LiMoDE: Rethinking Lifelong Robot Manipulation from a Mixture-of-Dynamic-Experts Perspective
Pith reviewed 2026-06-26 02:02 UTC · model grok-4.3
The pith
A dynamic mixture-of-experts structure learns reusable robot manipulation skills in pre-training and combines them with new experts for lifelong task adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LiMoDE first trains a dynamic MoE during multi-task pre-training that activates a varied number of heterogeneous experts based on motion information to capture prior knowledge for different short-term manipulations. It then applies a lifelong MoE adaptation mechanism that learns new experts and dynamically combines them with the frozen pre-trained experts when facing novel tasks, enabling knowledge transfer and lifelong adaptation.
What carries the argument
The LiMoDE two-stage scheme that uses motion-based dynamic expert activation in pre-training followed by on-the-fly combination of new lifelong experts with frozen ones during adaptation.
If this is right
- Superior performance on simulated lifelong benchmarks and real-world tasks compared with prior parameter-efficient or prompt-based baselines.
- Lifelong adaptation occurs by adding a moderate number of trainable parameters rather than retraining the full model.
- Inference overhead remains limited because only a subset of experts is active for any given motion.
- Knowledge transfer improves when new experts interact dynamically with the frozen pre-trained set instead of operating in isolation.
Where Pith is reading between the lines
- The motion-driven expert split may generalize to other sequential robot skills such as navigation or assembly if similar low-level primitives can be isolated.
- Increasing the expert pool size during pre-training could support longer task sequences without raising interference, provided the activation rule stays motion-based.
- The frozen-expert reuse pattern suggests that early training on diverse motion data creates modular components that later tasks can query selectively.
Load-bearing premise
That motion-based activation of heterogeneous experts during pre-training produces reusable skills that can be freely recombined with newly trained experts without catastrophic interference.
What would settle it
A new manipulation task where the adapted model shows large performance drops on previously learned tasks or requires far more than the reported number of additional parameters to match the claimed accuracy.
Figures

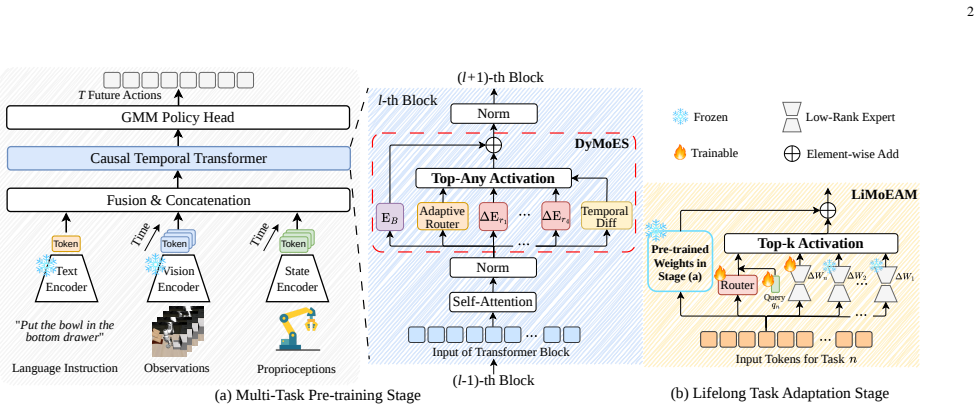

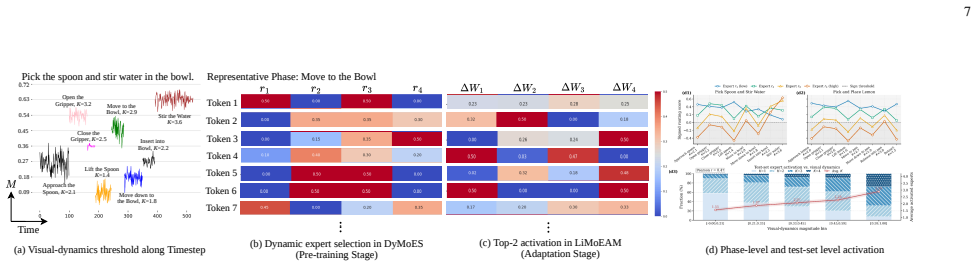
read the original abstract
Building a generalist robot that can leverage prior knowledge for continuous task adaptation remains a significant challenge. Previous works alleviate the catastrophic forgetting problem by parameter-efficient fine-tuning for single-task adaptation. However, they fail to extract reusable skills and model the interaction with other skills effectively. Recent works try to address these issues by learning prompts. Differently, this paper presents an architectural perspective on the Lifelong Mixture of Dynamic Experts (\textit{LiMoDE}), a novel two-stage learning scheme for lifelong robot manipulation. Specifically, a dynamic MoE structure is first proposed in the multi-task pre-training stage to learn prior knowledge, where a varied number of heterogeneous experts are activated based on the motion information to address different short-term manipulations. Subsequently, in the task adaptation stage, we design a lifelong MoE adaptation mechanism % (LiMoEAM) that learns lifelong experts and dynamically combines them with frozen ones for new tasks, facilitating the knowledge transfer during adaptation. The proposed \textit{LiMoDE} is evaluated on both the simulated lifelong learning benchmark and real-world tasks. Extensive experiments demonstrate its effectiveness in achieving superior performance and strong lifelong adaptation by introducing a moderate number of additional trainable parameters and inference overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LiMoDE, a two-stage scheme for lifelong robot manipulation. It uses a dynamic MoE in multi-task pre-training to activate varied numbers of heterogeneous experts based on motion information for learning prior knowledge. Then, in adaptation, lifelong experts are learned and dynamically combined with frozen pre-trained ones. It claims superior performance and strong lifelong adaptation on simulated benchmarks and real-world tasks with moderate additional parameters and inference overhead.
Significance. If the empirical claims hold, the work could advance lifelong robotic learning by providing an architectural separation between skill extraction via dynamic expert activation and interference-free adaptation, potentially improving upon prompt-based or parameter-efficient fine-tuning methods in terms of reusability and efficiency.
major comments (3)
- [Abstract] Abstract: the claim of 'superior performance and strong lifelong adaptation' is asserted without any quantitative results, baselines, ablation studies, or metrics, so the central empirical claim cannot be evaluated from the manuscript.
- [Pre-training stage / Task adaptation stage] Pre-training and adaptation stages: the load-bearing assumption that dynamic MoE pre-training extracts reusable, non-interfering skills (via motion-conditioned expert activation) is stated but not isolated; no ablation (e.g., freezing vs. unfreezing pre-trained experts, per-expert attribution, or forgetting curves across task sequences) is described to confirm transfer without catastrophic interference.
- [Evaluation] Evaluation: the manuscript states evaluation on 'simulated lifelong learning benchmark and real-world tasks' but supplies no tables, figures, or numbers showing parameter counts, inference overhead, or comparisons, undermining the efficiency and superiority assertions.
minor comments (1)
- [Abstract] The parenthetical '(LiMoEAM)' appears once but is never referenced again; either define the acronym consistently or remove it.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'superior performance and strong lifelong adaptation' is asserted without any quantitative results, baselines, ablation studies, or metrics, so the central empirical claim cannot be evaluated from the manuscript.
Authors: We agree the abstract would be strengthened by including key quantitative highlights. The full manuscript contains these results in the experiments section. We will revise the abstract to reference specific metrics (e.g., success rates and overhead comparisons) while remaining concise. revision: yes
-
Referee: [Pre-training stage / Task adaptation stage] Pre-training and adaptation stages: the load-bearing assumption that dynamic MoE pre-training extracts reusable, non-interfering skills (via motion-conditioned expert activation) is stated but not isolated; no ablation (e.g., freezing vs. unfreezing pre-trained experts, per-expert attribution, or forgetting curves across task sequences) is described to confirm transfer without catastrophic interference.
Authors: This observation is fair. The current text describes the mechanism but lacks explicit isolation experiments. We will add ablations on expert freezing, attribution, and forgetting curves in a new subsection of the revised manuscript. revision: yes
-
Referee: [Evaluation] Evaluation: the manuscript states evaluation on 'simulated lifelong learning benchmark and real-world tasks' but supplies no tables, figures, or numbers showing parameter counts, inference overhead, or comparisons, undermining the efficiency and superiority assertions.
Authors: The manuscript does contain evaluation tables and figures with these metrics (performance, parameters, overhead). To prevent any oversight, we will add a consolidated summary table early in the evaluation section and ensure all comparisons are explicitly cross-referenced. revision: partial
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper proposes a two-stage dynamic MoE architecture for lifelong manipulation (pre-training with motion-conditioned experts, then adaptation with frozen experts plus new lifelong experts) and supports its claims solely via experimental results on simulated benchmarks and real-world tasks. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central performance claims are therefore independent of any internal reduction and rest on falsifiable external evaluation, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohanet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovichet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inCoRL, 2023
2023
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Blacket al., “π0: A vision-language-action flow model for general robot control,”arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Learning diffusion policy from primitive skills for robot manipulation,
Z. Gu, M. Yang, D. Zou, and D. Xu, “Learning diffusion policy from primitive skills for robot manipulation,” inAAAI, 2026
2026
-
[5]
Bc-z: Zero-shot task generaliza- tion with robotic imitation learning,
E. Jang, A. Irpan, M. Khansariet al., “Bc-z: Zero-shot task generaliza- tion with robotic imitation learning,” inCoRL, 2022
2022
-
[6]
Think small, act big: Primitive prompt learning for lifelong robot manipulation,
Y . Yao and other, “Think small, act big: Primitive prompt learning for lifelong robot manipulation,” inCVPR, 2025
2025
-
[7]
M2distill: Multi- modal distillation for lifelong imitation learning,
K. Roy, A. Dissanayakc, B. Tidd, and P. Moghadam, “M2distill: Multi- modal distillation for lifelong imitation learning,” inIEEE ICRA, 2025
2025
-
[8]
Policy compatible skill incremental learning via lazy learning interface,
D. Lee, D. Lee, T. Kwack, W. Choi, and H. Woo, “Policy compatible skill incremental learning via lazy learning interface,” inNeurIPS, 2025
2025
-
[9]
A continual learning survey: Defying forgetting in classification tasks,
M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, and T. Tuytelaars, “A continual learning survey: Defying forgetting in classification tasks,” inIEEE TPAMI, 2021
2021
-
[10]
Cril: Continual robot imitation learning via generative and prediction model,
C. Gao, H. Gao, and S. e. a. Guo, “Cril: Continual robot imitation learning via generative and prediction model,” inIEEE IROS, 2021
2021
-
[11]
Bottom-up skill discovery from unsegmented demonstra- tions for long-horizon robot manipulation,
Y . Zhuet al., “Bottom-up skill discovery from unsegmented demonstra- tions for long-horizon robot manipulation,” inIEEE RAL, 2022
2022
-
[12]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gaoet al., “Libero: Benchmarking knowledge transfer for lifelong robot learning,” inNeurIPS, 2023
2023
-
[13]
Lotus: Continual imitation learning for robot manipu- lation through unsupervised skill discovery,
W. Wanet al., “Lotus: Continual imitation learning for robot manipu- lation through unsupervised skill discovery,” inIEEE ICRA, 2024
2024
-
[14]
Expe- rience replay for continual learning,
D. Rolnick, A. Ahuja, J. Schwarz, T. Lillicrap, and G. Wayne, “Expe- rience replay for continual learning,” inNeurIPS, 2019
2019
-
[15]
Efficient data collection for robotic manipulation via compositional generalization,
J. Gao, A. Xie, T. Xiao, C. Finn, and D. Sadigh, “Efficient data collection for robotic manipulation via compositional generalization,” inRSS, 2024
2024
-
[16]
Learning without forgetting,
Z. Liet al., “Learning without forgetting,” inIEEE TPAMI, 2017
2017
-
[17]
Continual learning through synaptic intelligence,
F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” inICML, 2017
2017
-
[18]
Tail: Task-specific adapters for imitation learning with large pretrained models,
Z. Liu, J. Zhang, K. Asadiet al., “Tail: Task-specific adapters for imitation learning with large pretrained models,” inICML, 2024
2024
-
[19]
Learning to modulate pre-trained models in rl,
T. Schmied, M. Hofmarcher, F. Paischer, R. Pascanu, and S. Hochreiter, “Learning to modulate pre-trained models in rl,” inNeurIPS, 2023
2023
-
[20]
Towards a unified view of parameter-efficient transfer learning,
J. He, C. Zhou, X. Ma, T. Berg-Kirkpatrick, and G. Neubig, “Towards a unified view of parameter-efficient transfer learning,” inICLR, 2021
2021
-
[21]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Walliset al., “Lora: Low-rank adaptation of large language models.” inICLR, 2022
2022
-
[22]
Continual sequence generation with adaptive compositional modules,
Y . Zhang, X. Wang, and D. Yang, “Continual sequence generation with adaptive compositional modules,” inACL, 2022
2022
-
[23]
Sapt: A shared attention framework for parameter-efficient continual learning of large language models,
W. Zhao, S. Wang, Y . Huet al., “Sapt: A shared attention framework for parameter-efficient continual learning of large language models,” in ACL, 2024, pp. 11 641–11 661
2024
-
[24]
Adaptformer: Adapting vision transformers for scalable visual recognition,
S. Chen, C. Ge, Z. Tong, and other, “Adaptformer: Adapting vision transformers for scalable visual recognition,” inNeurIPS, 2022
2022
-
[25]
Visual prompt tuning,
M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” inECCV, 2022
2022
-
[26]
The Power of Scale for Parameter-Efficient Prompt Tuning
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,”arXiv:2104.08691, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Incremental learning of retrievable skills for efficient continual task adaptation,
D. Lee, M. Yoo, W. K. Kimet al., “Incremental learning of retrievable skills for efficient continual task adaptation,” inNeurIPS, 2024
2024
-
[28]
Hand me the data: Fast robot adaptation via hand path retrieval,
M. Hong, A. Liang, K. Kimet al., “Hand me the data: Fast robot adaptation via hand path retrieval,”arXiv:2505.20455, 2025
-
[29]
Learning generalizable manipulation policy with adapter-based parameter fine-tuning,
K. Lu, K. T. Ly, W. Hebberdet al., “Learning generalizable manipulation policy with adapter-based parameter fine-tuning,” inIROS, 2024
2024
-
[30]
Efficient continual adaptation of pretrained robotic policy with online meta-learned adapters,
R. Zhuet al., “Efficient continual adaptation of pretrained robotic policy with online meta-learned adapters,”arXiv:2503.18684, 2025
-
[31]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
D. Daiet al., “Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models,”arXiv:2401.06066, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
A. Liuet al., “Deepseek-v2: A strong, economical, and efficient mixture- of-experts language model,”arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Moeut: Mixture-of-experts universal transformers,
R. Csord ´as, K. Irie, J. Schmidhuber, C. Potts, and C. D. Manning, “Moeut: Mixture-of-experts universal transformers,” inNeurIPS, 2024
2024
-
[34]
Switchhead: Accelerating trans- formers with mixture-of-experts attention,
R. Csord ´as, P. Pikekos, K. Irieet al., “Switchhead: Accelerating trans- formers with mixture-of-experts attention,” inNeurIPS, 2024
2024
-
[35]
Statistical advantages of perturbing cosine router in mixture of experts,
H. Nguyen, P. Akbarian, T. Phamet al., “Statistical advantages of perturbing cosine router in mixture of experts,” inICLR, 2025
2025
-
[36]
Routing experts: Learning to route dynamic experts in multi-modal large language models,
Q. Wu, Z. Ke, Y . Zhouet al., “Routing experts: Learning to route dynamic experts in multi-modal large language models,” inICLR, 2025
2025
-
[37]
From sparse to soft mixtures of experts,
J. Puigcerver, C. Riquelme, B. Mustafa, and N. Houlsby, “From sparse to soft mixtures of experts,” inICLR, 2024
2024
-
[38]
arXiv preprint arXiv:2405.00361 (2024)
Z. Liuet al., “Adamole: Fine-tuning large language models with adaptive mixture of low-rank adaptation experts,”arXiv:2405.00361, 2024
-
[39]
Mixture of lora experts,
X. Wu, S. Huang, and F. Wei, “Mixture of lora experts,” inICLR, 2024
2024
-
[40]
Omni-smola: Boosting generalist multimodal models with soft mixture of low-rank experts,
J. Wuet al., “Omni-smola: Boosting generalist multimodal models with soft mixture of low-rank experts,” inCVPR, 2024
2024
-
[41]
Moe-loco: Mixture of experts for multitask locomotion,
R. Huang, S. Zhu, Y . Du, and H. Zhao, “Moe-loco: Mixture of experts for multitask locomotion,”arXiv:2503.08564, 2025
-
[42]
Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning,
Y . Wang, Y . Zhang, M. Huoet al., “Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning,” inCoRL, 2024
2024
-
[43]
Efficient diffusion transformer policies with mixture of expert denoisers for multitask learning,
M. Reusset al., “Efficient diffusion transformer policies with mixture of expert denoisers for multitask learning,” inICLR, 2025
2025
-
[44]
W. Shen, Y . Liu, Y . Wuet al., “Expertise need not monopolize: Action- specialized mixture of experts for vision-language-action learning,” arXiv:2510.14300, 2025
-
[45]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Fenget al., “Diffusion policy: Visuomotor policy learning via action diffusion,” inIJRR, 2025
2025
-
[46]
Learning grounded finite-state representations from unstructured demonstrations,
S. Niekumet al., “Learning grounded finite-state representations from unstructured demonstrations,”IJRR, 2015
2015
-
[47]
Generative skill chaining: Long-horizon skill planning with diffusion models,
U. A. Mishra, S. Xue, Y . Chen, and D. Xu, “Generative skill chaining: Long-horizon skill planning with diffusion models,” inCoRL, 2023
2023
-
[48]
Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution,
Z. Lianget al., “Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution,” inCVPR, 2024
2024
-
[49]
A framework for behavioural cloning
M. Bain and C. Sammut, “A framework for behavioural cloning.” in Machine intelligence, 1995
1995
-
[50]
Learning transferable visual models from natural language supervision,
A. Radfordet al., “Learning transferable visual models from natural language supervision,” inICML, 2021
2021
-
[51]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inAAAI, 2018
2018
-
[52]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeeret al., “Outrageously large neural networks: The sparsely- gated mixture-of-experts layer,”arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhinet al., “Gshard: Scaling giant models with conditional computation and automatic sharding,”arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[54]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[55]
Load balancing mixture of experts with similarity preserving routers,
N. Omi, S. Sen, and A. Farhadi, “Load balancing mixture of experts with similarity preserving routers,”arXiv preprint arXiv:2506.14038, 2025
-
[56]
Advancing expert specialization for better moe,
H. Guo, H. Lu, G. Nanet al., “Advancing expert specialization for better moe,”NIPS, vol. 38, pp. 48 767–48 809, 2026
2026
-
[57]
Synergistic intra-and cross-layer regularization losses for moe expert specialization,
R. Huet al., “Synergistic intra-and cross-layer regularization losses for moe expert specialization,”arXiv:2602.14159, 2026
-
[58]
Continual learning with tiny episodic memories,
A. Chaudhry, M. Rohrbach, M. Elhoseinyet al., “Continual learning with tiny episodic memories,” inWorkshop on Multi-Task and Lifelong Reinforcement Learning, 2019
2019
-
[59]
Lifelong robotic reinforcement learning by retaining experiences,
A. Xie and C. Finn, “Lifelong robotic reinforcement learning by retaining experiences,” inCoLLA. PMLR, 2022, pp. 838–855
2022
-
[60]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kimet al., “Openvla: An open-source vision-language-action model,”arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Universal actions for enhanced embodied foundation models,
J. Zheng, J. Li, D. Liuet al., “Universal actions for enhanced embodied foundation models,” inCVPR, 2025. 9
2025
-
[62]
Learning to act anywhere with task-centric latent actions,
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li, “Learning to act anywhere with task-centric latent actions,” inRSS, 2025
2025
-
[63]
Q. Liet al., “Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation,” arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
M. J. Kim, C. Finn, and P. Liang, “Fine-tuning vision-language-action models: Optimizing speed and success,”arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Florence-vl: Enhancing vision-language models with generative vision encoder and depth-breadth fusion,
J. Chenet al., “Florence-vl: Enhancing vision-language models with generative vision encoder and depth-breadth fusion,” inCVPR, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.