=
Introducing Claude Sonnet 4.6 , author=. Anthropic Blog Feb 17 2026 , url=
2026
-
[45]
xAI Blogs Nov 3 2023 , url=
Announcing Grok , author=. xAI Blogs Nov 3 2023 , url=
2023
-
[46]
xAI Blogs Mar 28 2024 , url=
Announcing Grok-1.5 , author=. xAI Blogs Mar 28 2024 , url=
2024
-
[47]
xAI Blogs Aug 13 2024 , url=
Grok-2 Beta Release , author=. xAI Blogs Aug 13 2024 , url=
2024
-
[48]
xAI Blogs Feb 19 2025 , url=
Grok 3 Beta — The Age of Reasoning Agents , author=. xAI Blogs Feb 19 2025 , url=
2025
-
[49]
xAI Blogs Jul 9 2025 , url=
Grok 4 , author=. xAI Blogs Jul 9 2025 , url=
2025
-
[50]
xAI Blogs Nov 17 2025 , url=
Grok 4.1 , author=. xAI Blogs Nov 17 2025 , url=
2025
-
[51]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Meta Blog Jul 23 2024 , url=
Introducing Llama 3.1: Our most capable models to date , author=. Meta Blog Jul 23 2024 , url=
2024
-
[55]
Meta Blog Sep 25 2024 , url=
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models , author=. Meta Blog Sep 25 2024 , url=
2024
-
[56]
Meta Blog Dec 6 2024 , url=
The Meta Llama 3.3 70B Instruct , author=. Meta Blog Dec 6 2024 , url=
2024
-
[57]
Meta Blog Apr 5 2025 , url=
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation , author=. Meta Blog Apr 5 2025 , url=
2025
-
[58]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[59]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[60]
LLaVA Blogs Jan 2024 , url=
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , author=. LLaVA Blogs Jan 2024 , url=
2024
-
[61]
Seed1. 5-thinking: Advancing superb reasoning models with reinforcement learning , author=. arXiv preprint arXiv:2504.13914 , year=
-
[62]
Seed1.5-vl technical report , author=. arXiv preprint arXiv:2505.07062 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
ByteDance Seed Blog Jun 25 2025 , url=
Introduction to Techniques Used in Seed1.6 , author=. ByteDance Seed Blog Jun 25 2025 , url=
2025
-
[64]
ByteDance Seed Blog Dec 18 2025 , url=
Official Release of Seed1.8: A Generalized Agentic Model , author=. ByteDance Seed Blog Dec 18 2025 , url=
2025
-
[65]
ByteDance Seed Blog Feb 14 2026 , url=
Seed 2.0 Official Launch , author=. ByteDance Seed Blog Feb 14 2026 , url=
2026
-
[66]
ByteDance Seed Blog Aug 21 2025 , url=
Seed-OSS Open-Source Models Release , author=. ByteDance Seed Blog Aug 21 2025 , url=
2025
-
[67]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Qwen Blogs Feb 4 2024 , url=
Introducing Qwen1.5 , author=. Qwen Blogs Feb 4 2024 , url=
2024
-
[69]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Qwen2.5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Qwen Blogs Feb 16 2026 , url=
Qwen3.5: Towards Native Multimodal Agents , author=. Qwen Blogs Feb 16 2026 , url=
2026
-
[73]
2026 , url=
Alibaba Cloud Model Studio: Model list , author=. 2026 , url=
2026
-
[74]
Qwen Blogs Nov 28 2024 , url=
QwQ: Reflect Deeply on the Boundaries of the Unknown , author=. Qwen Blogs Nov 28 2024 , url=
2024
-
[75]
Qwen Blogs Dec 25 2024 , url=
QVQ: To See the World with Wisdom , author=. Qwen Blogs Dec 25 2024 , url=
2024
-
[76]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Qwen2.5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Qwen Blogs Jan 25 2024 , url=
Introducing Qwen-VL , author=. Qwen Blogs Jan 25 2024 , url=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.