The Decomposition Is the Fingerprint: Per-Component Identity for Agent Skills
Pith reviewed 2026-07-01 05:42 UTC · model grok-4.3
The pith
A per-component triple fingerprint on prompt, code and tools recovers skill-family identity across paraphrase and refactoring when one component stays shared, but not for independent reimplementation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
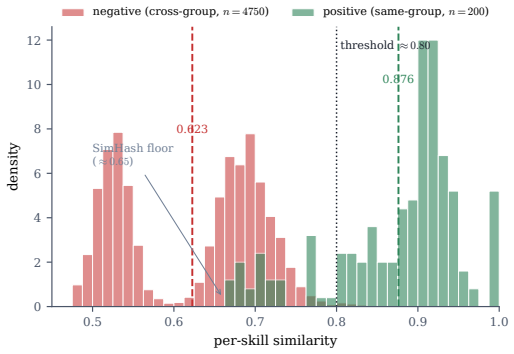
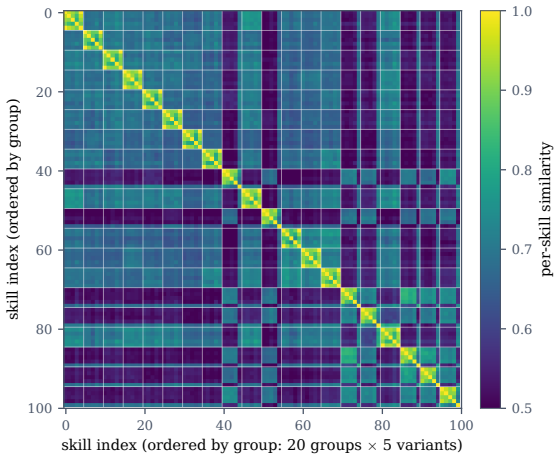
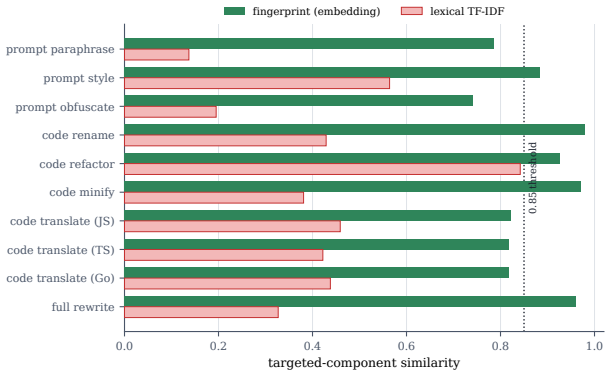
The central claim is that keeping the fingerprint as a per-component triple (prompt, code, tools) rather than a single score recovers skill-family identity through paraphrase, renaming, refactoring and controlled code translation when another component remains shared, while independent multilingual reimplementation is not recovered; the triple also localizes which component carries the reuse and supplies lineage without asserting behavioral equivalence.
What carries the argument
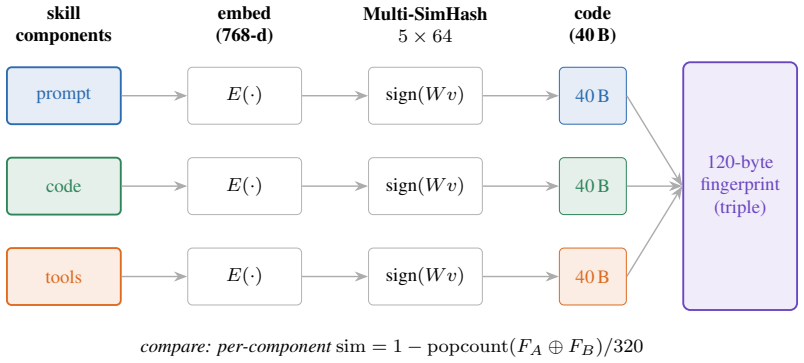
per-component triple fingerprint produced by embedding each of prompt, code and tools then projecting with multi-bank SimHash to bits, compared by Hamming distance
If this is right
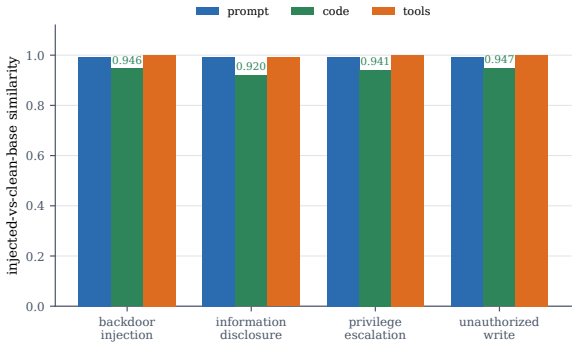
- The fingerprint localizes which component was altered in an injected skill copy.
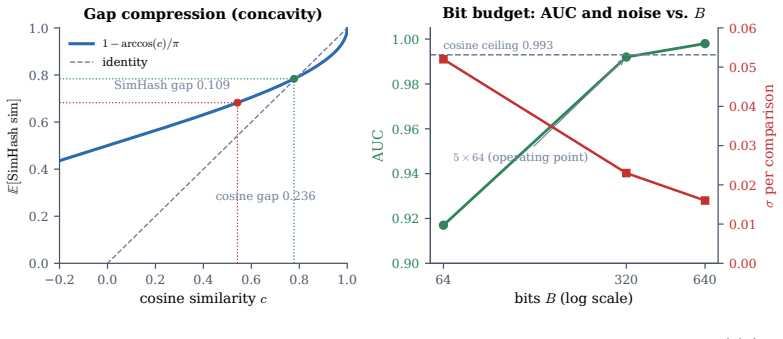
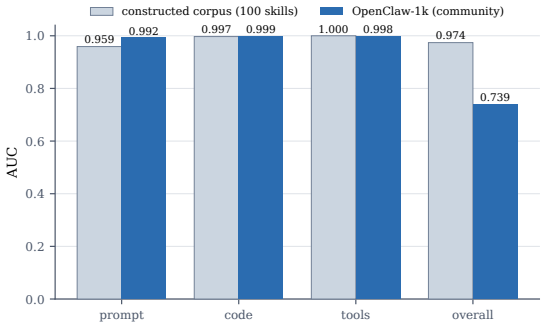
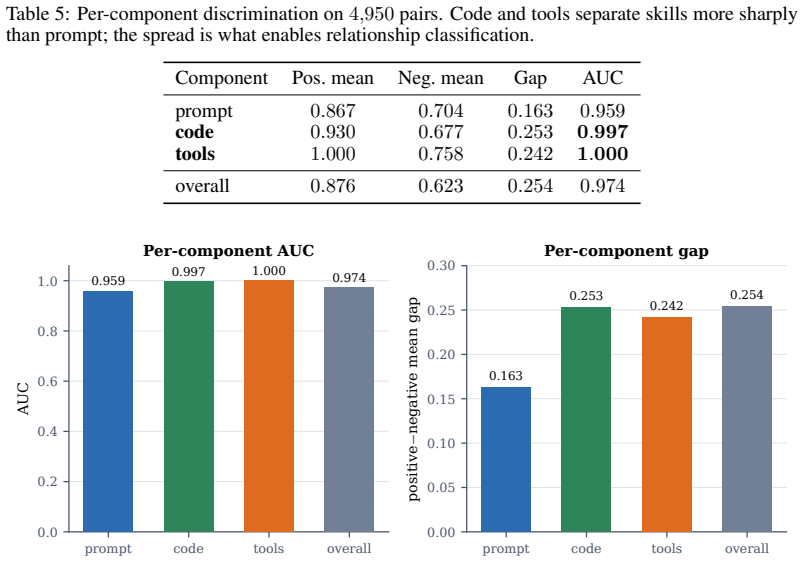
- It reaches an AUC of 0.974 on 4,950 comparisons while using 77 times fewer bits than the embedding it approximates.
- Ranking by Hamming distance is preserved in expectation with finite-bit concentration.
- The per-component split converts one numeric score into explicit family, novelty and change-location labels for a registry.
- It supplies a portable SkillBOM record that can be stored or transmitted without the original skill artifacts.
Where Pith is reading between the lines
- Marketplaces could use the triple to track provenance of skills across agents without performing full behavioral tests on every upload.
- The constant-time Hamming comparison makes the method practical for real-time deduplication in large skill libraries.
- Because identity is kept separate from safety, downstream verification layers remain necessary even when the fingerprint matches.
- The same decomposition might be applied to other composite artifacts such as multi-file code projects or prompt-plus-data bundles.
Load-bearing premise
The 4,950 pairwise comparisons accurately represent the distribution of real-world skill modifications and the SimHash parameters were not tuned on the same data used for the reported AUC.
What would settle it
A set of independent multilingual reimplementations of the same skill that produce Hamming distances below the family threshold, or a set of paraphrased skills sharing one component that produce distances above the threshold.
Figures
read the original abstract
AI agents increasingly acquire and execute skills at runtime: bundles of prompt instructions, executable code, and tool declarations fetched from marketplaces and other agents. Governing them needs a stable notion of skill identity, yet cryptographic hashing is engineered to destroy the very similarity we need, as a one-character edit scrambles the digest. We present a compact, locality-sensitive fingerprint that embeds each component of a skill and projects it to bits with a multi-bank SimHash, giving a fixed 120-byte signature compared in constant time by Hamming distance. Our central claim is that keeping the fingerprint as a per-component triple (prompt, code, tools), rather than a single score, is what makes it useful: the triple recovers skill-family identity through paraphrase, renaming, refactoring, and controlled code translation when another component remains shared, while independent multilingual reimplementation is not recovered; it also localizes which component carries the reuse. We claim lineage, not behavioral equivalence: identity supplies the structural axis of a registry and leaves safety to behavioral verification. The fingerprint reaches an area under the ROC curve (AUC) of 0.974 (95% CI [0.956, 0.994]) over 4,950 pairwise comparisons while using 77x fewer bits than the embedding it approximates, with ranking preserved in expectation and finite-bit concentration; the per-component split turns one number into relationship classification, families, novelty, and a portable "SkillBOM" for a skill registry. On a 906-skill injection benchmark the fingerprint recognizes injected skills as tampered copies of a known base and localizes the change, but recognition is not trust: it remains, by design, an identity signal complementary to behavioral verification rather than a safety verdict.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a per-component locality-sensitive fingerprint for AI agent skills using multi-bank SimHash on triples of (prompt, code, tools) to produce a compact 120-byte signature. The central claim is that representing the fingerprint as a per-component triple (rather than a scalar) recovers skill-family identity under paraphrase, renaming, refactoring, and controlled code translation when another component remains shared, while independent multilingual reimplementation is not recovered; the triple also localizes which component changed. This is evidenced by an AUC of 0.974 (95% CI [0.956, 0.994]) over 4,950 pairwise comparisons, a 77x bit reduction relative to the approximated embedding, preservation of ranking in expectation, and results on a 906-skill injection benchmark showing recognition of tampered copies with change localization. The work positions the fingerprint as a structural identity signal for registries, complementary to (not a replacement for) behavioral verification.
Significance. If the empirical results hold on benchmarks constructed independently of parameter selection, the per-component decomposition supplies a practical, constant-time mechanism for lineage tracking and reuse detection in agent skill marketplaces. Explicit strengths include the reported confidence interval on the AUC, the 77x bit reduction with theoretical guarantees on ranking preservation and finite-bit concentration, and the clear framing that identity is distinct from safety or behavioral equivalence.
major comments (2)
- [Section reporting the 4,950 pairwise comparisons and AUC] The section reporting the 4,950 pairwise comparisons and AUC provides no description of benchmark construction (how pairs were generated, whether synthetic or sampled from observed reuse, selection criteria, or exclusions), nor of how the free parameters (number of SimHash banks and total bit length) were chosen. This is load-bearing for the central claim, as the AUC is the primary quantitative support for the assertion that the triple recovers identity under the listed modifications but not independent reimplementation; without evidence against post-hoc tuning or data leakage, the result risks being fitted rather than generalizable.
- [Section on the 906-skill injection benchmark] The section on the 906-skill injection benchmark provides insufficient detail on skill selection and injection methodology to assess whether the localization result depends on the specific construction or generalizes to the claimed modifications.
minor comments (1)
- [Abstract] The abstract states that ranking is 'preserved in expectation' but does not cite the supporting derivation or theorem number.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in benchmark construction. Both major comments correctly identify areas where the manuscript lacks sufficient methodological detail. We agree these details are necessary to support claims of generalizability and will incorporate them in the revision. We respond to each comment below.
read point-by-point responses
-
Referee: [Section reporting the 4,950 pairwise comparisons and AUC] The section reporting the 4,950 pairwise comparisons and AUC provides no description of benchmark construction (how pairs were generated, whether synthetic or sampled from observed reuse, selection criteria, or exclusions), nor of how the free parameters (number of SimHash banks and total bit length) were chosen. This is load-bearing for the central claim, as the AUC is the primary quantitative support for the assertion that the triple recovers identity under the listed modifications but not independent reimplementation; without evidence against post-hoc tuning or data leakage, the result risks being fitted rather than generalizable.
Authors: We acknowledge that the manuscript does not currently describe how the 4,950 pairs were constructed or how the SimHash parameters were selected. In the revised version we will add a new subsection that specifies: the procedure for generating positive pairs (paraphrase, renaming, refactoring, controlled translation with shared components) and negative pairs (independent reimplementations); whether pairs were synthetically generated or drawn from observed marketplace reuse; explicit selection criteria and any exclusions; and the method used to choose the number of banks and total bit length, including any sensitivity analysis performed. This addition will directly address concerns about post-hoc tuning and data leakage. revision: yes
-
Referee: [Section on the 906-skill injection benchmark] The section on the 906-skill injection benchmark provides insufficient detail on skill selection and injection methodology to assess whether the localization result depends on the specific construction or generalizes to the claimed modifications.
Authors: We agree that the current description of the 906-skill injection benchmark is insufficient. In the revision we will expand this section to detail: the source and selection criteria for the 906 skills; the precise injection methodology (how tampered copies were created while preserving one or more components); and any controls used to ensure the modifications match the paraphrase/refactoring cases evaluated in the pairwise experiment. These additions will allow readers to evaluate whether the localization results generalize beyond the specific benchmark construction. revision: yes
Circularity Check
No significant circularity; performance reported on described benchmarks without reduction to fitted inputs by construction
full rationale
The manuscript reports an AUC of 0.974 on 4,950 pairwise comparisons and results on a 906-skill injection benchmark as empirical support for the per-component triple's ability to recover skill-family identity under specific modifications. No equations, self-citations, or descriptions in the provided text reduce this metric to a parameter fitted on the same data and then relabeled as a prediction. The central claim rests on the design of the multi-bank SimHash projection and the per-component split rather than on a self-referential loop. The benchmarks are presented as external test sets, and no ansatz, uniqueness theorem, or renaming of known results is invoked in a load-bearing way. The derivation chain is therefore self-contained against the stated external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of SimHash banks and total bit length
axioms (1)
- domain assumption SimHash preserves locality for the text distributions present in prompts, code, and tool declarations
Reference graph
Works this paper leans on
-
[1]
Model context protocol.https://modelcontextprotocol.io/, 2024
Anthropic. Model context protocol.https://modelcontextprotocol.io/, 2024. Ac- cessed 2026
2024
-
[2]
Agent skills.https://platform.claude.com/docs/en/ agents-and-tools/agent-skills/overview, 2025
Anthropic. Agent skills.https://platform.claude.com/docs/en/ agents-and-tools/agent-skills/overview, 2025. Accessed 2026
2025
- [3]
-
[4]
Ricardo J. G. B. Campello, Davoud Moulavi, and Jörg Sander. Density-based clustering based on hierarchical density estimates. InAdvances in Knowledge Discovery and Data Mining (PAKDD), pages 160–172, 2013. doi: 10.1007/978-3-642-37456-2_14
-
[5]
Moses S. Charikar. Similarity estimation techniques from rounding algorithms. InProceedings of the 34th Annual ACM Symposium on Theory of Computing (STOC), pages 380–388, 2002. doi: 10.1145/509907.509965
-
[6]
Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S. Mirrokni. Locality-sensitive hash- ing scheme based on p-stable distributions. InProceedings of the 20th Annual Symposium on Computational Geometry (SoCG), pages 253–262, 2004. doi: 10.1145/997817.997857
-
[7]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi ´c, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. AgentDojo: A dynamic environment to evaluate attacks and defenses for LLM agents. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024. arXiv:2406.13352. 19
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. CodeBERT: A pre-trained model for programming and natural languages. InFindings of EMNLP, 2020. arXiv:2002.08155
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wal- lach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021. arXiv:1803.09010
-
[10]
Similarity search in high dimensions via hashing
Aristides Gionis, Piotr Indyk, and Rajeev Motwani. Similarity search in high dimensions via hashing. InProceedings of the 25th International Conference on Very Large Data Bases (VLDB), pages 518–529, 1999
1999
-
[11]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. InProceedings of the 16th ACM Workshop on Artificial Intelli- gence and Security (AISec), 2023. arXiv:2302.12173
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
On Calibration of Modern Neural Networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of mod- ern neural networks. InInternational Conference on Machine Learning (ICML), 2017. arXiv:1706.04599
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
GraphCodeBERT: Pre-training Code Representations with Data Flow
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, et al. GraphCodeBERT: Pre-training code represen- tations with data flow. InInternational Conference on Learning Representations (ICLR), 2021. arXiv:2009.08366
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
UniXcoder: Unified Cross-Modal Pre-training for Code Representation
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. UniXcoder: Unified cross-modal pre-training for code representation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022. arXiv:2203.03850
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Accelerating large-scale inference with anisotropic vector quantization
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Ku- mar. Accelerating large-scale inference with anisotropic vector quantization. InInternational Conference on Machine Learning (ICML), 2020. arXiv:1908.10396
-
[16]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. CodeSearchNet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[17]
Approximate nearest neighbors: Towards removing the curse of dimensionality
Piotr Indyk and Rajeev Motwani. Approximate nearest neighbors: Towards removing the curse of dimensionality. InProceedings of the 30th Annual ACM Symposium on Theory of Computing (STOC), pages 604–613, 1998. doi: 10.1145/276698.276876
-
[18]
Product quantization for nearest neighbor search.IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(1):117–128,
Hervé Jégou, Matthijs Douze, and Cordelia Schmid. Product quantization for nearest neighbor search.IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(1):117–128,
-
[19]
doi: 10.1109/TPAMI.2010.57
-
[20]
SkillJect: Effectively Automating Skill-Based Prompt Injection for Skill-Enabled Agents
Xiaojun Jia, Jie Liao, Simeng Qin, Jindong Gu, Wenqi Ren, Xiaochun Cao, Yang Liu, and Philip Torr. SkillJect: Effectively automating skill-based prompt injection for skill-enabled agents.arXiv preprint arXiv:2602.14211, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
DECKARD: Scal- able and accurate tree-based detection of code clones
Lingxiao Jiang, Ghassan Misherghi, Zhendong Su, and Stephane Glondu. DECKARD: Scal- able and accurate tree-based detection of code clones. InProceedings of the 29th International Conference on Software Engineering (ICSE), pages 96–105, 2007. doi: 10.1109/ICSE.2007. 30
-
[22]
Billion-scale similarity search with GPUs
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2019. arXiv:1702.08734
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Johnson and Joram Lindenstrauss
William B. Johnson and Joram Lindenstrauss. Extensions of lipschitz mappings into a hilbert space.Contemporary Mathematics, 26:189–206, 1984. doi: 10.1090/conm/026/737400
-
[24]
Identifying almost identical files using context triggered piecewise hashing
Jesse Kornblum. Identifying almost identical files using context triggered piecewise hashing. Digital Investigation, 3:91–97, 2006. doi: 10.1016/j.diin.2006.06.015. Proceedings of the DFRWS. 20
-
[25]
On the sentence embeddings from pre-trained language models
Bohan Li, Hao Zhou, Junxian He, Mingxuan Wang, Yiming Yang, and Lei Li. On the sentence embeddings from pre-trained language models. InProceedings of EMNLP, 2020. arXiv:2011.05864
-
[26]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li et al. SkillsBench: Benchmarking how well agent skills work across diverse tasks. arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2308.03688
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
"Do Not Mention This to the User": Detecting and Understanding Malicious Agent Skills in the Wild
Yi Liu, Zhihao Chen, Yanjun Zhang, Gelei Deng, Yuekang Li, Jianting Ning, and Leo Yu Zhang. “do not mention this to the user”: Detecting and understanding malicious agent skills in the wild.arXiv preprint arXiv:2602.06547, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Detecting near-duplicates for web crawling
Gurmeet Singh Manku, Arvind Jain, and Anish Das Sarma. Detecting near-duplicates for web crawling. InProceedings of the 16th International Conference on World Wide Web (WWW), pages 141–150, 2007. doi: 10.1145/1242572.1242592
-
[30]
hdbscan: Hierarchical density based clustering
Leland McInnes, John Healy, and Steve Astels. hdbscan: Hierarchical density based clustering. Journal of Open Source Software, 2(11):205, 2017. doi: 10.21105/joss.00205
-
[31]
Model Cards for Model Reporting
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. InProceedings of the Conference on Fairness, Accountability, and Transparency (FAT*), pages 220–229, 2019. arXiv:1810.03993
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
MTEB: Massive Text Embedding Benchmark
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. MTEB: Massive text embedding benchmark.arXiv preprint arXiv:2210.07316, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Scalable fingerprinting of large language models.arXiv preprint arXiv:2502.07760, 2025
Anshul Nasery, Jonathan Hayase, Creston Brooks, Peiyao Sheng, Himanshu Tyagi, Pramod Viswanath, and Sewoong Oh. Scalable fingerprinting of large language models.arXiv preprint arXiv:2502.07760, 2025
-
[34]
Sigstore: Software sign- ing for everybody
Zachary Newman, John Speed Meyers, and Santiago Torres-Arias. Sigstore: Software sign- ing for everybody. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2022. doi: 10.1145/3548606.3560596
-
[35]
TLSH – a locality sensitive hash
Jonathan Oliver, Chun Cheng, and Yanggui Chen. TLSH – a locality sensitive hash. InPro- ceedings of the 4th Cybercrime and Trustworthy Computing Workshop (CTC), pages 7–13,
-
[36]
doi: 10.1109/CTC.2013.9
-
[37]
OpenClaw: Personal AI assistant.https://github.com/openclaw/openclaw,
OpenClaw. OpenClaw: Personal AI assistant.https://github.com/openclaw/openclaw,
-
[38]
Community agent-skill registry; accessed 2026
2026
-
[39]
SLSA: Supply-chain levels for software artifacts.https://slsa.dev/, 2023
OpenSSF. SLSA: Supply-chain levels for software artifacts.https://slsa.dev/, 2023. Accessed 2026
2023
-
[40]
CycloneDX bill of materials specification.https://cyclonedx.org/ specification/overview/, 2024
OW ASP Foundation. CycloneDX bill of materials specification.https://cyclonedx.org/ specification/overview/, 2024. Accessed 2026
2024
-
[41]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2307.16789
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of EMNLP-IJCNLP, 2019. arXiv:1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[44]
Chanchal K. Roy, James R. Cordy, and Rainer Koschke. Comparison and evaluation of code clone detection techniques and tools: A qualitative approach.Science of Computer Program- ming, 74(7):470–495, 2009. doi: 10.1016/j.scico.2009.02.007. 21
-
[45]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox. InInternational Conference on Learning Representations (ICLR),
-
[46]
SourcererCC: Scaling Code Clone Detection to Big Code
Hitesh Sajnani, Vaibhav Saini, Jeffrey Svajlenko, Chanchal K. Roy, and Cristina V . Lopes. SourcererCC: Scaling code clone detection to big code. InProceedings of the 38th International Conference on Software Engineering (ICSE), pages 1157–1168, 2016. arXiv:1512.06448
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[48]
Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks
D. Schmotz, L. Beurer-Kellner, S. Abdelnabi, and M. Andriushchenko. Skill-inject: Measuring agent vulnerability to skill file attacks.arXiv preprint arXiv:2602.20156, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.arXiv preprint arXiv:2308.11432, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Large Language Models are not Fair Evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators.arXiv preprint arXiv:2305.17926, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Behavioral Integrity Verification for AI Agent Skills
Yuhao Wu, Tung-Ling Li, and Hongliang Liu. Behavioral integrity verification for ai agent skills.arXiv preprint arXiv:2605.11770, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
A fingerprint for large language models.arXiv preprint arXiv:2407.01235, 2024
Zhiguang Yang and Hanzhou Wu. A fingerprint for large language models.arXiv preprint arXiv:2407.01235, 2024
-
[54]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Confer- ence on Learning Representations (ICLR), 2023. arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent: Benchmarking in- direct prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics (ACL), 2024. arXiv:2403.02691
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, et al. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023. arXiv:2306.05685. A Bit budget and concentration The bit-budg...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.