MoHallBench: A Benchmark for Motion Hallucination in Video Large Language Models
Pith reviewed 2026-07-02 13:42 UTC · model grok-4.3
The pith
VideoLLMs hallucinate absent human motions most often when over-inferring from partial sequences, despite recognizing present actions well.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
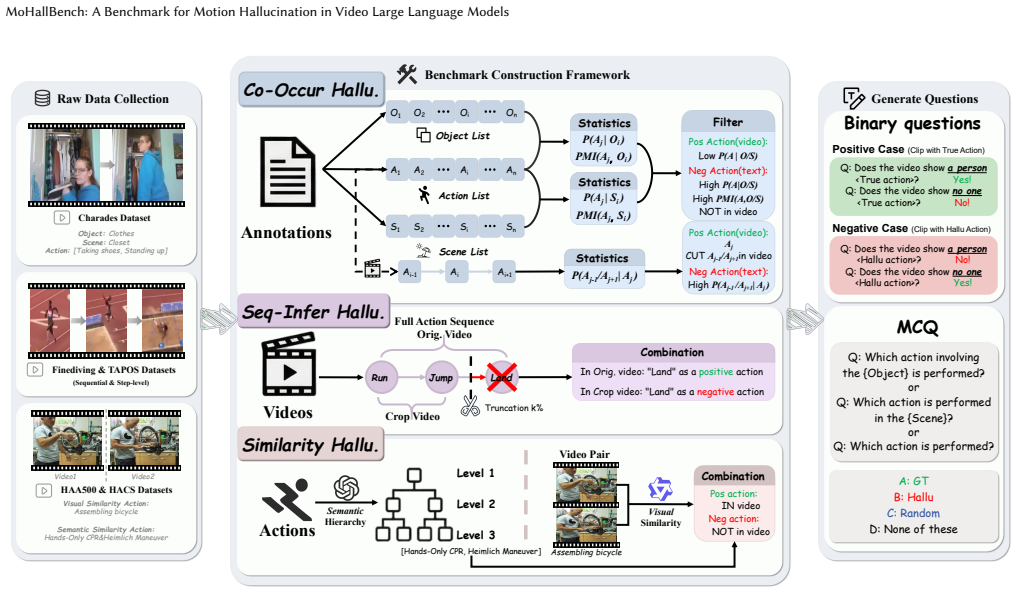
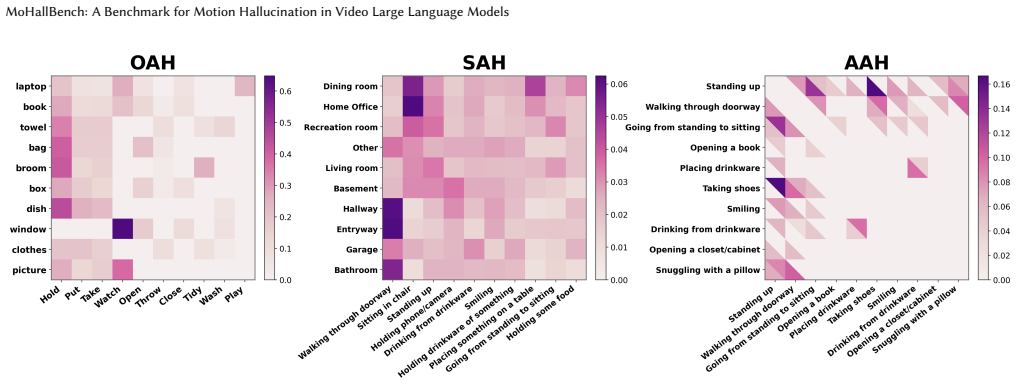
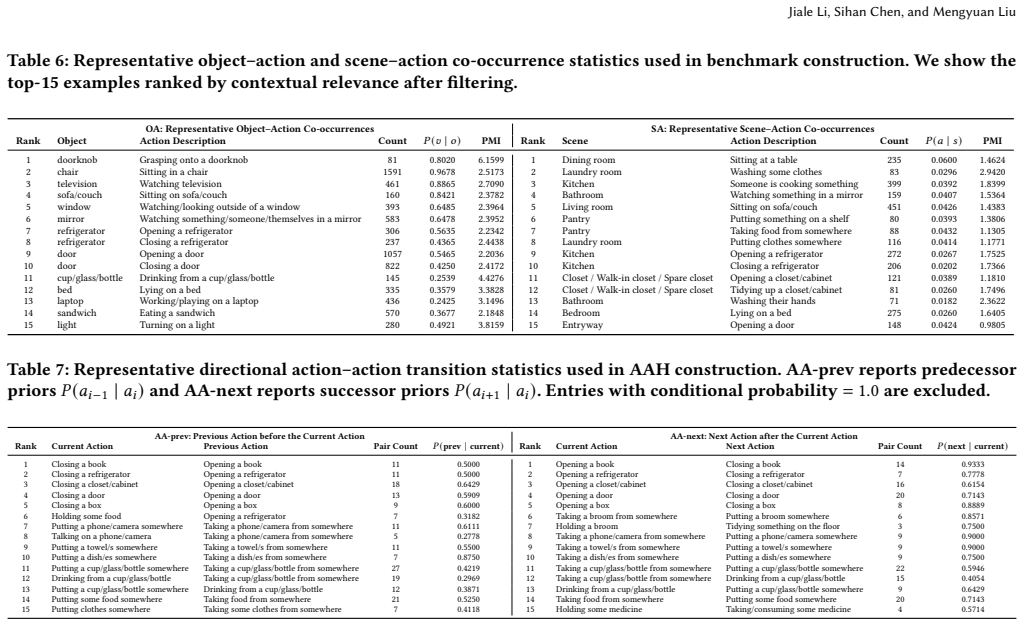
MoHallBench demonstrates that motion hallucination in VideoLLMs is driven by three distinct sources and shows a clear decoupling from standard action recognition accuracy, with sequential inference hallucination proving most severe as models over-infer expected motion outcomes from incomplete visual cues.
What carries the argument
MoHallBench benchmark with its bi-directional questioning protocol that evaluates co-occurrence priors, sequential inference, and similarity confusion while controlling for affirmation bias.
If this is right
- Models excelling at positive action recognition still produce high hallucination rates on adversarial negatives.
- Sequential inference causes the highest hallucination rates because models extrapolate expected future motions from partial cues.
- Stronger co-occurrence priors and finer-grained action similarity both increase hallucination frequency across settings.
Where Pith is reading between the lines
- Training objectives that penalize over-inference from partial motion sequences could reduce the dominant failure mode.
- The benchmark design could be adapted to test whether similar decoupling appears in object or event hallucination tasks.
- Mitigation methods might prioritize explicit checks against co-occurrence statistics during generation.
Load-bearing premise
The questions and protocol isolate the three hallucination sources without introducing new biases that would alter the observed decoupling between recognition and resistance.
What would settle it
A follow-up test on the same ten models using new video clips and questions that reverses the reported ranking of hallucination severity or eliminates the recognition-hallucination decoupling.
Figures




read the original abstract
Video Large Language Models (VideoLLMs) have shown strong progress in video understanding, yet they still suffer from hallucinations that are inconsistent with visual evidence. Existing benchmarks mainly focus on object hallucination or coarse action perception, leaving a key video-specific problem underexplored: motion hallucination, in which models infer human motions that are absent from the video. We present MoHallBench, a benchmark for diagnosing motion hallucination in VideoLLMs. MoHallBench systematically evaluates three major sources of hallucination: co-occurrence priors, sequential inference, and similarity confusion. It contains 11,306 video clips and 40,493 question-answer pairs, covering binary-choice, multiple-choice, and generative settings. We further introduce a bi-directional questioning protocol with bias-aware metrics to reduce affirmation bias in binary evaluation. Experiments on ten recent open-source VideoLLMs reveal a clear decoupling between action recognition and hallucination resistance, as models that perform well on positive action recognition often fail on adversarial negatives. Among all settings, sequential inference hallucination is the most severe, showing that current models tend to over-infer expected outcomes from partial motion cues. Our analyses further confirm that stronger priors and finer-grained similarity substantially amplify hallucination. We hope MoHallBench can facilitate future evaluation and mitigation of motion hallucination in VideoLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MoHallBench, a benchmark with 11,306 video clips and 40,493 QA pairs to diagnose motion hallucination in VideoLLMs across three sources (co-occurrence priors, sequential inference, similarity confusion) in binary-choice, multiple-choice, and generative settings. It proposes a bi-directional questioning protocol with bias-aware metrics to reduce affirmation bias and reports experiments on ten open-source VideoLLMs showing decoupling between positive action recognition and hallucination resistance on adversarial negatives, with sequential inference hallucination being the most severe.
Significance. If the benchmark design is validated, this addresses an underexplored video-specific hallucination type beyond existing object or coarse-action benchmarks. The dataset scale, coverage of multiple settings, and empirical observation of decoupling plus the dominance of sequential inference represent a useful empirical contribution for guiding VideoLLM evaluation. The paper supplies no indication of released code or data, but the benchmark construction itself is the primary deliverable.
major comments (2)
- [§3 and §4] §3 (Benchmark Construction) and §4 (Bi-directional Protocol): The decoupling result and source-specific severity claims rest on the protocol accurately isolating co-occurrence priors, sequential inference, and similarity confusion. The manuscript supplies no details on video selection criteria, negative-example crafting rules, symmetry of bidirectional pairs, inter-annotator validation of source attribution, or controls for language-only confounds, which is load-bearing for interpreting the pattern as a property of the models rather than an artifact of benchmark design.
- [§5] §5 (Experiments and Results): The reported decoupling between action recognition and hallucination resistance (and the ranking of sequential inference as most severe) lacks ablations or statistical controls for potential post-hoc selection effects or unmeasured biases in the 40,493 QA pairs; without these, the central experimental claim cannot be fully assessed from the provided evidence.
minor comments (2)
- [Abstract] The abstract states the protocol 'reduces affirmation bias' but does not define the bias-aware metrics; a brief definition or reference to the relevant subsection would improve clarity.
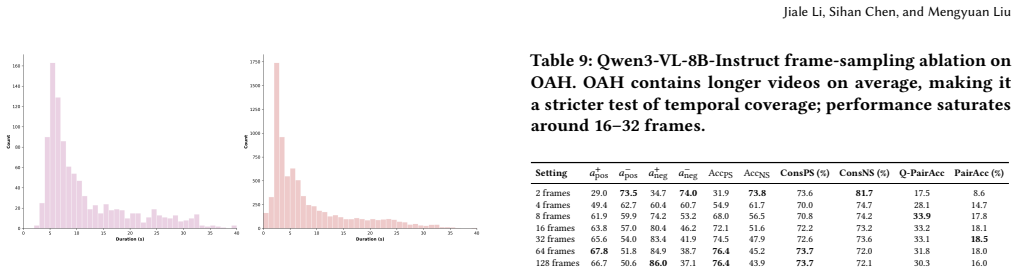
- [§3] Consider adding a table or figure in §3 summarizing the distribution of the 40,493 pairs across the three hallucination sources, settings, and video clip categories for transparency.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments highlight important areas where additional transparency and validation are needed to support the benchmark's claims. We address each point below and commit to revisions that incorporate the requested details and analyses without altering the core contributions.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Benchmark Construction) and §4 (Bi-directional Protocol): The decoupling result and source-specific severity claims rest on the protocol accurately isolating co-occurrence priors, sequential inference, and similarity confusion. The manuscript supplies no details on video selection criteria, negative-example crafting rules, symmetry of bidirectional pairs, inter-annotator validation of source attribution, or controls for language-only confounds, which is load-bearing for interpreting the pattern as a property of the models rather than an artifact of benchmark design.
Authors: We agree that the current manuscript lacks sufficient detail on these aspects of benchmark construction, which are necessary to substantiate that the observed patterns reflect model behavior rather than design artifacts. In the revised version, we will expand §3 and §4 with: explicit criteria for selecting the 11,306 video clips from source datasets; step-by-step rules used to craft negatives for each of the three hallucination sources; verification that bidirectional pairs maintain symmetry in question structure and answer options; inter-annotator agreement metrics (e.g., Cohen's kappa) for source attribution during QA pair creation; and analyses or controls (such as language-only baselines) to address potential confounds. These additions will directly support the validity of the decoupling and severity rankings. revision: yes
-
Referee: [§5] §5 (Experiments and Results): The reported decoupling between action recognition and hallucination resistance (and the ranking of sequential inference as most severe) lacks ablations or statistical controls for potential post-hoc selection effects or unmeasured biases in the 40,493 QA pairs; without these, the central experimental claim cannot be fully assessed from the provided evidence.
Authors: We acknowledge that the experimental section would benefit from explicit ablations and statistical safeguards to rule out selection effects or biases in the QA pairs. In the revision, we will add: (i) ablation studies using random subsampling of the 40,493 pairs and re-computation of decoupling metrics; (ii) statistical tests (e.g., paired t-tests or bootstrap confidence intervals) comparing action-recognition accuracy against hallucination rates on adversarial negatives; and (iii) controls for potential post-hoc biases, such as stratification by video length or source. These will be reported alongside the existing results on the ten VideoLLMs to strengthen the claims regarding source-specific severity. revision: yes
Circularity Check
No circularity: empirical benchmark with external model evaluations
full rationale
This is a benchmark construction paper with no mathematical derivation chain, fitted parameters, or predictions. The central claims consist of empirical measurements on ten external open-source VideoLLMs using a newly constructed dataset of 11,306 clips and 40,493 QA pairs. The bi-directional protocol and bias-aware metrics are described as design choices to mitigate affirmation bias, but they do not reduce any reported result to a quantity defined inside the paper by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results occurs. The observed decoupling between action recognition and hallucination resistance is a direct experimental outcome on independent models, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Co-occurrence priors, sequential inference, and similarity confusion are the three major sources of motion hallucination in VideoLLMs.
invented entities (1)
-
MoHallBench benchmark and bi-directional questioning protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Bar- reira, Oriol Vinyals, Andrew Zisserman, and Karén Simonyan
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L. Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binko...
2022
-
[2]
Lawrence Zitnick, and Devi Parikh
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. 2015. VQA: Visual Question Answering. In2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015. IEEE Computer Society, 2425–2433. doi:10.1109/ICCV. 2015.279
-
[3]
Kyungho Bae, Jinhyung Kim, Sihaeng Lee, Soonyoung Lee, Gunhee Lee, and Jinwoo Choi. 2025. MASH-VLM: Mitigating Action-Scene Hallucination in Video-LLMs through Disentangled Spatial-Temporal Representations. InCVPR. Computer Vision Foundation / IEEE, 13744–13753
2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Ming- Hsuan Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[5]
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of Multimodal Large Language Models: A Survey.CoRRabs/2404.18930 (2024). arXiv:2404.18930 doi:10.48550/ ARXIV.2404.18930
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Jang Hyun Cho, Andrea Madotto, Effrosyni Mavroudi, Triantafyllos Afouras, Tushar Nagarajan, Muhammad Maaz, Yale Song, Tengyu Ma, Shuming Hu, Suyog Dutt Jain, Miguel Martin, Huiyu Wang, Hanoona Abdul Rasheed, Peize Sun, Po-Yao Huang, Daniel Bolya, Nikhila Ravi, Shashank Jain, Tammy Stark, Shane Moon, Babak Damavandi, Vivian Lee, Andrew Westbury, Salman H. ...
-
[7]
Jihoon Chung, Cheng-hsin Wuu, Hsuan-ru Yang, Yu-Wing Tai, and Chi-Keung Tang. 2021. HAA500: Human-Centric Atomic Action Dataset with Curated Videos. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. IEEE, 13445–13454. doi:10.1109/ ICCV48922.2021.01321
-
[8]
Kenneth Ward Church and Patrick Hanks. 1990. Word Association Norms, Mutual Information, and Lexicography.Comput. Linguistics16, 1 (1990), 22–29
1990
-
[9]
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, Vincent Shao, Yue Yang, Weikai Huang, Ziqi Gao, Taira Anderson, Jianrui Zhang, Jitesh Jain, George Stoica, Winson Han, Ali Farhadi, and Ranjay Krishna
-
[10]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding.CoRRabs/2601.10611 (2026). arXiv:2601.10611 doi:10.48550/ARXIV.2601.10611
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.10611 2026
-
[11]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi
-
[12]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine (E...
2023
-
[13]
DeepSeek-AI. 2024. DeepSeek-V3 Technical Report.CoRRabs/2412.19437 (2024). arXiv:2412.19437 doi:10.48550/ARXIV.2412.19437
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2024
-
[14]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh
-
[15]
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 6325–6334. doi:10.1109/CVPR.2017.670
-
[16]
Wenyi Hong, Yean Cheng, Zhuoyi Yang, Weihan Wang, Lefan Wang, Xiaotao Gu, Shiyu Huang, Yuxiao Dong, and Jie Tang. 2025. MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. Computer Visio...
-
[17]
Ming Kong, Xianzhou Zeng, Luyuan Chen, Yadong Li, Bo Yan, and Qiang Zhu
-
[18]
MHBench: Demystifying Motion Hallucination in VideoLLMs. InThirty- Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence, Fifteenth Symposium on Edu- cational Advances in Artificial Intelligence, AAAI 2025, Philadelphia, PA, USA, February 25 - March 4, 2025, Toby Walsh, Julie Shah...
-
[19]
Chaoyu Li, Eun Woo Im, and Pooyan Fazli. 2025. VidHalluc: Evaluating Temporal Hallucinations in Multimodal Large Language Models for Video Understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. Computer Vision Foundation / IEEE, 13723– 13733. doi:10.1109/CVPR52734.2025.01281
-
[20]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. 2023. BLIP- 2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research), Andreas Krause, Emma Brunskill, Kyunghyun C...
2023
-
[21]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Lou, Limin Wang, and Yu Qiao. 2024. MVBench: A Comprehensive Multi-modal Video Understanding Benchmark. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, W A, USA, June 16-22, 2024. IEEE, 22195–22206. doi:10.1109/CVPR52733.2...
-
[22]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Evaluating Object Hallucination in Large Vision-Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computati...
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Vi- sual Instruction Tuning. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Lev...
2023
-
[24]
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. 2024. A Survey on Hallucination in Large Vision-Language Models.CoRRabs/2402.00253 (2024). arXiv:2402.00253 doi:10.48550/ARXIV.2402.00253
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.00253 2024
- [25]
-
[26]
Muhammad Maaz, Hanoona Abdul Rasheed, Salman Khan, and Fahad Khan
-
[27]
InACL (1)
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. InACL (1). Association for Computational Linguistics, 12585–12602
-
[28]
Joanna Materzynska, Tete Xiao, Roei Herzig, Huijuan Xu, Xiaolong Wang, and Trevor Darrell. 2020. Something-Else: Compositional Action Recognition With Spatial-Temporal Interaction Networks. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, W A, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 1046–1056. do...
-
[29]
OpenAI. 2026. GPT-5.4 Thinking System Card. OpenAI. https://openai.com/ index/gpt-5-4-thinking-system-card/ Official system card
2026
-
[30]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object Hallucination in Image Captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, Ellen Riloff, David Chiang, Julia Hock- enmaier, and Jun’ichi Tsujii (Eds.). Associati...
-
[31]
Dian Shao, Yue Zhao, Bo Dai, and Dahua Lin. 2020. Intra- and Inter-Action Understanding via Temporal Action Parsing. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, W A, USA, June 13-19,
2020
-
[32]
Computer Vision Foundation / IEEE, 727–736. doi:10.1109/CVPR42600. 2020.00081
-
[33]
Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta
Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. 2016. Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding. InComputer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part I (Lecture Notes in Computer Science), Bastian Leibe, J...
-
[34]
Qwen Team. 2025. Qwen3-VL Technical Report.CoRRabs/2511.21631 (2025). arXiv:2511.21631 doi:10.48550/ARXIV.2511.21631
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[35]
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Ming Yan, Ji Zhang, and Jitao Sang. 2023. An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation.arXiv preprint arXiv:2311.07397(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.CoRRabs/2409.12191 (2024). arXiv:2...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Yuxuan Wang, Yueqian Wang, Dongyan Zhao, Cihang Xie, and Zilong Zheng
-
[38]
VideoHallucer: Evaluating Intrinsic and Extrinsic Hallucinations in Large Video-Language Models.CoRRabs/2406.16338 (2024). arXiv:2406.16338 doi:10. 48550/ARXIV.2406.16338
-
[39]
Jinglin Xu, Yongming Rao, Xumin Yu, Guangyi Chen, Jie Zhou, and Jiwen Lu
-
[40]
Ego4d: Around the world in 3, 000 hours of egocentric video
FineDiving: A Fine-grained Dataset for Procedure-aware Action Quality Assessment. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 2939–2948. doi:10. 1109/CVPR52688.2022.00296
-
[41]
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, Bokai Xu, Junbo Cui, Yingjing Xu, Liqing Ruan, Luoyuan Zhang, Hanyu Liu, Jingkun Tang, Hongyuan Liu, Qining Guo, Wenhao Hu, Bingxiang He, Jie Zhou, Jie Cai, Ji Qi, Zonghao Guo, Chi Chen, Guoyang Zeng, Yuxuan Li, Ganqu Cui, Ning D...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.18154 2025
-
[42]
Liping Yuan, Jiawei Wang, Haomiao Sun, Yuchen Zhang, and Yuan Lin. 2025. Tarsier2: Advancing Large Vision-Language Models from Detailed Video De- scription to Comprehensive Video Understanding.CoRRabs/2501.07888 (2025). arXiv:2501.07888 doi:10.48550/ARXIV.2501.07888
-
[43]
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, and Deli Zhao. 2025. VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding.CoRRabs/2501.13106 (2025). arXiv:2501.13106 doi:10.48550/ARXIV.2501.13106
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.13106 2025
-
[44]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. InEMNLP (Demos). Association for Computational Linguistics, 543–553
2023
-
[45]
Jiacheng Zhang, Yang Jiao, Shaoxiang Chen, Jingjing Chen, and Yu-Gang Jiang
-
[46]
arXiv:2409.16597 doi:10.48550/ARXIV.2409.16597
EventHallusion: Diagnosing Event Hallucinations in Video LLMs.CoRR abs/2409.16597 (2024). arXiv:2409.16597 doi:10.48550/ARXIV.2409.16597
-
[47]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.CoRRabs/2506.05176 (2025). arXiv:2506.05176 doi:10.48550/ARXIV.2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[48]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. 2025. LLaVA-Video: Video Instruction Tuning With Synthetic Data.Trans. Mach. Learn. Res.2025 (2025). https://openreview.net/forum?id=EElFGvt39K
2025
-
[49]
Hang Zhao, Antonio Torralba, Lorenzo Torresani, and Zhicheng Yan. 2019. HACS: Human Action Clips and Segments Dataset for Recognition and Tempo- ral Localization. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019. IEEE, 8667–8677. doi:10.1109/ICCV.2019.00876
-
[50]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingcheng Zh...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.10479 2025
-
[51]
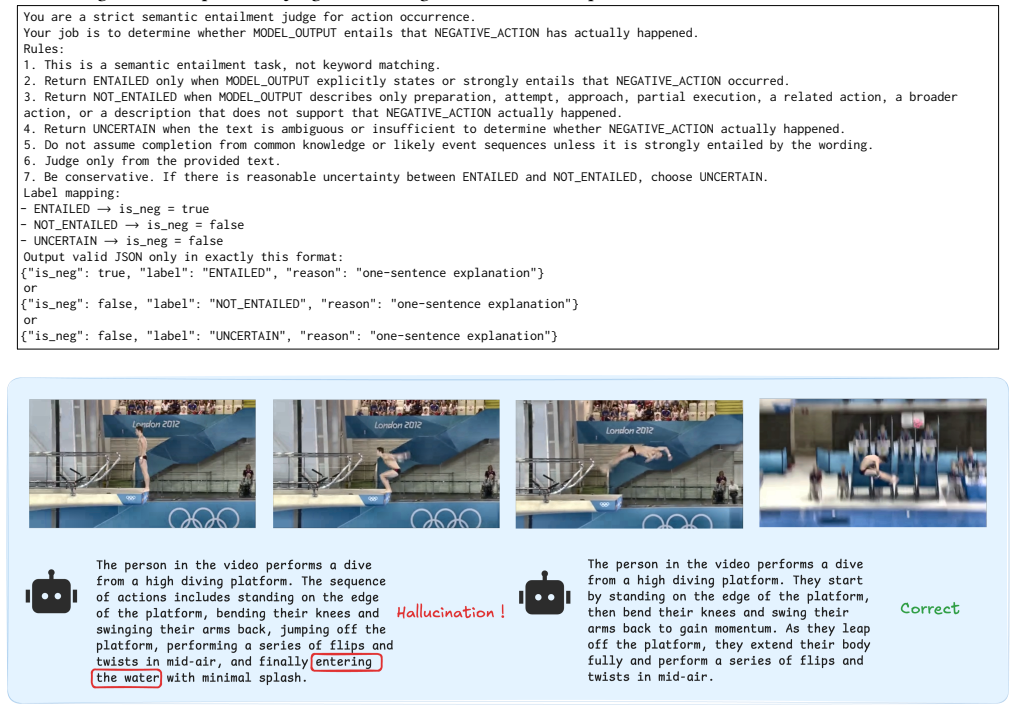
This is a semantic entailment task, not keyword matching
-
[52]
Return ENTAILED only when MODEL_OUTPUT explicitly states or strongly entails that NEGATIVE_ACTION occurred
-
[53]
Return NOT_ENTAILED when MODEL_OUTPUT describes only preparation, attempt, approach, partial execution, a related action, a broader action, or a description that does not support that NEGATIVE_ACTION actually happened
-
[54]
Return UNCERTAIN when the text is ambiguous or insufficient to determine whether NEGATIVE_ACTION actually happened
-
[55]
Do not assume completion from common knowledge or likely event sequences unless it is strongly entailed by the wording
-
[56]
Judge only from the provided text
-
[57]
is_neg": true,
Be conservative. If there is reasonable uncertainty between ENTAILED and NOT_ENTAILED, choose UNCERTAIN. Label mapping: - ENTAILED→is_neg = true - NOT_ENTAILED→is_neg = false - UNCERTAIN→is_neg = false Output valid JSON only in exactly this format: {"is_neg": true, "label": "ENTAILED", "reason": "one-sentence explanation"} or {"is_neg": false, "label": "N...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.