AgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Pith reviewed 2026-06-27 06:39 UTC · model grok-4.3
The pith
Agent assessment can be performed by other agents using standardized protocols instead of fixed benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentBeats implements AAA by letting judge agents interact with subject agents solely through A2A and MCP protocols, eliminating the need for benchmark-specific harnesses. The design supports five operation modes that reconcile real-world constraints on openness, privacy, and reproducibility. The community competition demonstrates broad applicability across heterogeneous agent designs, while the coding case study shows that agentified scores align with public records yet reveal previously unavailable comparative insights about agent architectures.
What carries the argument
Agentified Agent Assessment (AAA) realized through judge agents communicating via A2A task-management and MCP tool-access protocols.
If this is right
- Assessment logic becomes independent of any particular agent implementation.
- Head-to-head comparisons become possible across agents that previously could not share a common test harness.
- Multi-agent and multi-judge evaluations can be run at community scale without custom integration work.
- Reproducibility improves because all interactions follow the same open protocols rather than bespoke code.
- Five operation modes allow the same framework to accommodate different privacy and openness requirements.
Where Pith is reading between the lines
- The protocol-based approach could support evolving, agent-improved benchmarks in which judge agents themselves are updated over time.
- The same structure might be tested in domains beyond coding, such as web navigation or tool-use agents, to check whether fidelity holds outside the reported case study.
- Widespread adoption would lower the barrier for independent developers to submit agents to shared evaluations without writing benchmark-specific adapters.
- The five operation modes offer a template that industry teams could adapt when internal privacy rules prevent fully open competitions.
Load-bearing premise
Judge agents interacting through the protocols can produce assessments that match the fidelity of traditional public records.
What would settle it
A controlled experiment in which the same set of subject agents receives both agentified assessments and conventional benchmark scores, and the two sets of results diverge substantially in rankings or absolute values.
Figures



read the original abstract
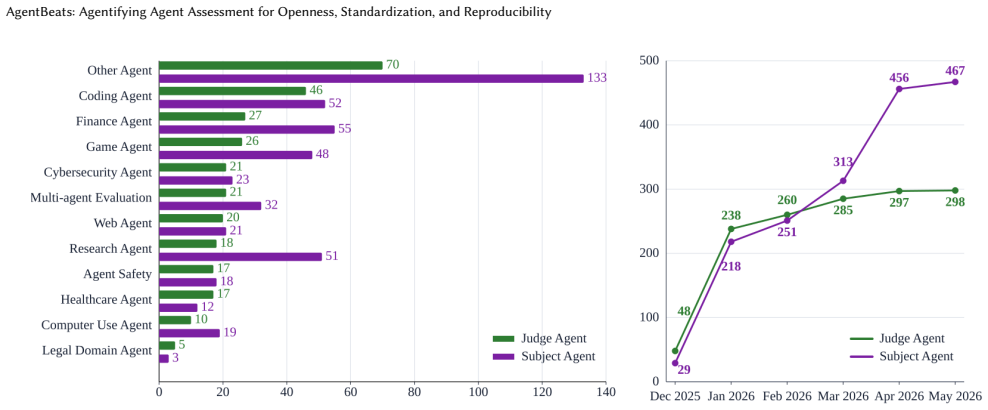
Agent systems are advancing quickly across domains, but their evaluation remains fragmented. Most benchmarks rely on fixed, LLM-centric harnesses that require heavy integration, create test-production mismatch, and limit fair comparison across diverse agent designs. The root problem is the lack of an open, agent-agnostic assessment interface. We advocate Agentified Agent Assessment (AAA), where evaluation is performed by judge agents and all participants interact through standardized protocols: A2A for task management and MCP for tool access. Conventional benchmarking defines two separate interfaces, one for the benchmark and one for the agent, while AAA only needs one; this yields a generic, unified framework that separates assessment logic from agent implementation and enables reproducible, interoperable, and multi-agent evaluation. We further introduce AgentBeats as a concrete realization of AAA: we identify five practical operation modes that make standardized assessment compatible with real-world constraints on openness, privacy, and reproducibility. To evaluate our design at scale, we conduct two studies: a five-month open competition that drew 298 judge agents across 12 categories together with 467 subject agents from independent participants, showing that AAA applies across a heterogeneous range of benchmarks; and a case study on coding agents that confirms agentified evaluation preserves fidelity with the public record while surfacing previously missing head-to-head results, yielding research insights about agent design. Combining a community-scale field study and a controlled coding case study, we verify that AAA delivers coverage, practicality, and fidelity across heterogeneous scenarios at scale. Together, AAA and AgentBeats offer a clear path toward open, standardized, and reproducible agent assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Agentified Agent Assessment (AAA) as an alternative to fixed LLM-centric benchmarks: evaluation is performed by judge agents interacting with subject agents via standardized A2A (task management) and MCP (tool access) protocols. It introduces AgentBeats as a concrete implementation supporting five practical operation modes that address openness, privacy, and reproducibility constraints. Validation rests on two empirical studies—an open five-month competition involving 298 judge agents and 467 subject agents across 12 categories, plus a controlled coding-agent case study—claimed to demonstrate coverage, practicality, and fidelity at scale while enabling head-to-head comparisons unavailable in traditional setups.
Significance. If the reported studies hold, the work would provide a practical path toward interoperable, agent-agnostic evaluation frameworks that separate assessment logic from agent implementation. This could reduce integration overhead and test-production mismatch in agent research, while the open-competition design offers a model for community-scale reproducibility.
major comments (2)
- [Abstract] Abstract (final paragraph): the claim that the coding case study 'confirms agentified evaluation preserves fidelity with the public record' is load-bearing for the central fidelity assertion, yet the abstract provides no quantitative metric, statistical test, or comparison protocol (e.g., agreement rate, error distribution) used to establish preservation; without this, the verification cannot be assessed.
- [Abstract] Abstract (study description): the field study reports participant counts (298 judges, 467 subjects, 12 categories) but supplies no outcome measures—such as category coverage statistics, inter-judge agreement, or practicality indicators (e.g., integration effort, privacy compliance rates)—that would substantiate the claim of applicability 'across a heterogeneous range of benchmarks.'
minor comments (2)
- [Abstract] The five operation modes of AgentBeats are introduced but not enumerated or characterized in the abstract; a concise listing or table would clarify how they map to real-world constraints.
- [Abstract] Notation for protocols (A2A, MCP) is used without an initial definition or reference to their specifications; this should be supplied on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly identify opportunities to strengthen the presentation of our empirical results. We address each point below and will revise the abstract to incorporate additional quantitative details.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the claim that the coding case study 'confirms agentified evaluation preserves fidelity with the public record' is load-bearing for the central fidelity assertion, yet the abstract provides no quantitative metric, statistical test, or comparison protocol (e.g., agreement rate, error distribution) used to establish preservation; without this, the verification cannot be assessed.
Authors: We agree that the abstract would be strengthened by including quantitative metrics supporting the fidelity claim. The full manuscript details the coding case study with agreement rates to public benchmarks and error distribution analysis. We will revise the abstract to include these key metrics. revision: yes
-
Referee: [Abstract] Abstract (study description): the field study reports participant counts (298 judges, 467 subjects, 12 categories) but supplies no outcome measures—such as category coverage statistics, inter-judge agreement, or practicality indicators (e.g., integration effort, privacy compliance rates)—that would substantiate the claim of applicability 'across a heterogeneous range of benchmarks.'
Authors: The referee correctly notes that the abstract emphasizes scale without outcome measures. The full paper reports category coverage and related indicators from the competition. We will partially revise the abstract to add selected outcome measures such as coverage statistics, subject to length constraints. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper advances a framework (AAA/AgentBeats) whose central claims of coverage, practicality, and fidelity are verified directly by two external empirical studies—an open competition drawing 298 judge agents and 467 subject agents across 12 categories, plus a separate coding case study matching public records—rather than any mathematical derivation, fitted-parameter prediction, or self-referential chain. No equations, ansatzes, or uniqueness theorems appear; the validation rests on participant-submitted data outside the authors' control, rendering the reported outcomes self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Judge agents interacting through standardized protocols can produce reliable and faithful assessments of subject agents
Reference graph
Works this paper leans on
-
[1]
A2A. 2025. Agent2Agent (A2A) Protocol Specification. Online draft specification. https://a2a-protocol.org/latest/specification/ Draft v0.3.0
2025
-
[2]
Anthropic. 2026. Claude Code: Anthropic’s Agentic Coding System. https: //www.anthropic.com/product/claude-code. Accessed: 2026-05-03
2026
-
[3]
2026.Claude Mythos Preview System Card
Anthropic. 2026.Claude Mythos Preview System Card. Technical Report. An- thropic. https://www.anthropic.com/claude-mythos-preview-system-card Published April 2026
2026
-
[4]
2026.Claude Opus 4.7 System Card
Anthropic. 2026.Claude Opus 4.7 System Card. Technical Report. Anthropic. https://www.anthropic.com/system-cards Published April 16, 2026
2026
-
[5]
Elron Bandel, Asaf Yehudai, Lilach Eden, Yehoshua Sagron, Yotam Perlitz, Elad Venezian, Natalia Razinkov, Natan Ergas, Shlomit Shachor Ifergan, Segev Shlo- mov, Michal Jacovi, Leshem Choshen, Liat Ein-Dor, Yoav Katz, and Michal Shmueli-Scheuer. 2026. General Agent Evaluation. arXiv:2602.22953 [cs.AI] https://arxiv.org/abs/2602.22953
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Elron Bandel, Asaf Yehudai, Alexandre Lacoste, Avijit Ghosh, Graham Neubig, Margaret Mitchell, Michal Shmueli-Scheuer, and Leshem Choshen. 2026. Position: Agentic Systems Should be General. InForty-third International Conference on Machine Learning Position Paper Track. https://openreview.net/forum?id=WM YI7TFDmi
2026
-
[7]
Elron Bandel, Asaf Yehudai, and Michal Shmueli-Scheuer. 2026. Ready For General Agents? Let’s Test It.. InICLR Blogposts 2026. https://iclr-blogposts.gith ub.io/2026/blog/2026/general-agent-evaluation/
2026
-
[8]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan
-
[9]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
𝜏 2-Bench: Evaluating Conversational Agents in a Dual-Control Environ- ment. arXiv:2506.07982 [cs.AI] https://arxiv.org/abs/2506.07982
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander Mądry. 2025. MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering. arXiv:2410.07095 [cs.CL] https: //arxiv.org/abs/2410.07095
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Sharifymoghad- dam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. 2025. BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent...
-
[13]
Thibault Le Sellier De Chezelles, Maxime Gasse, Alexandre Drouin, Massimo Caccia, Léo Boisvert, Megh Thakkar, Tom Marty, Rim Assouel, Sahar Omidi Shayegan, Lawrence Keunho Jang, Xing Han Lù, Ori Yoran, Dehan Kong, Frank F. Xu, Siva Reddy, Quentin Cappart, Graham Neubig, Ruslan Salakhutdinov, Nicolas Chapados, and Alexandre Lacoste. 2025. The BrowserGym Ec...
-
[14]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. 2025. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?C...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.16941 2025
-
[15]
2026.Gemini 3.1 Pro Model Card
Google DeepMind. 2026.Gemini 3.1 Pro Model Card. Technical Report. Google DeepMind. https://deepmind.google/models/model-cards/gemini-3-1-pro/ Published February 2026
2026
-
[16]
Harbor Framework Team. 2026. Harbor Framework: A framework for evaluating and optimizing agents and models in container environments. https://github.com/laude-institute/harbor
2026
-
[17]
Hugging Face. 2026. Hugging Face. https://huggingface.co. Open platform for machine learning models, datasets, and evaluation
2026
-
[18]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y. Ng, and Jonathan H. Chen. 2025. MedAgentBench: A Realistic Virtual EHR Environment to Benchmark Medical LLM Agents. arXiv:2501.14654 [cs.LG] https://arxiv.org/abs/2501.14654
-
[19]
Kaggle. 2025. Kaggle Game Arena. https://www.kaggle.com/game-arena A benchmarking platform where AI models and agents compete in strategic games
2025
-
[20]
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, Franck Ndzomga, Dheeraj Oruganty, Sophie Luskin, Kangheng Liu, Botao Yu, Amit Arora, Dongy- oon Hahm, Harsh Trivedi, Huan Sun, Juyong Lee, Tengjun Jin, Yifan Mai, Yifei Zhou, Yuxuan Zhu, Rishi Bommasani, Daniel Kang, ...
2025
-
[21]
Alexandre Lacoste, Nicolas Gontier, Oleh Shliazhko, Aman Jaiswal, Kusha Sa- reen, Shailesh Nanisetty, Joan Cabezas, Manuel Del Verme, Omar G. Younis, Simone Baratta, Matteo Avalle, Imene Kerboua, Xing Han Lù, Elron Bandel, Michal Shmueli-Scheuer, Asaf Yehudai, Leshem Choshen, Jonathan Lebensold, Sean Hughes, Massimo Caccia, Alexandre Drouin, Siva Reddy, T...
-
[22]
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, Kaibo Liu, Zheng Fang, Lanshen Wang, Jiazheng Ding, Xuanming Zhang, Yuqi Zhu, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, Yongbin Li, Bin Gu, and Mengfei Yang. 2024. DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories. InFindings of the...
-
[23]
LiteLLM. 2026. LiteLLM. https://github.com/BerriAI/litellm
2026
- [24]
- [25]
-
[26]
MCP. 2025. Model Context Protocol (MCP) Specification. Online technical specification. https://modelcontextprotocol.io/specification/2025-11-25
2025
-
[27]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander Glenn Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, Estefany Kelly Buchanan, et al. 2026. Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces.CoRRabs/2601.11868 (2026). arXiv:2601.11868 https://doi.org/10.48550/arXiv.2601.11868
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.11868 2026
-
[28]
Meta. 2026. OpenEnv. https://github.com/meta-pytorch/OpenEnv. Open-source platform for environment-based agent training and evaluation
2026
-
[29]
MLflow. 2026. MLflow. https://github.com/mlflow/mlflow
2026
-
[30]
Moonshot AI. 2026. Kimi K2.6: Advancing Open-Source Coding. https://www.ki mi.com/blog/kimi-k2-6. Moonshot AI blog. Accessed: 2026-05-03
2026
-
[31]
NVIDIA. 2026. NeMo Evaluator. https://github.com/NVIDIA-NeMo/Evaluator
2026
-
[32]
OpenAI. 2025. Building More with GPT-5.1-Codex-Max. https://openai.com/ind ex/gpt-5-1-codex-max/. Accessed: 2026-05-03
2025
-
[33]
OpenAI. 2026. ChatGPT Atlas. https://chatgpt.com/atlas
2026
-
[34]
OpenAI. 2026. Codex: OpenAI’s Coding Agent. https://developers.openai.com/ codex/cloud. Accessed: 2026-05-03
2026
-
[35]
OpenAI. 2026. GPT-5.4 Thinking System Card. https://openai.com/index/gpt-5- 4-thinking-system-card/. Accessed: 2026-05-03
2026
-
[36]
OpenCode Contributors. 2026. OpenCode: The Open Source AI Coding Agent. https://github.com/anomalyco/opencode. Version 1.14.39; accessed May 5, 2026
2026
-
[37]
OpenHands. 2026. OpenHands Repository. https://github.com/OpenHands/OpenHands/tree/main/evaluation/benchmarks
2026
-
[38]
Krista Opsahl-Ong, Arnav Singhvi, Jasmine Collins, Ivan Zhou, Cindy Wang, Ashutosh Baheti, Owen Oertell, Jacob Portes, Sam Havens, Erich Elsen, Michael Bendersky, Matei Zaharia, and Xing Chen. 2026. OfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning. arXiv:2603.08655 [cs.AI] https: //arxiv.org/abs/2603.08655
-
[39]
Davide Paglieri, Bartłomiej Cupiał, Sam Coward, Ulyana Piterbarg, Maciej Wołczyk, Akbir Khan, Eduardo Pignatelli, Łukasz Kuciński, Lerrel Pinto, Rob Fergus, Jakob Nicolaus Foerster, Jack Parker-Holder, and Tim Rocktäschel. 2024. Benchmarking Agentic LLM and VLM Reasoning On Games.arXiv preprint arXiv:2411.13543(2024)
-
[40]
Perplexity AI. 2026. Comet. https://www.perplexity.ai/comet
2026
-
[41]
Qwen Team. 2026. Qwen3.5: Towards Native Multimodal Agents. https: //qwen.ai/blog?id=qwen3.5
2026
-
[42]
Qwen Team. 2026. Qwen3.6-Plus: Towards Real World Agents. https://qwen.ai/ blog?id=qwen3.6
2026
-
[43]
Pascal J Sager, Benjamin Meyer, Peng Yan, Rebekka von Wartburg-Kottler, Layan Etaiwi, Aref Enayati, Gabriel Nobel, Ahmed Abdulkadir, Benjamin F Grewe, and Thilo Stadelmann. 2025. A Comprehensive Survey of Agents for Computer Use: Foundations, Challenges, and Future Directions.arXiv preprint arXiv:2501.16150 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [44]
-
[45]
Scale AI. 2025. SWE-Bench Pro Leaderboard (Public Dataset). https://labs.scale .com/leaderboard/swe_bench_pro_public. Scale Labs leaderboard. Accessed: 2026-05-03
2025
- [46]
-
[47]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
2022
-
[48]
Weights & Biases. 2026. Weights & Biases. https://wandb.ai
2026
-
[49]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu
-
[50]
InAdvances in Neural Information Processing Systems 38 (NeurIPS 2024)
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. InAdvances in Neural Information Processing Systems 38 (NeurIPS 2024). http://papers.nips.cc/paper_files/paper/2024/hash/5d413e48f 84dc61244b6be550f1cd8f5-Abstract-Datasets_and_Benchmarks_Track.html
2024
- [51]
-
[52]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. https://arxiv.org/abs/2405 .15793
2024
-
[53]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. Tau- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. arXiv preprint arXiv:2406.12045(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[55]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. 2024. Webarena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations, Vol. 2024. 15585–15606
2024
-
[56]
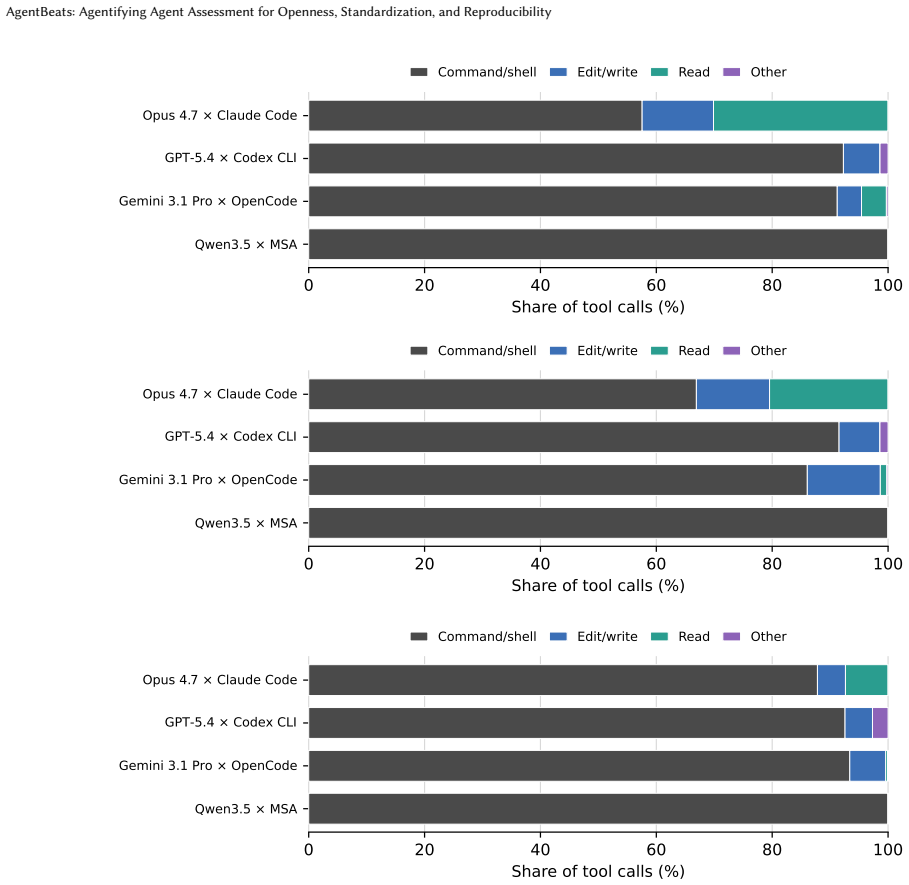
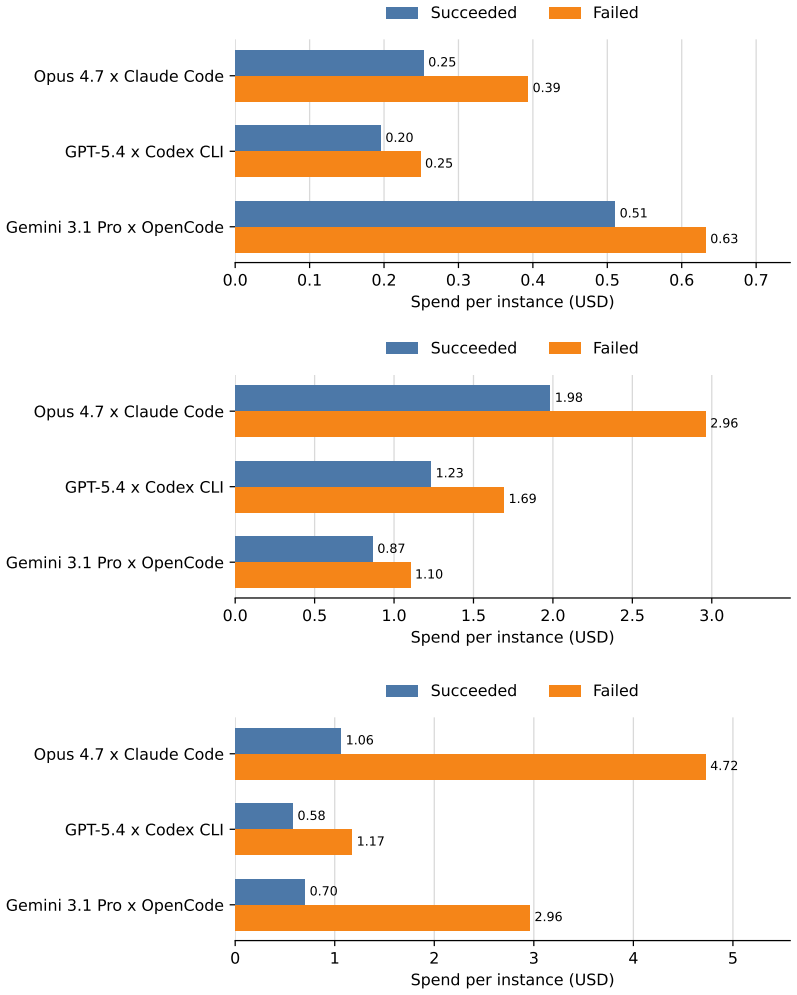
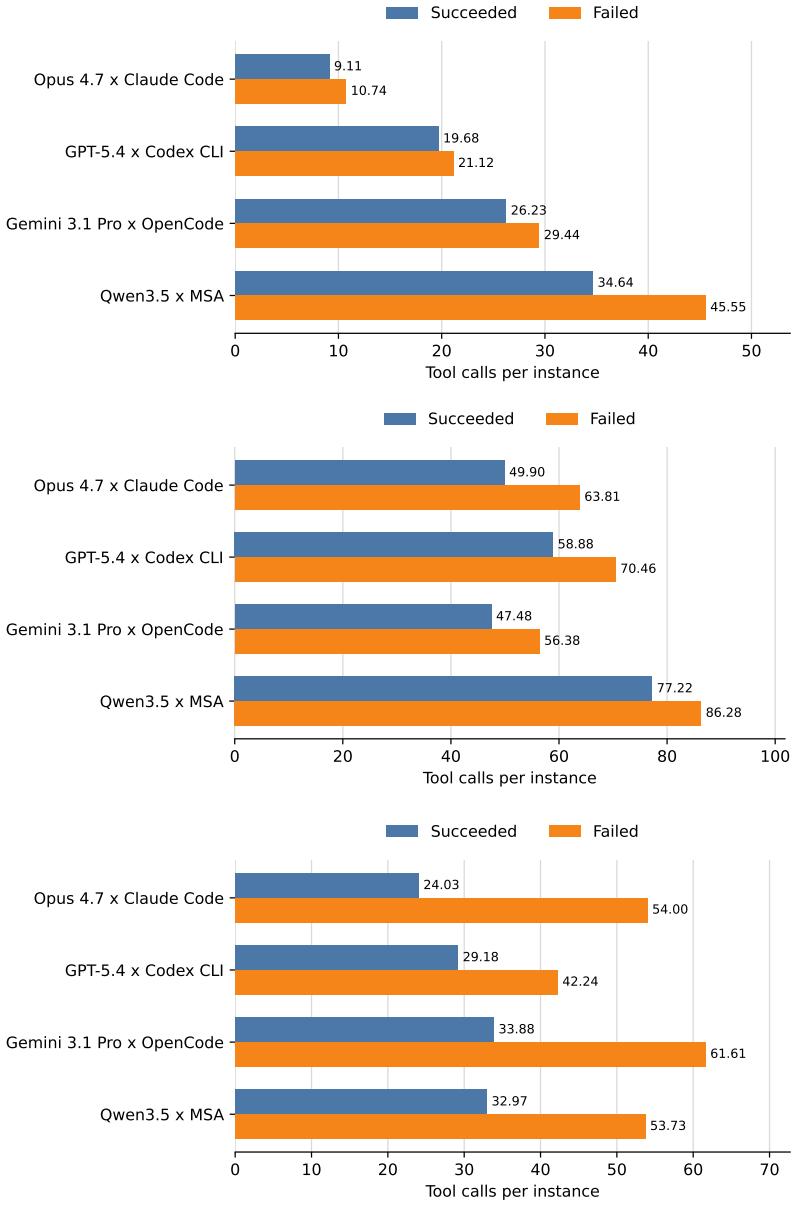
Yuwen Zou, Jia Liu, and Wenjun Fan. 2026. CTFAgent: An LLM-powered Agent for CTF Challenge Solving.Journal of Information Security and Applications96 (2026), 104305. A Additional Experiment Results This section reports supplementary measurements from the main experiments of our coding-agent case study (Section 8). We provide them as a reference for downst...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.