From Accuracy to Visual Dependence: Auditing and Filtering Modality Collapse in Traffic VideoQA
Pith reviewed 2026-06-30 06:11 UTC · model grok-4.3
The pith
Vision-language models often solve traffic video questions without needing the video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
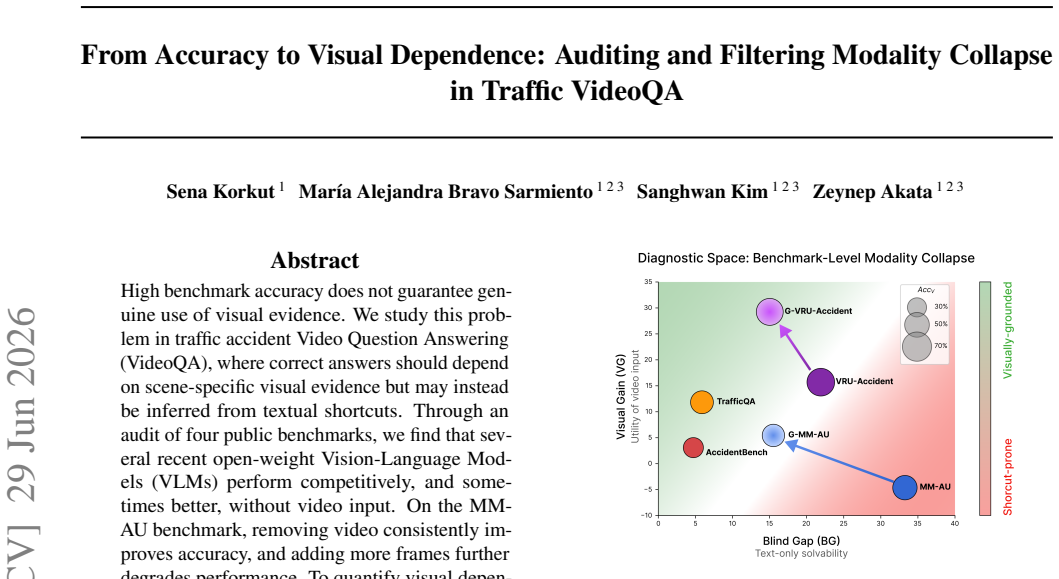
Several recent open-weight Vision-Language Models perform competitively, and sometimes better, without video input on traffic VideoQA benchmarks. On MM-AU, removing video consistently improves accuracy while adding more frames degrades performance. The work introduces Blind Gap and Visual Gain as dataset-level diagnostics of visual dependence and a Shortcut Score for instance-level filtering of shortcut-prone questions, yielding filtered subsets that reduce textual bias and improve visual grounding.
What carries the argument
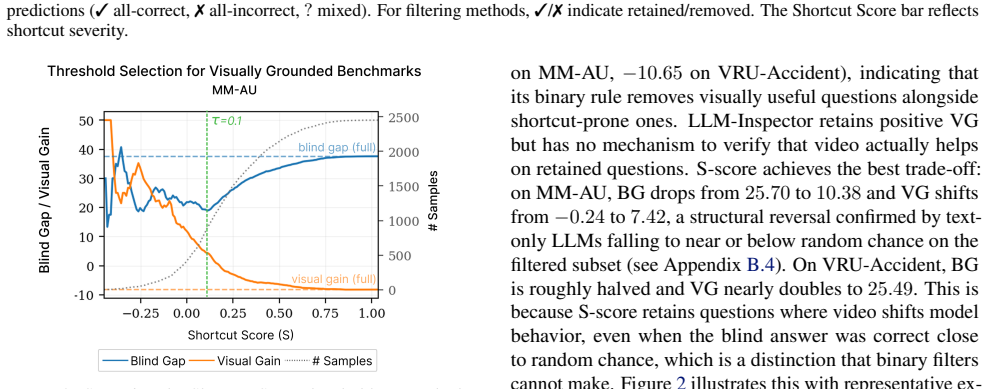
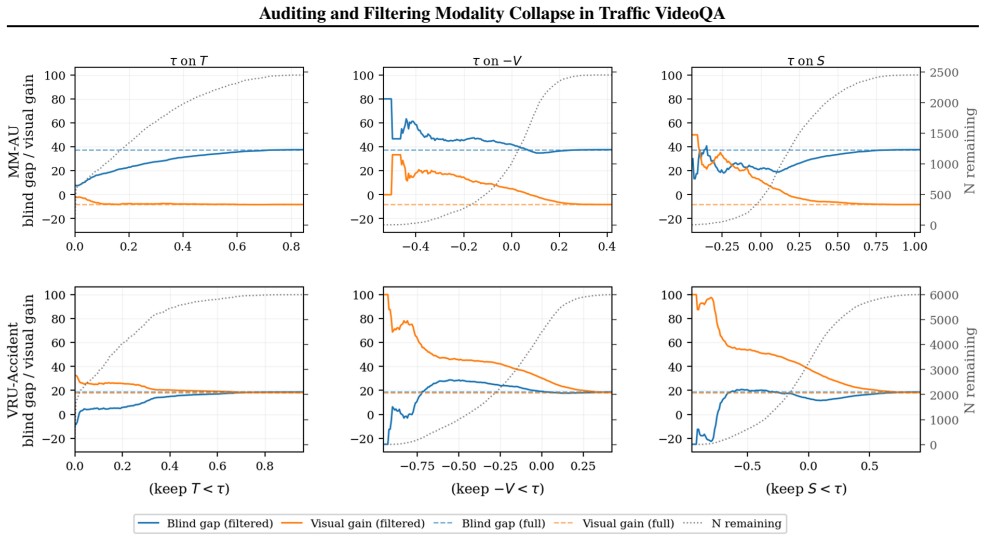
The Shortcut Score, which combines text-only model confidence with signals of visual necessity to enable continuous, training-free filtering of shortcut-prone questions.
If this is right
- Benchmarks exhibit large differences in the degree of visual grounding required.
- Applying the Shortcut Score produces subsets with reduced shortcut bias and improved visual grounding.
- High accuracy on existing benchmarks does not ensure that models use visual evidence.
- Safety-critical VideoQA evaluation must prioritize measures of visual dependence beyond accuracy.
Where Pith is reading between the lines
- Similar modality collapse may exist in other VideoQA domains where text shortcuts are possible.
- Benchmark design should explicitly test whether questions remain solvable after removing visual content.
- The filtering method could be applied at training time to encourage genuine multimodal learning.
Load-bearing premise
That text-only performance above chance on these benchmarks means the questions can be solved without scene-specific visual evidence.
What would settle it
Rewrite the questions to remove all textual patterns that allow correct answers from text alone, then measure whether text-only accuracy falls to chance while video input becomes necessary for high accuracy.
Figures

read the original abstract
High benchmark accuracy does not guarantee genuine use of visual evidence. We study this problem in traffic accident Video Question Answering (VideoQA), where correct answers should depend on scene-specific visual evidence but may instead be inferred from textual shortcuts. Through an audit of four public benchmarks, we find that several recent open-weight Vision-Language Models (VLMs) perform competitively, and sometimes better, without video input. On the MM-AU benchmark, removing video consistently improves accuracy, and adding more frames further degrades performance. To quantify visual dependence, we introduce two dataset-level diagnostics: Blind Gap, measuring above-chance text-only performance, and Visual Gain, measuring the marginal benefit of adding video. We further propose an instance-level Shortcut Score that combines text-only confidence with visual necessity signals, enabling continuous, training-free filtering of shortcut-prone questions. The resulting subsets reduce shortcut bias and improve visual grounding. Our findings reveal large differences in grounding quality across benchmarks and show that visually grounded evaluation, not just high accuracy, is essential in safety-critical VideoQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits four public traffic accident VideoQA benchmarks and reports that recent open-weight VLMs often achieve competitive or superior accuracy without video input, with removing video improving performance and adding frames degrading it on MM-AU. It introduces dataset-level metrics Blind Gap (above-chance text-only performance) and Visual Gain (marginal benefit of video), plus an instance-level Shortcut Score combining text-only confidence and visual necessity signals, to filter shortcut-prone questions and produce more visually grounded subsets. The central claim is that high accuracy does not ensure visual dependence and that these diagnostics are needed for safety-critical evaluation.
Significance. If the audit findings and metrics hold after addressing verification gaps, the work would be significant for exposing limitations in current VideoQA benchmarks and providing training-free tools to improve visual grounding. It directly addresses a practical issue in deploying VLMs for traffic safety applications, where reliance on textual shortcuts could lead to unreliable systems, and highlights benchmark-specific differences in grounding quality.
major comments (2)
- [Metrics definitions and audit interpretation] The definitions of Blind Gap and Visual Gain (introduced after the audit description) rest on the assumption that benchmark questions require scene-specific visual evidence rather than being solvable via textual patterns or common sense. Without independent verification—such as question-type analysis, human studies on visual necessity, or dataset construction details—this risks interpreting dataset artifacts as modality collapse. This assumption is load-bearing for all claims about auditing and filtering visual dependence.
- [Audit results section] The audit results, including the MM-AU finding that removing video improves accuracy while adding frames degrades performance, are stated without quantitative values, error bars, dataset statistics, per-model breakdowns, or verification steps. This absence undermines assessment of effect sizes and reliability, as noted in the abstract's reporting of results.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., accuracy delta on MM-AU) to convey the magnitude of the findings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to strengthen the foundational assumptions of our metrics and to improve the quantitative reporting of our audit results. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: The definitions of Blind Gap and Visual Gain (introduced after the audit description) rest on the assumption that benchmark questions require scene-specific visual evidence rather than being solvable via textual patterns or common sense. Without independent verification—such as question-type analysis, human studies on visual necessity, or dataset construction details—this risks interpreting dataset artifacts as modality collapse. This assumption is load-bearing for all claims about auditing and filtering visual dependence.
Authors: We agree that the metrics are grounded in the premise that traffic accident VideoQA questions are intended to require scene-specific visual evidence, as stated in the original benchmark papers and motivated by safety-critical applications. While we did not perform new human annotation studies, the empirical results (text-only accuracy matching or exceeding video-input accuracy on multiple benchmarks) provide direct evidence of shortcut reliance independent of that assumption. In revision we will add an expanded discussion of benchmark construction details from the source papers, include a question-type breakdown where available, and explicitly note the assumption as a scope limitation rather than claiming universal visual necessity. revision: partial
-
Referee: The audit results, including the MM-AU finding that removing video improves accuracy while adding frames degrades performance, are stated without quantitative values, error bars, dataset statistics, per-model breakdowns, or verification steps. This absence undermines assessment of effect sizes and reliability, as noted in the abstract's reporting of results.
Authors: We acknowledge that the current manuscript version under-reports the numerical details of the audit. The full paper contains per-model tables, but these lack error bars, explicit dataset sizes, and step-by-step verification of the text-only and multi-frame protocols. In the revised manuscript we will insert the missing quantitative values, standard deviations across runs where applicable, benchmark statistics (question counts, video lengths), per-model breakdowns, and a verification subsection describing the exact zero-shot prompting and frame-sampling procedures used. revision: yes
Circularity Check
No significant circularity; empirical measurements are self-contained
full rationale
The paper performs an empirical audit by running VLMs on public benchmarks under text-only, single-frame, and multi-frame conditions and directly reports the resulting accuracies. Blind Gap is defined as above-chance text-only accuracy and Visual Gain as the accuracy delta when video is added; these are transparent arithmetic differences with no fitted parameters, no equations that equate a claimed output to its own input by construction, and no load-bearing self-citations or uniqueness theorems. The Shortcut Score is likewise a composite of the same measured signals. All central claims are therefore observations from external benchmark runs rather than derivations that collapse to their own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Correct answers in the studied traffic VideoQA tasks require scene-specific visual evidence.
invented entities (3)
-
Blind Gap
no independent evidence
-
Visual Gain
no independent evidence
-
Shortcut Score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Flamingo: a Visual Language Model for Few-Shot Learning
Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr, I., Has- son, Y ., Lenc, K., Mensch, A., Millican, K., Reynolds, M., Ring, R., Rutherford, E., Cabi, S., Han, T., Gong, Z., Samangooei, S., Monteiro, M., Menick, J., Borgeaud, S., Brock, A., Nematzadeh, A., Sharifzadeh, S., Binkowski, M., Barreira, R., Vinyals, O., Zisserman, A., and Si- monyan, K. Fl...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
W., Cao, F., Nedaee, T., Raja- balifardi, K., Li, F.-F., Adeli, E., and Ashley, E
Asadi, M., O’Sullivan, J. W., Cao, F., Nedaee, T., Raja- balifardi, K., Li, F.-F., Adeli, E., and Ashley, E. Mi- rage: The illusion of visual understanding.arXiv preprint arXiv:2603.21687,
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y ., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y ., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., and Lin, J. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Brown, E., Yang, J., Yang, S., Fergus, R., and Xie, S. Benchmark designers should “train on the test set” to expose exploitable non-visual shortcuts.arXiv preprint arXiv:2511.04655,
-
[5]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y ., Chen, Z., Duan, H., Wang, J., Qiao, Y ., Lin, D., and Zhao, F. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330, 2024a. Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., Li, B., Luo, P., Lu, T., Qiao, Y ., and D...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Words or vision: Do vision-language models have blind faith in text? In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Deng, A., Cao, T., Chen, Z., and Hooi, B. Words or vision: Do vision-language models have blind faith in text? In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3867–3876,
2025
-
[7]
doi: 10.1109/CVPR52734.2025.00366. Fang, J., Li, L.-l., Zhou, J., Xiao, J., Yu, H., Lv, C., Xue, J., and Chua, T.-S. Abductive ego-view accident video un- derstanding for safe driving perception. InCVPR,
-
[8]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Fu, C., Dai, Y ., Luo, Y ., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y ., Zhang, M., Chen, P., Li, Y ., Lin, S., Zhao, S., Li, K., Xu, T., Zheng, X., Chen, E., Shan, C., He, R., and Sun, X. Video-mme: The first-ever com- prehensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Do Vision Language Models Need to Process Image Tokens?
Ghosh, S., Babu, R. V ., and Agarwal, C. Do vision language models need to process image tokens?arXiv preprint arXiv:2604.09425,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Gu, S., Wang, X., Ying, D., Zhao, H., Yang, R., Jin, M., Li, B., Pavone, M., Yeung-Levy, S., Wang, J., Song, D., and Spanos, C. Accidentbench: Benchmarking multimodal understanding and reasoning in vehicle accidents and beyond.arXiv preprint arXiv:2509.26636,
-
[11]
Kim, Y ., Abdelrahman, A. S., and Abdel-Aty, M. Vru- accident: A vision-language benchmark for video ques- tion answering and dense captioning for accident scene understanding.arXiv preprint arXiv:2507.09815,
- [12]
-
[13]
LLaVA-OneVision: Easy Visual Task Transfer
5 Auditing and Filtering Modality Collapse in Traffic VideoQA Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., and Li, C. Llava- onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Understanding lan- guage prior of lvlms by contrasting chain-of-embedding
Long, L., Oh, C., Park, S., and Li, S. Understanding lan- guage prior of lvlms by contrasting chain-of-embedding. arXiv preprint arXiv:2509.23050,
-
[15]
Mangalam, K., Akshulakov, R., and Malik, J. Egoschema: A diagnostic benchmark for very long-form video language understanding.arXiv preprint arXiv:2308.09126,
-
[16]
Nooralahzadeh, F., Rohanian, O., Zhang, Y ., F ¨urst, J., and Stockinger, K. Arbitration failure, not perceptual blindness: How vision-language models resolve visual- linguistic conflicts.arXiv preprint arXiv:2604.09364,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Wu, H., Li, D., Chen, B., and Li, J. Longvideobench: A benchmark for long-context interleaved video-language understanding.arXiv preprint arXiv:2407.15754,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Xie, S., Kong, L., Dong, Y ., Sima, C., Zhang, W., Chen, Q. A., Liu, Z., and Pan, L. Are vlms ready for autonomous driving? an empirical study from the reliability, data, and metric perspectives.arXiv preprint arXiv:2501.04003,
-
[19]
Zafar, A., Murali, L. K., and Vashist, A. Beyond accu- racy: Evaluating visual grounding in multimodal medical reasoning.arXiv preprint arXiv:2603.03437,
-
[20]
Zhang, Y ., Hwang, E., Zhang, H., Du, P., Jia, Y ., Jiang, D., He, X., Zhang, S., Nie, P., West, P., and Allen, K. R. Watch before you answer: Learning from visually grounded post-training.arXiv preprint arXiv:2604.05117,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
MLVU: Benchmarking Multi-task Long Video Understanding
Zhou, J., Shu, Y ., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y ., Zhang, B., Huang, T., and Liu, Z. Mlvu: Benchmarking multi-task long video understanding.arXiv preprint arXiv:2406.04264,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Dataset Videos Avg
6 Auditing and Filtering Modality Collapse in Traffic VideoQA Table 3.Comparison of the traffic accident VideoQA benchmarks analyzed in this work. Dataset Videos Avg. # Frames QA Pairs Choices Format Reasoning Types MM-AU 11,727 187 11,727 5 MCQ Causal VRU-Accident 1,000 189 6,000 4 MCQ Causal, counterfactual, scene attr. TrafficQA 10,080 189 62,535 4 MCQ...
2021
-
[23]
have expanded multimodal evaluation to richer temporal and causal reasoning over video, with the implicit assumption that such tasks require genuine visual grounding, which accuracy alone cannot verify (Chen et al., 2024a; Zhang et al., 2026). Traffic accident VideoQA is a critical test case: accident causality, agent behavior, and collision dynamics are ...
2026
-
[24]
target precisely this reasoning but report only answer accuracy and no blind baselines, which is the gap this work addresses. Vision-Language Models and the Roots of Language Dominance.Modern VLMs combine a visual encoder, projection module, and autoregressive language backbone, extended to video via frame sampling and spatiotemporal encodings (Bai et al....
2025
-
[25]
in VQA motivated bias-controlled datasets (Goyal et al., 2017; Agrawal et al.,
2017
-
[26]
In multimodal systems this manifests asmodality collapse, where language dominates prediction regardless of visual input (Sim et al., 2025; Deng et al., 2025)
and was later extended to joint image-question correlations (Dancette et al., 2021). In multimodal systems this manifests asmodality collapse, where language dominates prediction regardless of visual input (Sim et al., 2025; Deng et al., 2025). In traffic accident VideoQA, DriveBench (Xie et al.,
2021
-
[27]
Existing auditing approaches either apply binary filtering by removing questions a blind model answers correctly (Asadi et al., 2026; Zhang et al.,
confirms this by showing comparable performance under text-only and full-input conditions. Existing auditing approaches either apply binary filtering by removing questions a blind model answers correctly (Asadi et al., 2026; Zhang et al.,
2026
-
[28]
Binary filtering discards visually ambiguous but grounded questions; dataset-level metrics cannot identify which individual questions are shortcut-prone
, or introduce dataset-level metrics to quantify visual contribution (Chen et al., 2024a; Zafar et al., 2026; Brown et al., 2025; Lee et al., 2025). Binary filtering discards visually ambiguous but grounded questions; dataset-level metrics cannot identify which individual questions are shortcut-prone. OurShortcut Scoreaddresses both limitations by assigni...
2026
-
[29]
Videos can reach approximately 16 minutes, posing a practical challenge for models under a fixed frame budget
targets temporal, spatial, and intent reasoning with a tiered answer set that modulates difficulty. Videos can reach approximately 16 minutes, posing a practical challenge for models under a fixed frame budget. We use only the Land domain subset. B.2. Evaluation Protocol We evaluate four vision-language models at the 7–8B parameter scale: Qwen2.5-VL-7B, I...
2024
-
[30]
A substantial share of what these benchmarks measure is answerable without any video
and MLVU (Zhou et al., 2025), which are widely used benchmarks for video understanding, Blind Gap ranges from roughly 14 to 22 points, comparable to VRU-Accident. A substantial share of what these benchmarks measure is answerable without any video. Visual Gain is positive across all models, which confirms that the visual signal contributes, but that contr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.