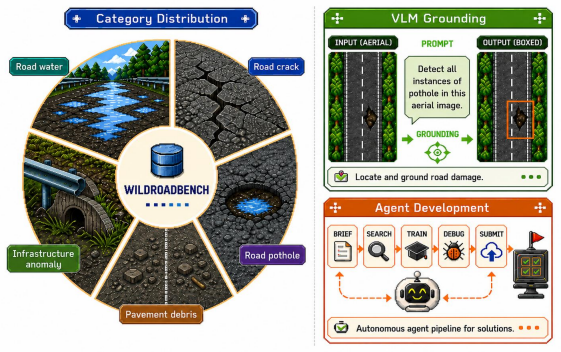
WildRoadBench: A Wild Aerial Road-Damage Grounding Benchmark for Vision-Language Models and Autonomous Agents
Pith reviewed 2026-05-21 07:51 UTC · model grok-4.3
The pith
WildRoadBench shows both VLMs and LLM agents fall far short of reliable road-damage grounding on wild UAV imagery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the same wild aerial road-damage UAV images and the same per-class AP_50 metric, neither fixed vision-language models nor budget-constrained LLM-driven agents reach reliable localization performance; closed-source models lead but substantial gaps remain, open-source models plateau lower especially on small instances, and agents do not surpass the strongest VLM.
What carries the argument
The dual-track WildRoadBench protocol that applies identical UAV images and AP_50 scoring to both direct VLM prompting and autonomous agent adaptation under unified prompting, decoding and parsing rules.
If this is right
- Closed-source frontier VLMs set the current ceiling but still miss more than half the AP_50 points.
- Open-source VLMs plateau well below closed-source ones and fail especially on small damage instances.
- Newer generations and reasoning-style open-source variants do not deliver consistent grounding gains.
- LLM agents with web search and code-writing affordances still lag the best fixed VLM within the given budget.
Where Pith is reading between the lines
- Domain-specific fine-tuning or aerial-aware pretraining may be required before general VLMs become practical for UAV road inspection.
- The benchmark could be extended with multi-frame or temporal inputs to test whether agents improve when given richer context.
- Real deployment of autonomous UAV fleets for infrastructure monitoring would need grounding accuracy well above the levels shown here.
Load-bearing premise
The professionally annotated UAV corpus together with per-class AP_50 under one fixed prompting and parsing pipeline gives a fair measure of real-world wild aerial road-damage grounding ability.
What would settle it
A new VLM or agent that achieves AP_50 scores approaching the theoretical maximum on the hidden holdout set while following the benchmark's exact prompting, decoding and submission rules.
Figures




read the original abstract
We introduce WildRoadBench, a wild aerial road-damage grounding benchmark that couples direct visual grounding by vision-language models with autonomous research-and-engineering by LLM-driven agents on a single professionally annotated UAV corpus. The same image set and the same per-class AP_50 metric are evaluated under two protocols. The VLM Track measures whether a fixed VLM can localise domain-specific damage from one image and one short prompt under a unified prompting, decoding and parsing pipeline. The Agent Track measures whether an autonomous agent, given only a written task brief, a small exploratory slice and a fixed interaction budget, can search the public web, adapt pretrained components, write training and inference code, and submit predictions through a scalar-feedback oracle on a hidden holdout. We benchmark a broad pool of closed-source frontier models and open-source VLMs together with several frontier LLM-driven agents. Both routes remain far from reliable performance in this wild setting: closed-source frontier models lead the VLM leaderboard but still leave more than half of the metric on the table; open-source grounders plateau well below them, and newer generations or reasoning-style variants do not consistently improve grounding; small targets collapse for every open-source model; agents lag the strongest VLM despite richer affordances, and several fail to land a valid submission within the budget. We release the code and data at https://anonymous.4open.science/r/wildroadbench-0607 to support reproducible follow-up research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WildRoadBench, a benchmark coupling VLM direct grounding and LLM-agent engineering on a single professionally annotated UAV corpus of wild aerial road damages. The VLM Track evaluates fixed models under a unified prompting/decoding/parsing pipeline using per-class AP_50; the Agent Track evaluates autonomous agents that must search the web, adapt components, write code, and submit to a hidden holdout under a fixed interaction budget and scalar feedback. Results show closed-source frontier VLMs lead but leave more than half the metric unrealized, open-source models plateau lower (especially on small targets), and agents lag the best VLM or fail to submit.
Significance. If the benchmark is representative, the work provides a reproducible, dual-protocol testbed that quantifies current limitations in domain-specific aerial grounding and agentic adaptation for real-world conditions. The release of code, data, and the hidden-holdout protocol with scalar feedback are concrete strengths that enable follow-up research.
major comments (1)
- [Benchmark definition and data sections] Benchmark definition and data sections: the central claim that both tracks remain far from reliable performance rests on the corpus providing a fair, unbiased measure of wild aerial road-damage grounding. The manuscript states the data are 'professionally annotated' and evaluations use 'the same per-class AP_50 metric' under a 'unified prompting, decoding and parsing pipeline,' yet supplies no details on damage class definitions, annotation guidelines, inter-annotator agreement, image selection criteria (altitude, weather, occlusion), or class balance. This is load-bearing; without these, the reported gaps (frontier models leaving >50% on the table, open-source collapse on small targets) cannot be confidently attributed to model limitations rather than testbed artifacts.
minor comments (2)
- [Abstract] Abstract: the anonymous link should be replaced with a permanent repository identifier in the camera-ready version to ensure long-term reproducibility.
- [Figures and tables] Figure and table captions: several captions are terse; expanding them to explicitly state what each subplot or row measures would improve readability for readers unfamiliar with the dual-track protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark transparency. We agree that additional details on data construction are warranted to support the central claims and will incorporate them in the revision.
read point-by-point responses
-
Referee: [Benchmark definition and data sections] Benchmark definition and data sections: the central claim that both tracks remain far from reliable performance rests on the corpus providing a fair, unbiased measure of wild aerial road-damage grounding. The manuscript states the data are 'professionally annotated' and evaluations use 'the same per-class AP_50 metric' under a 'unified prompting, decoding and parsing pipeline,' yet supplies no details on damage class definitions, annotation guidelines, inter-annotator agreement, image selection criteria (altitude, weather, occlusion), or class balance. This is load-bearing; without these, the reported gaps (frontier models leaving >50% on the table, open-source collapse on small targets) cannot be confidently attributed to model limitations rather than testbed artifacts.
Authors: We agree that these details are load-bearing for interpreting the reported performance gaps. The original manuscript emphasized the dual-track protocols and results while keeping the data section concise; the full annotation protocol was documented internally but not expanded in the main text. In the revised manuscript we will add a dedicated subsection (or appendix) that specifies: (1) exact definitions and visual examples for each damage class, (2) the annotation guidelines given to the professional annotators, (3) inter-annotator agreement statistics (e.g., mean IoU and Cohen’s kappa on a double-annotated subset), (4) image selection criteria including altitude ranges, weather and lighting conditions, and occlusion levels chosen to capture realistic “wild” variability, and (5) per-class instance counts and balance statistics. These additions will make explicit that the corpus was constructed to reflect domain-specific challenges rather than to favor any particular model class. We have retained all original annotation records and can integrate this material without altering the reported numbers or conclusions. revision: yes
Circularity Check
No circularity: benchmark introduction with external evaluations
full rationale
This is a benchmark paper that collects a UAV corpus, defines evaluation protocols (VLM Track and Agent Track), and reports empirical results from existing models and agents. No derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. The central claims rest on measured performance gaps against a held-out set under a fixed pipeline, with no self-citation load-bearing steps or ansatz smuggling. The work is self-contained against external model benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- interaction budget for agents
axioms (1)
- domain assumption Professional annotations constitute reliable ground truth for per-class damage localization.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce WILDROADBENCH, a wild aerial road-damage grounding benchmark that couples direct visual grounding by vision-language models with autonomous research-and-engineering by LLM-driven agents on a single professionally annotated UAV corpus.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Introducing Claude Haiku 4.5. https://www.anthropic.com/news/ claude-haiku-4-5 , October 2025. System card available at https://anthropic.com/ claude-haiku-4-5-system-card
work page 2025
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report, 2025. URL https: //arxiv.org/abs/2502.13923. Qwen Team, Alibaba Group
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Eval- uating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Aleksander Madry, and Lilian Weng. MLE-bench: Evaluating machine learning agents on machine learning engineering.arXiv preprint arXiv:2410.07095, 2024. doi: 10.48550/ARXIV .2410.07095
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[7]
Xinbao Chen, Chang Liu, Long Chen, Xiaodong Zhu, Yaohui Zhang, and Chenxi Wang. A pavement crack detection and evaluation framework for a uav inspection system based on deep learning.Applied Sciences, 14(3):1157, 2024. doi: 10.3390/app14031157
-
[8]
Mark Everingham, Luc Van Gool, Christopher K. I. Williams, John Winn, and Andrew Zis- serman. The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88(2):303–338, 2010. doi: 10.1007/s11263-009-0275-4
-
[9]
Inês Feitosa, Bruno Santos, and Paulo J. G. Almeida. Pavement inspection in transport in- frastructures using unmanned aerial vehicles (uavs).Sustainability, 16(5):2207, 2024. doi: 10.3390/su16052207
-
[10]
Gemini 3: Introducing the latest Gemini AI model from Google
Google DeepMind. Gemini 3: Introducing the latest Gemini AI model from Google. https: //blog.google/products-and-platforms/products/gemini/gemini-3/ , November 2025
work page 2025
-
[11]
Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, Kefeng Zhang, Man Gao, Xi Su, Xiaodong Cai, Xunliang Cai, Yu Yang, and Yunke Zhao. Vitabench: Benchmarking llm agents with versatile interactive tasks in real-world applications.arXiv preprint arXiv:2509.26490, 2025
-
[12]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[13]
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara L. Berg. ReferItGame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 787–798, 2014. doi: 10.3115/v1/D14-1086. URLhttps://aclanthology.org/D14-1086/. 10
-
[14]
Kimi Team. Kimi-VL technical report, 2025. URLhttps://arxiv.org/abs/2504.07491
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations.International Journal of Computer Vision, 123(1):32–73, 2017. doi: 10.1007/s11263-016-0981-7
-
[16]
LLaV A-NeXT: Improved reasoning, OCR, and world knowledge.https://llava-vl
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. LLaV A-NeXT: Improved reasoning, OCR, and world knowledge.https://llava-vl. github.io/blog/2024-01-30-llava-next/, January 2024
work page 2024
-
[17]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision, 2024
work page 2024
-
[18]
Nano Claude Code: A lightweight python agent loop
Xinhao Ma. Nano Claude Code: A lightweight python agent loop. https://github.com/ mxh1999/nano-claude-code, 2024. Open-source reference implementation
work page 2024
-
[19]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024. URL https://arxiv. org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026. Public model idgpt-5.4-2026-03-05
work page 2026
-
[22]
Kosmos-2: Grounding multimodal large language models to the world
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Qixiang Ye, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. In International Conference on Learning Representations, 2024
work page 2024
-
[23]
Qwen3-VL technical report, 2025
Qwen Team. Qwen3-VL technical report, 2025. URL https://arxiv.org/abs/2511. 21631
work page 2025
-
[24]
Nazia Tasnim, Keanu Nichols, Yuting Yan, Nicholas Ikechukwu, Elva Zou, Deepti Ghadiyaram, and Bryan A. Plummer. Seeing isn’t orienting: A cognitively grounded benchmark reveals systematic orientation failures in MLLMs (DORI).arXiv preprint arXiv:2505.21649, 2025. URLhttps://arxiv.org/abs/2505.21649
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Chen Yang, Guanxin Lin, Youquan He, Peiyao Chen, Guanghe Liu, Yufan Mo, Zhouyuan Xu, Linhao Wang, Guohui Zhang, Zihang Zhang, Shenxiang Zeng, Chen Wang, and Jiansheng Fan. Thinking in structures: Evaluating spatial intelligence through reasoning on constrained manifolds (SSI-Bench).arXiv preprint arXiv:2602.07864, 2026. URL https://arxiv.org/ abs/2602.07864
-
[26]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-Agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[27]
Mmsi-bench: A benchmark for multi-image spatial intelligence.arXiv:2505.23764, 2025
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, et al. MMSI-Bench: A benchmark for multi-image spatial intelligence.arXiv preprint arXiv:2505.23764, 2025. URL https://arxiv.org/abs/2505. 23764
-
[28]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
work page 2023
-
[29]
URLhttps://openreview.net/forum?id=WE_vluYUL-X
OpenReview.net, 2023. URLhttps://openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[30]
Ferret: Refer and ground anything anywhere at any granularity
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity. InInternational Conference on Learning Representations, 2024. 11
work page 2024
-
[31]
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg. Modeling context in referring expressions. InEuropean Conference on Computer Vision (ECCV), pages 69–85, 2016. doi: 10.1007/978-3-319-46475-6_5
-
[32]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. URL https://arxiv.org/abs/2504.10479
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Pavement distress detection using convolutional neural networks with images captured via uav
Junqing Zhu, Jingtao Zhong, Tao Ma, Xiaoming Huang, Weiguang Zhang, and Yang Zhou. Pavement distress detection using convolutional neural networks with images captured via uav. Automation in Construction, 133:103991, 2022. doi: 10.1016/j.autcon.2021.103991
-
[35]
Pengfei Zhu, Longyin Wen, Dawei Du, Xiao Bian, Haibin Ling, Qinghua Hu, Qinqin Nie, Hao Cheng, et al. VisDrone-DET2018: The vision meets drone object detection in image challenge results. InEuropean Conference on Computer Vision (ECCV) Workshops, pages 437–468, 2018. doi: 10.1007/978-3-030-11021-5_27. Challenge results paper; full author list (60+) in the...
-
[36]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.