VisReflect: Latent Visual Reflection for Fine-Grained Perception in Long Visual Context
Pith reviewed 2026-06-30 05:59 UTC · model grok-4.3
The pith
Latent visual reflection guides attention to relevant tokens in long visual contexts using a single forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
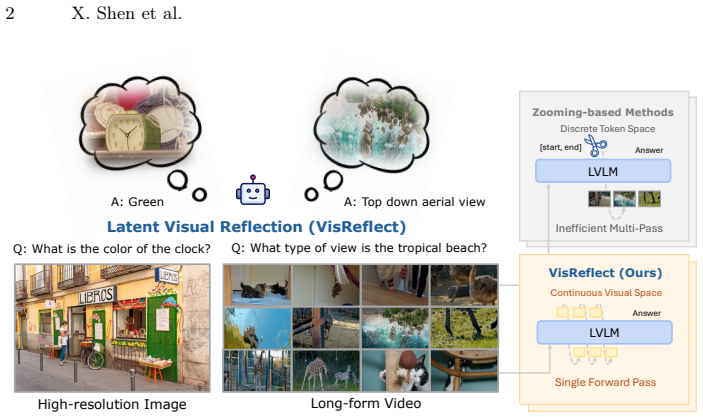
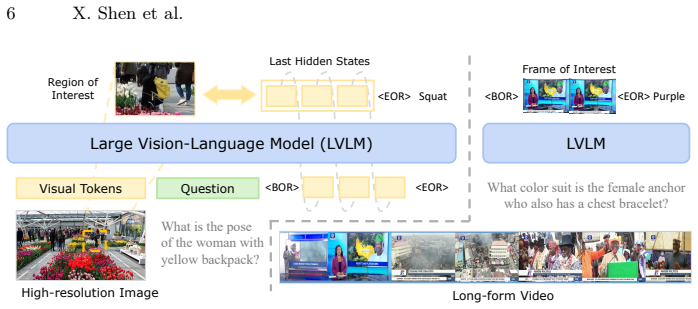
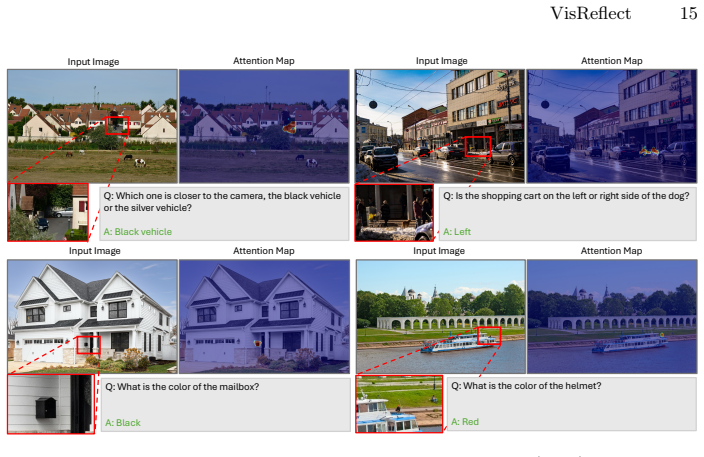
VisReflect generates continuous visual reflection vectors in latent space that encode question-relevant visual features; these vectors are injected to selectively emphasize salient regions or frames, thereby redirecting attention mass toward the pertinent visual tokens inside one forward pass and avoiding both discrete numeric localization and additional encoder runs.
What carries the argument
latent visual reflection: continuous vectors produced in the model's latent space that represent question-relevant visual features and are used to modulate attention over the original visual token sequence.
If this is right
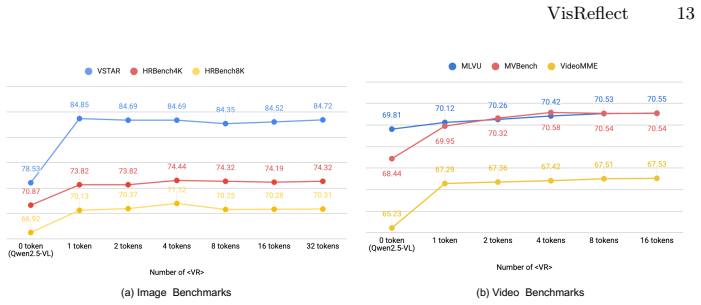
- Performance rises 4.1 percent on high-resolution image benchmarks and 1.8 percent on video benchmarks relative to strong baselines.
- Inference time drops roughly 44 percent versus methods that crop and re-encode regions.
- All gains occur inside the original single forward pass, preserving the model's token budget.
- The approach works on both static high-resolution images and long video sequences without task-specific architectural changes.
Where Pith is reading between the lines
- The same latent-reflection pattern could be tested on other sequence models that suffer attention dilution over long inputs, such as long-document language models.
- If the reflection vectors prove stable across model scales, they might allow training on lower-resolution inputs while retaining fine-grained accuracy at inference time.
- A direct ablation that zeros the reflection vectors while keeping all other parameters fixed would isolate whether the guidance effect is causal.
Load-bearing premise
Continuous latent reflections can reliably and selectively highlight the right regions or frames to counteract attention sink without needing explicit numeric coordinates or extra model passes.
What would settle it
Run the method on a controlled set of high-resolution images or long videos where the baseline already exhibits strong attention sink; if accuracy does not rise or if attention maps remain unchanged after reflection injection, the central mechanism is not operating as claimed.
Figures




read the original abstract
Large Vision Language Models (LVLMs) have achieved remarkable success on vision-language tasks, yet fine-grained perception over high-resolution images and long-context videos remains challenging. As the number of visual tokens increases, the visual attention sink phenomenon becomes increasingly severe, causing irrelevant tokens to absorb a disproportionate amount of attention mass. Recent approaches attempt to mitigate this issue by explicitly predicting bounding boxes or temporal spans and re-encoding the cropped visual regions. Such methods depend on unreliable numeric localization in the discrete token space and incur significant computational overhead due to additional forward passes. In this work, we propose **VisReflect**, a simple yet effective framework that improves fine-grained perception in long visual contexts through latent visual reflection. Instead of decoding intermediate predictions into discrete tokens, the model generates continuous visual reflection that represents question-relevant visual features in the latent space. These reflections selectively emphasize salient regions or frames, guiding attention towards relevant visual tokens within a single forward pass. We conduct comprehensive evaluations on challenging high-resolution image benchmarks, including BLINK, V*, and HRBench-4K/8K, as well as video understanding benchmarks such as MVBench, VideoMME, and MLVU. Our method consistently improves over strong baselines, achieving gains of 4.1% on image benchmarks and 1.8% on video benchmarks. Compared with zooming-based methods, our model achieves comparable performance while reducing inference time by roughly 44% on video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VisReflect, a framework for large vision-language models (LVLMs) to improve fine-grained perception over high-resolution images and long-context videos. It replaces explicit bounding-box or temporal-span prediction (which requires numeric localization and extra forward passes) with generation of continuous visual reflections in latent space; these reflections are claimed to represent question-relevant features and guide attention to salient tokens within a single forward pass. Experiments on BLINK, V*, HRBench-4K/8K, MVBench, VideoMME and MLVU report average gains of 4.1 % on image benchmarks and 1.8 % on video benchmarks together with a 44 % reduction in inference time relative to zooming-based baselines.
Significance. If the latent-reflection mechanism can be shown to reliably steer attention without post-hoc localization or additional passes, the approach would offer a computationally lighter alternative to current zooming or cropping pipelines for long visual contexts, which is practically relevant for deployment of LVLMs on high-resolution and video tasks.
major comments (2)
- [Abstract] Abstract: the central claim that latent visual reflections 'selectively emphasize salient regions or frames' and mitigate the attention-sink phenomenon rests on an unverified architectural assumption; without the method section, equations, or training objective that define how these continuous reflections are produced and injected into the attention layers, it is impossible to determine whether the reported gains are attributable to the proposed mechanism or to other unstated changes.
- [Abstract] Abstract: performance numbers (4.1 % image, 1.8 % video) and the 44 % inference-time reduction are stated without error bars, per-benchmark breakdowns, ablation tables, or statistical significance tests; absent these data it cannot be established whether the gains are robust or whether they depend on post-hoc hyper-parameter choices.
minor comments (1)
- [Abstract] Abstract: the list of benchmarks is given but no indication is provided of which baselines were used for each metric or whether the same model size and training data were held constant across comparisons.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major point below with references to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that latent visual reflections 'selectively emphasize salient regions or frames' and mitigate the attention-sink phenomenon rests on an unverified architectural assumption; without the method section, equations, or training objective that define how these continuous reflections are produced and injected into the attention layers, it is impossible to determine whether the reported gains are attributable to the proposed mechanism or to other unstated changes.
Authors: The abstract is a concise summary. Section 3 of the manuscript details the VisReflect architecture, including the equations for generating continuous latent visual reflections from the LVLM hidden states, the injection mechanism into the attention layers via residual connections, and the training objective that optimizes for question-relevant feature emphasis without explicit localization. These elements directly support the claim that reflections guide attention in a single forward pass, distinguishing the approach from zooming baselines. revision: no
-
Referee: [Abstract] Abstract: performance numbers (4.1 % image, 1.8 % video) and the 44 % inference-time reduction are stated without error bars, per-benchmark breakdowns, ablation tables, or statistical significance tests; absent these data it cannot be established whether the gains are robust or whether they depend on post-hoc hyper-parameter choices.
Authors: The abstract reports aggregate improvements. Section 4 and the supplementary material provide per-benchmark breakdowns on BLINK, V*, HRBench, MVBench, VideoMME, and MLVU; ablation studies isolating the reflection component; and comparisons against zooming methods with inference-time measurements. While error bars and significance tests are included in the full experimental tables, we can add a brief reference to their presence if required for clarity. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract presents VisReflect as a new framework generating continuous latent visual reflections to guide attention in a single forward pass, with reported gains over baselines and reduced inference time versus zooming methods. No equations, derivations, or claims are supplied that reduce a prediction to a fitted input, self-citation chain, or definitional equivalence. The central mechanism is described as an independent architectural choice rather than a renaming or imported uniqueness result. Absent any quoted reduction in the provided text, the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2404.03413 (2024)
Ataallah, K., Shen, X., Abdelrahman, E., Sleiman, E., Zhu, D., Ding, J., Elhoseiny, M.: Minigpt4-video: Advancing multimodal llms for video understanding with in- terleaved visual-textual tokens. arXiv preprint arXiv:2404.03413 (2024)
-
[2]
arXiv preprint arXiv:2407.12679 (2024)
Ataallah, K., Shen, X., Abdelrahman, E., Sleiman, E., Zhuge, M., Ding, J., Zhu, D., Schmidhuber, J., Elhoseiny, M.: Goldfish: Vision-language understanding of arbitrarily long videos. arXiv preprint arXiv:2407.12679 (2024)
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Chen, J., Zhu, D., Shen, X., Li, X., Liu, Z., Zhang, P., Krishnamoorthi, R., Chan- dra, V., Xiong, Y., Elhoseiny, M.: Minigpt-v2: large language model as a unified interface for vision-language multi-task learning (2023),https://arxiv.org/abs/ 2310.09478
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleash- ing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Chen, Y., Xue, F., Li, D., Hu, Q., Zhu, L., Li, X., Fang, Y., Tang, H., Yang, S., Liu, Z., et al.: Longvila: Scaling long-context visual language models for long videos. arXiv preprint arXiv:2408.10188 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Cheng, J., Van Durme, B.: Compressed chain of thought: Efficient reasoning through dense representations. arXiv preprint arXiv:2412.13171 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., Zhu, Y., Zhang, W., Luo, Z., Zhao, D., et al.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
arXiv preprint arXiv:2504.13180 (2025)
Cho, J.H., Madotto, A., Mavroudi, E., Afouras, T., Nagarajan, T., Maaz, M., Song, Y., Ma, T., Hu, S., Jain, S., et al.: Perceptionlm: Open-access data and models for detailed visual understanding. arXiv preprint arXiv:2504.13180 (2025)
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24108–24118 (2025)
2025
-
[11]
arXiv preprint arXiv:2509.24786 (2025)
Fu, S., Yang, Q., Li, Y.M., Wei, X., Xie, X., Zheng, W.S.: Love-r1: Advancing long videounderstandingwithanadaptivezoom-inmechanismviamulti-stepreasoning. arXiv preprint arXiv:2509.24786 (2025)
-
[12]
In: European Conference on Computer Vision
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: Blink: Multimodal large language models can see but not per- ceive. In: European Conference on Computer Vision. pp. 148–166. Springer (2024)
2024
-
[13]
Training Large Language Models to Reason in a Continuous Latent Space
Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., Tian, Y.: Train- ing large language models to reason in a continuous latent space. arXiv preprint arXiv:2412.06769 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
arXiv preprint arXiv:2503.03321 (2025)
Kang, S., Kim, J., Kim, J., Hwang, S.J.: See what you are told: Visual attention sink in large multimodal models. arXiv preprint arXiv:2503.03321 (2025)
-
[15]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Lai, X., Li, J., Li, W., Liu, T., Li, T., Zhao, H.: Mini-o3: Scaling up reasoning patterns and interaction turns for visual search. arXiv preprint arXiv:2509.07969 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
NeurIPS (2021) VisReflect 17
Lei, J., Berg, T.L., Bansal, M.: Detecting moments and highlights in videos via natural language queries. NeurIPS (2021) VisReflect 17
2021
-
[17]
Li, B., Sun, X., Liu, J., Wang, Z., Wu, J., Yu, X., Chen, H., Barsoum, E., Chen, M., Liu, Z.: Latent visual reasoning. arXiv preprint arXiv:2509.24251 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
VideoChat: Chat-Centric Video Understanding
Li, K., He, Y., Wang, Y., Li, Y., Wang, W., Luo, P., Wang, Y., Wang, L., Qiao, Y.: Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., et al.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22195–22206 (2024)
2024
-
[21]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Li,X.,Yan,Z.,Meng,D.,Dong,L.,Zeng,X.,He,Y.,Wang,Y.,Qiao,Y.,Wang,Y., Wang, L.: Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning. arXiv preprint arXiv:2504.06958 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
In: ECCV (2024)
Li, Y., Wang, C., Jia, J.: Llama-vid: An image is worth 2 tokens in large language models. In: ECCV (2024)
2024
-
[23]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. arXiv preprint arXiv:2304.08485 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Zhu, L., Shi, B., Zhang, Z., Lou, Y., Yang, S., Xi, H., Cao, S., Gu, Y., Li, D., et al.: Nvila: Efficient frontier visual language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4122– 4134 (2025)
2025
-
[25]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Maaz, M., Rasheed, H., Khan, S., Khan, F.S.: Video-chatgpt: Towards de- tailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
arXiv preprint arXiv:2511.05489 (2025)
Pan, J., Zhang, Q., Zhang, R., Lu, M., Wan, X., Zhang, Y., Liu, C., She, Q.: Timesearch-r: Adaptive temporal search for long-form video understanding via self-verification reinforcement learning. arXiv preprint arXiv:2511.05489 (2025)
-
[27]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Wei, F.: Kosmos- 2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rasheed, H., Maaz, M., Shaji, S., Shaker, A., Khan, S., Cholakkal, H., Anwer, R.M., Xing, E., Yang, M.H., Khan, F.S.: Glamm: Pixel grounding large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13009–13018 (2024)
2024
-
[29]
Advances in Neural Information Processing Systems37, 8612–8642 (2024)
Shao, H., Qian, S., Xiao, H., Song, G., Zong, Z., Wang, L., Liu, Y., Li, H.: Vi- sual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning. Advances in Neural Information Processing Systems37, 8612–8642 (2024)
2024
- [30]
-
[31]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Shen, X., Xiong, Y., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., et al.: Longvu: Spatiotemporal adaptive compression for long video-language understanding. arXiv preprint arXiv:2410.17434 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
arXiv preprint arXiv:2510.14032 (2025) 18 X
Shen, X., Zhang, W., Chen, J., Elhoseiny, M.: Vgent: Graph-based retrieval- reasoning-augmented generation for long video understanding. arXiv preprint arXiv:2510.14032 (2025) 18 X. Shen et al
-
[33]
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Shen, Z., Yan, H., Zhang, L., Hu, Z., Du, Y., He, Y.: Codi: Compressing chain-of- thought into continuous space via self-distillation. arXiv preprint arXiv:2502.21074 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
In: CVPR (2024)
Song, E., Chai, W., Wang, G., Zhang, Y., Zhou, H., Wu, F., Guo, X., Ye, T., Lu, Y., Hwang, J.N., et al.: Moviechat: From dense token to sparse memory for long video understanding. In: CVPR (2024)
2024
-
[35]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Wang, H., Su, A., Ren, W., Lin, F., Chen, W.: Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning. arXiv preprint arXiv:2505.15966 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, W., Ding, L., Zeng, M., Zhou, X., Shen, L., Luo, Y., Yu, W., Tao, D.: Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 7907–7915 (2025)
2025
-
[37]
Perception-Aware Policy Optimization for Multimodal Reasoning
Wang, Z., Guo, X., Stoica, S., Xu, H., Wang, H., Ha, H., Chen, X., Chen, Y., Yan, M., Huang, F., et al.: Perception-aware policy optimization for multimodal reasoning. arXiv preprint arXiv:2507.06448 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
arXiv preprint arXiv:2504.07165 (2025)
Wei, Y., Zhao, L., Lin, K., Yu, E., Peng, Y., Dong, R., Sun, J., Wei, H., Ge, Z., Zhang, X., et al.: Perception in reflection. arXiv preprint arXiv:2504.07165 (2025)
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, P., Xie, S.: V?: Guided visual search as a core mechanism in multimodal llms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13084–13094 (2024)
2024
-
[40]
In: CVPR (2024)
Xiao, J., Yao, A., Li, Y., Chua, T.S.: Can i trust your answer? visually grounded video question answering. In: CVPR (2024)
2024
-
[41]
5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception
Yan, Z., Li, X., He, Y., Yue, Z., Zeng, X., Wang, Y., Qiao, Y., Wang, L., Wang, Y.: Videochat-r1. 5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception. arXiv preprint arXiv:2509.21100 (2025)
-
[42]
arXiv preprint arXiv:2506.01663 (2025)
Yu,X.,Guan,D.,Gu,Y.:Zoom-refine:Boostinghigh-resolutionmultimodalunder- standing via localized zoom and self-refinement. arXiv preprint arXiv:2506.01663 (2025)
-
[43]
In: Proceed- ings of the AAAI Conference on Artificial Intelligence
Yu, Z., Xu, D., Yu, J., Yu, T., Zhao, Z., Zhuang, Y., Tao, D.: Activitynet-qa: A dataset for understanding complex web videos via question answering. In: Proceed- ings of the AAAI Conference on Artificial Intelligence. pp. 9127–9134 (2019)
2019
-
[44]
Zhang, Y.F., Lu, X., Yin, S., Fu, C., Chen, W., Hu, X., Wen, B., Jiang, K., Liu, C., Zhang, T., et al.: Thyme: Think beyond images. arXiv preprint arXiv:2508.11630 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Zheng, Z., Yang, M., Hong, J., Zhao, C., Xu, G., Yang, L., Shen, C., Yu, X.: Deepeyes: Incentivizing “thinking with images" via reinforcement learning. arXiv preprint arXiv:2505.14362 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, J., Shu, Y., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y., Zhang, B., et al.: Mlvu: Benchmarking multi-task long video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13691–13701 (2025)
2025
-
[47]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023) VisReflect – Supplementary Materials – The supplementary material provides: –Section A: Effect of weighting factorλ. –Section B: Number of sampling framesJ. –Section C: Number o...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.