Context, Reasoning, and Hierarchy: A Cost-Performance Study of Compound LLM Agent Design in an Adversarial POMDP
Pith reviewed 2026-05-20 18:59 UTC · model grok-4.3
The pith
Programmatic state abstraction improves LLM agent returns by up to 76 percent per token over raw observations in adversarial POMDPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
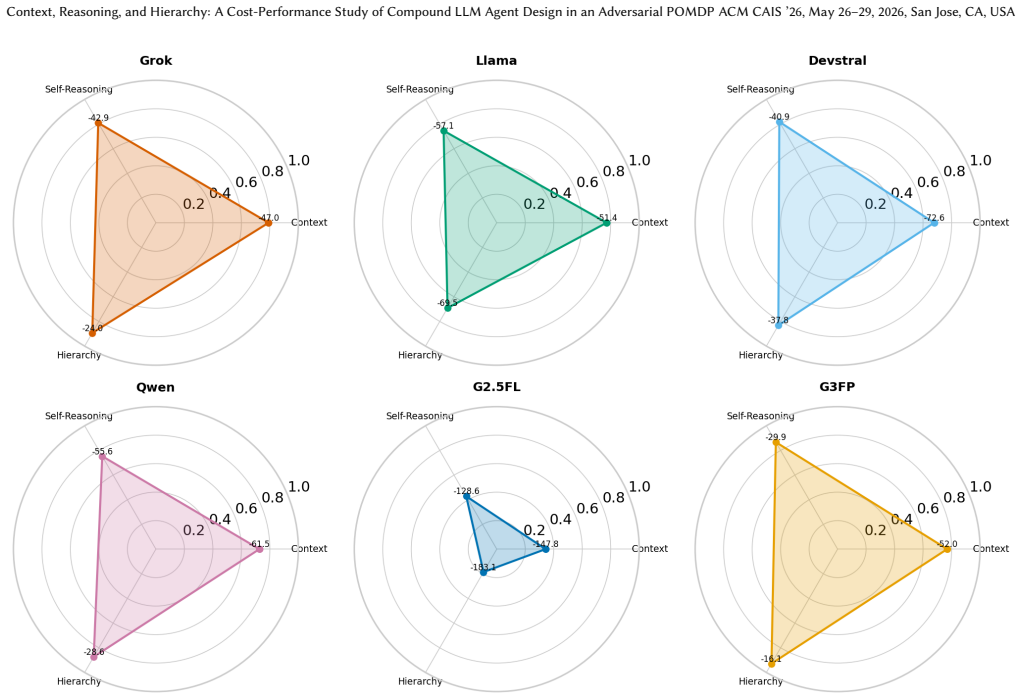
In the tested adversarial POMDP, replacing raw observations with a deterministic state-tracking layer that compresses history raises mean return per token spent by as much as 76 percent. Hierarchical decomposition without any deliberation tools yields the highest absolute performance for most models. Distributing self-questioning, self-critique, and self-improvement tools across the hierarchy produces a deliberation cascade that cuts mean return by up to 3.4 times while consuming 1.8 to 2.7 times more tokens. Context engineering therefore proves more cost-effective than deeper per-agent reasoning.
What carries the argument
The controlled comparison of three design axes—context representation (raw observations versus programmatic state abstraction), deliberation tools (self-questioning, critique, and improvement), and hierarchy (monolithic versus specialized sub-agents)—with full token-level cost accounting across 3,475 episodes.
If this is right
- Programmatic state abstraction delivers the largest returns per token spent across the tested model families.
- Hierarchical decomposition without deliberation achieves the best absolute performance for most models.
- Distributing deliberation tools across a hierarchy triggers a deliberation cascade that degrades mean return while increasing token consumption.
- Context engineering is generally more cost-effective than adding deliberation capabilities.
Where Pith is reading between the lines
- The same priority on clean state infrastructure over added reasoning layers may hold in other partially observable sequential domains such as robotics or logistics.
- System builders could replace some prompting complexity with lightweight programmatic trackers to reduce inference spend without loss of capability.
- The observed interference implies that reasoning depth is best controlled at the overall architecture level rather than multiplied inside every sub-agent.
Load-bearing premise
The twelve configurations and the reward structure of this particular simulator are representative enough of other adversarial POMDPs that the observed ranking of context and hierarchy over deliberation will generalize.
What would settle it
Re-running the identical twelve configurations inside a different adversarial POMDP simulator that uses a materially different reward function and checking whether state abstraction still produces the highest returns per token while hierarchy-plus-deliberation still underperforms.
Figures





















read the original abstract
Deploying compound LLM agents in adversarial, partially observable sequential environments requires navigating several design dimensions: (1) what the agent sees, (2) how it reasons, and (3) how tasks are decomposed across components. Yet practitioners lack guidance on which design choices improve performance versus merely increase inference costs. We present a controlled study of compound LLM agent design in CybORG CAGE-2, a cyber defense environment modeled as a Partially Observable Markov Decision Process (POMDP). Reward is non-positive, so all configurations operate in a failure-mitigation mode. Our evaluation spans five model families, six models, and twelve configurations (3,475 episodes) with token-level cost accounting. We vary context representation (raw observations vs. a deterministic state-tracking layer with compressed history), deliberation (self-questioning, self-critique, and self-improvement tools, with optional chain-of-thought prompting), and hierarchical decomposition (monolithic ReAct vs. delegation to specialized sub-agents). We find that: (1) Programmatic state abstraction delivers the largest returns per token spent (RPTS), improving mean return by up to 76% over raw observations. (2) Distributing deliberation tools across a hierarchy degrades performance relative to hierarchy alone for all five model families, reaching up to 3.4$\times$ worse mean return while using 1.8-2.7$\times$ more tokens. We call this destructive pattern a deliberation cascade. (3) Hierarchical decomposition without deliberation achieves the best absolute performance for most models, and context engineering is generally more cost-effective than deliberation. These findings suggest a design principle for structured adversarial POMDPs: invest in programmatic infrastructure and clean task decomposition rather than deeper per-agent reasoning, as these strategies can interfere when combined.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale empirical study of compound LLM agent designs in the CybORG CAGE-2 adversarial POMDP. It systematically varies context representation (raw observations versus programmatic state abstraction with compressed history), deliberation mechanisms (self-questioning, self-critique, and self-improvement with optional CoT), and task decomposition (monolithic ReAct versus hierarchical delegation to specialized sub-agents). Evaluating 12 configurations across 6 models from 5 families in 3,475 episodes with detailed token cost tracking, the authors report that programmatic state abstraction provides the highest returns per token spent (RPTS), with up to 76% improvement in mean return over raw observations. Hierarchical decomposition without deliberation yields the best absolute performance for most models, while adding deliberation tools to the hierarchy triggers a 'deliberation cascade' resulting in up to 3.4 times worse returns at 1.8-2.7 times the token cost. The study concludes with a suggested design principle favoring programmatic infrastructure and clean decomposition over deeper reasoning in such environments.
Significance. If these empirical patterns hold, the work offers actionable insights for practitioners building LLM agents in partially observable adversarial settings, emphasizing the cost-effectiveness of state abstraction and simple hierarchies. The strengths include the controlled experimental design, explicit accounting for inference costs at the token level, and the scale of evaluation covering multiple model families. This could help shift focus from complex reasoning chains to better context engineering in agent architectures. However, the single-environment nature of the study tempers the generalizability of the proposed design principle.
major comments (2)
- Abstract: The claim that the findings suggest a design principle for structured adversarial POMDPs is load-bearing for the paper's broader contribution, yet rests exclusively on results from CybORG CAGE-2 under its fixed non-positive reward and observation structure. A concrete test to address the correctness risk would be replication of the 12 configurations in at least one additional adversarial POMDP with differing state space and dynamics to check whether the RPTS ranking and deliberation cascade persist.
- Results section: The reported mean return gains (up to 76%) and deliberation cascade effects (up to 3.4× worse return) are presented without variance estimates, standard errors, or statistical significance tests across the 3,475 episodes. Given stochasticity from both LLM sampling and the POMDP, this omission weakens confidence in the configuration rankings and effect sizes.
minor comments (2)
- Abstract: The exact definition and computation of RPTS (e.g., whether it is the ratio of mean return to mean tokens per episode or an aggregate) is not fully specified, which affects reproducibility of the cost-performance claims.
- Methods: A summary table explicitly listing all 12 configurations (combinations of context type, deliberation tools, and hierarchy level) per model would improve clarity and allow readers to map the reported outcomes directly to design choices.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: Abstract: The claim that the findings suggest a design principle for structured adversarial POMDPs is load-bearing for the paper's broader contribution, yet rests exclusively on results from CybORG CAGE-2 under its fixed non-positive reward and observation structure. A concrete test to address the correctness risk would be replication of the 12 configurations in at least one additional adversarial POMDP with differing state space and dynamics to check whether the RPTS ranking and deliberation cascade persist.
Authors: We appreciate the referee's point regarding the scope of our conclusions. Our work presents a controlled, large-scale study focused on the CybORG CAGE-2 environment, which is a standard benchmark for adversarial cyber defense POMDPs. We agree that the single-environment design limits broad claims, and replicating the full experimental suite in a second environment would require resources beyond a minor revision. We will therefore revise the abstract and conclusion sections to qualify the suggested design principle more precisely as being supported by evidence from this class of structured adversarial POMDPs, while explicitly noting the single-environment limitation. This maintains the contribution without overstating generalizability. revision: partial
-
Referee: Results section: The reported mean return gains (up to 76%) and deliberation cascade effects (up to 3.4× worse return) are presented without variance estimates, standard errors, or statistical significance tests across the 3,475 episodes. Given stochasticity from both LLM sampling and the POMDP, this omission weakens confidence in the configuration rankings and effect sizes.
Authors: We agree that reporting variance and conducting statistical tests would strengthen confidence in the results, particularly given the stochastic nature of both the LLM outputs and the environment. In the revised manuscript, we will add standard errors (or confidence intervals) to all reported mean returns and RPTS values. We will also include appropriate statistical significance tests (such as paired t-tests or non-parametric alternatives) for the primary comparisons between configurations to support the reported effect sizes and rankings. revision: yes
Circularity Check
No circularity: purely empirical evaluation with direct measurements
full rationale
The paper reports results from a controlled experimental study running 3,475 episodes across twelve agent configurations in the fixed CybORG CAGE-2 POMDP. All central claims (76% RPTS gain from state abstraction, deliberation cascade degrading performance, hierarchy without deliberation as best for most models) are obtained by direct measurement of return and token cost under the environment's external reward structure. No derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations exist; the findings are falsifiable by re-running the same simulator and configurations. This is the most common honest non-finding for empirical papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CybORG CAGE-2 constitutes a representative adversarial POMDP for evaluating LLM agent design choices.
Reference graph
Works this paper leans on
-
[1]
Elizabeth Bates, Vasilios Mavroudis, and Chris Hicks. 2023. Reward Shaping for Happier Autonomous Cyber Security Agents. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec ’23)(Copenhagen, Den- mark). Association for Computing Machinery, New York, NY, USA, 221–232. doi:10.1145/3605764.3623916
-
[2]
CardiffUni Team. 2022. CybORG CAGE-2 Winning Agent: PPO + Greedy Decoys. https://github.com/john-cardiff/-cyborg-cage-2. Accessed: 2026-04-28
work page 2022
-
[3]
Castro, Roberto Campbell, Nancy Lau, Octavio Villalobos, Jiaqi Duan, and Alvaro A
Sebastián R. Castro, Roberto Campbell, Nancy Lau, Octavio Villalobos, Jiaqi Duan, and Alvaro A. Cardenas. 2025. Large Language Models are Autonomous Cyber Defenders. InProceedings of the 2025 IEEE Conference on Artificial Intelligence (CAI). 1125–1132. doi:10.1109/CAI64502.2025.00195
-
[4]
Kim Hammar, Neil Dhir, and Rolf Stadler. 2024. Optimal Defender Strate- gies for CAGE-2 using Causal Modeling and Tree Search.arXiv(2024). arXiv:2407.11070 [cs.CR] doi:10.48550/arXiv.2407.11070
-
[5]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2024. Large Language Models Cannot Self- Correct Reasoning Yet. InInternational Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2310.01798
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01798 2024
-
[6]
Andrej Karpathy. 2025. +1 for “context engineering” over “prompt engineering”. X (formerly Twitter) post. https://x.com/karpathy/status/1937902205765607626 Accessed 2026-02-22
-
[7]
Karim Ben Khaled and Davy Monticolo. 2026. G2CP: A Graph-Grounded Com- munication Protocol for Verifiable and Efficient Multi-Agent Reasoning.arXiv (2026). arXiv:2602.13370 [cs.AI] doi:10.48550/arXiv.2602.13370
-
[8]
Mitchell Kiely, David Bowman, Maxwell Standen, and Christopher Moir. 2023. On Autonomous Agents in a Cyber Defence Environment.arXiv(2023). arXiv:2309.07388 [cs.CR] doi:10.48550/arXiv.2309.07388
-
[9]
Yubin Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A. Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Mark Malhotra, Paul Pu Liang, Hae Won Park, Yuzhe Yang, Xuhai Xu, Yilun Du, Shwetak Patel, Tim Althoff, Daniel McDuff, and Xin Liu. 2025. Towards a Science of Scaling Agent Systems. arXiv(2025). arXiv:2512.08296 [cs.AI] doi:10.48550/arX...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.08296 2025
-
[10]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large Language Models are Zero-Shot Reasoners. InAdvances in Neural Information Processing Systems, Vol. 35. doi:10.48550/arXiv.2205.11916
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.11916 2022
-
[11]
LangChain. 2025. LangChain. Open-source software framework. https://github. com/langchain-ai/langchain Accessed 2026-02-22
work page 2025
- [12]
-
[13]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-Refine: Iterative Refinement with Self-Feedback. InAdvances in Neural Information Processi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17651 2023
-
[14]
Hamoun Mohammadi, Jonathan J. Davis, and Mitchell Kiely. 2025. Leveraging Large Language Models for Autonomous Cyber Defense: Insights from CAGE-2 Simulations.IEEE Intelligent Systems40 (2025), 29–36. doi:10.1109/MIS.2025. 3568209
-
[15]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2023. Measuring and Narrowing the Compositionality Gap in Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics, 5687–5711. doi:10.18653/v1/2023. findings-emnlp.378
-
[16]
Chen Qian, Zihao Xie, YiFei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun
-
[17]
InInter- national Conference on Learning Representations (ICLR)
Scaling Large Language Model-based Multi-Agent Collaboration. InInter- national Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2406. 07155
- [18]
-
[19]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. InAdvances in Neural Information Processing Systems, Vol. 36. doi:10.48550/arXiv.2303.11366
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.11366 2023
-
[20]
Richer, Junae Kim, and Damian Marriott
Maxwell Standen, Martin Lucas, David Bowman, Toby J. Richer, Junae Kim, and Damian Marriott. 2021. CybORG: A Gym for the Development of Autonomous Cyber Agents.arXiv(2021). arXiv:2108.09118 [cs.CR] doi:10.48550/arXiv.2108. 09118
-
[21]
Yichen Tang, Weihang Su, Yujia Zhou, Yiqun Liu, Min Zhang, Shaoping Ma, and Qingyao Ai. 2025. Augmenting Multi-Agent Communication with State Delta Trajectory. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 10219–10240. doi:10.18653/v1/2025.emnlp-main.518
-
[22]
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D. Nguyen. 2025. Multi-Agent Collaboration Mechanisms: A Survey of LLMs.arXiv(2025). arXiv:2501.06322 [cs.AI] doi:10.48550/arXiv. 2501.06322
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[23]
TTCP CAGE Challenge Working Group. 2022. TTCP CAGE Challenge 2. https: //github.com/cage-challenge/cage-challenge-2 Accessed 2026-02-22
work page 2022
-
[24]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 35. doi:10.48550/arXiv.2201.11903
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903 2022
-
[25]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR). doi:10. 48550/arXiv.2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Ur- mish Thakker, James Zou, and Kunle Olukotun. 2025. Agentic Context Engi- neering: Evolving Contexts for Self-Improving Language Models.arXiv(2025). arXiv:2510.04618 [cs.LG] doi:10.48550/arXiv.2510.04618 Appendix org...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.04618 2025
-
[27]
Which hosts need attention? What actions have been tried?
REVIEW SITUATION: Check network status and step history. Which hosts need attention? What actions have been tried?
-
[28]
IDENTIFY TARGET: Select the most critical host or threat to address this step
-
[29]
GATHER INFO: If needed, use get_analysis_of_host_update for detailed analysis of a changed host
-
[30]
GET SUGGESTIONS: Call get_suggestion_for_next_action with JSON: {"target_host": "hostname", "situation": "description", "severity": "level", "context": "relevant history"}
-
[31]
DECIDE: Choose ONE action from suggestions. You may override based on strategic reasoning rules: - You must select ONLY ONE action for your final Answer from the list of suggestions provided by the'get_suggestion_for_next_action'tool - Your final Answer MUST be a verbatim copy of the action-string from ONE of the suggestions - TOOLS CANNOT HANDLE MULTIPLE...
work page 2026
-
[32]
GET CURRENT STATE: Use get_host_current_state for the target host
-
[33]
GET BASELINE: Use get_host_baseline_state to compare against initial state
-
[34]
IDENTIFY ANOMALIES: What changed? New processes, connections, missing services?
-
[35]
ASSESS SEVERITY: How critical is this compromise? Is there C2 activity?
-
[36]
RECOMMEND ACTION: Should we contain, investigate further, or just monitor? tools: - name: "get_host_current_state" description: "Get the current state details for a specific host. The input must be a single hostname." example_calling: "get_host_current_state: Enterprise1" - name: "get_host_baseline_state" description: "Get the baseline state details for a...
-
[37]
READ SITUATION: Check SITUATION_JSON for target_host, threat description, severity, and context
-
[38]
types and their costs vs benefits
EVALUATE ACTIONS: Consider available action ACM CAIS ’26, May 26–29, 2026, San Jose, CA, USA Bogdanov et al. types and their costs vs benefits
work page 2026
-
[39]
RANK THREE: Provide three suggestions with confidence scores (0.0-1.0), highest confidence first answer_format: | Your response MUST STRICTLY be a JSON array of objects, where each object represents a suggested action. Each object must have ONLY the following keys: "action", "confidence". The ActionChooser hasno tools, it is a pure generation agent that r...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.