SA-VLA: State-aware tokenizer for improving Vision-Language-Action Models' performance
Pith reviewed 2026-06-30 05:37 UTC · model grok-4.3
The pith
Conditioning action tokens on robot proprioceptive state allows each discrete code to represent multiple continuous actions and raises VLA success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that state-conditioned action decoding in a VQ tokenizer expands the effective support of each discrete code by making reconstruction depend on the robot's current proprioceptive state, thereby reducing the compression gap between discrete tokens and continuous controls without altering the model interface.
What carries the argument
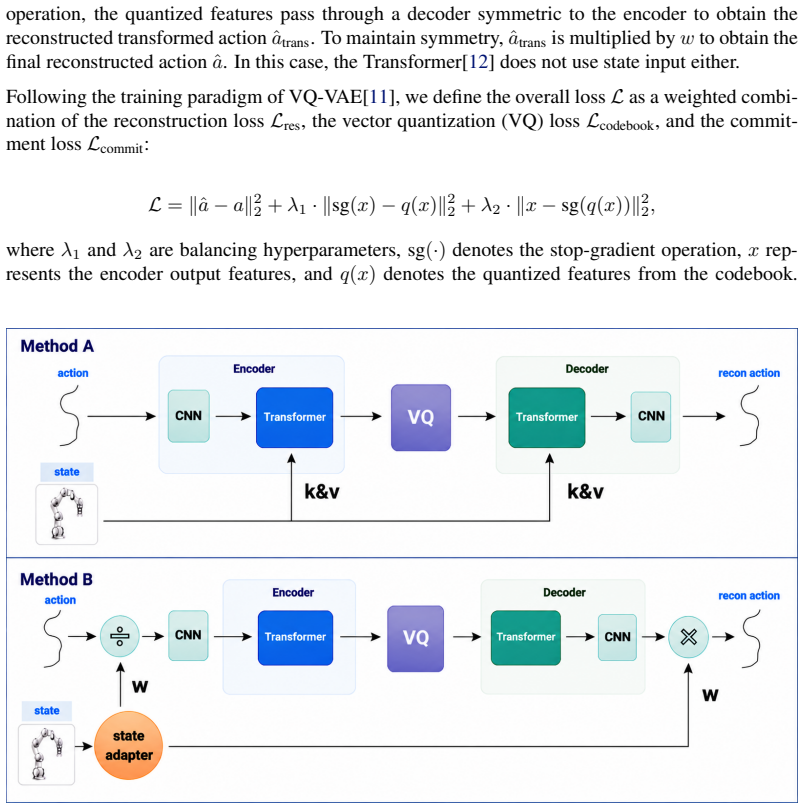
Lightweight state adapter that predicts action-wise modulation factors to condition continuous action reconstruction on proprioceptive state.
If this is right
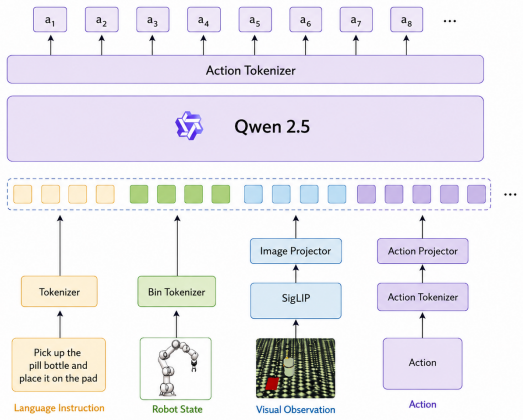
- The state adapter integrates into existing LLM-based VLA policies with only minimal interface changes and supports both autoregressive and parallel token decoding.
- Average success across the 12 RoboTwin manipulation tasks rises from 0.29 to 0.56.
- Zero-shot sim-to-real average success on three real-world tasks rises from 0.15 to 0.33.
- Each discrete token can now represent a family of state-dependent actions while the codebook size and autoregressive structure remain unchanged.
Where Pith is reading between the lines
- The same state-modulation idea could be tested in non-robotics sequence models where context changes the meaning of a token.
- Smaller codebooks paired with state adapters might reach performance levels previously requiring larger codebooks.
- Proprioceptive state may be an under-used conditioning signal in other discrete policy architectures beyond VLA.
Load-bearing premise
The measured gains are produced by the state-conditioning mechanism itself rather than by any differences in training procedure or implementation details between SA-VLA and the baseline tokenizers.
What would settle it
Train the strongest baseline tokenizer with the exact same data, optimizer schedule, and hyperparameters used for SA-VLA but without any state input, then compare success rates on the same 12 RoboTwin tasks.
Figures


read the original abstract
Discrete action tokenization provides a compact interface for autoregressive VLA policies, but accurately recovering continuous robot actions from discrete codes remains challenging. Existing tokenizers typically map each discrete code to a fixed continuous action prototype, ignoring the robot's current proprioceptive state. This limitation is particularly pronounced in manipulation, where the same action token may require different continuous controls under different joint configurations, object poses, and contact conditions. We therefore propose SA-VLA, a state-aware action tokenizer that conditions action decoding on robot state. We study two state-injection mechanisms for VQ-based action tokenization: cross-attention between state and action features, and a lightweight state adapter that predicts action-wise modulation factors for state-conditioned action modulation and reconstruction. The adapter formulation expands the effective support of a finite codebook by allowing each discrete token to represent a family of state-dependent continuous actions, while preserving the efficiency and compatibility of discrete action modeling. Integrated into an LLM-based VLA policy, SA-VLA supports both autoregressive and parallel action-token decoding with minimal changes to the model interface. On 12 RoboTwin manipulation tasks, SA-VLA improves the average success rate from 0.29 to 0.56 over the strongest tokenizer baseline. In zero-shot sim-to-real experiments on three real-world tasks, it further improves average success from 0.15 to 0.33 over the strongest tokenizer baseline. These results demonstrate that state-conditioned action decoding is a simple and effective mechanism for reducing the compression gap in discrete VLA policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SA-VLA, a state-aware action tokenizer for VLA models that conditions discrete action decoding on the robot's proprioceptive state. It introduces two mechanisms—cross-attention between state and action features, and a lightweight state adapter that predicts modulation factors—to allow each discrete token to represent a family of state-dependent continuous actions. The method is integrated into an LLM-based VLA policy supporting autoregressive and parallel decoding. On 12 RoboTwin manipulation tasks, it reports raising average success rate from 0.29 to 0.56 versus the strongest tokenizer baseline; in zero-shot sim-to-real transfer on three real-world tasks, it reports raising average success from 0.15 to 0.33.
Significance. If the gains are shown to stem specifically from state conditioning rather than uncontrolled variables, the work would be significant for discrete VLA policies. It directly targets the compression gap in action tokenization for contact-rich manipulation, where identical tokens must map to different controls under varying joint configurations and contacts. The adapter formulation preserves discrete modeling efficiency while expanding effective codebook support, and the minimal interface changes make it compatible with existing autoregressive VLAs.
major comments (2)
- [Abstract / Experiments] Abstract (and Experiments section): the central empirical claim attributes the 0.29→0.56 (RoboTwin) and 0.15→0.33 (sim-to-real) gains to the state-injection mechanisms, yet no ablation is described that holds codebook size, training schedule, VLA integration, optimizer, and data augmentations fixed while toggling only the cross-attention path or state adapter. Because the adapter alters the reconstruction objective and cross-attention changes feature flow, any unmentioned hyper-parameter or implementation mismatch could fully explain the deltas; this is load-bearing for the claim that state conditioning itself is the effective mechanism.
- [Abstract] Abstract: success rates are reported as point estimates with no error bars, standard deviations, or number of evaluation seeds. Without these, it is impossible to assess whether the reported improvements are statistically reliable or sensitive to random seeds, which is required to support the conclusion that state-aware tokenization reduces the compression gap.
minor comments (2)
- [Abstract] Abstract: the phrase 'strongest tokenizer baseline' is undefined; the manuscript should name the specific baseline tokenizer(s), their codebook sizes, and training details for reproducibility.
- The manuscript should clarify whether the state adapter is trained jointly with the VLA policy or only with the tokenizer, and whether the modulation factors are applied at inference time only or also during policy training.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and commit to revisions that directly strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract (and Experiments section): the central empirical claim attributes the 0.29→0.56 (RoboTwin) and 0.15→0.33 (sim-to-real) gains to the state-injection mechanisms, yet no ablation is described that holds codebook size, training schedule, VLA integration, optimizer, and data augmentations fixed while toggling only the cross-attention path or state adapter. Because the adapter alters the reconstruction objective and cross-attention changes feature flow, any unmentioned hyper-parameter or implementation mismatch could fully explain the deltas; this is load-bearing for the claim that state conditioning itself is the effective mechanism.
Authors: We agree that isolating the contribution of the state-injection mechanisms (cross-attention and state adapter) while holding codebook size, training schedule, VLA integration, optimizer, and data augmentations fixed is necessary to support the central claim. The current manuscript reports comparisons to baseline tokenizers but does not contain such a controlled ablation. In the revised manuscript we will add this ablation, explicitly toggling only the state-conditioning components. revision: yes
-
Referee: [Abstract] Abstract: success rates are reported as point estimates with no error bars, standard deviations, or number of evaluation seeds. Without these, it is impossible to assess whether the reported improvements are statistically reliable or sensitive to random seeds, which is required to support the conclusion that state-aware tokenization reduces the compression gap.
Authors: We agree that point estimates alone are insufficient to demonstrate statistical reliability. Although the underlying experiments were performed with multiple random seeds, the manuscript reports only averages. In the revised version we will report standard deviations, include error bars in figures, and state the number of evaluation seeds used for both the RoboTwin and sim-to-real results. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external task benchmarks
full rationale
The manuscript presents an empirical proposal for a state-aware action tokenizer (cross-attention and state adapter) and validates it via success-rate comparisons on 12 RoboTwin tasks and three sim-to-real tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the reported deltas (0.29→0.56 or 0.15→0.33) to quantities defined by the method itself. The central claims therefore remain independent of the input data and are evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation. arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Y . Wang, H. Zhu, M. Liu, J. Yang, H.-S. Fang, and T. He. Vq-vla: Improving vision-language- action models via scaling vector-quantized action tokenizers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11089–11099, 2025
2025
-
[7]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
T. Shiba. The compression gap: Why discrete tokenization limits vision-language-action model scaling.arXiv preprint arXiv:2604.03191, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Van Den Oord, O
A. Van Den Oord, O. Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[12]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
- [13]
- [14]
-
[15]
B. Team. Being-h0. 7: A latent world-action model from egocentric videos, 2026
2026
-
[16]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. Cot- vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025. 9
2025
- [17]
-
[18]
J. Zhai, H. Shi, S. Guo, K. Yang, and K. Wang. E-vla: Event-augmented vision-language- action model for dark and blurred scenes.arXiv preprint arXiv:2604.04834, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
S. Yang, X. Hu, Q. Wu, and D. Yang. Vaevq: Enhancing discrete visual tokenization through variational modeling. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 40, pages 11703–11711, 2026
2026
-
[20]
H. Chen, Z. Wang, X. Li, X. Sun, F. Chen, J. Liu, J. Wang, B. Raj, Z. Liu, and E. Barsoum. Softvq-vae: Efficient 1-dimensional continuous tokenizer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28358–28370, 2025
2025
-
[21]
Y . Zhu, B. Li, Y . Xin, Z. Xia, and L. Xu. Addressing representation collapse in vector quantized models with one linear layer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22968–22977, 2025
2025
-
[22]
Elfwing, E
S. Elfwing, E. Uchibe, and K. Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
2018
-
[23]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[26]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transform- ers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[27]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
HumanNet: Scaling Human-centric Video Learning to One Million Hours
Y . Deng and D. Zhou. Humannet: Scaling human-centric video learning to one million hours. arXiv preprint arXiv:2605.06747, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[31]
G. A. Team. Gen-0: Embodied foundation models that scale with physical interaction.Gener- alist AI Blog, 2025. https://generalistai.com/blog/nov-04-2025-GEN-0
2025
-
[32]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020. 10
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[33]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[34]
Dexora: Open-source VLA for High-DoF Bimanual Dexterity
Z. Zhang, J. Pang, Z. Yang, K. Li, M. Liao, S. Zhang, G. Chi, J. Guo, H.-a. Gao, M. Shi, et al. Dexora: Open-source vla for high-dof bimanual dexterity.arXiv preprint arXiv:2605.18722, 2026. 11 Appendix A Detailed Training And Evaluation Recipes A.1 Settings for Data Collection in Simulator We conducted experiments in the RoboTwin simulator using two Pipe...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.