Learning from Mistakes: Rollout-Retrieval Lifelong Policy Learning for Autonomous Driving
Pith reviewed 2026-06-30 05:11 UTC · model grok-4.3
The pith
A driving policy improves continually by retrieving corrective targets from its own recoverable closed-loop mistakes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
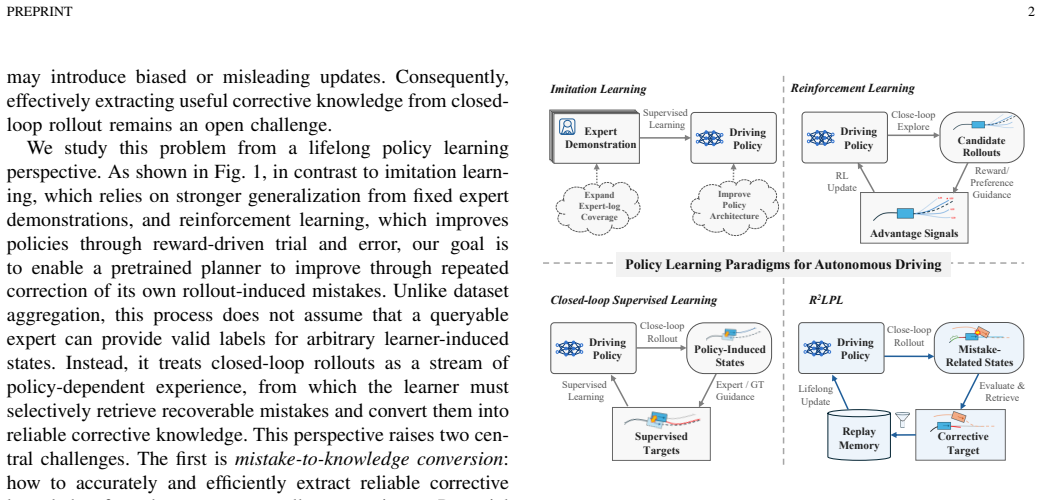
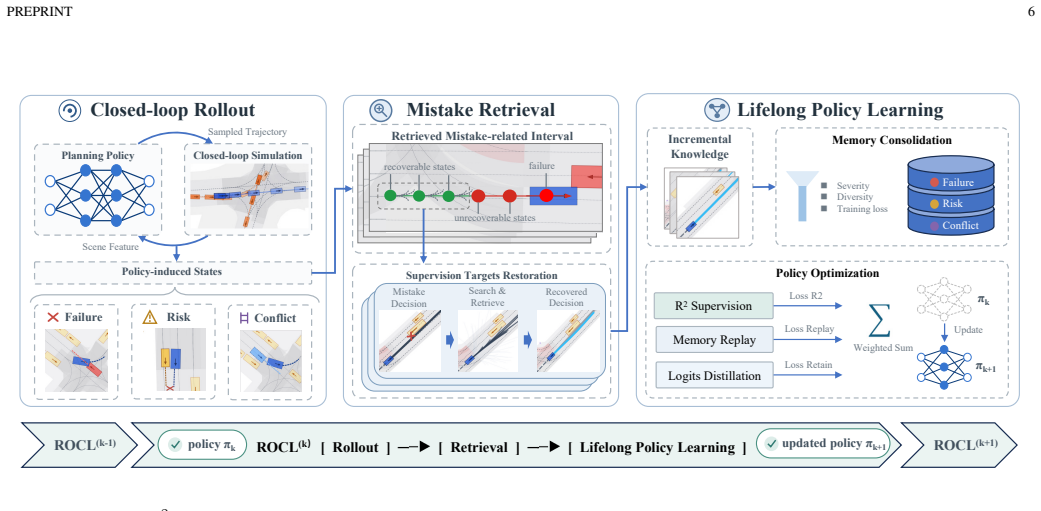
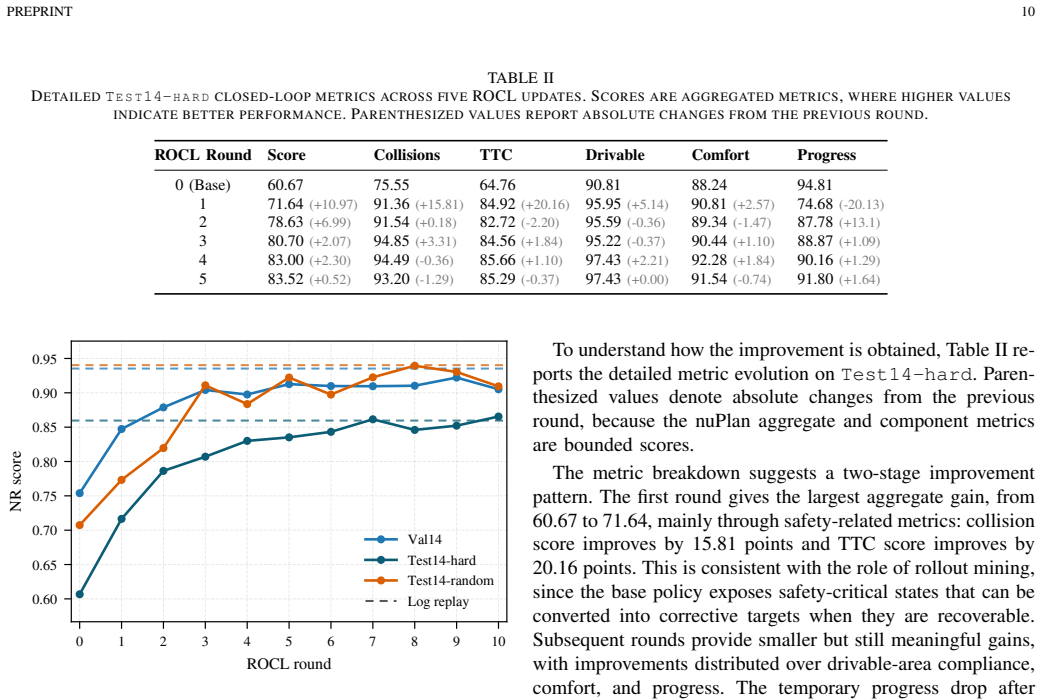
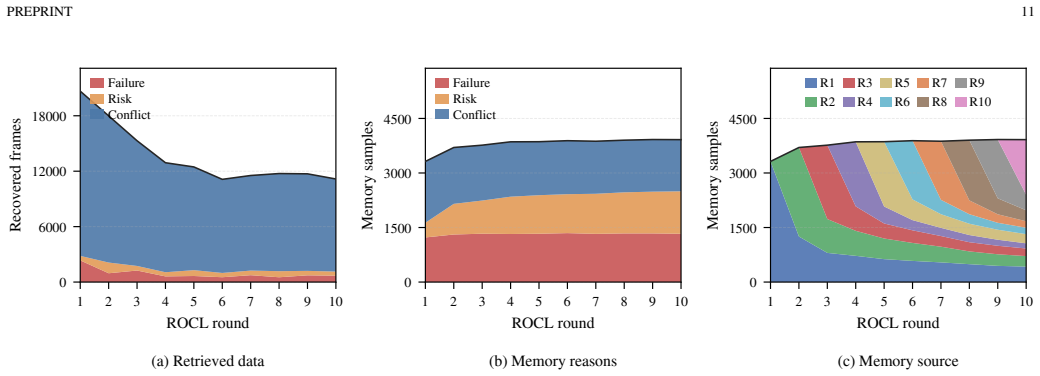
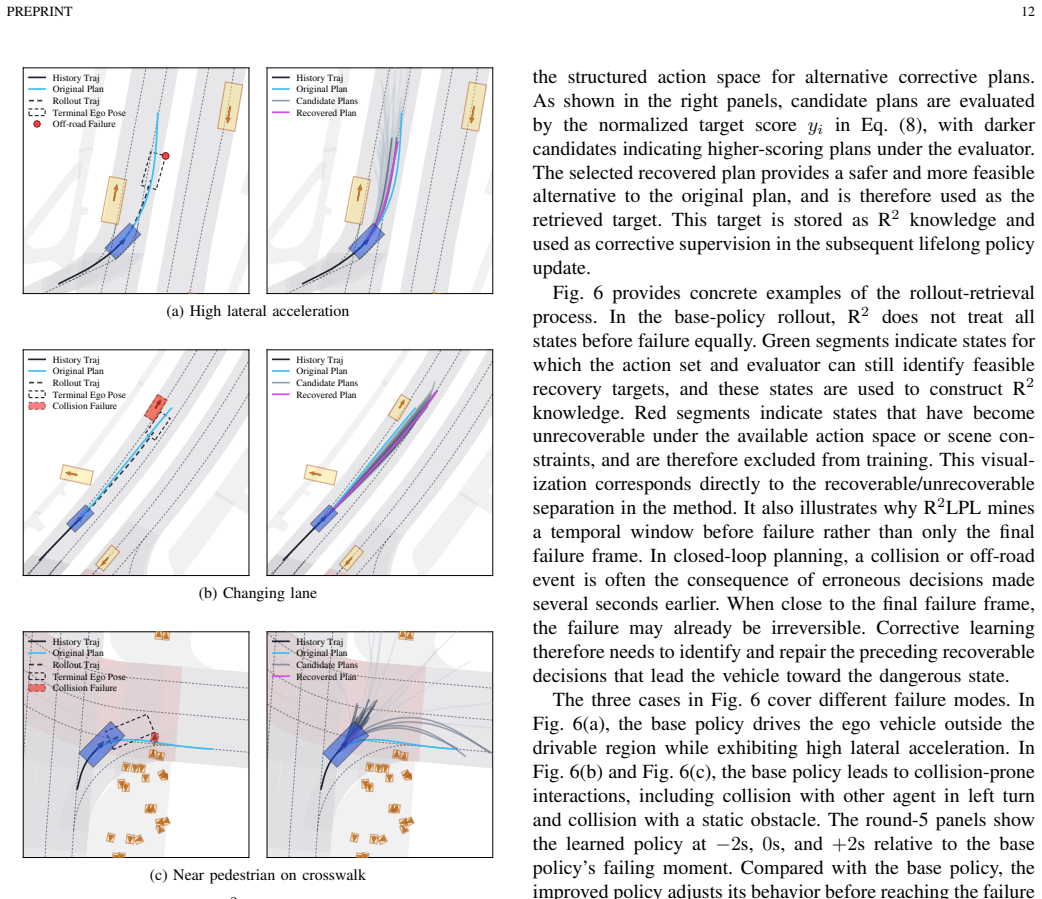
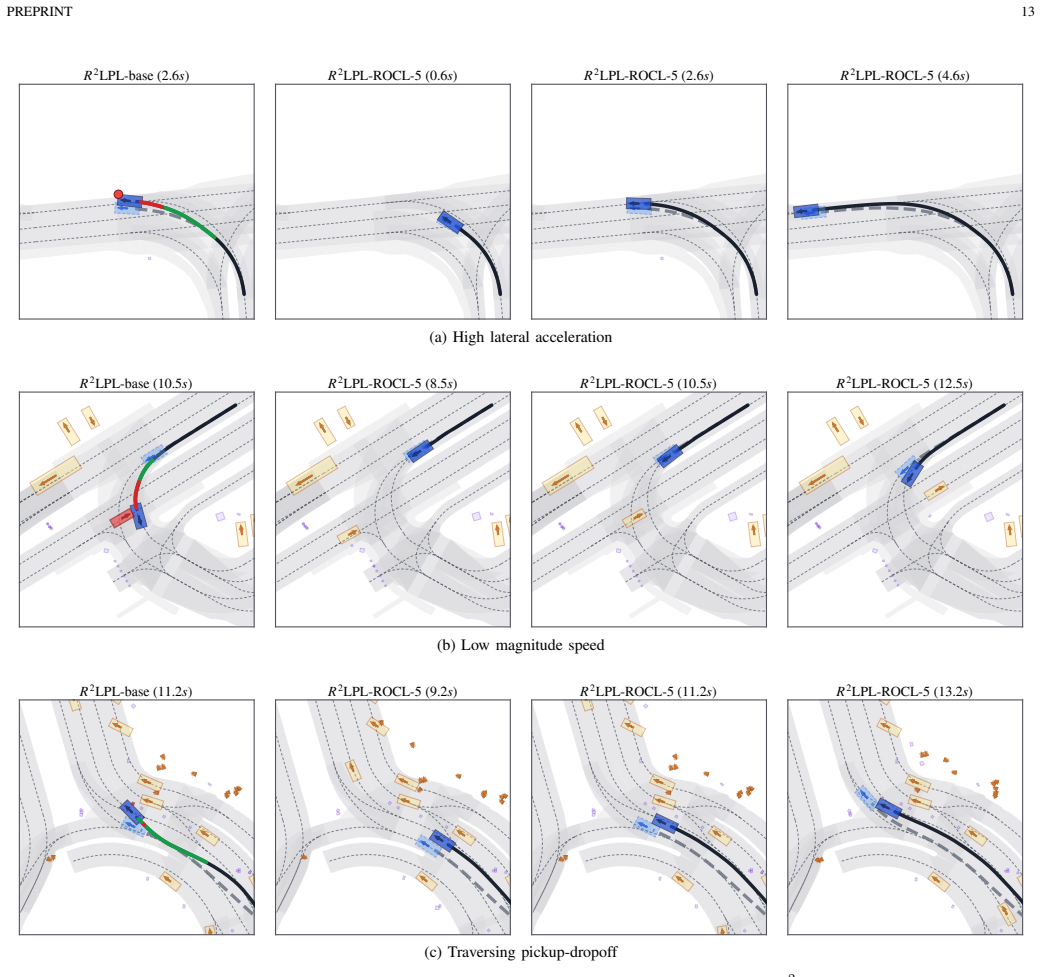
R²LPL addresses the bottleneck that closed-loop mistakes reveal where the policy is weak but do not directly specify what the policy should learn. By filtering recoverable mistake-related states and retrieving feasible corrective targets, R²LPL turns sparse failure evidence into compact supervised knowledge for stable and sample-efficient policy improvement. On large-scale closed-loop nuPlan benchmarks, only a few rollout and continual-learning cycles elevate a moderate initial policy to state-of-the-art performance, especially on the challenging Test14-hard split.
What carries the argument
Rollout-Retrieval Lifelong Policy Learning (R²LPL), which filters recoverable mistake-related states and retrieves feasible corrective targets to create supervised learning signals while retaining prior competence through lifelong updates.
If this is right
- Moderate policies reach state-of-the-art results across nuPlan benchmarks with few cycles.
- Gains are largest on long-tail and challenging splits.
- Closed-loop mistakes become a direct source of compact supervised training data.
- Policy updates remain stable without catastrophic forgetting.
Where Pith is reading between the lines
- The same mistake-to-correction retrieval pattern could apply to other robotic control domains where failures are recoverable.
- It reduces dependence on fresh expert demonstrations by generating training targets from the policy itself.
Load-bearing premise
Recoverable mistakes can be filtered and matched to feasible corrective targets to produce reliable supervised signals that improve the policy without causing forgetting or instability.
What would settle it
After several rollout and learning cycles on the nuPlan Test14-hard split, the policy shows no performance gain over the initial moderate level or exhibits increased instability or forgetting.
Figures
read the original abstract
Autonomous driving policies should be able to improve continually as deployment exposes them to increasingly diverse and long-tail traffic situations. However, most learning-based policies are trained or fine-tuned on expert demonstrations and then rely largely on generalization to handle challenging closed-loop scenarios, lacking an explicit mechanism to correct and retain the mistakes exposed in these scenarios. This paper studies autonomous driving policy improvement from a lifelong learning perspective: Can a pretrained policy improve continually by accumulating corrective knowledge derived from its own mistakes, while retaining previously acquired driving competence? To answer this question, we propose Rollout-Retrieval Lifelong Policy Learning (R$^2$LPL), a policy learning framework that retrieves corrective targets from recoverable policy-induced mistakes and retains the resulting knowledge through lifelong policy learning. R^2LPL addresses a key bottleneck in continual policy improvement: closed-loop mistakes reveal where the policy is weak, but do not directly specify what the policy should learn. By filtering recoverable mistake-related states and retrieving feasible corrective targets, R$^2$LPL turns sparse failure evidence into compact supervised knowledge for stable and sample-efficient policy improvement. We evaluate R$^2$LPL on large-scale closed-loop nuPlan benchmarks. With only a few rollout and continual-learning cycles, R$^2$LPL elevates a learning-based planner with moderate initial performance to state-of-the-art performance across the evaluated benchmarks, especially on the challenging and long-tail Test14-hard split. These results demonstrate the effectiveness of R$^2$LPL in converting recoverable closed-loop mistakes into corrective knowledge for sustained policy improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rollout-Retrieval Lifelong Policy Learning (R²LPL), a framework that filters recoverable mistake-related states from closed-loop policy rollouts, retrieves feasible corrective targets, and uses the resulting supervised signals for continual policy improvement while retaining prior competence. It claims that a few rollout-plus-learning cycles suffice to elevate a moderate initial learning-based planner to state-of-the-art closed-loop performance on large-scale nuPlan benchmarks, especially the long-tail Test14-hard split.
Significance. If the filtering/retrieval mechanism reliably converts sparse failure traces into stable corrective supervision without inducing forgetting or closed-loop instability, the approach would address a practical bottleneck in deployment-time policy improvement for autonomous driving and could generalize to other robotics domains that rely on lifelong correction from real-world mistakes.
major comments (3)
- [Abstract, §5] Abstract and §5 (Evaluation): the central claim that R²LPL reaches SOTA on Test14-hard after only a few cycles is stated without any quantitative results, tables, error bars, baseline comparisons, or ablation numbers; the performance elevation cannot be assessed from the supplied text.
- [§3] §3 (Method): the recoverability criteria used to filter mistake-related states and the source of corrective targets are not specified; without these definitions the claim that sparse failures are turned into compact supervised knowledge remains unsupported and load-bearing for the entire pipeline.
- [§4] §4 (Lifelong retention): no description is given of the mechanism (replay buffer, regularization, parameter isolation, etc.) that prevents catastrophic forgetting; the assertion of stable retention after new cycles therefore lacks any reported check or metric.
minor comments (2)
- [§3] Notation for the retrieval function and the lifelong loss is introduced without an explicit equation or pseudocode block, making the algorithmic flow harder to follow.
- [§5] The nuPlan benchmark splits (including Test14-hard) are referenced but not characterized with respect to scenario diversity or failure modes, which would help interpret the long-tail emphasis.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract, §5] Abstract and §5 (Evaluation): the central claim that R²LPL reaches SOTA on Test14-hard after only a few cycles is stated without any quantitative results, tables, error bars, baseline comparisons, or ablation numbers; the performance elevation cannot be assessed from the supplied text.
Authors: We agree that the abstract and §5 would benefit from explicit quantitative support. In the revision we will add key performance metrics, tables with error bars, baseline comparisons, and ablation results to the abstract and §5 so that the SOTA claims on nuPlan (including Test14-hard) can be directly assessed. revision: yes
-
Referee: [§3] §3 (Method): the recoverability criteria used to filter mistake-related states and the source of corrective targets are not specified; without these definitions the claim that sparse failures are turned into compact supervised knowledge remains unsupported and load-bearing for the entire pipeline.
Authors: We acknowledge the need for explicit definitions. The revised §3 will specify the recoverability criteria for filtering mistake-related states and detail the source and retrieval mechanism for corrective targets, thereby grounding the conversion of failure traces into supervised signals. revision: yes
-
Referee: [§4] §4 (Lifelong retention): no description is given of the mechanism (replay buffer, regularization, parameter isolation, etc.) that prevents catastrophic forgetting; the assertion of stable retention after new cycles therefore lacks any reported check or metric.
Authors: We agree that the retention mechanism must be described. The revised §4 will specify the technique employed to avoid catastrophic forgetting and will include retention metrics or verification checks after each learning cycle. revision: yes
Circularity Check
No circularity in derivation; claims rest on empirical benchmarks
full rationale
The abstract and provided text describe R²LPL at a conceptual level without any equations, parameter-fitting steps, self-citations, or mathematical derivations. The central claim—that filtering mistakes and retrieving targets yields stable improvement—is presented as an empirical outcome from nuPlan evaluations rather than a result derived by construction from its own inputs. No load-bearing step reduces to a fit, renaming, or self-referential definition. This is the expected non-finding for a high-level methods paper whose evidence is benchmark performance.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards learning-based planning: The nuplan benchmark for real-world autonomous driving,
N. Karnchanachari, D. Geromichalos, K. S. Tan, N. Li, C. Eriksen, S. Yaghoubi, N. Mehdipour, G. Bernasconi, W. K. Fong, Y . Guo, and H. Caesar, “Towards learning-based planning: The nuplan benchmark for real-world autonomous driving,” inProceedings of the IEEE Inter- national Conference on Robotics and Automation, 2024, pp. 629–636
2024
-
[2]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta, “Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 28 706–28 719
2024
-
[3]
Planning- oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, L. Lu, X. Jia, Q. Liu, J. Dai, Y . Qiao, and H. Li, “Planning- oriented autonomous driving,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2023, pp. 17 853– 17 862
2023
-
[4]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2023
2023
-
[5]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10 164– 10 183, 2024
2024
-
[6]
PLUTO: Pushing the limit of imi- tation learning-based planning for autonomous driving,
J. Cheng, Y . Chen, and Q. Chen, “PLUTO: Pushing the limit of imi- tation learning-based planning for autonomous driving,”arXiv preprint arXiv:2404.14327, 2024
-
[7]
Sparsedrive: End-to-end autonomous driving via sparse scene representation,
W. Sun, X. Lin, Y . Shi, C. Zhang, H. Wu, and S. Zheng, “Sparsedrive: End-to-end autonomous driving via sparse scene representation,” in Proceedings of the IEEE International Conference on Robotics and Automation, 2025, pp. 8795–8801
2025
-
[8]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu et al., “Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation,”arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, and X. Wang, “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 12 037–12 047
2025
-
[10]
Diffusion-based planning for autonomous driving with flexible guidance,
Y . Zheng, R. Liang, K. ZHENG, J. Zheng, L. Mao, J. Li, W. Gu, R. Ai, S. E. Li, X. Zhan, and J. Liu, “Diffusion-based planning for autonomous driving with flexible guidance,” inProceedings of the International Conference on Learning Representations, 2025
2025
-
[11]
Meanfuser: Fast one-step multi- modal trajectory generation and adaptive reconstruction via meanflow for end-to-end autonomous driving,
J. Wang, Y . Zheng, X. Liu, Z. Xing, P. Li, K. Ma, H. Ye, G. Chen, G. Li, L. Chen, Z. Xia, and Q. Zhang, “Meanfuser: Fast one-step multi- modal trajectory generation and adaptive reconstruction via meanflow for end-to-end autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 17 884–17 893
2026
-
[12]
Opendrivevla: Towards end-to-end autonomous driving with large vision language action model,
X. Zhou, X. Han, F. Yang, Y . Ma, V . Tresp, and A. Knoll, “Opendrivevla: Towards end-to-end autonomous driving with large vision language action model,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 16, 2026, pp. 13 782–13 790
2026
-
[13]
Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning,
Z. Zhou, T. Cai, S. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma, “Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning,” in Advances in Neural Information Processing Systems, vol. 38, 2025, pp. 27 920–27 956
2025
-
[14]
Reasoning-vla: A fast and general vision-language- action reasoning model for autonomous driving,
D. Zhang, Z. Yuan, Z. Chen, C.-T. Liao, Y . Chen, F. Shen, Q. Zhou, and T.-S. Chua, “Reasoning-vla: A fast and general vision-language- action reasoning model for autonomous driving,”arXiv preprint arXiv:2511.19912, 2025
-
[15]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the International Conference on Artificial Intelligence and Statistics, vol. 15, 2011, pp. 627–635
2011
-
[16]
Road: Rollouts as demonstrations for closed-loop supervised fine-tuning of autonomous driving policies,
G. Garcia-Cobo, M. Igl, P. Karkus, Z. Zhang, M. Watson, Y . Chen, B. Ivanovic, and M. Pavone, “Road: Rollouts as demonstrations for closed-loop supervised fine-tuning of autonomous driving policies,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Findings, 2026, pp. 1000–1009
2026
-
[17]
Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving,
Z. Huang, H. Liu, and C. Lv, “Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3903–3913
2023
-
[18]
Rethinking imitation-based planner for autonomous driving,
J. Cheng, Y . Chen, X. Mei, B. Yang, B. Li, and M. Liu, “Rethinking imitation-based planner for autonomous driving,” inProceedings of the IEEE International Conference on Robotics and Automation, 2024, pp. 14 123–14 130
2024
-
[19]
Vadv2: End-to-end vectorized autonomous driving via probabilistic planning,
S. Chen, B. Jiang, H. Gao, B. Liao, Q. Xu, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Vadv2: End-to-end vectorized autonomous driving via probabilistic planning,” inProceedings of the International Conference on Learning Representations, 2024
2024
-
[20]
Flow matching-based autonomous driving planning with advanced interactive behavior modeling,
T. Tan, Y . Zheng, R. Liang, Z. Wang, K. Zheng, J. Zheng, J. Li, X. Zhan, and J. Liu, “Flow matching-based autonomous driving planning with advanced interactive behavior modeling,” inAdvances in Neural Information Processing Systems, vol. 38, 2025, pp. 38 310–38 335
2025
-
[21]
Diffusion forcing plan- ner: History-annealed planning with time-dependent guidance for au- tonomous driving,
Z. Zhang, Y . Li, N. Zhang, and J. Cai, “Diffusion forcing plan- ner: History-annealed planning with time-dependent guidance for au- tonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 39 796–39 805
2026
-
[22]
Planagent: A multi-modal large language agent for closed- loop vehicle motion planning,
Y . Zheng, Z. Xing, Q. Zhang, B. Jin, P. Li, Y . Zheng, Z. Xia, Y . Chen, and D. Zhao, “Planagent: A multi-modal large language agent for closed- loop vehicle motion planning,”IEEE Transactions on Cognitive and Developmental Systems, pp. 1–14, 2026
2026
-
[23]
Human-guided reinforcement learning with sim-to-real transfer for autonomous naviga- tion,
J. Wu, Y . Zhou, H. Yang, Z. Huang, and C. Lv, “Human-guided reinforcement learning with sim-to-real transfer for autonomous naviga- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 14 745–14 759, 2023
2023
-
[24]
Carplanner: Consistent auto-regressive trajectory planning for large-scale reinforcement learning in autonomous driving,
D. Zhang, J. Liang, K. Guo, S. Lu, Q. Wang, R. Xiong, Z. Miao, and Y . Wang, “Carplanner: Consistent auto-regressive trajectory planning for large-scale reinforcement learning in autonomous driving,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 17 239–17 248
2025
-
[25]
Drivedpo: Policy learning via safety dpo for end-to-end autonomous driving,
S. Shang, Y . Chen, Y . Wang, Y . Li, and Z.-X. ZHANG, “Drivedpo: Policy learning via safety dpo for end-to-end autonomous driving,” in Advances in Neural Information Processing Systems, vol. 38, 2025, pp. 81 565–81 585
2025
-
[26]
Plan-R1: Safe and Feasible Trajectory Planning as Language Modeling
X. Tang, M. Kan, S. Shan, and X. Chen, “Plan-r1: Safe and feasible trajectory planning as language modeling,”arXiv preprint arXiv:2505.17659, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Breaking through safety performance stagnation in autonomous vehicles with dense learning,
S. Feng, H. Zhu, H. Sun, X. Yan, L. He, J. Yang, G. Su, B. Li, S. Li, L. Wang, S. Shen, and H. X. Liu, “Breaking through safety performance stagnation in autonomous vehicles with dense learning,” Nature Communications, vol. 17, no. 3163, 2026
2026
-
[28]
Closed-loop supervised fine-tuning of tokenized traffic models,
Z. Zhang, P. Karkus, M. Igl, W. Ding, Y . Chen, B. Ivanovic, and M. Pavone, “Closed-loop supervised fine-tuning of tokenized traffic models,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025, pp. 5422–5432
2025
-
[29]
Mp3: A unified model to map, perceive, predict and plan,
S. Casas, A. Sadat, and R. Urtasun, “Mp3: A unified model to map, perceive, predict and plan,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 398–14 407
2021
-
[30]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8340–8350
2023
-
[31]
Generalizing motion planners with mixture of experts for autonomous driving,
Q. Sun, H. Wang, J. Zhan, F. Nie, X. Wen, L. Xu, K. Zhan, P. Jia, X. Lang, and H. Zhao, “Generalizing motion planners with mixture of experts for autonomous driving,” inProceedings of the IEEE Interna- tional Conference on Robotics and Automation, 2025, pp. 6033–6039
2025
-
[32]
MISTY: High-Throughput Motion Planning via Mixer-based Single-step Drifting
Y . Xing, Z. Ke, Y . Tu, Z. Liu, W. Yu, and J. Wang, “Misty: High- throughput motion planning via mixer-based single-step drifting,”arXiv preprint arXiv:2604.21489, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Dart: Noise injection for robust imitation learning,
M. Laskey, J. Lee, R. Fox, A. Dragan, and K. Goldberg, “Dart: Noise injection for robust imitation learning,” inProceedings of the Conference on Robot Learning, vol. 78, 2017, pp. 143–156
2017
-
[34]
Query-efficient imitation learning for end-to- end autonomous driving,
J. Zhang and K. Cho, “Query-efficient imitation learning for end-to- end autonomous driving,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 30, 2017, pp. 2891–2897
2017
-
[35]
Hg-dagger: Interactive imitation learning with human experts,
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer, “Hg-dagger: Interactive imitation learning with human experts,” inPro- ceedings of the International Conference on Robotics and Automation, 2019, pp. 8077–8083. PREPRINT 15
2019
-
[36]
Ensembledag- ger: A bayesian approach to safe imitation learning,
K. Menda, K. Driggs-Campbell, and M. J. Kochenderfer, “Ensembledag- ger: A bayesian approach to safe imitation learning,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2019, pp. 5041–5048
2019
-
[37]
DIVER: Reinforced Diffusion Breaks Imitation Bottlenecks in End-to-End Autonomous Driving
Z. Song, L. Liu, H. Pan, B. Liao, M. Guo, L. Yang, Y . Zhang, S. Xu, C. Jia, and Y . Luo, “Diver: Reinforced diffusion breaks imi- tation bottlenecks in end-to-end autonomous driving,”arXiv preprint arXiv:2507.04049, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Unleashing the Potential of Diffusion Models for End-to-End Autonomous Driving
Y . Zheng, T. Tan, B. Huang, E. Liu, R. Liang, J. Zhang, J. Cui, G. Chen, K. Ma, H. Ye, L. Chen, Y .-Q. Zhang, X. Zhan, and J. Liu, “Unleashing the potential of diffusion models for end-to-end autonomous driving,” arXiv preprint arXiv:2602.22801, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Three types of incremental learning,
G. M. van de Ven, T. Tuytelaars, and A. S. Tolias, “Three types of incremental learning,”Nature Machine Intelligence, vol. 4, no. 12, pp. 1185–1197, 2022
2022
-
[40]
A comprehensive survey of continual learning: Theory, method and application,
L. Wang, X. Zhang, H. Su, and J. Zhu, “A comprehensive survey of continual learning: Theory, method and application,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5362– 5383, 2024
2024
-
[41]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,”Proceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[42]
Learning without forgetting,
Z. Li and D. Hoiem, “Learning without forgetting,” inProceedings of the European Conference on Computer Vision, 2016, pp. 614–629
2016
-
[43]
icarl: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 2001–2010
2017
-
[44]
Gradient episodic memory for continual learning,
D. Lopez-Paz and M. Ranzato, “Gradient episodic memory for continual learning,” inAdvances in Neural Information Processing Systems, 2017, p. 6470–6479
2017
-
[45]
Dark experience for general continual learning: a strong, simple base- line,
P. Buzzega, M. Boschini, A. Porrello, D. Abati, and S. CALDERARA, “Dark experience for general continual learning: a strong, simple base- line,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 15 920–15 930
2020
-
[46]
Lifelong learning with dynamically expandable networks,
J. Yoon, E. Yang, J. Lee, and S. J. Hwang, “Lifelong learning with dynamically expandable networks,” inProceedings of the International Conference on Learning Representations, 2018
2018
-
[47]
Packnet: Adding multiple tasks to a single network by iterative pruning,
A. Mallya and S. Lazebnik, “Packnet: Adding multiple tasks to a single network by iterative pruning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7765–7773
2018
-
[48]
Learning to prompt for continual learning,
Z. Wang, Z. Zhang, S. Ebrahimi, R. Sun, H. Zhang, C.-Y . Lee, X. Ren, G. Su, V . Perot, J. Dy, and T. Pfister, “Learning to prompt for continual learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 139–149
2022
-
[49]
Dualprompt: Complementary prompting for rehearsal-free continual learning,
Z. Wang, Z. Zhang, C.-Y . Lee, H. Zhang, R. Sun, X. Ren, G. Su, V . Perot, J. Dy, and T. Pfister, “Dualprompt: Complementary prompting for rehearsal-free continual learning,” inProceedings of the European Conference on Computer Vision, 2022, pp. 631–648
2022
-
[50]
Inflora: Interference-free low-rank adaptation for continual learning,
Y .-S. Liang and W.-J. Li, “Inflora: Interference-free low-rank adaptation for continual learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 23 638–23 647
2024
-
[51]
Continual learning with pre-trained models: A survey,
D.-W. Zhou, H.-L. Sun, J. Ning, H.-J. Ye, and D.-C. Zhan, “Continual learning with pre-trained models: A survey,” inProceedings of the International Joint Conference on Artificial Intelligence, 2024, pp. 8363– 8371
2024
-
[52]
Continual driver behaviour learning for connected vehicles and intelligent transportation systems: Framework, survey and challenges,
Z. Li, C. Gong, Y . Lin, G. Li, X. Wang, C. Lu, M. Wang, S. Chen, and J. Gong, “Continual driver behaviour learning for connected vehicles and intelligent transportation systems: Framework, survey and challenges,” Green Energy and Intelligent Transportation, vol. 2, no. 4, p. 100103, 2023
2023
-
[53]
Toward zero-forget continual learning for interactive trajectory prediction: A dynamically expandable approach,
H. Li, X. Wu, J. Huang, and Z. Zhong, “Toward zero-forget continual learning for interactive trajectory prediction: A dynamically expandable approach,”Communications in Transportation Research, vol. 6, no. 1, p. 9640015, 2026
2026
-
[54]
H2c: Hippocampal circuit-inspired continual learning for lifelong trajectory prediction in autonomous driving,
Y . Lin, Z. Li, G. Du, X. Zhao, C. Gong, X. Wang, C. Lu, and J. Gong, “H2c: Hippocampal circuit-inspired continual learning for lifelong trajectory prediction in autonomous driving,”IEEE Transactions on Intelligent Transportation Systems, pp. 1–18, 2026
2026
-
[55]
Continu- ous improvement of self-driving cars using dynamic confidence-aware reinforcement learning,
Z. Cao, K. Jiang, W. Zhou, S. Xu, H. Peng, and D. Yang, “Continu- ous improvement of self-driving cars using dynamic confidence-aware reinforcement learning,”Nature Machine Intelligence, vol. 5, no. 2, pp. 145–158, 2023
2023
-
[56]
Preserving and combining knowledge in robotic lifelong reinforcement learning,
Y . Meng, Z. Bing, X. Yao, K. Chen, K. Huang, Y . Gao, F. Sun, and A. Knoll, “Preserving and combining knowledge in robotic lifelong reinforcement learning,”Nature Machine Intelligence, vol. 7, no. 2, pp. 256–269, 2025
2025
-
[57]
Beyond imi- tation: A life-long policy learning framework for path tracking control of autonomous driving,
C. Gong, C. Lu, Z. Li, Z. Liu, J. Gong, and X. Chen, “Beyond imi- tation: A life-long policy learning framework for path tracking control of autonomous driving,”IEEE Transactions on Vehicular Technology, vol. 73, no. 7, pp. 9786–9799, 2024
2024
-
[58]
Human-guided continual learning for personalized decision-making of autonomous driv- ing,
H. Yang, Y . Zhou, J. Wu, H. Liu, L. Yang, and C. Lv, “Human-guided continual learning for personalized decision-making of autonomous driv- ing,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 4, pp. 5435–5447, 2025
2025
-
[59]
Urban driver: Learning to drive from real-world demonstrations using policy gradients,
O. Scheel, L. Bergamini, M. Wolczyk, B. Osi ´nski, and P. Ondruska, “Urban driver: Learning to drive from real-world demonstrations using policy gradients,” inProceedings of the Conference on Robot Learning, vol. 164, 2022, pp. 718–728
2022
-
[60]
Parting with misconceptions about learning-based vehicle motion planning,
D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta, “Parting with misconceptions about learning-based vehicle motion planning,” inPro- ceedings of The Conference on Robot Learning, vol. 229, 2023, pp. 1268–1281
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.