MedRLM: Recursive Multimodal Health Intelligence for Long-Context Clinical Reasoning, Sensor-Guided Screening, Evidence-Grounded Decision Support, and Community-to-Tertiary Referral Optimization
Pith reviewed 2026-06-26 17:12 UTC · model grok-4.3
The pith
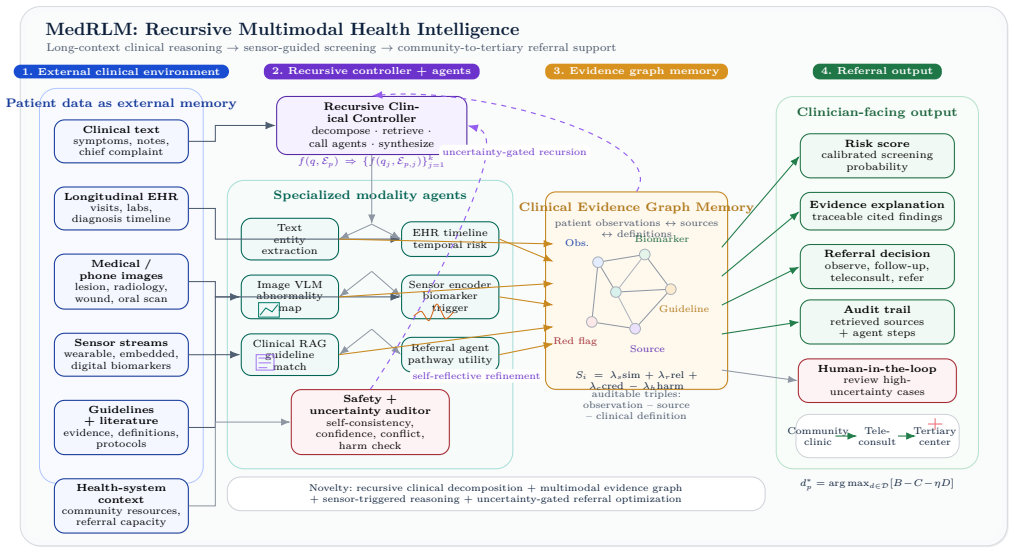
MedRLM treats patient cases as external environments that specialized agents recursively inspect using a Clinical Evidence Graph Memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedRLM treats the patient case as an external clinical environment that can be recursively inspected, decomposed, retrieved, verified, and synthesized using coordinated specialized agents for clinical text, longitudinal EHR, medical imaging, physiological sensor signals, guideline retrieval, uncertainty auditing, and referral planning together with a Clinical Evidence Graph Memory.
What carries the argument
The Clinical Evidence Graph Memory that connects patient-specific observations with retrieved evidence, standardized definitions, sensor-derived biomarkers, and referral criteria, plus the sensor-guided recursive triggering mechanism that activates deeper reasoning on abnormal patterns.
If this is right
- Enables reasoning over heterogeneous and longitudinal patient data without compressing everything into one prompt.
- Uses sensor data to trigger deeper analysis for screening and early detection.
- Supports uncertainty auditing with options for clinician oversight on high-risk cases.
- Grounds community-to-tertiary referral decisions in connected evidence and criteria.
Where Pith is reading between the lines
- The graph memory structure could make individual reasoning steps more traceable for audit purposes.
- Integration with existing hospital data systems might reduce the need for manual chart review.
- Real-time sensor streams from wearables could extend the triggering mechanism beyond clinical settings.
Load-bearing premise
Coordinating multiple specialized agents with a shared graph memory and sensor-based triggering will reliably outperform single-step prompting or standard retrieval when evidence is distributed across long records, images, and streams.
What would settle it
Head-to-head tests on public clinical datasets spanning long EHRs, radiology images, ECG signals, and referral outcomes where the recursive agent system shows no improvement in accuracy, safety, or appropriateness over baseline single-prompt or retrieval-augmented systems.
Figures

read the original abstract
Real-world clinical decision support requires reasoning over heterogeneous and longitudinal patient information rather than answering isolated medical questions. However, current medical large language models and retrieval-augmented generation systems often rely on single-step prompting or retrieval, which can be fragile when clinical evidence is distributed across long electronic health records, medical images, sensor streams, guidelines, and referral constraints. This paper proposes MedRLM, a Recursive Multimodal Health Intelligence framework for long-context clinical reasoning, sensor-guided screening, and community-to-tertiary referral support. Instead of compressing all patient information into one prompt, MedRLM treats the patient case as an external clinical environment that can be recursively inspected, decomposed, retrieved, verified, and synthesized. The framework coordinates specialized agents for clinical text, longitudinal EHR, medical imaging, physiological sensor signals, guideline retrieval, uncertainty auditing, and referral planning. It further introduces a Clinical Evidence Graph Memory to connect patient-specific observations with retrieved evidence, standardized definitions, sensor-derived biomarkers, and referral criteria. A sensor-guided recursive triggering mechanism activates deeper reasoning when abnormal physiological or behavioral patterns are detected, while uncertainty-gated refinement supports clinician review for high-risk or low-confidence cases. We also outline a real-data evaluation design using public and credentialed clinical datasets spanning EHR, radiology, ECG, ICU time series, and referral-proxy outcomes. MedRLM aims to move medical AI from static question answering toward auditable, multimodal, and workflow-aware clinical decision support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MedRLM, a high-level Recursive Multimodal Health Intelligence framework that coordinates specialized agents (for clinical text, EHR, imaging, sensors, guidelines, uncertainty, and referral) together with a Clinical Evidence Graph Memory and sensor-guided recursive triggering to enable long-context clinical reasoning, screening, and community-to-tertiary referral optimization over distributed multimodal patient data. It contrasts this with single-step prompting and standard RAG, outlines an evaluation design on public datasets (EHR, radiology, ECG, ICU time series), but supplies no implementation, algorithms, pseudocode, or results.
Significance. If the proposed recursive agent coordination, graph memory updates, and uncertainty gating could be shown to outperform baselines on distributed clinical evidence without coordination collapse, the work would advance medical AI toward more auditable and workflow-aware decision support. The conceptual emphasis on treating the patient case as an inspectable external environment and integrating sensor-triggered recursion addresses real limitations in current medical LLMs, though the absence of any empirical grounding limits immediate impact.
major comments (2)
- [Abstract] Abstract: The central claim that MedRLM's multi-agent system with Clinical Evidence Graph Memory and sensor-guided recursive triggering 'will reliably synthesize distributed multimodal evidence better than single-step prompting or standard RAG' is load-bearing, yet the manuscript provides neither the recursion mechanism, graph update rules, coordination protocol, nor any empirical results (or even ablation-style examples) to demonstrate functionality or superiority.
- [Abstract] Evaluation outline (Abstract): The manuscript states it 'outline[s] a real-data evaluation design using public and credentialed clinical datasets' spanning EHR, radiology, ECG, and referral outcomes, but includes no actual experiments, baselines, metrics, error analysis, or validation data, leaving all performance claims unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive review highlighting the distinction between conceptual framework proposals and fully implemented empirical studies. Our manuscript presents MedRLM as a high-level architectural design for recursive multimodal clinical reasoning, with an outlined evaluation plan but without executed experiments or detailed algorithms. We address each point below and propose targeted clarifications to the abstract and text to better align reader expectations with the paper's scope as a proposal rather than a completed system.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that MedRLM's multi-agent system with Clinical Evidence Graph Memory and sensor-guided recursive triggering 'will reliably synthesize distributed multimodal evidence better than single-step prompting or standard RAG' is load-bearing, yet the manuscript provides neither the recursion mechanism, graph update rules, coordination protocol, nor any empirical results (or even ablation-style examples) to demonstrate functionality or superiority.
Authors: We agree the manuscript does not supply implementation details, update rules, protocols, or results, as it is structured as a conceptual framework proposal rather than an empirical systems paper. The abstract language describes the design objectives and intended behavior of the proposed architecture (treating the patient case as an inspectable environment with specialized agents and graph memory) rather than validated performance. We will revise the abstract and introduction to explicitly state that this work proposes the framework and outlines an evaluation design, with empirical validation positioned as future work. This addresses the load-bearing nature of the claims by tempering them to reflect the proposal scope. revision: partial
-
Referee: [Abstract] Evaluation outline (Abstract): The manuscript states it 'outline[s] a real-data evaluation design using public and credentialed clinical datasets' spanning EHR, radiology, ECG, and referral outcomes, but includes no actual experiments, baselines, metrics, error analysis, or validation data, leaving all performance claims unsupported.
Authors: The referee correctly observes that no experiments, baselines, or results are included. The manuscript outlines a prospective evaluation design on public datasets (EHR, radiology, ECG, ICU time series, referral proxies) as a roadmap for subsequent validation, without claiming completed runs. We will revise the abstract and any evaluation sections to remove any implication of performed experiments and to clearly label the content as an evaluation plan for future implementation. This maintains honesty about the current contribution while preserving the value of the proposed design for guiding such work. revision: yes
Circularity Check
No circularity: conceptual framework proposal with no derivations or fitted predictions
full rationale
The manuscript is a high-level architecture proposal for MedRLM. It contains no equations, no parameter fitting, no predictions derived from inputs, and no self-citation chains that bear the central claim. The description of recursive agents, Clinical Evidence Graph Memory, and sensor-guided triggering is presented as a design outline rather than a derivation that reduces to its own inputs by construction. The evaluation is described only as a planned design on public datasets, with no results or ablations supplied. This matches the default expectation of no circularity for non-mathematical framework papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Specialized agents for text, imaging, sensors, and guidelines can be coordinated effectively for clinical tasks
- domain assumption Recursive inspection of patient data as an external environment improves reasoning over single-step prompting
invented entities (2)
-
Clinical Evidence Graph Memory
no independent evidence
-
sensor-guided recursive triggering mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. L. Zhang, T. Kraska, and O. Khattab, “Recursive Lan- guage Models,”arXiv preprint arXiv:2512.24601, 2026. [On- line]. Available: https://arxiv.org/abs/2512.24601
Pith/arXiv arXiv 2026
-
[2]
K. Alizadeh, P. Shojaee, M. Cho, and M. Farajtabar, “Re- cursive Language Models Meet Uncertainty: The Surprising Effectiveness of Self-Reflective Program Search for Long Con- text,”arXiv preprint arXiv:2603.15653, 2026. [Online]. Avail- able: https://arxiv.org/abs/2603.15653
arXiv 2026
-
[3]
The Y-Combinator for LLMs: Solving Long-Context Rot with λ-Calculus,
A. Roy, R. Tutunov, X. Ji, M. Zimmer, and H. Bou-Ammar, “The Y-Combinator for LLMs: Solving Long-Context Rot with λ-Calculus,”arXiv preprint arXiv:2603.20105, 2026. [Online]. Available: https://arxiv.org/abs/2603.20105
arXiv 2026
-
[4]
Lost in the Middle: How Language Models Use Long Contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the Middle: How Language Models Use Long Contexts,”TransactionsoftheAssociationfor Computational Linguistics, vol. 12, pp. 157–173, 2024. [Online]. Available: https://arxiv.org/abs/2307.03172
Pith/arXiv arXiv 2024
-
[5]
Long- Bench: A Bilingual, Multitask Benchmark for Long Context Un- derstanding,
Y. Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y. Dong, J. Tang, and J. Li, “Long- Bench: A Bilingual, Multitask Benchmark for Long Context Un- derstanding,”arXiv preprint arXiv:2308.14508, 2023. [Online]. Available: https://arxiv.org/abs/2308.14508
Pith/arXiv arXiv 2023
-
[6]
Retrieval-Augmented Generation for Knowledge- IntensiveNLPTasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Kuttler, M. Lewis, W. Yih, T. Rocktaschel, S. Riedel, and D. Kiela, “Retrieval-Augmented Generation for Knowledge- IntensiveNLPTasks,”AdvancesinNeuralInformationProcess- ing Systems, vol. 33, pp. 9459–9474, 2020. [Online]. Available: https://arxiv.org/abs/2005.11401
Pith/arXiv arXiv 2020
-
[7]
ReAct: Synergizing Reasoning and Act- ing in Language Models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “ReAct: Synergizing Reasoning and Act- ing in Language Models,” inProc. International Confer- ence on Learning Representations, 2023. [Online]. Available: https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[8]
K. Singhalet al., “Large Language Models Encode Clinical Knowledge,”Nature,vol.620,pp.172–180,2023.[Online].Avail- able: https://doi.org/10.1038/s41586-023-06291-2
-
[9]
K. Singhalet al., “Toward Expert-Level Medical Question Answering with Large Language Models,”Nature Medicine, vol. 31, pp. 943–950, 2025. [Online]. Available: https://doi.org/10.1038/s41591-024-03423-7
-
[10]
LLaVA-Med: Training a Large Language- and-Vision Assistant for Biomedicine in One Day,
C. Liet al., “LLaVA-Med: Training a Large Language- and-Vision Assistant for Biomedicine in One Day,”arXiv preprint arXiv:2306.00890, 2023. [Online]. Available: https://arxiv.org/abs/2306.00890
Pith/arXiv arXiv 2023
-
[11]
Towards Generalist Biomedical AI,
T. Tuet al., “Towards Generalist Biomedical AI,”arXiv preprint arXiv:2307.14334, 2023. [Online]. Available: https://arxiv.org/abs/2307.14334
arXiv 2023
-
[12]
Benchmarking Retrieval-Augmented Generation for Medicine,
G. Xiong, Q. Jin, Z. Lu, and A. Zhang, “Benchmarking Retrieval-Augmented Generation for Medicine,”arXiv preprint arXiv:2402.13178, 2024. [Online]. Available: https://arxiv.org/abs/2402.13178
arXiv 2024
-
[13]
MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models,
P. Xiaet al., “MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models,” inProc. International Conference on Learning Representations, 2025. [Online]. Avail- able: https://arxiv.org/abs/2410.13085
arXiv 2025
-
[14]
J. Wu, J. Zhu, Y. Qi, J. Chen, M. Xu, F. Menolascina, and V. Grau, “Medical Graph RAG: Towards Safe Medical Large Language Model via Graph Retrieval-Augmented Generation,” arXiv preprint arXiv:2408.04187, 2024. [Online]. Available: https://arxiv.org/abs/2408.04187
arXiv 2024
-
[15]
M.Wornow,R.Thapa,E.Steinberg,J.A.Fries,andN.H.Shah, “EHRSHOT: An EHR Benchmark for Few-Shot Evaluation of TABLE II benchmark tasks, labels, and metrics grounded in real datasets. Evaluation task Dataset(s) T arget label or output Primary metric(s) Clinical interpreta- tion Long-context EHR risk reasoning MIMIC-IV, eICU- CRD Mortality, ICU admission, readm...
arXiv 2012
-
[16]
MIMIC-IV.PhysioNet, October 2024
A. Johnson, L. Bulgarelli, T. Pollard, B. Gow, B. Moody, S. Horng, L. A. Celi, and R. Mark, “MIMIC-IV,”PhysioNet, version 3.1, 2024, doi: 10.13026/kpb9-mt58
-
[17]
doi: 10.1038/s41597-022-01899-x
A. E. W. Johnson, L. Bulgarelli, L. Shen, A. Gayles, A. Sham- mout, S. Horng, T. J. Pollard, S. Hao, B. Moody, B. Gow, L. H. Lehman, L. A. Celi, and R. G. Mark, “MIMIC-IV, a freely accessible electronic health record dataset,”Scientific Data, vol. 10, no. 1, 2023, doi: 10.1038/s41597-022-01899-x
-
[18]
MIMIC-CXR-JPG - chest radiographs with structured labels.PhysioNet, March 2024
A. Johnson, M. Lungren, Y. Peng, Z. Lu, R. Mark, S. Berkowitz, and S. Horng, “MIMIC-CXR-JPG - chest radio- graphs with structured labels,”PhysioNet, version 2.1.0, 2024, doi: 10.13026/jsn5-t979
-
[19]
MIMIC-CXR: A large publicly available database of labeled chest radiographs,
A. E. W. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Green- baum, M. P. Lungren, C.-Y. Deng, R. G. Mark, and S. Horng, “MIMIC-CXR: A large publicly available database of labeled chest radiographs,”arXiv preprint arXiv:1901.07042, 2019
Pith/arXiv arXiv 1901
-
[20]
CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison,
J. Irvinet al., “CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison,”arXiv preprint arXiv:1901.07031, 2019
Pith/arXiv arXiv 1901
-
[21]
T. Pollard, A. Johnson, J. Raffa, L. A. Celi, O. Badawi, and R. Mark, “eICU Collaborative Research Database,”PhysioNet, version 2.0, 2019, doi: 10.13026/C2WM1R
-
[22]
Scientific data5(1), 1–13 (2018).https://doi.org/10.1038/sdata.2018.178
T. J. Pollard, A. E. W. Johnson, J. D. Raffa, L. A. Celi, R. G. Mark, and O. Badawi, “The eICU Collaborative Re- search Database, a freely available multi-center database for critical care research,”Scientific Data, vol. 5, 180178, 2018, doi: 10.1038/sdata.2018.178
-
[23]
PTB-XL, a large publicly available electrocardiography dataset.PhysioNet, November 2022
P. Wagner, N. Strodthoff, R.-D. Bousseljot, W. Samek, and T. Schaeffter, “PTB-XL, a large publicly available electro- cardiography dataset,”PhysioNet, version 1.0.3, 2022, doi: 10.13026/kfzx-aw45
-
[24]
P. Wagner, N. Strodthoff, R.-D. Bousseljot, D. Kreiseler, F. I. Lunze, W. Samek, and T. Schaeffter, “PTB-XL, a large publicly available electrocardiography dataset,”Scientific Data, vol. 7, 154, 2020, doi: 10.1038/s41597-020-0495-6
-
[25]
Predicting in-hospital mortality of patients in ICU: The Phy- sioNet/Computing in Cardiology Challenge 2012,
I. Silva, G. Moody, D. J. Scott, L. A. Celi, and R. G. Mark, “Predicting in-hospital mortality of patients in ICU: The Phy- sioNet/Computing in Cardiology Challenge 2012,”Computing in Cardiology, vol. 39, pp. 245–248, 2012. [Online]. Available: https://physionet.org/content/challenge-2012/1.0.0/
2012
-
[26]
Goswami, M., Szafer, K., Choudhry, A., Cai, Y ., Li, S., and Dubrawski, A
A. L. Goldbergeret al., “PhysioBank, PhysioToolkit, and Phy- sioNet: Components of a new research resource for complex physiologicsignals,”Circulation,vol.101,no.23,pp.e215–e220, 2000, doi: 10.1161/01.CIR.101.23.e215
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.