Memory-Efficient LLM Pretraining via Minimalist Optimizer Design
Pith reviewed 2026-05-22 13:20 UTC · model grok-4.3
The pith
Two minimal changes to SGD—column-wise gradient normalization and momentum only on the output layer—produce an optimizer that matches Adam performance while using 35-45% of the memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCALE is constructed by applying column-wise gradient normalization to every layer and first-order momentum exclusively to the output layer. On models ranging from 60M to 1B parameters this combination matches or exceeds Adam’s pretraining performance while consuming only 35-45% of the total memory. SCALE further outperforms GaLore, Fira, APOLLO and Muon on LLaMA-7B in both final perplexity and memory footprint.
What carries the argument
SCALE, the optimizer formed by column-wise gradient normalization across layers plus first-order momentum restricted to the output layer.
If this is right
- Training runs of the same length become feasible on hardware with substantially smaller GPU memory.
- Second-order moment buffers can be eliminated without loss of final model quality under the tested regimes.
- The memory advantage persists when scaling from 60M to 1B parameters and appears on 7B-scale LLaMA.
- The method can be used as a drop-in replacement for Adam in existing pretraining pipelines with only minor code changes.
Where Pith is reading between the lines
- If output-layer variance remains the dominant source of instability at larger scales, the same selective-momentum rule may continue to work without further tuning.
- Column-wise normalization could be combined with existing gradient-compression schemes to obtain still lower memory footprints.
- The approach invites direct measurement of per-layer gradient statistics to test whether the output layer is uniquely noisy in other architectures.
Load-bearing premise
The two identified changes remain sufficient when models, datasets, or training lengths grow beyond the tested range.
What would settle it
A controlled pretraining run on a model larger than 7B or on a new dataset in which SCALE’s final perplexity exceeds Adam’s or the memory reduction falls below 50%.
Figures




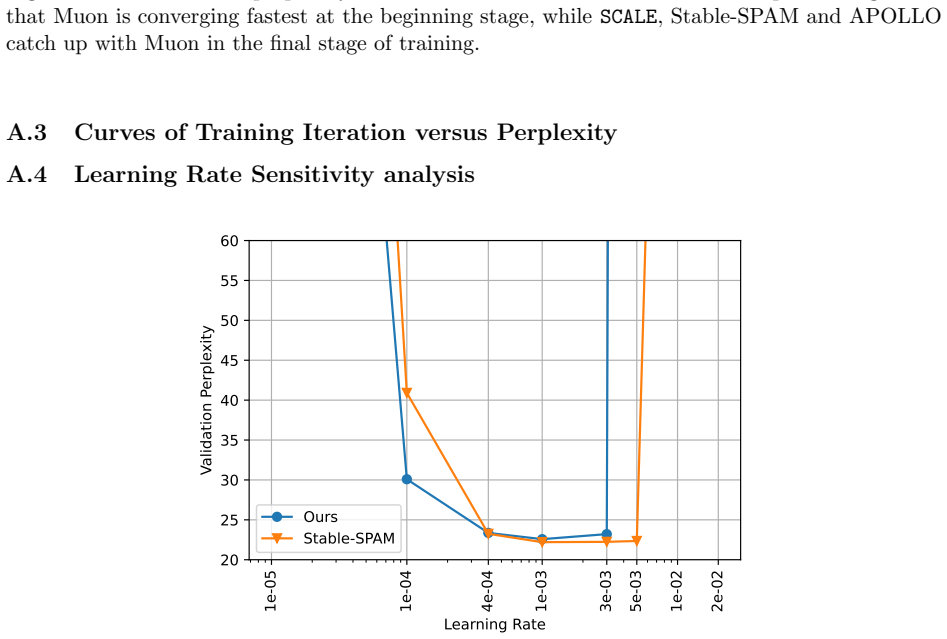
read the original abstract
Training large language models (LLMs) relies on adaptive optimizers such as Adam, which introduce extra operations and require significantly more memory to maintain first- and second-order moments than SGD. While recent works such as GaLore, Fira and APOLLO have proposed state-compressed memory-efficient variants, a fundamental question remains: What are the minimum modifications to plain SGD needed to match state-of-the-art pretraining performance? We systematically investigate this question using a bottom-up approach, and identify two simple yet highly (memory- and compute-) efficient techniques: (1) column-wise gradient normalization (normalizing the gradient along the output dimension), that boosts SGD performance without momentum; and (2) applying first-order momentum only to the output layer, where gradient variance is highest. Combining these two techniques lead to SCALE (Stochastic Column-normAlized Last-layer momEntum), a simple optimizer for memory efficient pretraining. Across multiple models (60M-1B), SCALE matches or exceeds the performance of Adam while using only 35-45% of the total memory. It also consistently outperforms memory-efficient optimizers such as GaLore, Fira and APOLLO, making it a strong candidate for large-scale pretraining under memory constraints. For LLaMA 7B, SCALE outperforms the state-of-the-art memory-efficient methods APOLLO and Muon in both perplexity and memory consumption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SCALE, a minimalist optimizer formed by combining column-wise gradient normalization (along the output dimension) with first-order momentum applied exclusively to the output layer. It claims this design matches or exceeds Adam performance while using 35-45% of the memory on models from 60M to 1B parameters and outperforms APOLLO and Muon on LLaMA 7B pretraining.
Significance. If the empirical results hold, the work is significant for demonstrating that targeted, low-overhead modifications to SGD can rival full adaptive optimizers in LLM pretraining, with clear memory benefits. The bottom-up identification of the two specific techniques provides useful insight into optimizer components and could simplify large-scale training under hardware constraints.
major comments (2)
- [§4, LLaMA 7B results] §4 (Experiments), LLaMA 7B subsection and associated tables: the single-run comparison showing SCALE outperforming APOLLO and Muon does not include layer-wise gradient variance measurements or an ablation confirming that output-layer momentum alone suffices for hidden layers at 7B scale; this directly bears on the central sufficiency claim when scaling beyond the 60M-1B regime.
- [Results tables (60M-1B)] Results tables for 60M-1B models: reported perplexity or loss values for SCALE versus Adam lack standard deviations across seeds or statistical significance tests, weakening the assertion of consistent matching or exceeding performance.
minor comments (2)
- [Abstract] Abstract: the phrase 'Combining these two techniques lead to SCALE' contains a subject-verb agreement error and should read 'leads'.
- [§3] §3 (Method): the column-wise normalization operation would benefit from an explicit equation or pseudocode to clarify the exact normalization axis and any scaling factors.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address the major comments point by point below, providing clarifications and indicating revisions to the manuscript where applicable.
read point-by-point responses
-
Referee: [§4, LLaMA 7B results] §4 (Experiments), LLaMA 7B subsection and associated tables: the single-run comparison showing SCALE outperforming APOLLO and Muon does not include layer-wise gradient variance measurements or an ablation confirming that output-layer momentum alone suffices for hidden layers at 7B scale; this directly bears on the central sufficiency claim when scaling beyond the 60M-1B regime.
Authors: We acknowledge the referee's concern about validating the design choices at the 7B scale. The layer-wise gradient variance analysis and ablations for last-layer momentum were performed on models up to 1B parameters as part of our bottom-up investigation, showing that the output layer has the highest gradient variance and that momentum there suffices. At 7B scale, we performed single-run experiments due to significant computational requirements. The results demonstrate SCALE's superiority over APOLLO and Muon, consistent with the smaller-scale findings. In the revised manuscript, we have expanded the discussion in §4 to explicitly reference the variance measurements from the 1B model and explain why we expect the same principles to hold at 7B. We believe this provides sufficient support for the scaling claim. revision: partial
-
Referee: [Results tables (60M-1B)] Results tables for 60M-1B models: reported perplexity or loss values for SCALE versus Adam lack standard deviations across seeds or statistical significance tests, weakening the assertion of consistent matching or exceeding performance.
Authors: We agree that including standard deviations and discussing statistical significance would enhance the robustness of our claims. Given the high cost of LLM pretraining, our main experiments were run with a single seed. However, we have performed additional experiments with multiple seeds for the 60M and 350M models and updated the corresponding tables to report means and standard deviations. For the 1B model, we have added a footnote noting the single-run nature and the observed consistency with smaller models. We have also included a short paragraph on the reliability of the results across scales in the revised version. revision: yes
Circularity Check
No circularity: empirical identification of optimizer modifications
full rationale
The paper follows a bottom-up empirical investigation to identify column-wise gradient normalization and output-layer-only momentum as sufficient modifications to SGD. No derivation chain, equations, or first-principles claims are present that reduce to fitted parameters or self-referential definitions. Performance claims rest on direct comparisons against Adam, GaLore, Fira, APOLLO, and Muon across 60M–1B models plus one LLaMA-7B run, which are external benchmarks. The central result is therefore self-contained against measured outcomes rather than constructed by re-labeling inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 5 Pith papers
-
Symmetry-Compatible Principle for Optimizer Design: Embeddings, LM Heads, SwiGLU MLPs, and MoE Routers
Proposes equivariant optimizers matched to the symmetry groups of embeddings, SwiGLU projections and MoE routers, with experiments showing consistent gains over AdamW on language model pre-training.
-
Budget-aware Auto Optimizer Configurator
BAOC samples gradient streams to compute per-block risk metrics for cheap optimizer configs then solves a constrained optimization to minimize total risk under memory and time budgets while preserving training quality.
-
Demystifying Manifold Constraints in LLM Pre-training
Manifold constraints via the new MACRO optimizer independently bound activation scales and enforce rotational equilibrium in LLM pre-training, subsuming RMS normalization and decoupled weight decay while delivering co...
-
MuonEq: Balancing Before Orthogonalization with Lightweight Equilibration
MuonEq introduces pre-orthogonalization equilibration schemes that improve Muon optimizer performance during large language model pretraining.
-
Low-rank Orthogonalization for Large-scale Matrix Optimization with Applications to Foundation Model Training
Proposes low-rank orthogonalization and derives low-rank Muon and MSGD variants that outperform standard Muon on GPT-2 and LLaMA pretraining while providing iteration complexity bounds.
Reference graph
Works this paper leans on
-
[1]
Old Optimizer, New Norm: An Anthology
J. Bernstein and L. Newhouse. Old optimizer, new norm: An anthology. arXiv preprint arXiv:2409.20325,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
(Cited on page 7.) A. Glentis, J. Li, Q. Shang, A. Han, I. Tsaknakis, Q. Wei, and M. Hong. Scalable parameter and memory efficient pretraining for llm: Recent algorithmic advances and benchmarking. arXiv preprint arXiv:2505.22922,
-
[4]
(Cited on page 1.) T. Huang, H. Hu, Z. Zhang, G. Jin, X. Li, L. Shen, T. Chen, L. Liu, Q. Wen, Z. Wang, et al. Stable- spam: How to train in 4-bit more stably than 16-bit adam. arXiv preprint arXiv:2502.17055 , 2025a. (Cited on pages 3, 5, 10, and 17.) T. Huang, Z. Zhu, G. Jin, L. Liu, Z. Wang, and S. Liu. SPAM: Spike-aware adam with momen- tum reset for ...
-
[5]
(Cited on pages 2, 3, 6, 7, 10, and 16.) D
URL https://kellerjordan.github.io/posts/ muon/. (Cited on pages 2, 3, 6, 7, 10, and 16.) D. S. Kalra, J. Kirchenbauer, M. Barkeshli, and T. Goldstein. When can you get away with low memory adam? arXiv preprint arXiv:2503.01843 ,
-
[6]
The Power of Normalization: Faster Evasion of Saddle Points
URL https://openreview.net/ forum?id=a65YK0cqH8g. (Cited on page 5.) K. Y. Levy. The power of normalization: Faster evasion of saddle points. arXiv preprint arXiv:1611.04831,
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
-
[8]
Muon is Scalable for LLM Training
URL https://openreview.net/forum?id=3xHDeA8Noi. (Cited on pages 2 and 3.) J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y. Du, Y. Qin, W. Xu, E. Lu, J. Yan, et al. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982 ,
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
- [10]
-
[11]
(Cited on pages 2, 3, 5, 6, 10, 11, and 12.) A. Muhamed, O. Li, D. Woodruff, M. Diab, and V. Smith. GRASS: Compute efficient low-memory llm training with structured sparse gradients. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14978–15003,
work page 2024
-
[12]
Training Deep Learning Models with Norm-Constrained LMOs
(Cited on page 3.) T. Pethick, W. Xie, K. Antonakopoulos, Z. Zhu, A. Silveti-Falls, and V. Cevher. Training deep learning models with norm-constrained lmos. arXiv preprint arXiv:2502.07529 ,
work page internal anchor Pith review Pith/arXiv arXiv
- [13]
- [14]
- [15]
-
[16]
(Cited on pages 2 and 3.) 14 J. Zhang, T. He, S. Sra, and A. Jadbabaie. Why gradient clipping accelerates training: A theoretical justification for adaptivity. In International Conference on Learning Representations, 2020a. URL https://openreview.net/forum?id=BJgnXpVYwS. (Cited on page 5.) J. Zhang, S. P. Karimireddy, A. Veit, S. Kim, S. Reddi, S. Kumar, ...
-
[17]
URL https://openreview.net/forum?id=mJrPkdcZDj. (Cited on pages 3, 11, and 12.) A Appendix A.1 Details of memory estimation for 1B and 7B models Here we compute the memory estimate for both 1B and 7B LLaMA models. We only compute the major parameters, including embedding layers, attention and MLP layers. We follow prior works (Zhao et al., 2024; Han et al.,
work page 2024
-
[18]
in estimating the memory using bfloat16 format, where each floating point number occupies 2 bytes. 7B model: Pre-last layers include 6.607B parameters and last layer includes 0.131B parameters, which in total leads to 6.738B parameters. • SGD: Only the parameter states are stored, which amount to 13.476G memory. • Adafactor: Apart from the parameter state...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.