Adaptive Turn-Taking for Real-time Multi-Party Voice Agents
Pith reviewed 2026-06-29 04:59 UTC · model grok-4.3
The pith
ModeratorLM conditions a speech LLM on an explicit conversational role to improve turn-taking decisions in multi-party voice interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By conditioning turn-taking behavior on an explicitly assigned role, ModeratorLM achieves over 40% better precision and over 70% better recall in deciding when to speak, compared to non-role baselines, on real-world meetings and the RolePlayConv dataset.
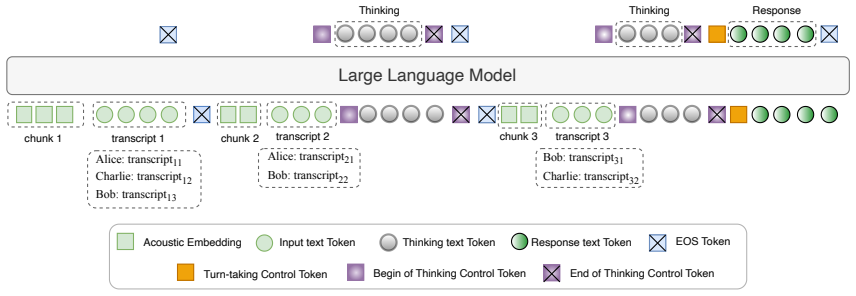
What carries the argument
Role-conditioned turn-taking decision making in a chunk-wise streaming speech LLM, where the assigned role guides responses to floor competition.
If this is right
- Explicit role assignment enables better handling of dynamic floor competition in multi-party talks.
- Chain-of-thought reasoning over role and context further refines interruption decisions.
- Use of synthetic RolePlayConv data supports training for diverse assistant roles.
- Substantial reduction in false-positive interruptions improves user experience in group settings.
Where Pith is reading between the lines
- Role conditioning could be tested in other modalities like video conferencing agents.
- The method might extend to agents that adapt roles dynamically during a conversation.
- Integration with real-time user feedback could further optimize turn-taking performance.
Load-bearing premise
Explicitly assigning a conversational role to the model produces measurably better turn-taking decisions under dynamic floor competition.
What would settle it
An experiment showing no improvement in turn-taking precision or recall when comparing role-conditioned models to non-role baselines on the same datasets.
Figures
read the original abstract
Turn-taking in multi-party spoken conversations remains a fundamental challenge for voice-based agents, particularly under dynamic floor competition and varying user expectations. We propose ModeratorLM, a role-playing voice agent that conditions turn-taking behavior on an explicitly assigned role in multi-party settings. The system is built on a speech large language model operating in chunk-wise streaming manner. We further introduce a reasoning-augmented variant that incorporates chain-of-thought reasoning over conversational context and the assigned role. We construct RolePlayConv, a large-scale synthetic dataset of spoken multi-party conversations with diverse assistant roles. Experiments on real-world meeting data and RolePlayConv show improved turn-taking precision by over 40% and recall by more than 70%, while substantially reducing false-positive interruptions compared to non-role-conditioned baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ModeratorLM, a role-playing voice agent based on a speech large language model operating in a chunk-wise streaming manner that conditions turn-taking behavior on an explicitly assigned role in multi-party settings. It describes a reasoning-augmented variant incorporating chain-of-thought reasoning over context and role, introduces the RolePlayConv synthetic dataset of spoken multi-party conversations with diverse assistant roles, and reports experiments on real-world meeting data and RolePlayConv claiming over 40% improvement in turn-taking precision and more than 70% in recall with reduced false-positive interruptions relative to non-role-conditioned baselines.
Significance. Turn-taking under dynamic floor competition is a core challenge for multi-party voice agents. Explicit role conditioning is a plausible mechanism that could improve decision-making if the empirical gains hold. The construction of RolePlayConv is a constructive contribution that could support future work if released with documentation. However, the absence of any methods, architecture, dataset statistics, evaluation protocol, or statistical tests means the claimed improvements cannot be assessed and the significance remains undetermined.
major comments (1)
- [Abstract] Abstract: the central empirical claim of >40% precision and >70% recall gains (plus reduced false positives) is presented with no accompanying description of model architecture, training procedure, evaluation metrics, baseline implementations, dataset sizes, or statistical tests. This absence is load-bearing because the paper's contribution is framed entirely as an empirical result.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below, noting that the manuscript body contains the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of >40% precision and >70% recall gains (plus reduced false positives) is presented with no accompanying description of model architecture, training procedure, evaluation metrics, baseline implementations, dataset sizes, or statistical tests. This absence is load-bearing because the paper's contribution is framed entirely as an empirical result.
Authors: Abstracts are intentionally concise high-level summaries. The manuscript provides full descriptions of the ModeratorLM architecture (role-conditioned streaming speech LLM, Section 3), training procedure (Section 4), RolePlayConv dataset construction and statistics (Section 4.2), evaluation metrics and baseline implementations (Section 5), and results including precision/recall gains and false-positive reductions (Section 5). Statistical tests are reported alongside the quantitative claims. We are willing to add one sentence to the abstract referencing the role-conditioning approach if the editor prefers. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical system (ModeratorLM) and evaluates it via experiments on real-world meeting data plus a new synthetic dataset (RolePlayConv). The central claims are measured improvements in precision, recall, and false-positive rate relative to non-role-conditioned baselines. No equations, parameter fits presented as predictions, self-definitional constructs, or load-bearing self-citation chains appear in the abstract or described method. The result is therefore an external empirical comparison rather than a reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Recent advances in large language models (LLMs) have driven rapid progress in the development of voice-based conversational agents [1, 2, 3, 4]. Modern spoken dialogue systems typi- cally combine low-latency streaming speech processing mod- ules with a core conversational component responsible for di- alogue management and response generation...
-
[2]
Adaptive Turn-Taking for Real-time Multi-Party Voice Agents
Methodology 2.1. ModeratorLM: System Architecture ModeratorLM consists of a speech encoder and a backbone LLM. The speech encoder processes each incoming audio chunk independently and produces chunk-level embeddings. These embeddings are projected into the LLM embedding space via a trainable linear projection layer, following prior work [18, 19]. The mult...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
as- sistant
Experimental Setup 3.1. Training Setup We use Qwen3-4B-Instruct-2507 [27] as the backbone LLM for ModeratorLM, and Qwen3-4B-Thinking-2507 for ModeratorLM-Think. For speech representation, we employ an in-house speech encoder trained with variable lookahead simi- lar to [28, 29], enabling block-wise attention during the infer- ence on variable-sized chunks...
-
[4]
assistant
(NSF-1), which consists of real recordings of formal meet- ings with approximately four speakers per session and an aver- age duration of six minutes. AsNSF-1 lacks role labels, we des- ignate one speaker as the “assistant” using a hybrid procedure that aggregates LLM-based rankings of assistant-like behavior with independent human evaluations. A role des...
-
[5]
Main Results Table 2 compares ModeratorLM variants against non-role- conditioned baselines on NSF-1 and RolePlayConv datasets
Results 4.1. Main Results Table 2 compares ModeratorLM variants against non-role- conditioned baselines on NSF-1 and RolePlayConv datasets. Moshi, trained on dyadic conversations, fails to generalize to multi-speaker settings, exhibiting very low recall and high false positive rates. The MP-Baseline, trained on multi-party conver- sations but without role...
-
[6]
Conclusions In this work, we introduced a role-playing voice agent for multi-party conversations that modulates turn-taking behavior based on an assigned role. Experimental results show that role-conditioned fine-tuning yields turn-taking decisions bet- ter aligned with configured preferences, and that incorporat- ing chain-of-thought reasoning further im...
-
[7]
Acknowledgments We would like to thank Ajay Srinivasamurthy, V olker Leutnant, Adam Kaplan, Andreas Schwarz, Raghavendra Bilgi and Sri Garimella for their support and valuable feedback
-
[8]
Generative AI was not used in the conceptualization, experi- mental design, or generation of the core scientific content
Generative AI Use Disclosure The authors acknowledge the use of generative AI tools during the preparation of this paper strictly for the purposes of edit- ing, polishing, and improving the readability of the manuscript. Generative AI was not used in the conceptualization, experi- mental design, or generation of the core scientific content. All co-authors...
-
[9]
Freeze-omni: A smart and low latency speech-to-speech dia- logue model with frozen llm,
X. Wang, Y . Li, C. Fu, Y . Shen, L. Xie, K. Li, X. Sun, and L. Ma, “Freeze-omni: A smart and low latency speech-to-speech dia- logue model with frozen llm,” arXiv preprint arXiv:2411.00774, 2024
-
[10]
Mini-omni: Language models can hear, talk while thinking in streaming, 2024,
Z. Xie and C. Wu, “Mini-omni: Language models can hear, talk while thinking in streaming, 2024,” URL https://arxiv. org/abs/2408.16725, 2024
-
[11]
Minmo: A multimodal large language model for seamless voice interaction,
Q. Chen, Y . Chen, Y . Chen, M. Chen, Y . Chen, C. Deng, Z. Du, R. Gao, C. Gao, Z. Gao et al. , “Minmo: A multimodal large language model for seamless voice interaction,” arXiv preprint arXiv:2501.06282, 2025
-
[12]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang et al., “Kimi-audio technical report,” arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,” arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Language model can listen while speaking,
Z. Ma, Y . Song, C. Du, J. Cong, Z. Chen, Y . Wang, Y . Wang, and X. Chen, “Language model can listen while speaking,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 39, no. 23, 2025, pp. 24 831–24 839
2025
-
[15]
Salmonn-omni: A codec-free llm for full-duplex speech understanding and generation,
W. Yu, S. Wang, X. Yang, X. Chen, X. Tian, J. Zhang, G. Sun, L. Lu, Y . Wang, and C. Zhang, “Salmonn-omni: A codec-free llm for full-duplex speech understanding and generation,” arXiv preprint arXiv:2411.18138, 2024
-
[16]
Talk- ing turns: Benchmarking audio foundation models on turn-taking dynamics,
S. Arora, Z. Lu, C.-C. Chiu, R. Pang, and S. Watanabe, “Talk- ing turns: Benchmarking audio foundation models on turn-taking dynamics,”arXiv preprint arXiv:2503.01174, 2025
-
[17]
Full-Duplex-Bench v1.5: Evaluating Overlap Handling for Full-Duplex Speech Models
G.-T. Lin, S.-Y . S. Kuan, Q. Wang, J. Lian, T. Li, and H.-y. Lee, “Full-duplex-bench v1. 5: Evaluating overlap handling for full- duplex speech models,”arXiv preprint arXiv:2507.23159, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Multi-party conversational agents: A survey,
S. Sapkota, M. S. Hasan, M. Shah, and S. Karmaker, “Multi-party conversational agents: A survey,” arXiv preprint arXiv:2505.18845, 2025
-
[19]
The design and im- plementation of xiaoice, an empathetic social chatbot,
L. Zhou, J. Gao, D. Li, and H.-Y . Shum, “The design and im- plementation of xiaoice, an empathetic social chatbot,”Computa- tional Linguistics, vol. 46, no. 1, pp. 53–93, 2020
2020
-
[20]
From persona to personalization: A survey on role-playing language agents. arxiv [cs. cl](april 2024),
J. Chen, X. Wang, R. Xu, S. Yuan, Y . Zhang, W. Shi, J. Xie, S. Li, R. Yang, T. Zhuet al., “From persona to personalization: A survey on role-playing language agents. arxiv [cs. cl](april 2024),” 2024
2024
-
[21]
Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models,
N. Wang, Z. Peng, H. Que, J. Liu, W. Zhou, Y . Wu, H. Guo, R. Gan, Z. Ni, J. Yang et al., “Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models,” in Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 14 743–14 777
2024
-
[22]
Characterglm: Customizing social charac- ters with large language models,
J. Zhou, Z. Chen, D. Wan, B. Wen, Y . Song, J. Yu, Y . Huang, P. Ke, G. Bi, L. Peng et al., “Characterglm: Customizing social charac- ters with large language models,” inProceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing: Industry Track, 2024, pp. 1457–1476
2024
-
[23]
Capturing minds, not just words: Enhancing role-playing lan- guage models with personality-indicative data,
Y . Ran, X. Wang, R. Xu, X. Yuan, J. Liang, Y . Xiao, and D. Yang, “Capturing minds, not just words: Enhancing role-playing lan- guage models with personality-indicative data,” inFindings of the Association for Computational Linguistics: EMNLP 2024 , 2024, pp. 14 566–14 576
2024
-
[24]
Character is destiny: Can role-playing language agents make persona-driven decisions?
R. Xu, X. Wang, J. Chen, S. Yuan, X. Yuan, J. Liang, Z. Chen, X. Dong, and Y . Xiao, “Character is destiny: Can role-playing language agents make persona-driven decisions?” arXiv preprint arXiv:2404.12138, 2024
-
[25]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in neural information pro- cessing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[26]
Sift-50m: A large-scale multilin- gual dataset for speech instruction fine-tuning,
P. Pandey, R. V . Swaminathan, K. Girish, A. Sen, J. Xie, G. P. Strimel, and A. Schwarz, “Sift-50m: A large-scale multilin- gual dataset for speech instruction fine-tuning,” arXiv preprint arXiv:2504.09081, 2025
-
[27]
Efficient streaming llm for speech recognition,
J. Jia, G. Keren, W. Zhou, E. Lakomkin, X. Zhang, C. Wu, F. Seide, J. Mahadeokar, and O. Kalinli, “Efficient streaming llm for speech recognition,” in ICASSP 2025-2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[28]
Omniflatten: An end-to- end gpt model for seamless voice conversation,
Q. Zhang, L. Cheng, C. Deng, Q. Chen, W. Wang, S. Zheng, J. Liu, H. Yu, C. Tan, Z. Du et al. , “Omniflatten: An end-to- end gpt model for seamless voice conversation,” arXiv preprint arXiv:2410.17799, 2024
-
[29]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Danget al., “Qwen2. 5-omni technical report,” arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Coser: Coordinat- ing llm-based persona simulation of established roles,
X. Wang, H. Wang, Y . Zhang, X. Yuan, R. Xu, J.-t. Huang, S. Yuan, H. Guo, J. Chen, S. Zhou et al. , “Coser: Coordinat- ing llm-based persona simulation of established roles,” in Forty- second International Conference on Machine Learning, 2025
2025
-
[31]
Meld: A multimodal multi-party dataset for emo- tion recognition in conversations,
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea, “Meld: A multimodal multi-party dataset for emo- tion recognition in conversations,” in Proceedings of the 57th annual meeting of the association for computational linguistics , 2019, pp. 527–536
2019
-
[32]
Pachat: Persona-aware speech assistant for multi-party dialogue,
D. Fu, X. Cheng, L. Li, X. Yang, L. Yang, and T. Jin, “Pachat: Persona-aware speech assistant for multi-party dialogue,” in Pro- ceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 29 313–29 330
2025
-
[33]
The amazon nova family of models: Tech- nical report and model card,
A. A. G. Intelligence, “The amazon nova family of models: Tech- nical report and model card,” 2024
2024
-
[34]
Zonos: an open-weight multilingual text-to-speech model (zonos-v0.1),
Zyphra, “Zonos: an open-weight multilingual text-to-speech model (zonos-v0.1),” https://github.com/Zyphra/Zonos, 2025
2025
-
[35]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv et al., “Qwen3 technical report,” arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Variable attention masking for configurable transformer trans- ducer speech recognition,
P. Swietojanski, S. Braun, D. Can, T. F. Da Silva, A. Ghoshal, T. Hori, R. Hsiao, H. Mason, E. McDermott, H. Silovsky et al., “Variable attention masking for configurable transformer trans- ducer speech recognition,” in ICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[37]
Durep: Dual-mode speech representation learning via asr-aware distillation,
P. R. Male, S. N. Ray, H. Arsikere, A. Jaiswal, P. Swarup, P. Sen, D. Chakrabarty, K. V . V . Girish, N. Bhave, F. Weber, S. Bhattacharya, and S. Garimella, “Durep: Dual-mode speech representation learning via asr-aware distillation,” 2025. [Online]. Available: https://arxiv.org/abs/2505.19774
-
[38]
Montreal forced aligner: Trainable text-speech align- ment using kaldi
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Son- deregger, “Montreal forced aligner: Trainable text-speech align- ment using kaldi.” inInterspeech, vol. 2017, 2017, pp. 498–502
2017
-
[39]
V oxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation,
C. Wang, M. Riviere, A. Lee, A. Wu, C. Talnikar, D. Haz- iza, M. Williamson, J. Pino, and E. Dupoux, “V oxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation,” inACL, 2021
2021
-
[40]
Mls: A large-scale multilin- gual dataset for scalable speech research,
V . Pratap, Q. Xu, S. Aniceto et al., “Mls: A large-scale multilin- gual dataset for scalable speech research,” inInterspeech, 2020
2020
-
[41]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis et al. , “Common voice: A massively-multilingual speech corpus,” inLREC, 2020
2020
-
[42]
The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage,
D. Galvez et al. , “The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage,” arXiv preprint arXiv:2111.09340, 2021
-
[43]
The ami meeting corpus: A pre-announcement,
J. Carletta, S. Ashby, S. Bourban, M. Flynn, M. Guillemot, T. Hain, J. Kadlec, V . Karaiskos, W. Kraaij, M. Kronenthalet al., “The ami meeting corpus: A pre-announcement,” in Interna- tional workshop on machine learning for multimodal interaction. Springer, 2005, pp. 28–39
2005
-
[44]
The fisher corpus: A resource for the next generations of speech-to-text
C. Cieri, D. Miller, and K. Walker, “The fisher corpus: A resource for the next generations of speech-to-text.”
-
[45]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large lan- guage models,”arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Notsofar-1 challenge: New datasets, baseline, and tasks for dis- tant meeting transcription,
A. Vinnikov, A. I. Mark, A. Hurvitz, I. Abramovski, S. Koubi, I. Gurvich, S. Peer, X. Xiao, B. Elizalde, N. Kanda et al. , “Notsofar-1 challenge: New datasets, baseline, and tasks for dis- tant meeting transcription,” inProc. CHiME 2024, 2024
2024
-
[47]
Qwq-32b: Embracing the power of reinforcement learning,
Q. Team, “Qwq-32b: Embracing the power of reinforcement learning,” 2025
2025
-
[48]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing et al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information pro- cessing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[49]
Claude 3.5 Sonnet,
Anthropic, “Claude 3.5 Sonnet,” https://www.anthropic.com/ news/claude-3-5-sonnet, 2024
2024
-
[50]
Streaming sequence-to-sequence learning with delayed streams modeling,
N. Zeghidour, E. Kharitonov, M. Orsini, V . V olhejn, G. de Marmiesse, E. Grave, P. P´erez, L. Mazar´e, and A. D´efossez, “Streaming sequence-to-sequence learning with delayed streams modeling,”arXiv preprint arXiv:2509.08753, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.