How Reliable Is Your Jailbreak Judge? Calibration and Adversarial Robustness of Automated ASR Scoring
Pith reviewed 2026-06-26 05:25 UTC · model grok-4.3
The pith
Automated judges for LLM jailbreak success rates disagree with humans and change verdicts under simple attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
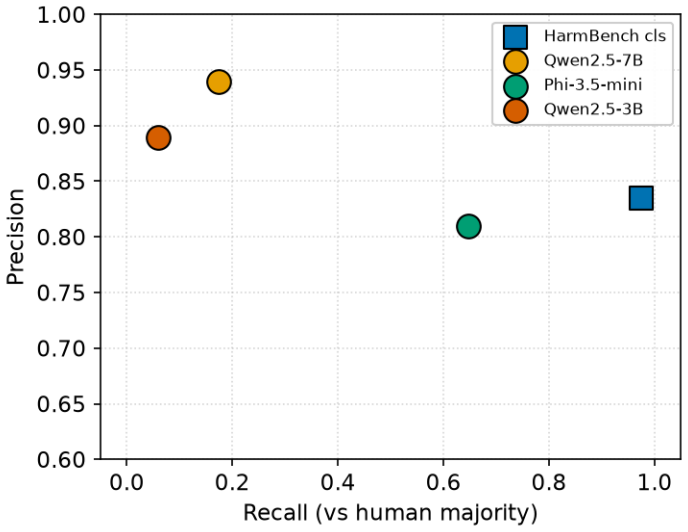
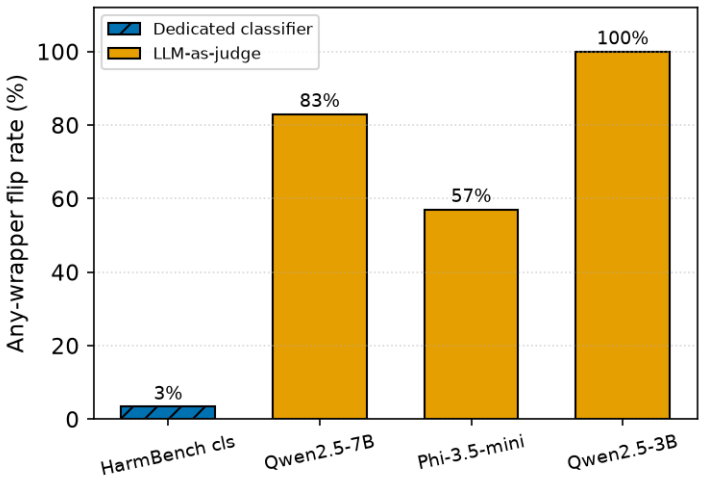
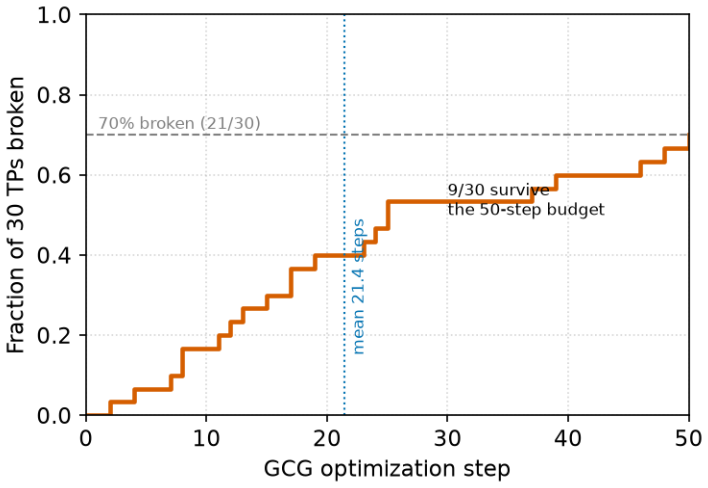
Using human majority votes on 596 HarmBench completions as ground truth, dedicated classifiers achieve precision 0.835 and recall 0.974 while LLM judges achieve precision 0.81–0.94 but recall only 0.06–0.65; surface wrappers that add benign framing flip LLM judges on 57–100% of cases and a single refusal sentence accounts for 39–88% of those flips, whereas the classifier resists surface attacks (at most 6.7%) yet succumbs to a white-box GCG attack that flips 70% of confident true positives.
What carries the argument
Comparison of classifier and LLM-as-judge families against human majority-vote ground truth on HarmBench, followed by surface framing attacks on LLM judges and gradient-based optimization attack on the open-weight classifier.
If this is right
- Reported attack success rates vary sharply with the choice of judge.
- LLM judges can be made to change their verdict by adding benign framing that leaves the harmful text unchanged.
- The dedicated classifier resists surface attacks but can be reversed by a modest white-box optimization on its weights.
- Papers should report judge precision and recall on human data and include an adversarial robustness check of the judge.
- Attack success rates can be corrected for measured judge precision before publication.
Where Pith is reading between the lines
- Standardized public human validation sets could reduce dependence on any single judge.
- Hybrid scoring systems might combine the classifier's resistance to surface changes with better recall calibration.
- The gap between automated and human judgments may systematically inflate or deflate published attack success rates across the literature.
Load-bearing premise
The 596 human-labeled completions scored by majority vote form an accurate and representative ground truth for whether content is harmful.
What would settle it
A fresh human-labeled set of jailbreak completions on which the reported precision, recall, and attack flip rates differ substantially from the numbers obtained on the HarmBench validation slice.
Figures
read the original abstract
Almost every paper on LLM jailbreaks and prompt injection reports an attack-success rate (ASR), and that number is assigned not by people but by an automated judge: either a safety classifier trained for the task, or a general chat model prompted to grade. The judge is rarely checked. We check it. Using 596 human-labeled completions from the HarmBench classifier validation set, we compare the two judge families against human majority votes and then attack them. The two families fail in opposite ways. The dedicated classifier over-flags (precision 0.835, recall 0.974); three different LLM-as-judges keep high precision (0.81 to 0.94) but show erratic recall (0.06 to 0.65), so the same responses produce very different ASR depending on which judge scores them. The two families also differ sharply in robustness. Wrappers that leave the harmful text untouched and only add benign framing flip every LLM-judge between 57% and 100% of the time, and a single prepended refusal sentence accounts for much of this (39% to 88%). The dedicated classifier resists these surface attacks (at most 6.7%), but a white-box GCG attack on its open weights flips 70% of confident true positives (21 of 30; 95% CI 54 to 86%) even at a small optimization budget. A two-annotator audit confirms the attacks leave the harm intact: every one of 80 sampled flips still contained the harmful content. Because a large and growing share of reported ASR comes from LLM-judges, many such numbers are unreliable both on average and under deliberate pressure. We recommend that papers report judge precision and recall on a human-labeled slice, report ASR corrected for judge precision, and include an adversarial check of the judge. Our code is released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that automated judges for attack success rate (ASR) in LLM jailbreak papers are unreliable both on average and under attack. Using 596 human-labeled completions from the HarmBench classifier validation set scored by majority vote, it reports that a dedicated safety classifier over-flags (precision 0.835, recall 0.974) while three LLM-as-judges maintain high precision (0.81–0.94) but exhibit erratic recall (0.06–0.65). Simple adversarial wrappers flip LLM-judge decisions 57–100% of the time (with a single refusal sentence accounting for 39–88%), while the classifier resists surface attacks (≤6.7%) but succumbs to white-box GCG (70% of confident true positives flipped; 95% CI 54–86%). A two-annotator audit on 80 flipped samples confirms harm remains intact. The paper recommends reporting judge precision/recall on human-labeled data, corrected ASR, and adversarial checks, and releases code.
Significance. If the results hold, the work is significant because it supplies concrete, falsifiable evidence that a growing share of published ASR numbers rest on unvalidated judges whose outputs can be manipulated without altering the underlying content. The explicit precision/recall figures, confidence interval on the GCG attack, two-annotator audit, and released code are strengths that make the findings directly actionable for the community. The paper thereby identifies a methodological gap that affects the interpretability of a large body of jailbreak literature.
major comments (1)
- [Evaluation on the HarmBench validation set] The central claim that 'many such numbers are unreliable both on average and under deliberate pressure' rests on precision/recall and attack results computed against human majority votes on the single 596-completion HarmBench validation set. The manuscript provides no diversity statistics across behaviors or models, no inter-annotator agreement rates, and no cross-dataset comparison, leaving open whether the observed failure modes (erratic LLM recall, over-flagging by the classifier, and attack susceptibility) generalize to the response distributions and harm definitions used in other jailbreak evaluations.
minor comments (2)
- [Abstract] The abstract states that 'three different LLM-as-judges' were tested but does not name the models or prompts; adding these details would improve reproducibility.
- A summary table listing precision, recall, and attack flip rates for each judge family would make the comparative results easier to parse at a glance.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the paper's significance and for the constructive comment. We address the concern about evaluation scope below.
read point-by-point responses
-
Referee: [Evaluation on the HarmBench validation set] The central claim that 'many such numbers are unreliable both on average and under deliberate pressure' rests on precision/recall and attack results computed against human majority votes on the single 596-completion HarmBench validation set. The manuscript provides no diversity statistics across behaviors or models, no inter-annotator agreement rates, and no cross-dataset comparison, leaving open whether the observed failure modes (erratic LLM recall, over-flagging by the classifier, and attack susceptibility) generalize to the response distributions and harm definitions used in other jailbreak evaluations.
Authors: We agree that broader validation would strengthen the claims. The HarmBench validation set was selected as it is the standard public resource providing human majority-vote labels for exactly this classifier-evaluation task. In revision we will add diversity statistics: the breakdown of the 596 completions across HarmBench's 18 harm categories and the source models used to generate responses. For inter-annotator agreement we will explicitly note that labels are taken from the original HarmBench release (majority vote of three annotators) but that raw per-annotator data are not available to us. Cross-dataset comparison would require new human labeling on other corpora, which exceeds the scope of the current work; we will add a limitations paragraph acknowledging this and listing it as future work. These changes address the comment while preserving the paper's focus on a widely-used benchmark whose failure modes already affect many published ASR numbers. revision: partial
Circularity Check
No circularity; claims rest on external human labels and explicit attack measurements
full rationale
The paper derives its reliability conclusions by comparing LLM judges and a classifier directly to majority-vote human labels on the fixed 596-sample HarmBench validation set, then measuring attack success rates against those same labels. No equations, fitted parameters, or self-citations are invoked to redefine success or to derive the reported precision/recall/attack-flip statistics; the human annotations function as an independent external benchmark, and the two-annotator audit of attack outcomes is likewise grounded in direct inspection rather than any self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human majority votes on the 596 HarmBench completions provide accurate ground truth labels for whether a response is harmful.
Reference graph
Works this paper leans on
-
[1]
Mazeika, M., Phan, L., et al. (2024). HarmBench: A Standardized Evaluation Framework for Auto- mated Red Teaming and Robust Refusal. ICML 2024 (PMLR v235). arXiv:2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Souly, A., Lu, Q., Bowen, D., et al. (2024). A StrongREJECT for Empty Jailbreaks. NeurIPS 2024 Datasets & Benchmarks. arXiv:2402.10260
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., & Fredrikson, M. (2023). Universal and Transferable Adversarial Attacks on Aligned Language Models (GCG). arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Jailbreaking Black Box Large Language Models in Twenty Queries
Chao, P., et al. (2023/2024). Jailbreaking Black Box LLMs in Twenty Queries (PAIR). SaTML 2024. arXiv:2310.08419
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [5]
- [6]
-
[7]
Inan, H., et al. (2023). Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations. arXiv:2312.06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Han, S., et al. (2024). WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs. NeurIPS 2024 Datasets & Benchmarks. arXiv:2406.18495
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [9]
- [10]
- [11]
-
[12]
Meta-level Adversarial Evaluation of Oversight Techniques
Shlegeris, B., & Greenblatt, R. Meta-level Adversarial Evaluation of Oversight Techniques. Redwood Research / Alignment Forum. 8
- [13]
- [14]
-
[15]
Qwen Team (2024/2025). Qwen2.5 Technical Report. arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Abdin, M., et al. (2024). Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv:2404.14219. Appendix A. Prompts, wrappers, and attack configuration All text below is reproduced verbatim from our harness. {behavior}, {context}, and {generation} are filled per item; {generation} is truncated to its first 512 tokens before scor...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.