Entropy Across the Bridge: Conditional-Marginal Discretization for Flow and Schr\"odinger Samplers
Pith reviewed 2026-05-20 19:42 UTC · model grok-4.3
The pith
A conditional-marginal entropy-rate objective provides a first-principles way to discretize time for flow and Schrödinger bridge samplers under limited inference budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
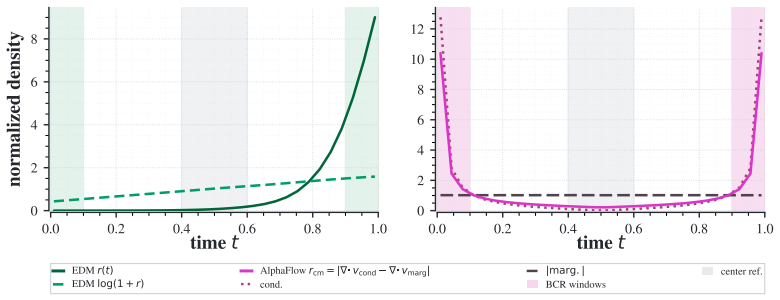
We derive a conditional-marginal entropy-rate objective for bridge-aware discretization, separating endpoint-conditioned bridge geometry from marginal flow evolution, and use it to build a training-free entropic inference-time scheduler from first principles. For Gaussian Brownian bridges this rate is closed-form and U-shaped, motivating boundary-heavy nonuniform grids. On trained models the estimated profile recovers the predicted shape and yields measurable gains in low-NFE regimes.
What carries the argument
The conditional-marginal entropy rate, which measures the expected change in entropy along the probability path while conditioning on both endpoints and the current marginal.
If this is right
- Boundary-heavy nonuniform time grids improve sample quality for Gaussian Brownian bridge samplers.
- The entropic scheduler requires no additional training and applies directly at inference.
- On 2D bridge models, 10-step Heun integration shows 18% better MMD than linear spacing.
- Five-step sampling on EDM/CIFAR-10 achieves an FID of 186.3 compared to 200.5 for linear.
- Protein generation on CAMEO22 and ATLAS benchmarks benefits in low-NFE settings.
Where Pith is reading between the lines
- Similar entropy-based allocation could be derived for other classes of generative paths if their entropy rates admit tractable estimates.
- The separation of conditional bridge geometry from marginal flow might extend to hybrid models that combine flows with other dynamics.
- Further work could test whether the U-shape persists or changes under different bridge constructions or data distributions.
Load-bearing premise
That the estimated conditional-marginal entropy rate remains a reliable proxy for optimal step allocation once the model is trained on high-dimensional data rather than being dominated by approximation error.
What would settle it
Running the entropic scheduler on a new high-dimensional flow model and finding that it produces worse FID or MMD scores than a simple linear schedule in a controlled low-NFE experiment would falsify the practical utility of the objective.
Figures














read the original abstract
For a fixed flow-based generative model under a small inference budget, sample quality can depend strongly on where the sampler spends its few function evaluations. Flow matching and Schr\"odinger bridges define probability paths, yet their inference grids are usually heuristic or inherited from one-endpoint diffusion. We derive a conditional-marginal entropy-rate objective for bridge-aware discretization, separating endpoint-conditioned bridge geometry from marginal flow evolution, and use it to build a training-free entropic inference-time scheduler from first principles. For Gaussian Brownian bridges this rate is closed-form and U-shaped, motivating boundary-heavy nonuniform grids. On trained two-dimensional bridge/flow models, the estimated profile recovers the predicted shape and improves 10-step ODE-Heun MMD over linear by 18.1%, with a paired 22.7% SDE-Heun improvement in the same low-NFE sweep. On EDM/CIFAR-10, the entropic time-discretization gives the best tested five-step FID (186.3 \pm 4.0 versus 200.5 \pm 2.9 for linear and 238.0 \pm 5.3 for cosine). On AlphaFlow protein generation, entropic conditional-marginal (cond-marg) scheduling shows advantage in low-NFE regimes on both CAMEO22 and ATLAS benchmarks. These results support entropy-rate scheduling as a practical low-budget allocation signal for high-dimensional bridge and flow samplers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives a conditional-marginal entropy-rate objective for bridge-aware discretization in flow matching and Schrödinger bridge samplers, separating endpoint-conditioned bridge geometry from marginal flow evolution to obtain a training-free entropic inference-time scheduler. For Gaussian Brownian bridges the rate is closed-form and U-shaped, motivating boundary-heavy nonuniform grids. On trained 2D models the estimated profile recovers the predicted shape and yields 18.1% MMD improvement for 10-step ODE-Heun and 22.7% for SDE-Heun over linear grids. On EDM/CIFAR-10 the entropic scheduler achieves the best reported 5-step FID (186.3 ± 4.0); on AlphaFlow it shows advantage in low-NFE regimes on CAMEO22 and ATLAS benchmarks.
Significance. If the conditional-marginal entropy-rate estimator remains a reliable proxy for optimal step allocation once models are trained on high-dimensional data, the approach supplies a principled, parameter-free method for allocating limited function evaluations at inference time. The closed-form Gaussian derivation and the reproducible 2D recovery of the U-shape constitute clear strengths that could make the scheduler a practical addition to existing flow and bridge samplers.
major comments (2)
- [EDM/CIFAR-10 and AlphaFlow experiments] The manuscript provides no error bound, convergence result, or ablation of the separation assumption for the entropy-rate estimator when applied to trained high-dimensional models (EDM/CIFAR-10 and AlphaFlow sections). Monte-Carlo variance, score-model mismatch, or discretization error in the entropy functional could therefore dominate the step-allocation signal rather than true bridge geometry.
- [Method and Experiments] The central claim that the scheduler is built 'from first principles' and remains training-free rests on the fidelity of the estimated conditional-marginal profile; without a quantitative demonstration that the estimator converges to the true rate as model capacity or sample size increases, the high-dimensional results remain vulnerable to post-hoc tuning artifacts.
minor comments (2)
- [Abstract] The abstract states an 18.1% MMD improvement but does not report the number of independent runs or the precise baseline configuration used for the 2D sweep.
- [Notation and Definitions] Notation for the conditional-marginal entropy rate should be introduced once and used consistently; occasional switches between 'cond-marg' and full phrasing reduce readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, acknowledging limitations where the manuscript currently lacks theoretical support and indicating revisions to clarify scope and add discussion of estimator reliability.
read point-by-point responses
-
Referee: [EDM/CIFAR-10 and AlphaFlow experiments] The manuscript provides no error bound, convergence result, or ablation of the separation assumption for the entropy-rate estimator when applied to trained high-dimensional models (EDM/CIFAR-10 and AlphaFlow sections). Monte-Carlo variance, score-model mismatch, or discretization error in the entropy functional could therefore dominate the step-allocation signal rather than true bridge geometry.
Authors: We agree that the manuscript does not supply formal error bounds, convergence results, or targeted ablations isolating the separation assumption for the conditional-marginal entropy-rate estimator on trained high-dimensional models. The 2D experiments show that the estimated profile recovers the closed-form U-shape predicted for Gaussian Brownian bridges, offering controlled validation of the estimator. On EDM/CIFAR-10 and AlphaFlow, we report reproducible empirical gains in low-NFE regimes (e.g., best 5-step FID of 186.3), yet we recognize that Monte-Carlo variance or model mismatch could affect the signal. We will add a dedicated limitations subsection discussing these factors and suggesting future ablations on estimator variance. revision: partial
-
Referee: [Method and Experiments] The central claim that the scheduler is built 'from first principles' and remains training-free rests on the fidelity of the estimated conditional-marginal profile; without a quantitative demonstration that the estimator converges to the true rate as model capacity or sample size increases, the high-dimensional results remain vulnerable to post-hoc tuning artifacts.
Authors: The conditional-marginal entropy-rate objective is derived directly from the separation of endpoint-conditioned bridge geometry and marginal flow evolution, yielding a training-free scheduler that uses only the pre-trained model for entropy estimation. The 2D recovery of the theoretical U-shape supports fidelity of the estimator in that regime. We do not, however, include a quantitative convergence study with respect to model capacity or sample size for high-dimensional cases. We will revise the abstract, introduction, and method sections to qualify the 'from first principles' phrasing, explicitly noting that high-dimensional validation is empirical and that the scheduler's practical utility is demonstrated through performance improvements rather than proven convergence. revision: yes
- A rigorous convergence analysis or error bounds for the entropy-rate estimator under trained high-dimensional score models, which would require new theoretical development outside the current scope of the work.
Circularity Check
Derivation from first principles with closed-form Gaussian case remains self-contained
full rationale
The paper derives the conditional-marginal entropy-rate objective by separating endpoint-conditioned bridge geometry from marginal flow evolution, yielding a closed-form U-shaped rate for Gaussian Brownian bridges without fitting parameters or self-referential definitions. This is presented as a first-principles result. On trained models the estimated profile is shown to recover the predicted shape on 2D toys and improve performance on high-dimensional tasks, but the scheduler construction itself does not reduce to a self-referential fit, self-citation chain, or renaming of inputs by construction. No load-bearing step equates the output to its inputs by construction, and the analysis is independent of the target results with external benchmark improvements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probability paths are continuous and differentiable as defined by flow matching or Schrödinger bridges.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive a conditional–marginal entropy-rate objective for bridge-aware discretization, separating endpoint-conditioned bridge geometry from marginal flow evolution... For Gaussian Brownian bridges this rate is closed-form and U-shaped
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
d/dt H(Z|X_t) = E_{Z,X_t|Z}[∇·v_t(X_t|Z)] − E_{X_t}[∇·¯v_t(X_t)]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zico Kolter, Nicholas Matthew Boffi, and Max Simchowitz
Xinyue Ai, Yutong He, Albert Gu, Ruslan Salakhutdinov, J. Zico Kolter, Nicholas Matthew Boffi, and Max Simchowitz. Joint distillation for fast likelihood evaluation and sampling in flow-based models. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=8uZ5UdIul2
work page 2026
-
[2]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InInternational Conference on Learning Representations, 2023
work page 2023
-
[3]
Mutual information neural estimation
Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajeshwar, Sherjil Ozair, Yoshua Bengio, Aaron Courville, and Devon Hjelm. Mutual information neural estimation. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine 9 Learning Research, pages 531–540, 2018. URL https://proceedings.mlr.press/v80/ belghazi18a.html
work page 2018
-
[4]
Anthony J. Bell and Terrence J. Sejnowski. An information-maximization approach to blind separation and blind deconvolution.Neural Computation, 7(6):1129–1159, 1995. doi: 10.1162/ neco.1995.7.6.1129
work page 1995
-
[5]
On the importance of noise scheduling for diffusion models.arXiv preprint arXiv:2301.10972, 2023
Ting Chen. On the importance of noise scheduling for diffusion models.arXiv preprint arXiv:2301.10972, 2023
-
[6]
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. InfoGAN: Interpretable representation learning by information max- imizing generative adversarial nets. InAdvances in Neural Information Pro- cessing Systems, volume 29, 2016. URL https://papers.nips.cc/paper/ 6399-infogan-interpretable-representation-learning-by-informat...
work page 2016
-
[7]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAdvances in Neural Information Processing Systems, volume 26, 2013
work page 2013
-
[8]
Diffusion Schrödinger bridge with applications to score-based generative modeling
Valentin De Bortoli, James Thornton, Jeremy Heng, and Arnaud Doucet. Diffusion Schrödinger bridge with applications to score-based generative modeling. InAdvances in Neural Information Processing Systems, volume 34, pages 17695–17709, 2021
work page 2021
-
[9]
Proteina: Scaling flow-based protein structure generative models
Tomas Geffner, Kieran Didi, Zuobai Zhang, Danny Reidenbach, Zhonglin Cao, Jason Yim, Mario Geiger, Christian Dallago, Emine Kucukbenli, Arash Vahdat, and Karsten Kreis. Proteina: Scaling flow-based protein structure generative models. InInternational Conference on Learning Representations, 2025
work page 2025
-
[10]
Inverse bridge matching distillation.arXiv preprint, 2025
Nikita Gushchin et al. Inverse bridge matching distillation.arXiv preprint, 2025
work page 2025
-
[11]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1861–1870, 2018. URL https://proceedings.mlr.press/v80/ haarno...
work page 2018
-
[12]
Juergen Haas, Alessandro Barbato, Dario Behringer, Gabriel Studer, Steven Roth, Martino Bertoni, Khaled Mostaguir, Rafal Gumienny, and Torsten Schwede. Continuous automated model evaluation (cameo) complementing the critical assessment of structure prediction in casp12.Proteins: Structure, Function, and Bioinformatics, 86:387–398, 2018. doi: 10.1002/ prot.25431
work page 2018
-
[13]
Wasserstein flow matching: Generative modeling over families of distributions
Doron Haviv, Aram-Alexandre Pooladian, Dana Pe’er, and Brandon Amos. Wasserstein flow matching: Generative modeling over families of distributions. InInternational Conference on Machine Learning, 2025. URLhttps://icml.cc/virtual/2025/poster/45541
work page 2025
-
[14]
Consistency diffusion bridge models.arXiv preprint, 2024
Guande He et al. Consistency diffusion bridge models.arXiv preprint, 2024
work page 2024
-
[15]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
-
[16]
Michele Invernizzi, Sandro Bottaro, Julian O. Streit, Bruno Trentini, Niccolò Alberto Elia Venanzi, Danny Reidenbach, Youhan Lee, Christian Dallago, Hassan Sirelkhatim, Bowen Jing, Fabio Airoldi, Kresten Lindorff-Larsen, Carlo Fisicaro, and Kamil Tamiola. Advancing protein ensemble predictions across the order–disorder continuum.bioRxiv, 2025. doi: 10. 11...
-
[17]
Efficient 3d molecular generation with flow matching and scale optimal transport
Ross Irwin, Alessandro Tibo, Jon Paul Janet, and Simon Olsson. Efficient 3d molecular generation with flow matching and scale optimal transport. InICML Workshop on AI for Science, 2024. URLhttps://icml.cc/virtual/2024/36820
work page 2024
-
[18]
Alphafold meets flow matching for generating protein ensembles, 2024
Bowen Jing, Bonnie Berger, and Tommi Jaakkola. Alphafold meets flow matching for generating protein ensembles, 2024. URLhttps://arxiv.org/abs/2402.04845. 10
-
[19]
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, Alex Bridgland, Clemens Meyer, Simon A. A. Kohl, Andrew J. Ballard, Andrew Cowie, Bernardino Romera-Paredes, Stanislav Nikolov, Rishub Jain, Jonas Adler, Trevor Back, Stig Petersen, David Reim...
-
[20]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems, volume 35, pages 26565–26577, 2022
work page 2022
-
[21]
Kingma, Tim Salimans, Ben Poole, and Jonathan Ho
Diederik P. Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. InAdvances in Neural Information Processing Systems, volume 34, 2021
work page 2021
-
[22]
Categorical Schrödinger bridge matching
Grigoriy Ksenofontov and Aleksandr Korotin. Categorical Schrödinger bridge matching. In International Conference on Machine Learning, 2025. URL https://icml.cc/virtual/ 2025/poster/45290
work page 2025
-
[23]
Christian Léonard. A survey of the schrödinger problem and some of its connections with optimal transport.Discrete and Continuous Dynamical Systems - A, 34(4):1533–1574, 2014. doi: 10.3934/dcds.2014.34.1533
-
[24]
Sarah Lewis, Tim Hempel, José Jiménez-Luna, Michael Gastegger, Yu Xie, Andrew Y . K. Foong, Victor G. Satorras, Osama Abdin, Bastiaan S. Veeling, Iryna Zaporozhets, Yaoyi Chen, Soojung Yang, Adam E. Foster, Arne Schneuing, Jigyasa Nigam, Federico Barbero, Vincent Stimper, Andrew Campbell, Jason Yim, Marten Lienen, Yu Shi, Shuxin Zheng, Hannes Schulz, Usma...
-
[25]
doi: 10.1126/science.adv9817
-
[26]
Common diffusion noise schedules and sample steps are flawed
Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Common diffusion noise schedules and sample steps are flawed. InIEEE/CVF Winter Conference on Applications of Computer Vision, pages 5404–5411, 2024
work page 2024
-
[27]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
work page 2023
-
[28]
Theodorou, Weili Nie, and Anima Anandkumar
Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A. Theodorou, Weili Nie, and Anima Anandkumar. I 2SB: Image-to-image Schrödinger bridge. InInternational Conference on Machine Learning, pages 22042–22062, 2023
work page 2023
-
[29]
Guan-Horng Liu, Jaemoo Choi, Yongxin Chen, Benjamin Kurt Miller, and Ricky T. Q. Chen. Adjoint Schrödinger bridge sampler. InAdvances in Neural Information Processing Systems,
-
[30]
URLhttps://openreview.net/forum?id=rMhQBlhh4c
-
[31]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023
work page 2023
- [32]
-
[33]
DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InAdvances in Neural Information Processing Systems, volume 35, pages 5775–5787, 2022
work page 2022
-
[34]
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM- Solver++: Fast solver for guided sampling of diffusion probabilistic models.arXiv preprint arXiv:2211.01095, 2022. 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Valerio Mariani, Marco Biasini, Alessandro Barbato, and Torsten Schwede. lddt: a local superposition-free score for comparing protein structures and models using distance difference tests.Bioinformatics, 29(21):2722–2728, 2013. doi: 10.1093/bioinformatics/btt473
-
[36]
Benjamin Kurt Miller, Ricky T. Q. Chen, Anuroop Sriram, and Brandon Wood. FlowMM: Generating materials with riemannian flow matching. InInternational Conference on Machine Learning, 2024. URLhttps://icml.cc/virtual/2024/poster/33890
work page 2024
-
[37]
BézierFlow: Learning Bézier stochastic interpolant schedulers for few-step generation
Yunhong Min, Juil Koo, Seungwoo Yoo, and Minhyuk Sung. BézierFlow: Learning Bézier stochastic interpolant schedulers for few-step generation. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=PCuDI32xhQ
work page 2026
-
[38]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInternational Conference on Machine Learning, pages 8162–8171, 2021
work page 2021
-
[39]
Ryan Park, Darren J. Hsu, C. Brian Roland, Maria Korshunova, Chen Tessler, Shie Mannor, Olivia Viessmann, and Bruno Trentini. Improving inverse folding for peptide design with diversity-regularized direct preference optimization, 2024. URL https://arxiv.org/abs/ 2410.19471
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Romeo Passaro, Zander W. Blasingame, Michael M. Bronstein, and Alexander Tong. Stochastic few-step models. InICLR 2026 Workshop on Reasoning and Planning for Large Generative Models, 2026. URLhttps://openreview.net/forum?id=i31AUZF8kO
work page 2026
-
[41]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022
work page 2022
-
[42]
Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align your steps: Optimizing sampling schedules in diffusion models.arXiv preprint arXiv:2404.14507, 2024
-
[43]
Erwin Schrödinger. Über die umkehrung der naturgesetze.Sitzungsberichte der Preussischen Akademie der Wissenschaften, Physikalisch-mathematische Klasse, 1931
work page 1931
-
[44]
Über die umkehrung der naturgesetze
Erwin Schrödinger. Über die umkehrung der naturgesetze. Zweite mitteilung.Sitzungsberichte der Preussischen Akademie der Wissenschaften, Physikalisch-mathematische Klasse, 1932
work page 1932
-
[45]
The information dynamics of generative diffusion
Dejan Stanˇcevi´c and Luca Ambrogioni. The information dynamics of generative diffusion. Entropy, 28(2):195, 2026. doi: 10.3390/e28020195
-
[46]
Entropic time schedulers for generative diffusion models
Dejan Stanˇcevi´c, Florian Handke, and Luca Ambrogioni. Entropic time schedulers for generative diffusion models. InAdvances in Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=EfDIApcjgI
work page 2025
-
[47]
Data-to-energy stochastic dynamics
Kirill Tamogashev and Nikolay Malkin. Data-to-energy stochastic dynamics. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=S1JJyWg1VG
work page 2026
-
[48]
Zheng Tan, Weizhen Wang, Andrea L. Bertozzi, and Ernest K. Ryu. STORK: Faster diffusion and flow matching sampling by resolving both stiffness and structure-dependence. InInter- national Conference on Learning Representations, 2026. URL https://openreview.net/ forum?id=CeOIVXMl4r
work page 2026
-
[49]
Branched Schrödinger bridge matching
Sophia Tang, Yinuo Zhang, Alexander Tong, and Pranam Chatterjee. Branched Schrödinger bridge matching. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=ctq8BfUXWz
work page 2026
-
[50]
The information bottleneck method
Naftali Tishby, Fernando C. Pereira, and William Bialek. The information bottleneck method. arXiv preprint physics/0004057, 2000. URLhttps://arxiv.org/abs/physics/0004057
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[51]
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector- Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research, 2024. 12
work page 2024
-
[52]
arXiv preprint arXiv:2307.03672 , year=
Alexander Tong, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector-Brooks, Kilian Fatras, Guy Wolf, and Yoshua Bengio. Simulation-free Schrödinger bridges via score and flow matching.arXiv preprint arXiv:2307.03672, 2024
-
[53]
Optimal scheduling of dynamic transport.arXiv preprint arXiv:2504.14425, 2025
Panos Tsimpos, Zhi Ren, Jakob Zech, and Youssef Marzouk. Optimal scheduling of dynamic transport.arXiv preprint arXiv:2504.14425, 2025
-
[54]
Atlas: protein flexibility description from atomistic molecular dynamics simulations
Yann Vander Meersche, Gabriel Cretin, Aria Gheeraert, Jean-Christophe Gelly, and Tatiana Ga- lochkina. Atlas: protein flexibility description from atomistic molecular dynamics simulations. Nucleic Acids Research, 52(D1):D384–D392, 2024. doi: 10.1093/nar/gkad1084
-
[55]
Kacper Wyrwal, Ismail Ilkan Ceylan, and Alexander Tong. Topological flow matching. In International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=5CM3ax45Ma
work page 2026
-
[56]
Accelerating diffusion sampling with optimized time steps.arXiv preprint arXiv:2402.17376, 2024
Shuchen Xue, Zhaoqiang Liu, Fei Chen, Shifeng Zhang, Tianyang Hu, Enze Xing, and Mingyuan Zhou. Accelerating diffusion sampling with optimized time steps.arXiv preprint arXiv:2402.17376, 2024
-
[57]
Fast sampling of diffusion models with exponential integrator
Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator. InInternational Conference on Learning Representations, 2023
work page 2023
-
[58]
UniPC: A unified predictor- corrector framework for fast sampling of diffusion models
Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. UniPC: A unified predictor- corrector framework for fast sampling of diffusion models. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[59]
Brian D. Ziebart, Andrew Maas, J. Andrew Bagnell, and Anind K. Dey. Maximum entropy inverse reinforcement learning. InProceedings of the 23rd AAAI Conference on Artificial Intelligence, pages 1433–1438, 2008. 13 Appendix A A guided derivation of the conditional–marginal rate Marginal entropy rate.We assumed in the main text that the density and vector fie...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.