Specialize Roles, Mix Deployments: Pushing the Cost-Accuracy Frontier of LLM Agent Teams
Pith reviewed 2026-06-28 23:51 UTC · model grok-4.3
The pith
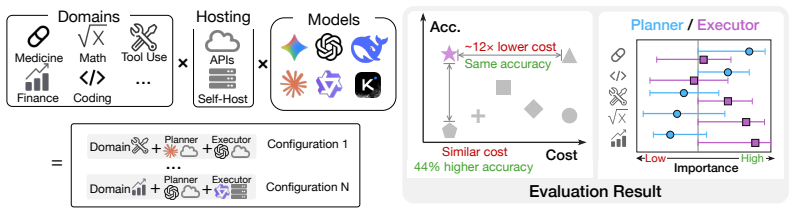
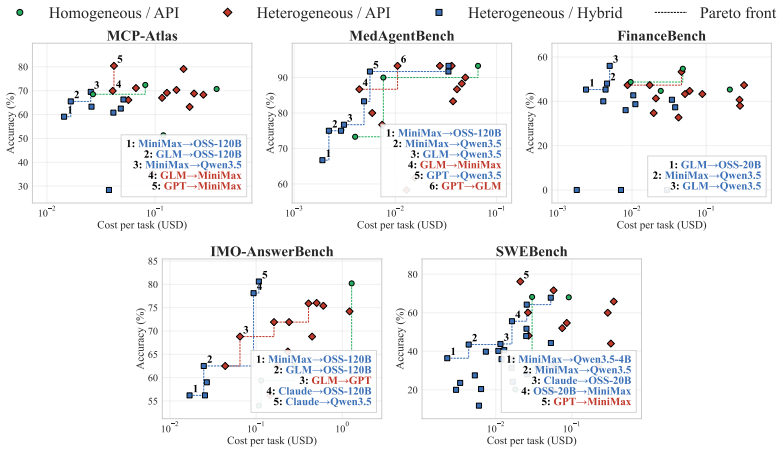
Heterogeneous LLM agent teams with specialized roles and mixed deployments reach higher accuracy at the same cost or match top accuracy at up to 12 times lower cost than uniform teams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
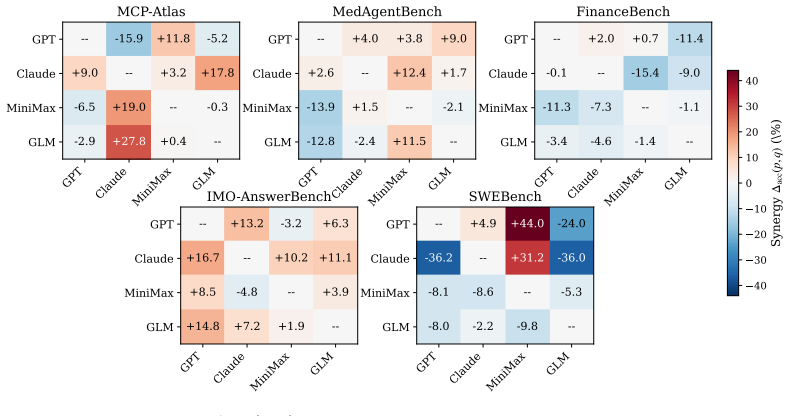
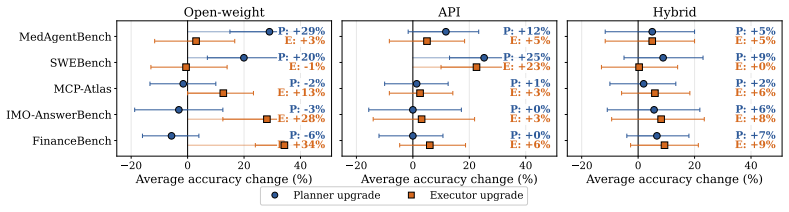
Heterogeneous teams consistently occupy the cost-accuracy frontier. They improve accuracy by up to 44% over cost-equivalent homogeneous teams, or match the strongest homogeneous team at up to 12× lower per-task cost through hybrid deployment. The best role assignment is domain-dependent: some domains are planner-bottlenecked, while others are executor-bottlenecked. The benchmark extends to workflows with additional roles such as verification and supports continual evaluation as new domains and team structures emerge.
What carries the argument
AgentCARD, a role-aware benchmark suite that combines a role-decomposed evaluation harness, a unified API and self-hosted cost model, Pareto-frontier analysis, and Shapley-based diagnostics to locate role bottlenecks.
If this is right
- Accuracy gains or cost savings from heterogeneous assignment vary by domain.
- Hybrid deployment (some roles on API, others self-hosted) can match strong uniform teams at substantially lower per-task cost.
- Some domains require stronger planners while others require stronger executors.
- The same measurement approach can evaluate workflows that add verification or other roles.
Where Pith is reading between the lines
- Teams could monitor ongoing tasks and reassign models to roles when bottlenecks appear.
- Cost models will require periodic updates as API prices and hardware costs shift.
- The approach could be extended to measure interactions among more than three roles in longer workflows.
Load-bearing premise
The role-decomposed evaluation harness accurately isolates each role's contribution without large unmodeled interactions between roles or deployment choices affecting task decomposition.
What would settle it
A re-run of the benchmark on the same tasks but with an explicit model of role interactions that changes the measured accuracy or cost ordering of heterogeneous versus homogeneous teams by more than a few percent.
Figures
read the original abstract
LLM agents are increasingly deployed as multi-role teams, where tasks are divided across specialized roles such as planner, executor, and verifier. In these systems, cost and accuracy are no longer properties of a single model: they depend on which model fills each role and where it is hosted, including API, self-hosted, and hybrid deployment. Existing agentic benchmarks typically evaluate fixed models or fixed agent configurations, and therefore offer limited guidance for cost-accuracy-optimal deployment. We introduce AgentCARD, a role-aware benchmark suite for evaluating LLM agent teams across role assignment and deployment mode. AgentCARD combines a role-decomposed evaluation harness, a unified API/self-hosted cost model, Pareto-frontier analysis, and a Shapley-based diagnostic for identifying role bottlenecks. Our evaluation shows that heterogeneous teams consistently occupy the cost-accuracy frontier. They improve accuracy by up to $44\%$ over cost-equivalent homogeneous teams, or match the strongest homogeneous team at up to $12\times$ lower per-task cost through hybrid deployment. We further find that the best role assignment is domain-dependent: some domains are planner-bottlenecked, while others are executor-bottlenecked. Finally, AgentCARD extends beyond planner--executor teams to workflows with additional roles such as verification, and supports continual evaluation as new domains and team structures emerge. Our code is released at: https://github.com/Auto-CAP/AgentCAP
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentCARD, a role-aware benchmark suite for LLM agent teams that evaluates role assignment (planner, executor, verifier) and deployment modes (API, self-hosted, hybrid) using a role-decomposed harness, unified cost model, Pareto-frontier analysis, and Shapley diagnostics. It claims that heterogeneous teams occupy the cost-accuracy frontier, improving accuracy by up to 44% over cost-equivalent homogeneous teams or matching the strongest homogeneous team at up to 12× lower per-task cost, with domain-dependent bottlenecks (planner- vs. executor-bottlenecked). The work extends to additional roles and releases code for continual evaluation.
Significance. If the results hold under rigorous controls, the paper offers actionable guidance for cost-accuracy optimization in multi-role LLM agent deployments, a practically relevant problem as agent teams proliferate. The combination of Pareto analysis with Shapley value diagnostics for bottleneck identification is a useful methodological contribution, and the open benchmark/code supports reproducibility and extension to new domains.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The central quantitative claims (up to 44% accuracy improvement and 12× cost reduction for heterogeneous teams) are presented without any description of task selection criteria, statistical significance testing, error bars, baseline definitions, or data exclusion rules. This information is required to evaluate whether the Pareto-frontier occupancy result is supported.
- [Role-decomposed evaluation harness] Role-decomposed evaluation harness (described in the methods): The harness is used to attribute performance to per-role model choice and deployment, but the manuscript provides no explicit ablation or test for cross-role interactions (e.g., whether planner quality alters executor behavior) or deployment effects on task decomposition itself. Without such a test, the Shapley diagnostics and frontier claims risk overstating specialization benefits.
minor comments (2)
- [Abstract] The abstract states that the code is released at a GitHub link, but the manuscript should include a brief note on the repository contents (e.g., which datasets and scripts are provided) to aid immediate reproducibility.
- [Cost model section] Notation for cost model and deployment modes could be clarified with a small table summarizing API vs. self-hosted vs. hybrid per role.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the rigor of our claims. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The central quantitative claims (up to 44% accuracy improvement and 12× cost reduction for heterogeneous teams) are presented without any description of task selection criteria, statistical significance testing, error bars, baseline definitions, or data exclusion rules. This information is required to evaluate whether the Pareto-frontier occupancy result is supported.
Authors: We agree these details are necessary for evaluating the claims. The full manuscript's Evaluation section describes the AgentCARD benchmark domains and task sampling but does not include statistical tests, error bars, or explicit exclusion rules. In the revision we will add: task selection criteria with domain coverage details; paired t-tests or Wilcoxon tests with p-values for the 44% and 12× improvements; error bars (standard error) on all Pareto plots and tables; explicit baseline definitions for homogeneous teams; and any data exclusion criteria applied. These additions will directly support the frontier occupancy result. revision: yes
-
Referee: [Role-decomposed evaluation harness] Role-decomposed evaluation harness (described in the methods): The harness is used to attribute performance to per-role model choice and deployment, but the manuscript provides no explicit ablation or test for cross-role interactions (e.g., whether planner quality alters executor behavior) or deployment effects on task decomposition itself. Without such a test, the Shapley diagnostics and frontier claims risk overstating specialization benefits.
Authors: The role-decomposed harness isolates per-role assignments by design, and Shapley values are computed over the full combinatorial space of role-model pairs to capture marginal contributions. However, we did not run dedicated ablations that vary planner quality while holding executor fixed or that measure changes in task decomposition under different deployments. We will add a targeted ablation on two domains (one planner-bottlenecked, one executor-bottlenecked) to quantify interaction effects and any decomposition shifts; if results show negligible interactions we will report them as supporting evidence for the current claims. This constitutes a partial revision as full cross-role interaction testing across all domains would require substantial additional compute. revision: partial
Circularity Check
No significant circularity: empirical benchmark with independent evaluations
full rationale
The paper introduces AgentCARD as a new role-aware benchmark suite with role-decomposed harness, cost model, Pareto analysis, and Shapley diagnostics. All central claims (heterogeneous teams on frontier, accuracy/cost gains, domain-dependent bottlenecks) rest on direct empirical measurements across models, roles, and deployments rather than any derivation, fitted parameter renamed as prediction, or self-citation chain. No equations, uniqueness theorems, or ansatzes are present that reduce to inputs by construction. The evaluation harness and diagnostics are externally falsifiable via the released code and new task data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Openai Codex: Cloud-based autonomous coding agent
OpenAI. Openai Codex: Cloud-based autonomous coding agent. https://openai.com/ index/introducing-codex/, 2025. Accessed: 30 April 2026
2025
-
[2]
Composer 2 technical report
Cursor Research Team. Composer 2 technical report. https://cursor.com/resources/ Composer2.pdf, 2026. Accessed: 30 April 2026
2026
-
[3]
Opencode: The open source AI coding agent
OpenCode. Opencode: The open source AI coding agent. https://github.com/opencode- ai/opencode, 2025. Accessed: 30 April 2026
2025
-
[4]
AutoGen: Enabling next-gen LLM applications via multi-agent conversation,
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation,
-
[5]
URLhttps://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Google agent development kit (ADK)
Google. Google agent development kit (ADK). https://google.github.io/adk-docs/,
-
[8]
Kimi agent swarm: Let 100 AI agents work for you
Moonshot AI. Kimi agent swarm: Let 100 AI agents work for you. https://www.kimi.com/ blog/agent-swarm, 2026. Accessed: 30 April 2026
2026
-
[9]
How we built our multi-agent research system
Jeremy Hadfield, Barry Zhang, Kenneth Lien, Florian Scholz, Jeremy Fox, and Daniel Ford. How we built our multi-agent research system. https://www.anthropic.com/ engineering/built-multi-agent-research-system , 2025. Anthropic Engineering Blog. Accessed: 30 April 2026
2025
-
[10]
Don’t build multi-agents
Walden Yan. Don’t build multi-agents. https://cognition.ai/blog/dont-build- multi-agents, 2024. Cognition AI engineering blog
2024
-
[11]
MCP Atlas leaderboard
Scale Labs. MCP Atlas leaderboard. https://labs.scale.com/leaderboard/mcp_atlas,
-
[12]
Updated April 8, 2026
2026
-
[13]
Plan-and-solve prompting: Improving zero-shot Chain-of-Thought reasoning by Large Lan- guage Models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot Chain-of-Thought reasoning by Large Lan- guage Models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Lon...
-
[14]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=WE_vluYUL-X
2023
-
[15]
HuggingGPT: Solving AI tasks with chatGPT and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI tasks with chatGPT and its friends in hugging face. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview. net/forum?id=yHdTscY6Ci
2023
-
[16]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum? id=vAElhFcKW6. 10
2023
-
[17]
An LLM compiler for parallel function calling
Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. An LLM compiler for parallel function calling. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. URL https://openreview. net/forum?id=uQ2FUoFjnF
2024
-
[18]
Plan-and-Act: Improving planning of agents for long-horizon tasks
Lutfi Eren Erdogan, Hiroki Furuta, Sehoon Kim, Nicholas Lee, Suhong Moon, Gopala Anu- manchipalli, Kurt Keutzer, and Amir Gholami. Plan-and-Act: Improving planning of agents for long-horizon tasks. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=ybA4EcMmUZ
2025
-
[19]
GitHub Copilot CLI v1.0.18: experimental critic agent for plan and complex im- plementation review
GitHub. GitHub Copilot CLI v1.0.18: experimental critic agent for plan and complex im- plementation review. GitHub Copilot CLI release notes (April 4, 2026), April 2026. URL https://github.com/github/copilot-cli/releases?page=5. Page number of v1.0.18 may change. Accessed: 30 April 2026
2026
-
[20]
Best practices for coding with agents: Plan mode
Lee Robinson. Best practices for coding with agents: Plan mode. Cursor Engineering Blog, https://cursor.sh/blog/agent-best-practices, January 2026. Plan Mode is a Cursor product feature; agents propose a plan and wait for approval before execution. Accessed: 1 May 2026
2026
-
[21]
State of AI 2025: An Empirical 100 Trillion Token Study
Malika Aubakirova, Alex Atallah, Chris Clark, Justin Summerville, and Anjney Midha. State of AI 2025: An Empirical 100 Trillion Token Study. https://openrouter.ai/state-of-ai,
2025
-
[22]
Accessed: 30 April 2026
2026
-
[23]
Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity, 2024
Tyler Griggs, Xiaoxuan Liu, Jiaxiang Yu, Doyoung Kim, Wei-Lin Chiang, Alvin Cheung, and Ion Stoica. Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity, 2024. URLhttps://arxiv.org/abs/2404.14527
-
[24]
MoE-CAP: Benchmarking cost, accuracy and performance of sparse mixture-of-experts systems, 2025
Yinsicheng Jiang, Yao Fu, Yeqi Huang, Ping Nie, Zhan Lu, Leyang Xue, Congjie He, Man-Kit Sit, Jilong Xue, Li Dong, Ziming Miao, Dayou Du, Tairan Xu, Kai Zou, Edoardo Ponti, and Luo Mai. MoE-CAP: Benchmarking cost, accuracy and performance of sparse mixture-of-experts systems, 2025. URLhttps://arxiv.org/abs/2412.07067
-
[25]
PEAR: Planner-executor agent robustness benchmark
Shen Dong, Mingxuan Zhang, Pengfei He, Li Ma, Bhavani Thuraisingham, Hui Liu, and Yue Xing. PEAR: Planner-executor agent robustness benchmark. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Findings of the Association for Computational Linguistics: EACL 2026, pages 4547–4567, Rabat, Morocco, March 2026. Association for Computational Linguistics...
-
[26]
How handshake saves 50% on LLM GPU costs with anyscale
Anyscale. How handshake saves 50% on LLM GPU costs with anyscale. https://www.anyscale.com/resources/case-study/how-handshake-saves-50- on-llm-gpu-costs-with-anyscale, 2024. Accessed: 6 May 2026
2024
-
[27]
Making AI more accessible: Up to 80% cost savings with Meta Llama 3.3 on databricks
Databricks. Making AI more accessible: Up to 80% cost savings with Meta Llama 3.3 on databricks. https://www.databricks.com/blog/making-ai-more-accessible-80- cost-savings-meta-llama-33-databricks, 2024. Accessed: 6 May 2026
2024
-
[28]
Jiin Kim, Byeongjun Shin, Jinha Chung, and Minsoo Rhu. The Cost of Dynamic Reasoning: Demystifying AI Agents and Test-Time Scaling from an AI Infrastructure Perspective. In Proceedings of the 32nd IEEE International Symposium on High-Performance Computer Archi- tecture (HPCA), 2026. URLhttps://arxiv.org/abs/2506.04301. arXiv:2506.04301
-
[29]
Narasimhan
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R. Narasimhan. τ-bench: A benchmark for Tool-Agent-User interaction in real-world domains. InThe Thirteenth International Con- ference on Learning Representations, 2025. URL https://openreview.net/forum?id= roNSXZpUDN
2025
-
[30]
MultiAgentBench: Evaluating the collaboration and competition of LLM agents, 2025
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Zhe Wang, Zhenhailong Wang, Cheng Qian, Xiangru Tang, Heng Ji, and Jiaxuan You. MultiAgentBench: Evaluating the Collaboration and Competition of LLM Agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025. URL https://aclanthology. org/20...
-
[31]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. TheAgentCompany: Benchmarking LLM agents on consequential real world tasks, 2025....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Faustino, Guanheng Liu, Shan Zhang, Hongbin Luo, Suhaib A
Tie Ma, Yixi Chen, Vaastav Anand, Alessandro Cornacchia, Amândio R. Faustino, Guanheng Liu, Shan Zhang, Hongbin Luo, Suhaib A. Fahmy, Zafar A. Qazi, and Marco Canini. Maestro: Multi-agent evaluation suite for testing, reliability, and observability, 2026. URL https: //arxiv.org/abs/2601.00481
-
[33]
Holistic agent leaderboard: The missing infrastructure for AI agent evaluation
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, Franck Ndzomga, Dheeraj Oruganty, Sophie Luskin, Kangheng Liu, Botao Yu, Amit Arora, Dongyoon Hahm, Harsh Trivedi, Huan Sun, Juyong Lee, Tengjun Jin, Yifan Mai, Yifei Zhou, Yuxuan Zhu, Rishi Bommasani, Daniel Kang, Da...
2026
-
[34]
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y . Ng, and Jonathan H. Chen. MedAgentBench: A virtual EHR environment to benchmark medical LLM agents.NEJM AI, 2(9):AIdbp2500144, 2025. doi: 10.1056/AIdbp2500144. URL https://ai.nejm.org/doi/full/10.1056/AIdbp2500144
-
[35]
FinanceBench: A New Benchmark for Financial Question Answering
Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. Financebench: A new benchmark for financial question answering, 2023. URL https://arxiv.org/abs/2311.11944
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Thang Luong, Dawsen Hwang, Hoang H. Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Clara Huiyi Hu, Henryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu H. Trinh, Quoc V . Le, and Junehyuk Jung. Towards robust mathematical reasoning. InProceedings of the 2025 C...
2025
-
[37]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world Github issues? InInternational Conference on Learning Representations, 2024. URL https://arxiv.org/ abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Oh my OpenAgent (omo): Multi-agent harness configurations for OpenCode
Code Yeongyu. Oh my OpenAgent (omo): Multi-agent harness configurations for OpenCode. https://github.com/code-yeongyu/oh-my-openagent , 2026. GitHub repository, previ- ouslyoh-my-opencode; accessed 2 May 2026
2026
-
[39]
Vast.ai pricing: live H100 marketplace listings
Vast.ai. Vast.ai pricing: live H100 marketplace listings. https://vast.ai/pricing, 2026. Accessed: 30 April 2026
2026
-
[40]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InThirty-seventh Conference on Neural Informati...
2023
-
[41]
Large Language Models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xiny- ing Song, and Denny Zhou. Large Language Models cannot self-correct reasoning yet. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=IkmD3fKBPQ
2024
-
[42]
H100 rental prices: A cloud cost comparison, October 2025
Adrien Laurent. H100 rental prices: A cloud cost comparison, October 2025. IntuitionLabs, https://intuitionlabs.ai/articles/h100-rental-prices-cloud-comparison
2025
-
[43]
Hyperstack AI cloud pricing
Hyperstack. Hyperstack AI cloud pricing. https://www.hyperstack.cloud/pricing,
-
[44]
Accessed Mar 2026. 12
2026
-
[45]
H100 rental prices: The $2 vs $98 gap explained, March 2026
gpu.fund. H100 rental prices: The $2 vs $98 gap explained, March 2026. https://gpu.fund/ blog/h100-price-reality-check-march-2026
2026
-
[46]
NVIDIA DGX H100 system datasheet (8×H100, list price reference)
NVIDIA Corporation. NVIDIA DGX H100 system datasheet (8×H100, list price reference). https://www.nvidia.com/en-us/data-center/dgx-h100/ , 2024. Accessed: 30 April 2026
2024
-
[47]
Energy Information Administration
U.S. Energy Information Administration. Electric power monthly: average retail price of elec- tricity to ultimate customers (commercial sector). https://www.eia.gov/electricity/ monthly/epm_table_grapher.php?t=epmt_5_6_a, 2025. Accessed: 30 April 2026
2025
-
[48]
role-criticality under a specified upgrade path
Uptime Institute. 2024 global data center survey: PUE remains stuck at 1.56 glob- ally. https://datacenter.uptimeinstitute.com/rs/711-RIA-145/images/2024. GlobalDataCenterSurvey.Report.pdf, 2024. Accessed: 30 April 2026. 13 A Self-Hosted Throughput Profiles We profile Qwen3.5-27B and GPT-OSS-120B at TP∈{2,4,8} on H100 SXM 80GB with vLLM. Table 2 reports p...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.