LWDrive: Layer-Wise World-Model-Guided Vision-Language Model Planning for Autonomous Driving
Pith reviewed 2026-06-30 06:32 UTC · model grok-4.3
The pith
Layer-wise world-model guidance refines coarse VLM trajectories into accurate driving plans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
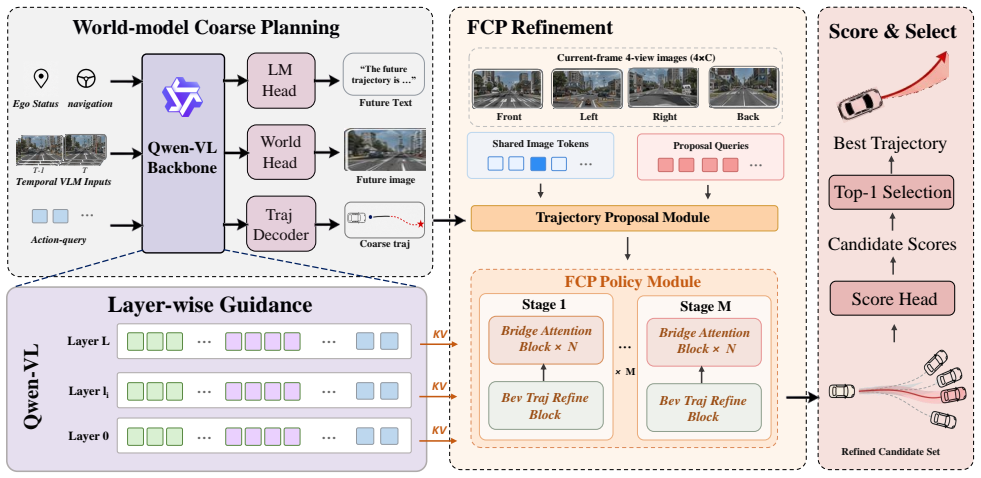
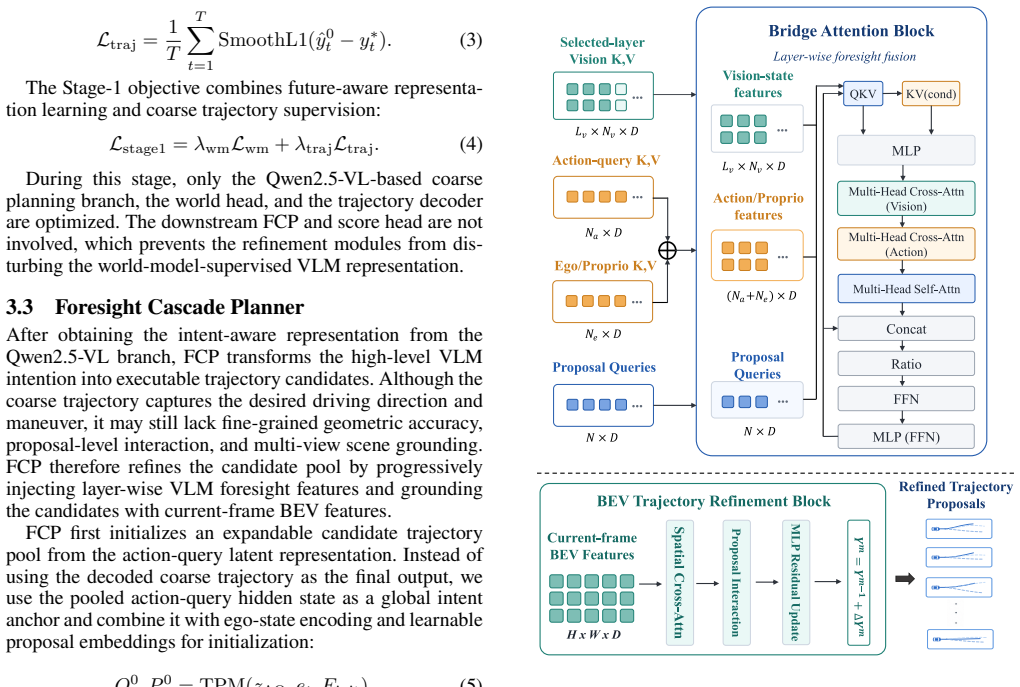
LWDrive treats the VLM output only as an intent-aware coarse plan, expands a diverse candidate space around it, and progressively refines the candidates through a Foresight Cascade Planner. Future-frame generation supervision injects planning-relevant predictive dynamics into the VLM's internal hidden states. The planner exploits VLM features across multiple layers, integrates historical temporal states, Action-Query representations, and current-frame multi-view BEV features to refine trajectories in a coarse-to-fine manner, enabling correction of spatial positions and motion trends while preserving the high-level driving intention. A score head then selects the best refined trajectory as th
What carries the argument
Foresight Cascade Planner (FCP), which exploits multi-layer VLM features under world-model supervision to refine trajectory candidates in a coarse-to-fine sequence.
If this is right
- Refined trajectories correct spatial positions and motion trends while preserving high-level driving intention from the VLM.
- Trajectory refinement is grounded with multi-view scene cues from BEV features.
- A score head evaluates refined candidates and selects the final planning output.
- The framework achieves 92.0 on the NAVSIM benchmark and 89.6 on NAVSIM-v2.
Where Pith is reading between the lines
- The same supervision-plus-cascade pattern could be tested on VLM planners for other robotic tasks such as manipulation or navigation.
- If the layer-wise refinement proves stable, it may reduce the need for separate geometric post-processors in VLM-based systems.
- Success would suggest that predictive world-model signals can be injected into existing VLMs without changing their core architecture.
Load-bearing premise
Future-frame generation supervision successfully injects planning-relevant predictive dynamics into the VLM hidden states and the cascade planner can refine candidates without introducing new spatial or motion errors.
What would settle it
If ablation experiments that remove future-frame supervision or the multi-layer cascade refinement produce equal or lower NAVSIM scores than the full model, the claim that layer-wise world-model guidance improves planning accuracy would be falsified.
Figures


read the original abstract
Vision-Language Models (VLMs) provide powerful semantic understanding and commonsense reasoning for End-to-End Autonomous Driving (E2E-AD) planning. However, trajectories directly generated by VLMs often encode only coarse driving intentions and remain insufficient for geometrically accurate, future-aware, and multi-view-grounded planning. To address these limitations, we develop the Layer-Wise World-Model-Guided Driving framework (LWDrive). LWDrive is a VLM planning framework that refines coarse trajectories through layer-wise world-model guidance. Instead of treating the VLM output as the final trajectory, LWDrive uses it as an intent-aware coarse plan, expands a diverse candidate space around it, and progressively refines the candidates through a Foresight Cascade Planner (FCP). Specifically, we introduce future-frame generation supervision to encourage the VLM to learn forward-looking scene representations, thereby injecting planning-relevant predictive dynamics into its internal hidden states. Built upon these world-model-supervised representations, FCP exploits VLM features across multiple layers and integrates historical temporal states, Action-Query representations, and current-frame multi-view Bird's-Eye-View (BEV) features to refine candidate trajectories in a coarse-to-fine manner. This design enables progressive correction of spatial positions and motion trends while grounding trajectory refinement with multi-view scene cues and preserving the high-level driving intention produced by the large model. Finally, a score head evaluates the refined candidates and selects the best trajectory as the final planning output. Experiments show that LWDrive achieves a score of 92.0 on the NAVSIM benchmark and 89.6 on NAVSIM-v2. Code and models will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LWDrive, a VLM-based framework for end-to-end autonomous driving planning. It treats VLM outputs as coarse intent-aware trajectories, applies future-frame generation supervision to inject predictive dynamics into hidden states, and uses a Foresight Cascade Planner (FCP) to progressively refine candidate trajectories in a coarse-to-fine manner by combining multi-layer VLM features with historical states, Action-Query representations, and multi-view BEV features. A score head then selects the final trajectory. Experiments report scores of 92.0 on NAVSIM and 89.6 on NAVSIM-v2.
Significance. If the central mechanism is validated, the work could meaningfully advance E2E-AD by showing how to retain VLM commonsense reasoning while achieving geometric and motion accuracy through world-model-guided refinement. The layer-wise cascade design and future-frame supervision are potentially generalizable ideas, but the absence of supporting analyses for representation quality limits the assessed impact.
major comments (2)
- [Abstract] Abstract: The reported scores of 92.0 (NAVSIM) and 89.6 (NAVSIM-v2) are presented without any baseline comparisons, ablation results, error bars, dataset statistics, or statistical significance tests, making it impossible to determine whether the gains are attributable to the proposed layer-wise world-model guidance or to other factors.
- [Abstract] Abstract (and method overview): No evidence is supplied that future-frame generation supervision causes VLM hidden states to encode planning-relevant predictive dynamics rather than purely semantic features. Without probing, representation similarity metrics, or controlled ablations isolating this supervision effect, the claim that FCP can reliably refine trajectories without introducing new spatial or motion errors rests on an unverified assumption.
minor comments (2)
- The description of candidate expansion around the coarse plan and the exact architecture of the score head should be expanded with pseudocode or a diagram for reproducibility.
- Clarify the precise integration of Action-Query representations within the FCP cascade and whether any additional learned parameters are introduced beyond the VLM backbone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas where the abstract and supporting analyses can be strengthened to better substantiate the claims. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported scores of 92.0 (NAVSIM) and 89.6 (NAVSIM-v2) are presented without any baseline comparisons, ablation results, error bars, dataset statistics, or statistical significance tests, making it impossible to determine whether the gains are attributable to the proposed layer-wise world-model guidance or to other factors.
Authors: We agree that the abstract would benefit from additional context. The full manuscript includes baseline comparisons in the experiments section showing improvements over prior methods, along with ablations. In the revision, we will update the abstract to reference key baseline scores and the magnitude of gains, and ensure the main text explicitly includes error bars, dataset statistics, and significance tests to demonstrate attribution to the proposed components. revision: yes
-
Referee: [Abstract] Abstract (and method overview): No evidence is supplied that future-frame generation supervision causes VLM hidden states to encode planning-relevant predictive dynamics rather than purely semantic features. Without probing, representation similarity metrics, or controlled ablations isolating this supervision effect, the claim that FCP can reliably refine trajectories without introducing new spatial or motion errors rests on an unverified assumption.
Authors: We acknowledge that the current version lacks direct empirical validation such as probing or isolated ablations for the supervision effect. In the revised manuscript, we will add controlled ablations that isolate the future-frame generation supervision, along with representation similarity metrics or probing results where feasible, to confirm that the hidden states encode planning-relevant predictive dynamics and support the FCP refinement claims. revision: yes
Circularity Check
No circularity: additive pipeline with external supervision and refinement steps
full rationale
The paper proposes an architectural pipeline (VLM coarse plan + future-frame supervision + FCP refinement using multi-layer features) whose final output is not shown by any equation or self-citation to be definitionally equivalent to its training inputs. The future-frame loss is an external supervision signal whose effect on hidden-state geometry is an empirical claim, not a tautology. No fitted parameter is renamed as a prediction, no uniqueness theorem is imported from the authors' prior work, and the reported NAVSIM scores are benchmark measurements rather than quantities forced by internal definitions. The derivation chain therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dauner, Daniel and Hallgarten, Marcel and Li, Tianyu and Weng, Xinshuo and Huang, Zhiyu and Yang, Zetong and Li, Hongyang and Gilitschenski, Igor and Ivanovic, Boris and Pavone, Marco and Geiger, Andreas and Chitta, Kashyap , booktitle =
-
[2]
2025 , eprint =
Pseudo-Simulation for Autonomous Driving , author =. 2025 , eprint =
2025
-
[3]
and Vora, Sourabh and Liong, Venice Erin and Xu, Qiang and Krishnan, Anush and Pan, Yu and Baldan, Giancarlo and Beijbom, Oscar , booktitle =
Caesar, Holger and Bankiti, Varun and Lang, Alex H. and Vora, Sourabh and Liong, Venice Erin and Xu, Qiang and Krishnan, Anush and Pan, Yu and Baldan, Giancarlo and Beijbom, Oscar , booktitle =
-
[4]
2023 , howpublished =
2023
-
[5]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Z...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Deep Residual Learning for Image Recognition , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
-
[7]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =
-
[8]
Advances in Neural Information Processing Systems , volume =
Denoising Diffusion Probabilistic Models , author =. Advances in Neural Information Processing Systems , volume =
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
High-Resolution Image Synthesis with Latent Diffusion Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[10]
Li, Zhiqi and Wang, Wenhai and Li, Hongyang and Xie, Enze and Sima, Chonghao and Lu, Tong and Yu, Qiao and Dai, Jifeng , journal =
-
[11]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
-
[12]
Hu, Shengchao and Chen, Li and Wu, Penghao and Li, Hongyang and Yan, Junchi and Tao, Dacheng , booktitle =
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Planning-Oriented Autonomous Driving , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[14]
Jiang, Bo and Chen, Shaoyu and Xu, Qing and Liao, Bencheng and Chen, Jiajie and Zhou, Helong and Zhang, Qian and Liu, Wenyu and Huang, Chang and Wang, Xinggang , booktitle =
-
[15]
2025 IEEE International Conference on Robotics and Automation , pages =
SparseDrive: End-to-End Autonomous Driving via Sparse Scene Representation , author =. 2025 IEEE International Conference on Robotics and Automation , pages =
2025
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
- [17]
-
[18]
Guo, Ke and Liu, Haochen and Wu, Xiaojun and Pan, Jia and Lv, Chen , year =. 2505.15111 , archivePrefix =
-
[19]
PRIX: Learning to Plan from Raw Pixels for End-to-End Autonomous Driving
Wozniak, Maciej K. and Liu, Lianhang and Cai, Yixi and Jensfelt, Patric , year =. 2507.17596 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
DIVER: Reinforced Diffusion Breaks Imitation Bottlenecks in End-to-End Autonomous Driving
Song, Ziying and Liu, Lin and Pan, Hongyu and Liao, Bencheng and Guo, Mingzhe and Yang, Lei and Zhang, Yongchang and Xu, Shaoqing and Jia, Caiyan and Luo, Yadan , year =. 2507.04049 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Drama: An efficient end-to-end motion planner for autonomous driving with mamba
Yuan, Chengran and Zhang, Zhanqi and Sun, Jiawei and Sun, Shuo and Huang, Zefan and Lee, Christina Dao Wen and Li, Dongen and Han, Yuhang and Wong, Anthony and Tee, Keng Peng and Ang, Marcelo H. , year =. 2408.03601 , archivePrefix =
-
[22]
Shi, Chen and Shi, Shaoshuai and Sheng, Kehua and Zhang, Bo and Jiang, Li , year =. 2505.19239 , archivePrefix =
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
DriveSuprim: Towards Precise Trajectory Selection for End-to-End Planning , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
DiffRefiner: Coarse to Fine Trajectory Planning via Diffusion Refinement with Semantic Interaction for End-to-End Autonomous Driving , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[25]
Feng, Rui and Xi, Ning and Chu, Duanfeng and Wang, Rukang and Deng, Zejian and Wang, Anzheng and Lu, Liping and Wang, Jinxiang and Huang, Yanjun , year =. 2504.19580 , archivePrefix =
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving? , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
DriveWorld: 4D Pre-Trained Scene Understanding via World Models for Autonomous Driving , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[28]
2024 , eprint =
Enhancing End-to-End Autonomous Driving with Latent World Model , author =. 2024 , eprint =
2024
-
[29]
End-to-end driving with online trajectory evaluation via bev world model
Li, Yingyan and Wang, Yuqi and Liu, Yang and He, Jiawei and Fan, Lue and Zhang, Zhaoxiang , year =. End-to-End Driving with Online Trajectory Evaluation via. 2504.01941 , archivePrefix =
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Epona: Autoregressive Diffusion World Model for Autonomous Driving , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[31]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
DrivingGPT: Unifying Driving World Modeling and Planning with Multimodal Autoregressive Transformers , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[32]
Zheng, Wenzhao and Chen, Weiliang and Huang, Yuanhui and Zhang, Borui and Duan, Yueqi and Lu, Jiwen , booktitle =
-
[33]
2025 , eprint =
World4Drive: End-to-End Autonomous Driving via Intention-Aware Physical Latent World Model , author =. 2025 , eprint =
2025
-
[34]
Jia, Feiyang and Liu, Lin and Song, Ziying and Jia, Caiyan and Ye, Hangjun and Hao, Xiaoshuai and Chen, Long , year =. 2602.06521 , archivePrefix =
-
[35]
Zhou, Xinyu and Liang, Dingkang and Tu, Shuyuan and Chen, Xinyu and Ding, Yuhang and Zhang, Dong and Tan, Fei and Zhao, Hang and Bai, Xiang , year =. 2501.14729 , archivePrefix =
-
[36]
2023 , eprint =
Copilot4D: Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion , author =. 2023 , eprint =
2023
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Visual Point Cloud Forecasting Enables Scalable Autonomous Driving , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[38]
and Liu, Yu and Li, Hongsheng , booktitle =
Shao, Hao and Hu, Yuxuan and Wang, Letian and Song, Guanglu and Waslander, Steven L. and Liu, Yu and Li, Hongsheng , booktitle =
-
[39]
Tian, Xiaoyu and Gu, Junru and Li, Boyuan and Liu, Yang and Wang, Yuxuan and Zhao, Zhiyuan and Zhan, Kai and Jia, Peng and Lang, Xianpeng and Zhao, Hang , booktitle =
-
[40]
GPT-Driver: Learning to Drive with GPT
Mao, Jiageng and Qian, Yuxi and Ye, Junjie and Zhao, Hang and Wang, Yue , year =. 2310.01415 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Zhou, Zewei and Cai, Tianhui and Zhao, Seth Z. and Zhang, Yun and Huang, Zhiyu and Zhou, Bolei and Ma, Jiaqi , year =. 2506.13757 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Li, Yingyan and Shang, Shuyao and Liu, Weisong and Zhan, Bing and Wang, Haochen and Wang, Yuqi and Chen, Yuntao and Wang, Xiaoman and An, Yasong and Tang, Chufeng and Hou, Lu and Fan, Lue and Zhang, Zhaoxiang , year =. 2510.12796 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
2025 , eprint =
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving , author =. 2025 , eprint =
2025
-
[44]
Li, Jingyu and Wu, Junjie and Hu, Dongnan and Huang, Xiangkai and Sun, Bin and Hao, Zhihui and Lang, Xianpeng and Zhu, Xiatian and Zhang, Li , year =. 2601.05640 , archivePrefix =
-
[45]
Zhou, Zewei and Yang, Ruining and Qi, Xuewei and Guo, Yiluan and Chen, Sherry X. and Feng, Tao and Pistunova, Kateryna and Shen, Yishan and Su, Lili and Ma, Jiaqi , year =. 2604.19710 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
2025 , eprint =
Unified Vision-Language-Action Model , author =. 2025 , eprint =
2025
-
[47]
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
Zeng, Shuang and Chang, Xinyuan and Xie, Mengwei and Liu, Xinran and Bai, Yifan and Pan, Zheng and Xu, Mu and Wei, Xing , year =. FutureSightDrive: Thinking Visually with Spatio-Temporal. 2505.17685 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
OpenDriveVLA: Towards End-to-End Autonomous Driving with Large Vision Language Action Model , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[49]
Fu, Haoyu and Zhang, Diankun and Zhao, Zongchuang and Cui, Jianfeng and Liang, Dingkang and Zhang, Chong and Zhang, Dingyuan and Xie, Hongwei and Wang, Bing and Bai, Xiang , booktitle =
-
[50]
Jiang, Anqing and Gao, Yu and Sun, Zhigang and Wang, Yiru and Wang, Jijun and Chai, Jinghao and Cao, Qian and Heng, Yuweng and Jiang, Hao and Zhang, Zongzheng and Guo, Xianda and Sun, Hao and Zhao, Hao , year =. 2505.19381 , archivePrefix =
-
[51]
Xu, Mengwei and others , year =. 2512.11872 , archivePrefix =
-
[52]
DriveFine: Refining-Augmented Masked Diffusion
Dang, Cheng and others , year =. DriveFine: Refining-Augmented Masked Diffusion. 2602.14577 , archivePrefix =
-
[53]
Hwang, Jyh-Jing and Xu, Runsheng and Lin, Hao and Hung, Wei-Chih and Ji, Jingwei and Choi, Kyle and Huang, Dengxin and He, Tong and Covington, Paul and Sapp, Benjamin and Zhou, Yin and Guo, Jiong and Anguelov, Dragomir and Tan, Mingxing , booktitle =
-
[54]
2024 , eprint =
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning , author =. 2024 , eprint =
2024
-
[55]
Han, Wencheng and Guo, Dongqian and Xu, Cheng-Zhong and Shen, Jianbing , year =. 2401.03641 , archivePrefix =
-
[56]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models from Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =
-
[57]
Advances in Neural Information Processing Systems , volume =
Flamingo: A Visual Language Model for Few-Shot Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[58]
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle =
-
[59]
Advances in Neural Information Processing Systems , volume =
Visual Instruction Tuning , author =. Advances in Neural Information Processing Systems , volume =
-
[60]
Computer Vision -- ECCV 2024 , pages =
Marcu, Ana-Maria and Chen, Long and H. Computer Vision -- ECCV 2024 , pages =
2024
-
[61]
Qian, Tianwen and Chen, Jingjing and Zhuo, Linhai and Jiao, Yang and Jiang, Yu-Gang , booktitle =
-
[62]
Computer Vision -- ECCV 2024 , pages =
Reason2Drive: Towards Interpretable and Chain-Based Reasoning for Autonomous Driving , author =. Computer Vision -- ECCV 2024 , pages =
2024
-
[63]
Sima, Chonghao and Renz, Katrin and Chitta, Kashyap and Chen, Long and Zhang, Han and Xie, Chunjing and Beisswenger, Jan and Luo, Ping and Geiger, Andreas and Li, Hongyang , booktitle =
-
[64]
Computer Vision -- ECCV 2024 , year =
Dolphins: Multimodal Language Model for Driving , author =. Computer Vision -- ECCV 2024 , year =
2024
-
[65]
and Velipasalar, Senem and Ren, Liu , booktitle =
Pan, Chenbin and Yaman, Burhaneddin and Nesti, Tommaso and Mallik, Abhirup and Allievi, Alessandro G. and Velipasalar, Senem and Ren, Liu , booktitle =
-
[66]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Generative Planning with 3D-Vision Language Pre-training for End-to-End Autonomous Driving , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[67]
Song, Wenxuan and Zhou, Ziyang and Zhao, Han and Chen, Jiayi and Ding, Pengxiang and Yan, Haodong and Huang, Yuxin and Tang, Feilong and Wang, Donglin and Li, Haoang , booktitle =
-
[68]
Proceedings of The 7th Conference on Robot Learning , series =
Parting with Misconceptions about Learning-Based Vehicle Motion Planning , author =. Proceedings of The 7th Conference on Robot Learning , series =
-
[69]
2025 , eprint =
Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models , author =. 2025 , eprint =
2025
-
[70]
2025 , eprint =
InsightDrive: Insight Scene Representation for End-to-End Autonomous Driving , author =. 2025 , eprint =
2025
-
[71]
2024 , eprint =
Doe-1: Closed-Loop Autonomous Driving with Large World Model , author =. 2024 , eprint =
2024
-
[72]
2024 , eprint =
Making Large Language Models Better Planners with Reasoning-Decision Alignment , author =. 2024 , eprint =
2024
-
[73]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops , pages =
OpenEMMA: Open-Source Multimodal Model for End-to-End Autonomous Driving , author =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops , pages =
-
[74]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[75]
2026 , eprint =
Bridging Scene Generation and Planning: Driving with World Model via Unifying Vision and Motion Representation , author =. 2026 , eprint =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.