Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
Pith reviewed 2026-07-02 13:22 UTC · model grok-4.3
The pith
Explicitly separating perception from reasoning in vision-language models raises accuracy on tasks needing small visual details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
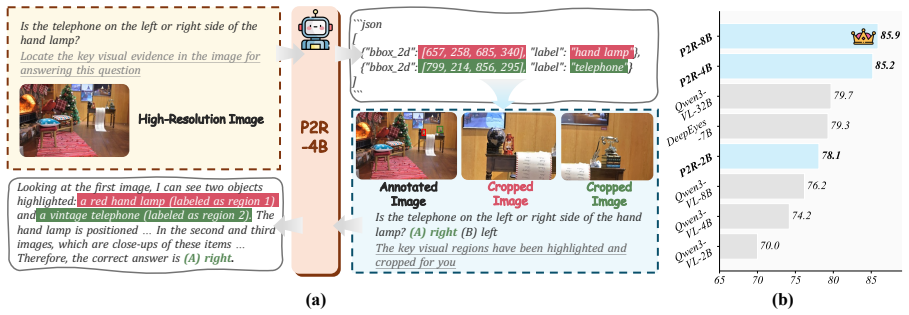
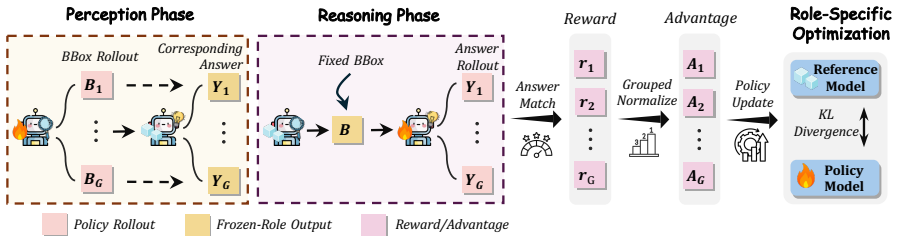
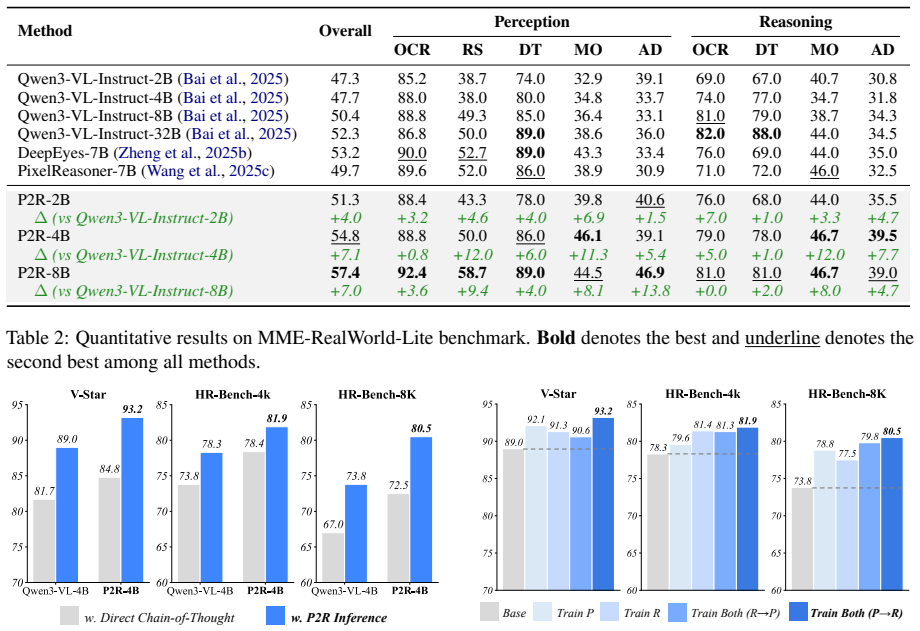
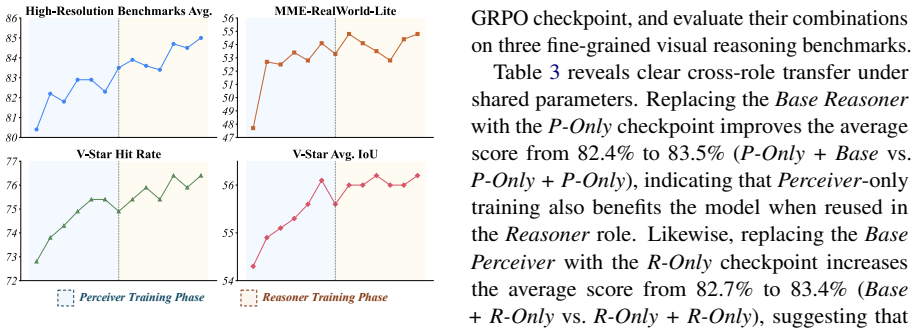
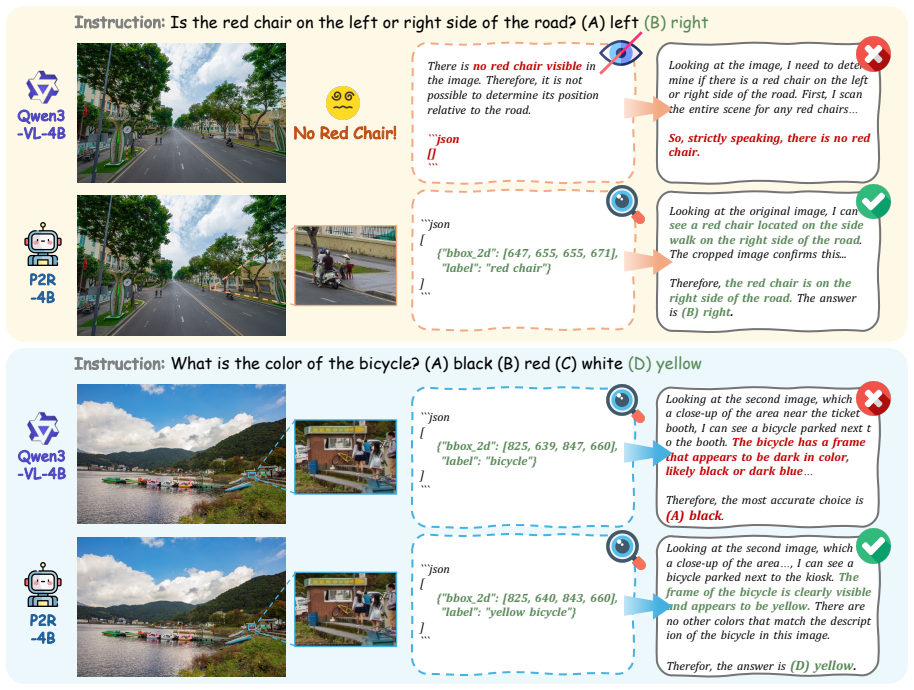
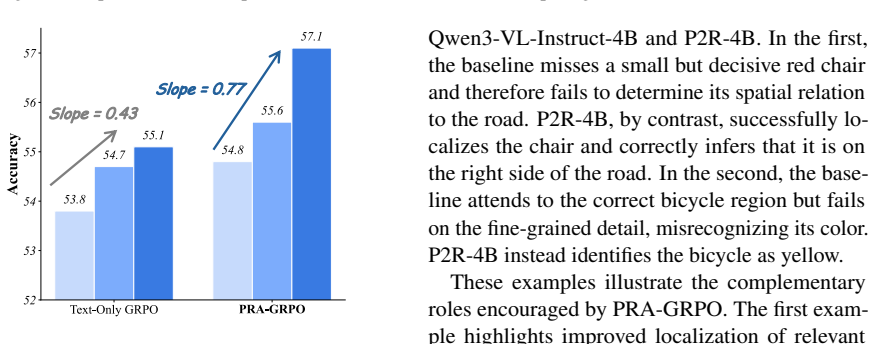
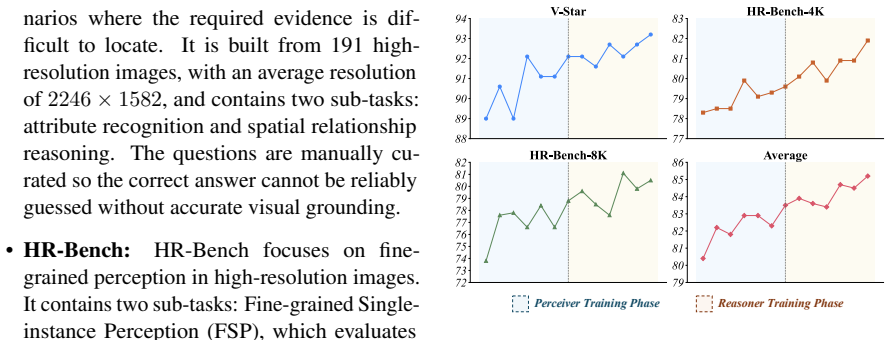
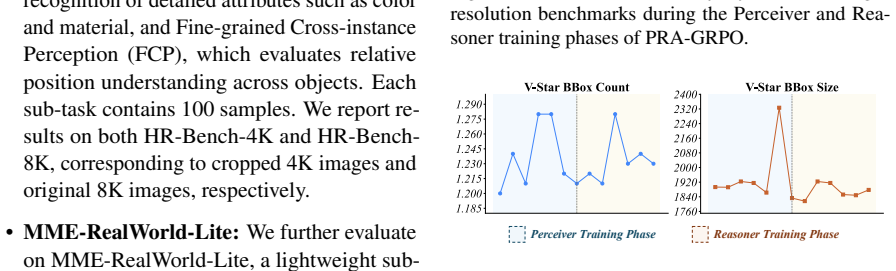
The central claim is that fine-grained visual reasoning is best formulated as a two-stage process in which the model first localizes question-relevant evidence as a Perceiver and then answers the question as a Reasoner based on the annotated image and cropped regions; training this formulation with Perception-Reasoning Alternating GRPO, which alternates role-specific updates using only final-answer supervision, produces consistent gains when applied to Qwen3-VL backbones, reaching 93.2 percent on V-Star, 81.9 percent on HR-Bench-4K, and 80.5 percent on HR-Bench-8K for the 4B variant while also helping broader multimodal tasks.
What carries the argument
The Perceive-to-Reason (P2R) framework, which enforces an explicit two-stage sequence of perception followed by reasoning together with role-aware alternating updates during reinforcement learning.
If this is right
- The same decoupling produces measurable gains across model sizes from 2B to 8B parameters on high-resolution benchmarks.
- Benefits appear on both high-resolution detail tasks and wider multimodal reasoning benchmarks.
- Training requires only final-answer labels yet still aligns the model to separate perception and reasoning behaviors.
- The approach removes the need for repeated cropping or test-time visual search at inference.
Where Pith is reading between the lines
- The separation could be used to train perception and reasoning modules independently in larger systems.
- Similar staged training might reduce entanglement in other sequential multimodal tasks such as video or document reasoning.
- If the pattern holds, single-stage joint training may be leaving performance on the table whenever perception and reasoning have different optimal update frequencies.
Load-bearing premise
The measured gains come from the explicit two-stage decoupling and alternating role updates rather than from extra training compute, data choices, or the reinforcement learning algorithm itself.
What would settle it
A model trained with the same total reinforcement learning steps and data but without the two-stage formulation or without alternating between perception and reasoning roles would match or exceed P2R performance on V-Star and the HR-Bench suites.
Figures

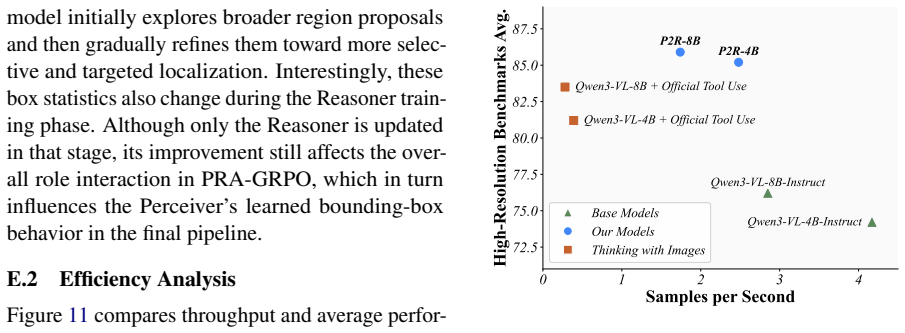
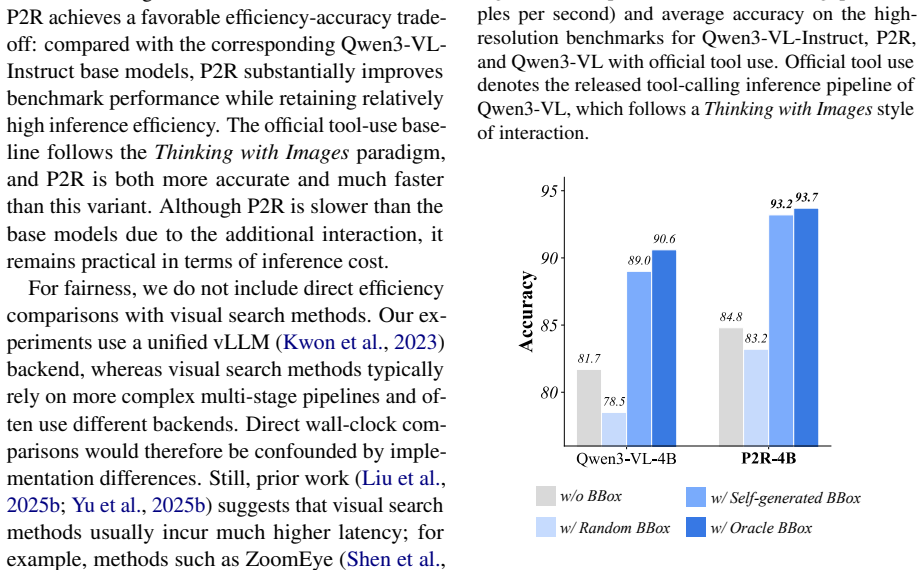








read the original abstract
Fine-grained visual reasoning remains challenging for vision-language models, especially when small but critical visual cues are buried in high-resolution images. Existing approaches rely on repeated cropping or test-time visual search to introduce local evidence, but they typically do not explicitly distinguish perception from reasoning. In this paper, we propose Perceive-to-Reason (P2R), a unified framework that formulates fine-grained visual reasoning as a two-stage process: the model first localizes question-relevant evidence as a Perceiver, and then answers the question as a Reasoner based on the annotated image and cropped regions. To better align training with this decoupled formulation, we further introduce Perception-Reasoning Alternating GRPO (PRA-GRPO), a role-aware reinforcement learning strategy that alternates between perception-focused and reasoning-focused updates using only final-answer supervision. Built on top of Qwen3-VL-Instruct-2B/4B/8B, P2R consistently improves performance across model scales. In particular, P2R-4B achieves 93.2% on V-Star, 81.9% on HR-Bench-4K, and 80.5% on HR-Bench-8K, substantially outperforming its corresponding backbone. Further experiments show that the benefits of P2R extend beyond high-resolution benchmarks to broader multimodal reasoning tasks. These results suggest that explicitly decoupling perception from reasoning provides an effective framework for fine-grained visual reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Perceive-to-Reason (P2R), a two-stage framework for fine-grained visual reasoning in VLMs: a Perceiver stage localizes question-relevant evidence in high-resolution images, followed by a Reasoner stage that answers using the annotated image and crops. Training uses Perception-Reasoning Alternating GRPO (PRA-GRPO) with role-aware alternating updates under final-answer supervision only. Built on Qwen3-VL-Instruct backbones (2B/4B/8B), P2R reports consistent gains, including P2R-4B at 93.2% on V-Star, 81.9% on HR-Bench-4K, and 80.5% on HR-Bench-8K, plus benefits on broader multimodal tasks.
Significance. If the gains can be causally attributed to the explicit perception-reasoning decoupling and alternating updates, the framework offers a practical training recipe that could improve fine-grained reasoning without test-time search or repeated cropping. The approach is notable for using only final-answer supervision and for scaling across model sizes, but its impact depends on whether the reported deltas exceed what generic RL or data choices would produce.
major comments (2)
- [Experiments / Results] The central claim—that explicit two-stage decoupling plus role-aware alternating updates drive the reported gains—is not supported by any ablation that holds the underlying RL algorithm (GRPO variant), data mixture, and total training steps fixed while removing either the Perceiver/Reasoner architectural split or the alternating update schedule. Without this control, the deltas (e.g., the 93.2%/81.9%/80.5% numbers for the 4B model) cannot be attributed to the proposed mechanism rather than to other training factors.
- [Abstract and §4 (Experiments)] The abstract and method description provide no information on baseline implementations, statistical significance testing, data splits, or variance across runs for the three main benchmarks. This makes it impossible to assess whether the claimed improvements over the corresponding backbones are robust or reproducible.
minor comments (2)
- [Method] Notation for the Perceiver and Reasoner roles and the exact form of the alternating update rule should be formalized with equations or pseudocode for clarity.
- [Experiments] The paper should clarify whether the reported numbers use the same evaluation protocol and prompts as the backbone baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the attribution of results to the proposed mechanisms and improve reproducibility details.
read point-by-point responses
-
Referee: [Experiments / Results] The central claim—that explicit two-stage decoupling plus role-aware alternating updates drive the reported gains—is not supported by any ablation that holds the underlying RL algorithm (GRPO variant), data mixture, and total training steps fixed while removing either the Perceiver/Reasoner architectural split or the alternating update schedule. Without this control, the deltas (e.g., the 93.2%/81.9%/80.5% numbers for the 4B model) cannot be attributed to the proposed mechanism rather than to other training factors.
Authors: We agree that the manuscript currently lacks a fully controlled ablation that isolates the Perceiver/Reasoner split and alternating schedule while exactly matching GRPO variant, data mixture, and total steps. In the revision we will add these experiments (e.g., a single-stage GRPO baseline and a non-alternating joint-update variant) on the same 4B backbone and report the resulting deltas on V-Star, HR-Bench-4K, and HR-Bench-8K. This will allow readers to attribute gains more directly to the decoupling and PRA-GRPO schedule. revision: yes
-
Referee: [Abstract and §4 (Experiments)] The abstract and method description provide no information on baseline implementations, statistical significance testing, data splits, or variance across runs for the three main benchmarks. This makes it impossible to assess whether the claimed improvements over the corresponding backbones are robust or reproducible.
Authors: We acknowledge the omission. In the revised §4 we will (1) detail how the Qwen3-VL-Instruct baselines were evaluated (prompting, resolution handling, and decoding settings), (2) specify the exact training/evaluation data splits and any filtering applied, (3) report standard deviation across at least three independent runs for the primary benchmarks, and (4) include a brief note on statistical significance where sample sizes permit. These additions will be reflected in an updated abstract if space allows. revision: yes
Circularity Check
No circularity; purely empirical framework with no derivations
full rationale
The paper introduces an empirical two-stage framework (Perceiver then Reasoner) plus PRA-GRPO training and reports benchmark scores on V-Star, HR-Bench, etc. No equations, fitted parameters, or mathematical derivations appear anywhere in the provided text. The performance claims are direct experimental outcomes rather than quantities derived from or equivalent to the inputs by construction. Self-citations are not load-bearing for any derivation because none exists. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Alternating perception-focused and reasoning-focused GRPO updates using only final-answer supervision suffices to train the decoupled Perceiver and Reasoner roles.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
2025 , url =
OpenAI , title =. 2025 , url =
2025
-
[10]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
V?: Guided visual search as a core mechanism in multimodal llms , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[14]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[15]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[16]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Deepeyes: Incentivizing" thinking with images" via reinforcement learning , author=. arXiv preprint arXiv:2505.14362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepEyesV2: Toward Agentic Multimodal Model
Deepeyesv2: Toward agentic multimodal model , author=. arXiv preprint arXiv:2511.05271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning , author=. arXiv preprint arXiv:2505.15966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Mini-o3: Scaling up reasoning patterns and interaction turns for visual search , author=. arXiv preprint arXiv:2509.07969 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Thyme: Think beyond images , author=. arXiv preprint arXiv:2508.11630 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2504.07954 , year=
Perception-r1: Pioneering perception policy with reinforcement learning , author=. arXiv preprint arXiv:2504.07954 , year=
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans? , author=. arXiv preprint arXiv:2408.13257 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2602.11858 , year=
Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception , author=. arXiv preprint arXiv:2602.11858 , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2403.12966 , year=
Chain-of-spot: Interactive reasoning improves large vision-language models , author=. arXiv preprint arXiv:2403.12966 , year=
-
[28]
Advances in Neural Information Processing Systems , volume=
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
GRIT: Teaching MLLMs to Think with Images
Grit: Teaching mllms to think with images , author=. arXiv preprint arXiv:2505.15879 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Visual-RFT: Visual Reinforcement Fine-Tuning
Visual-rft: Visual reinforcement fine-tuning , author=. arXiv preprint arXiv:2503.01785 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Vlm-r1: A stable and generalizable r1-style large vision-language model , author=. arXiv preprint arXiv:2504.07615 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
CoRR , year=
Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning , author=. CoRR , year=
-
[33]
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization , author=. arXiv preprint arXiv:2503.10615 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2602.12916 , year=
Reliable thinking with images , author=. arXiv preprint arXiv:2602.12916 , year=
-
[35]
HiDe: Rethinking The Zoom-IN method in High Resolution MLLMs via Hierarchical Decoupling
HiDe: Rethinking The Zoom-IN method in High Resolution MLLMs via Hierarchical Decoupling , author=. arXiv preprint arXiv:2510.00054 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[39]
Kullback-leibler divergence , author=. Tech. Rep. , year=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Lisa: Reasoning segmentation via large language model , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
arXiv preprint arXiv:2506.01663 , year=
Zoom-Refine: Boosting High-Resolution Multimodal Understanding via Localized Zoom and Self-Refinement , author=. arXiv preprint arXiv:2506.01663 , year=
-
[42]
arXiv preprint arXiv:2510.18876 , year=
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs , author=. arXiv preprint arXiv:2510.18876 , year=
-
[43]
Advances in Neural Information Processing Systems , volume=
Spot the fake: Large multimodal model-based synthetic image detection with artifact explanation , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Spatialladder: Progressive training for spatial reasoning in vision-language models,
Spatialladder: Progressive training for spatial reasoning in vision-language models , author=. arXiv preprint arXiv:2510.08531 , year=
-
[45]
arXiv preprint arXiv:2505.21500 , year=
Viewspatial-bench: Evaluating multi-perspective spatial localization in vision-language models , author=. arXiv preprint arXiv:2505.21500 , year=
-
[46]
International Conference on Learning Representations , volume=
Mllms know where to look: Training-free perception of small visual details with multimodal llms , author=. International Conference on Learning Representations , volume=
-
[47]
AdaTooler-V: Adaptive Tool-Use for Images and Videos
AdaTooler-V: Adaptive Tool-Use for Images and Videos , author=. arXiv preprint arXiv:2512.16918 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
arXiv preprint arXiv:2507.07998 , year=
Pyvision: Agentic vision with dynamic tooling , author=. arXiv preprint arXiv:2507.07998 , year=
-
[49]
GroundAct: Can LLM Agents Ground Actions in Environmental States?
Omniear: Benchmarking agent reasoning in embodied tasks , author=. arXiv preprint arXiv:2508.05614 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[51]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[52]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
arXiv preprint arXiv:2512.21625 , year=
Rethinking sample polarity in reinforcement learning with verifiable rewards , author=. arXiv preprint arXiv:2512.21625 , year=
-
[54]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization , author=. arXiv preprint arXiv:2601.05242 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Advances in Neural Information Processing Systems , volume=
Learning to reason under off-policy guidance , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
arXiv preprint arXiv:2602.20739 , year=
PyVision-RL: Forging Open Agentic Vision Models via RL , author=. arXiv preprint arXiv:2602.20739 , year=
-
[59]
arXiv preprint arXiv:2509.25916 , year=
Vlm-fo1: Bridging the gap between high-level reasoning and fine-grained perception in vlms , author=. arXiv preprint arXiv:2509.25916 , year=
-
[60]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement , author=. arXiv preprint arXiv:2503.06520 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Advances in Neural Information Processing Systems , volume=
Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
arXiv preprint arXiv:2509.13031 , year=
Perception before reasoning: Two-stage reinforcement learning for visual reasoning in vision-language models , author=. arXiv preprint arXiv:2509.13031 , year=
-
[63]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
arXiv preprint arXiv:2506.19767 , year=
Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning , author=. arXiv preprint arXiv:2506.19767 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.