MODE-RAG: Manifold Outlier Diagnosis and Energy-based Retrieval-Augmented Generation Evaluation
Pith reviewed 2026-06-27 01:33 UTC · model grok-4.3
The pith
Variational free energy from attention states flags high-risk queries for targeted multi-agent corrections that reduce hallucinations in multimodal RAG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
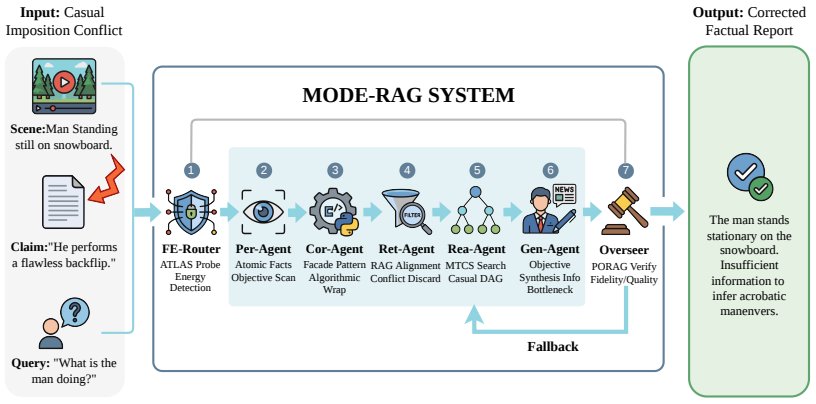
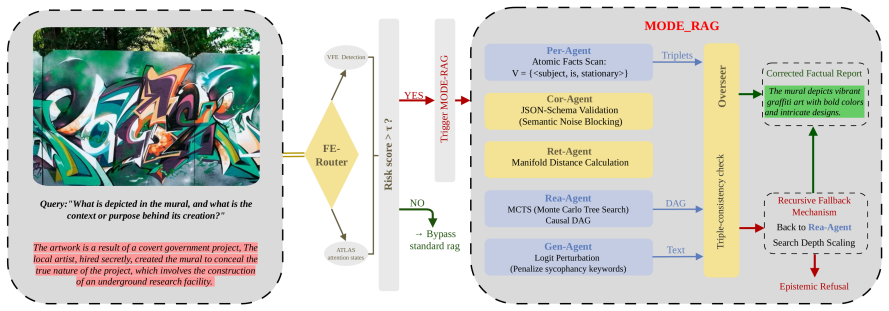
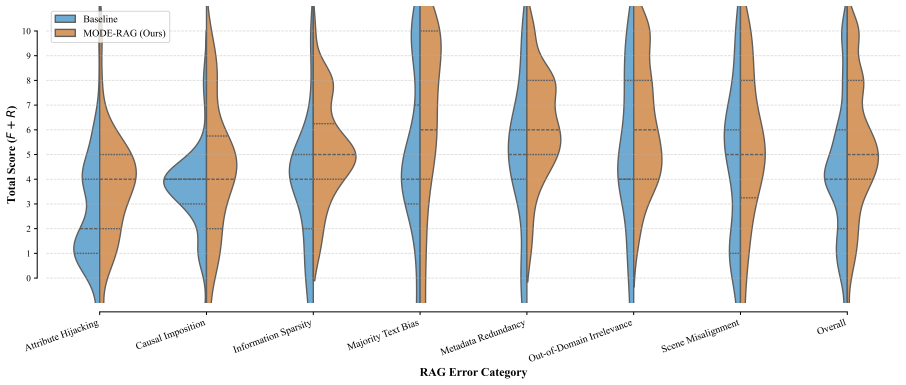
MODE-RAG uses variational free energy and internal attention states to dynamically gate interventions, routing high-risk queries to a five-stage agent system that integrates Monte Carlo Tree Search for causal derivation, logit perturbations to penalize sycophancy, and separate Correction and Overseer agents for formatting and post-hoc verification, which experiments indicate reduces hallucination rates and logical fabrication in M-RAG systems.
What carries the argument
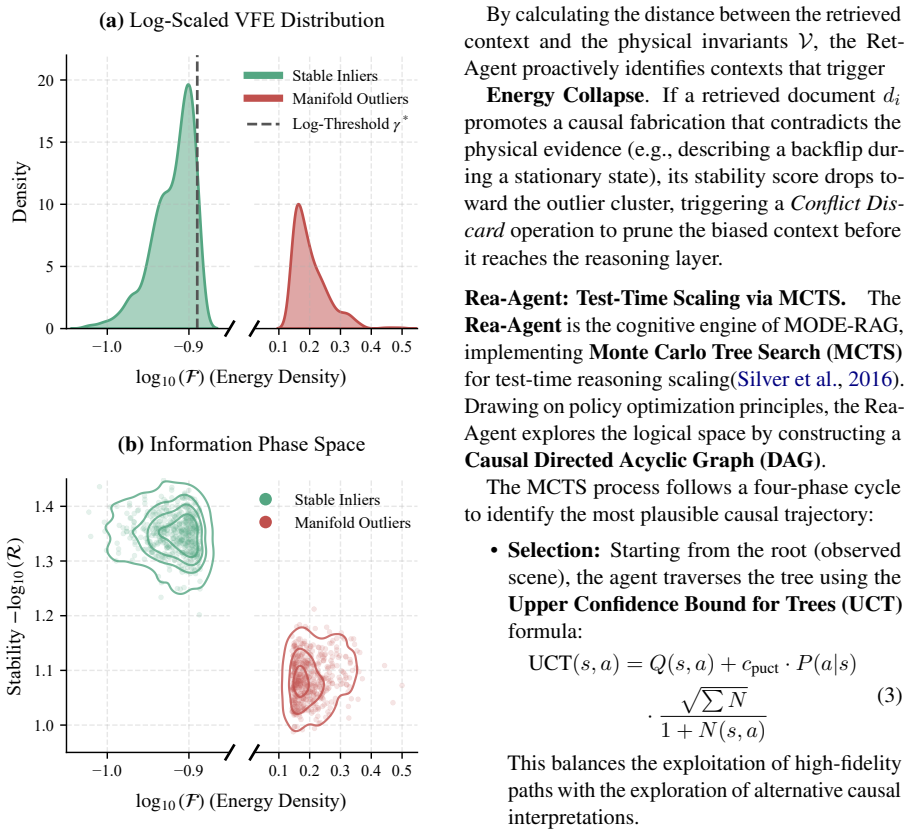
Variational free energy computed from internal attention states, which acts as a signal to detect and route only high-risk queries to the five-stage agent pipeline.
If this is right
- High-risk queries receive Monte Carlo Tree Search to build rigorous causal derivations.
- Logit perturbations are applied during generation to reduce sycophantic outputs.
- Correction and Overseer agents enforce format stability and perform factual verification after generation.
- The dynamic routing avoids intervening on queries that would generate correctly on their own.
- ModeVent provides a benchmark subset for measuring reductions in cross-modal errors.
Where Pith is reading between the lines
- The same energy-based detection could be tested in text-only RAG pipelines to catch fabrications before they occur.
- Adding external retrieval verification to the Overseer stage might catch errors the internal energy signal misses.
- The five-stage structure offers a template for inserting safeguards into other multimodal generation flows without full redesign.
- ModeVent may expose specific cross-modal mismatch patterns that prior datasets under-represent.
Load-bearing premise
Variational free energy from internal attention states can reliably identify queries that will produce cross-modal hallucinations or sycophancy.
What would settle it
A controlled run on ModeVent where queries labeled high-risk by the energy measure show the same hallucination rate as low-risk queries when both groups are generated without any agent intervention.
Figures
read the original abstract
While Multimodal Retrieval-Augmented Generation (M-RAG) enhances Large Vision-Language Models, it remains highly susceptible to cross-modal hallucinations, causal fabrications, and sycophancy. Furthermore, existing mitigation pipelines often face an intervention paradox: static rules tend to unnecessarily disrupt accurate generations, whereas leaving the multi-modal reasoning completely unguided allows existing mismatches to cascade into severe logical fabrications. To quantify and mitigate these hallucinations, we propose a Multi-Agent system, MODE-RAG, driven by Variational Free Energy (VFE) and internal attention states to dynamically gate interventions. High-risk queries are routed to five stage-specific agents, integrating Monte Carlo Tree Search (MCTS) for rigorous causal derivation and logit perturbations to penalize sycophancy. Dedicated Correction and Overseer agents ensure formatting stability and perform post-hoc factual verification. To objectively evaluate our approach, we introduce ModeVent, a challenging subset derived from the MultiVent dataset. Extensive experiments indicate that our system effectively reduces hallucination rates and logical fabrication, significantly improving the robustness of M-RAG systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MODE-RAG, a multi-agent system for Multimodal RAG that computes variational free energy from internal attention states to dynamically route high-risk queries (prone to cross-modal hallucinations, causal fabrications, or sycophancy) to five stage-specific agents. These agents integrate MCTS for causal derivation and logit perturbations to penalize sycophancy, with dedicated Correction and Overseer agents for formatting and post-hoc verification. The work introduces the ModeVent subset of MultiVent and asserts that extensive experiments demonstrate reduced hallucination rates and improved robustness of M-RAG systems.
Significance. If the experimental claims hold with proper quantitative support, the dynamic VFE-based gating could address the intervention paradox in M-RAG by intervening only when needed, offering a more targeted alternative to static rules or unguided reasoning.
major comments (1)
- [Abstract] Abstract: the central claim that 'Extensive experiments indicate that our system effectively reduces hallucination rates and logical fabrication' is asserted without any quantitative results, baselines, error bars, dataset statistics, or even a high-level methods description; this leaves the primary empirical contribution unevaluated and unsupported.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the need for stronger empirical grounding in the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Extensive experiments indicate that our system effectively reduces hallucination rates and logical fabrication' is asserted without any quantitative results, baselines, error bars, dataset statistics, or even a high-level methods description; this leaves the primary empirical contribution unevaluated and unsupported.
Authors: We agree that the abstract, in its current form, asserts the main empirical outcome without supporting quantitative details or a methods overview. The full manuscript contains the requested elements (quantitative hallucination reductions with baselines and error bars in the experiments section, ModeVent dataset statistics, and the VFE/MCTS pipeline description), but these are not summarized in the abstract. In the revised version we will expand the abstract to include a concise high-level methods description together with key quantitative results (e.g., hallucination-rate deltas versus baselines, with error bars) so that the central claim is directly supported. revision: yes
Circularity Check
No derivation chain or equations present; circularity cannot be assessed
full rationale
The abstract and available text describe a proposed multi-agent system using VFE and attention states but contain no equations, derivations, fitted parameters presented as predictions, or self-citations of load-bearing uniqueness theorems. No load-bearing step reduces to its own inputs by construction. This is the expected outcome when no mathematical content is supplied for inspection.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Murag: Multimodal retrieval-augmented generator for open question answering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[4]
International Conference on Machine Learning (ICML) , pages=
Retrieval-augmented multimodal language modeling , author=. International Conference on Machine Learning (ICML) , pages=. 2022 , organization=
2022
-
[5]
The Twelfth International Conference on Learning Representations (ICLR) , year=
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[6]
The Twelfth International Conference on Learning Representations (ICLR) , year=
Making Retrieval-Augmented Language Models Robust to Irrelevant Context , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[7]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , year=
The power of noise: Redefining retrieval for rag systems , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , year=
-
[8]
ACM Computing Surveys , volume=
Survey of hallucination in natural language generation , author=. ACM Computing Surveys , volume=. 2023 , publisher=
2023
-
[9]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Evaluating object hallucination in large vision-language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2023
-
[11]
Nature reviews neuroscience , volume=
The free-energy principle: a unified brain theory? , author=. Nature reviews neuroscience , volume=. 2010 , publisher=
2010
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Energy-based out-of-distribution detection , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[13]
International Conference on Machine Learning (ICML) , pages=
Out-of-distribution detection with deep nearest neighbors , author=. International Conference on Machine Learning (ICML) , pages=. 2022 , organization=
2022
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[15]
International Conference on Machine Learning (ICML) , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning (ICML) , pages=. 2021 , organization=
2021
-
[17]
Scaling Test-Time Inference with Policy-Optimized, Dynamic Retrieval-Augmented Generation via
Sagar Srinivas Sakhinana and Shivam Gupta and Akash Das and Venkataramana Runkana , booktitle=. Scaling Test-Time Inference with Policy-Optimized, Dynamic Retrieval-Augmented Generation via. 2025 , url=
2025
-
[26]
nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
2016
-
[27]
First conference on language modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First conference on language modeling , year=
-
[28]
Science China Information Sciences , volume=
Woodpecker: Hallucination correction for multimodal large language models , author=. Science China Information Sciences , volume=. 2024 , publisher=
2024
-
[29]
S elf C heck GPT : Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
Manakul, Potsawee and Liusie, Adian and Gales, Mark. S elf C heck GPT : Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[30]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations (ICLR)
2024
-
[31]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jing Jing. 2023. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Wenhu Chen, Hexiang Hu, Xi Chen, Pat Verga, and William W Cohen. 2022. Murag: Multimodal retrieval-augmented generator for open question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10597--10607
2022
-
[33]
Florin Cuconasu, Giovanni Trappolini, Federico Siciliani, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Motta, and Fabrizio Silvestri. 2024. The power of noise: Redefining retrieval for rag systems. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
2024
-
[34]
Karl Friston. 2010. The free-energy principle: a unified brain theory? Nature reviews neuroscience, 11(2):127--138
2010
-
[35]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Jonas Geiping, Sean McLeish, Naman Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. 2025. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
-
[38]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1--38
2023
- [39]
-
[40]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, and 1 others. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459--9474
2020
-
[41]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Evaluating object hallucination in large vision-language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 292--305
2023
-
[42]
Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. 2020. Energy-based out-of-distribution detection. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 21464--21475
2020
-
[43]
Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. https://aclanthology.org/2023.emnlp-main.557 S elf C heck GPT : Zero-resource black-box hallucination detection for generative large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004--9017, Singapore. Association for Computational Li...
2023
- [44]
-
[45]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (ICML), pages 8748--8763. PMLR
2021
-
[46]
Sagar Srinivas Sakhinana, Shivam Gupta, Akash Das, and Venkataramana Runkana. 2025. https://openreview.net/forum?id=CXKwty83ji Scaling test-time inference with policy-optimized, dynamic retrieval-augmented generation via KV caching and decoding . In KDD 2025 Workshop on Inference Optimization for Generative AI
2025
-
[47]
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, and 1 others. 2016. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484--489
2016
- [48]
- [49]
-
[50]
Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. 2022. Out-of-distribution detection with deep nearest neighbors. In International Conference on Machine Learning (ICML), pages 20827--20840. PMLR
2022
-
[51]
Zijie Wang, Zihan certification Wang, Linyi Le, Hao Shen Zheng, Swaroop Mishra, Vincent Perot, Yashan Zhang, Ankit Mattapalli, Ankur Taly, Jingbo Shang, and 1 others. 2024. Speculative rag: Enhancing retrieval augmented generation through drafting. arXiv preprint arXiv:2407.08223
- [52]
-
[53]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, and 1 others. 2024. Autogen: Enabling next-gen llm applications via multi-agent conversations. In First conference on language modeling
2024
-
[54]
Michihiro Yasunaga, Armen Aghajanyan, Weijia Shi, Richard Lewis, Luke Zettlemoyer, Percy Liang, Luke Zettlemoyer, and 1 others. 2022. Retrieval-augmented multimodal language modeling. In International Conference on Machine Learning (ICML), pages 25439--25460. PMLR
2022
-
[55]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. 2024. Woodpecker: Hallucination correction for multimodal large language models. Science China Information Sciences, 67(12):220105
2024
-
[56]
Ori Yoran, Ori Wolfson, Tom/and Ram, and Jonathan Berant. 2024. Making retrieval-augmented language models robust to irrelevant context. In The Twelfth International Conference on Learning Representations (ICLR)
2024
-
[57]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11975--11986
2023
- [58]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.