DynFly: Dynamic-Aware Continuous Trajectory Generation for UAV Vision-Language Navigation in Urban Environments
Pith reviewed 2026-07-01 05:32 UTC · model grok-4.3
The pith
DynFly generates continuous UAV trajectories from vision-language navigation commands by representing them as B-spline control points and training a generator with flow matching plus dynamic losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
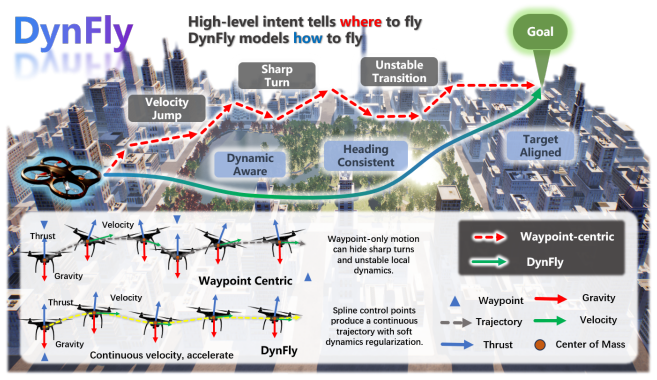
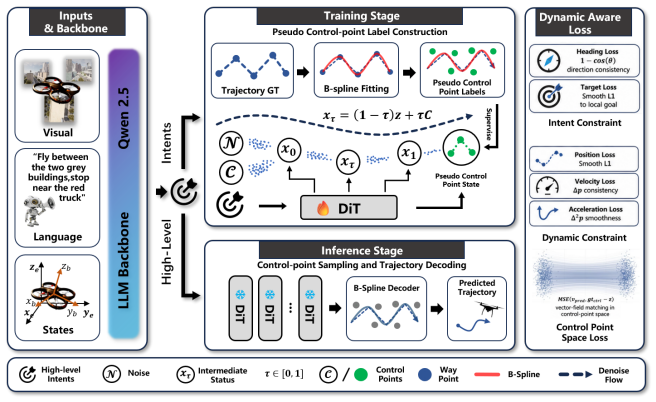
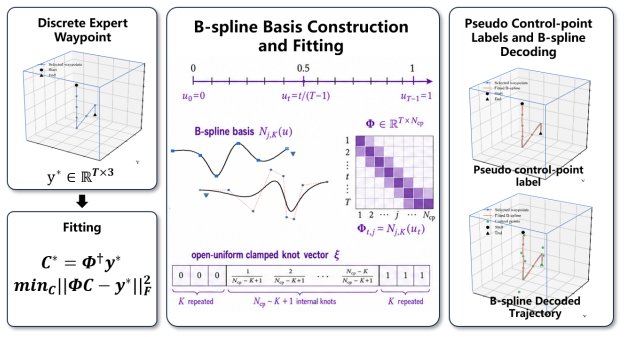
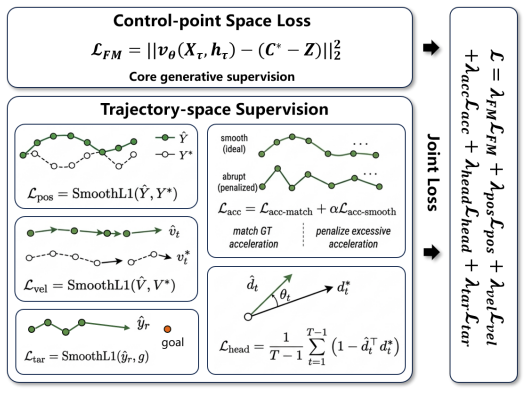
DynFly bridges high-level navigation intent and continuous UAV motion through a lightweight trajectory generation layer. Specifically, it represents expert trajectories in B-spline control-point space and employs a Spline-DiT generator to learn conditional trajectory generation via flow matching. UAV-oriented dynamic-aware supervision over position, finite-difference velocity, finite-difference acceleration, heading consistency, and local target alignment enables the generated trajectories to better satisfy UAV motion characteristics. The framework integrates with existing UAV-VLN pipelines while preserving their original visual-language reasoning.
What carries the argument
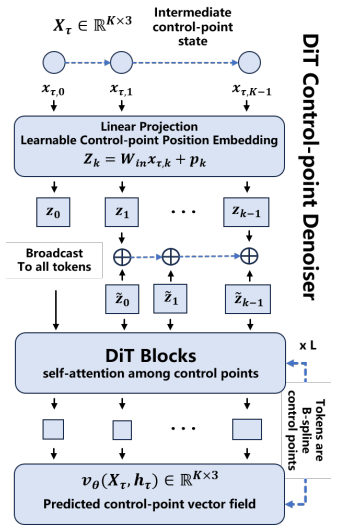
Spline-DiT generator trained by flow matching on B-spline control points, supervised by dynamic losses on position, velocity, acceleration, heading, and target alignment
If this is right
- The trajectory layer integrates with any existing UAV-VLN framework without changing its visual-language reasoning pipeline.
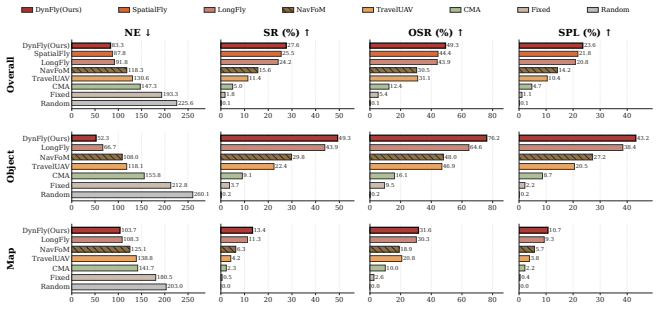
- On the Test Unseen Full split the method raises the strongest baseline by 4.69 NDTW, 2.40 SDTW, 2.14 SR, and 4.87 OSR while cutting NE by 4.51 m.
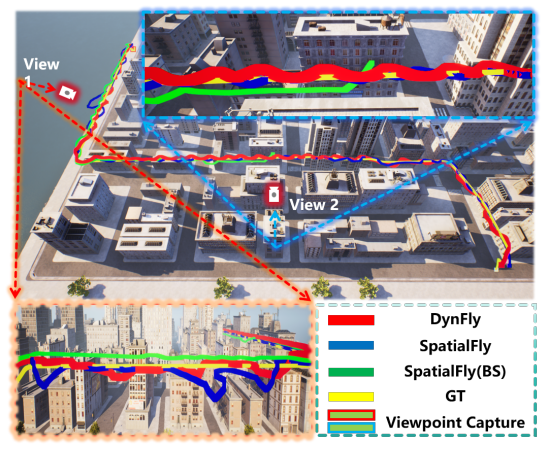
- Generated paths better match UAV motion properties than paths from discrete-action or sparse-waypoint baselines.
- Both navigation success and trajectory quality improve on the OpenUAV benchmark.
Where Pith is reading between the lines
- The same B-spline-plus-flow-matching approach could be tested on ground robots or other vehicles that require smooth continuous control from language instructions.
- Physical flight tests on real UAVs would show whether the simulated metric gains translate to hardware under wind and sensor noise.
- The dynamic losses might be reused in other trajectory tasks such as multi-agent coordination or energy-aware path planning.
Load-bearing premise
Expert trajectories encoded in B-spline control-point space, when trained with flow matching and the listed dynamic losses, will produce motions that UAVs can execute more effectively than discrete-action predictions.
What would settle it
Implementing the full DynFly pipeline on the OpenUAV Test Unseen Full split and observing no gains over the strongest baseline in NDTW, SDTW, SR, OSR, or NE.
Figures

read the original abstract
Recent advances in multimodal large models have significantly improved UAV vision-language navigation (UAV-VLN) by enhancing high-level perception and reasoning. However, existing methods mainly focus on predicting discrete actions, local targets, or sparse waypoints, while the continuous transition from navigation intent to executable UAV motion remains weakly modeled. This motion-interface gap limits the continuity, stability, and executability of generated UAV trajectories. To address this gap, we propose DynFly, a dynamic-aware continuous trajectory generation framework that bridges high-level navigation reasoning and executable UAV motion. DynFly bridges high-level navigation intent and continuous UAV motion through a lightweight trajectory generation layer. Specifically, it represents expert trajectories in B-spline control-point space and employs a Spline-DiT generator to learn conditional trajectory generation via flow matching. Furthermore, we introduce UAV-oriented dynamic-aware supervision over position, finite-difference velocity, finite-difference acceleration, heading consistency, and local target alignment, enabling the generated trajectories to better satisfy UAV motion characteristics. And our trajectory generation framework can also be integrated with an existing UAV-VLN framework while preserving its original visual-language reasoning pipeline. Extensive experiments on the OpenUAV UAV-VLN benchmark show that DynFly improves both navigation performance and trajectory quality. On the Test Unseen Full split, DynFly improves the strongest baseline by 4.69 NDTW, 2.40 SDTW, 2.14 SR points and 4.87 OSR points, while reducing NE by 4.51 m.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DynFly, a framework for UAV vision-language navigation that generates continuous trajectories by representing expert paths in B-spline control-point space and training a Spline-DiT generator via flow matching. It adds UAV-oriented dynamic-aware supervision consisting of position, finite-difference velocity, finite-difference acceleration, heading consistency, and local target alignment losses. The method is presented as integrable with existing VLN pipelines without altering their visual-language reasoning, and it reports concrete gains on the OpenUAV benchmark (Test Unseen Full split): +4.69 NDTW, +2.40 SDTW, +2.14 SR, +4.87 OSR, and -4.51 m NE relative to the strongest baseline.
Significance. If the central claim holds after verification, the work would be significant for UAV-VLN because it directly targets the motion-interface gap between high-level multimodal reasoning and executable continuous trajectories. The lightweight integration property and use of flow matching on B-splines are practical strengths. However, significance is limited by the absence of evidence that the soft finite-difference losses produce trajectories that respect realistic UAV dynamics or actuator constraints; the reported metrics reflect task success rather than physical executability or tracking performance under a dynamics model.
major comments (2)
- [Abstract] Abstract: the central claim that the dynamic-aware supervision (position, finite-difference velocity/acceleration, heading, local target) produces trajectories that 'better satisfy UAV motion characteristics' and bridge to 'executable UAV motion' rests on soft losses only; no hard constraints on thrust, actuator limits, or higher-order dynamics are described, and no evaluation of physical feasibility or tracking error under a UAV dynamics model is provided. This directly undermines the executability claim.
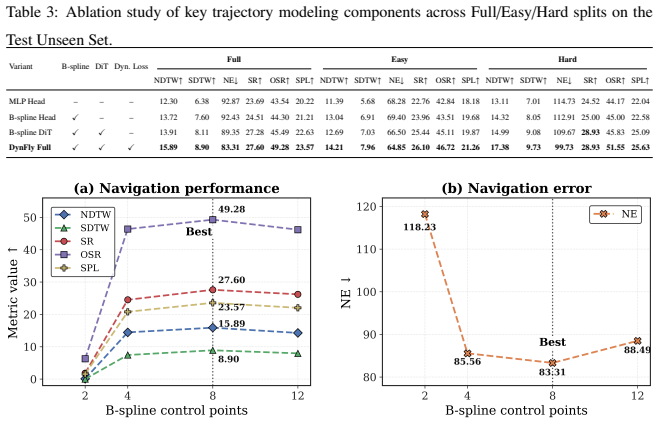
- [Abstract] Abstract (and Experiments section): headline metric gains (+4.69 NDTW, +2.14 SR, -4.51 m NE) are reported without baseline descriptions, ablation results isolating the contribution of each dynamic loss, error bars, or statistical tests. This makes it impossible to verify that the dynamic supervision, rather than other components of the Spline-DiT or flow-matching setup, drives the improvements.
minor comments (2)
- [Abstract] Abstract: the phrase 'lightweight trajectory generation layer' is used without quantifying parameters or inference cost relative to the baselines.
- The integration claim ('can also be integrated with an existing UAV-VLN framework while preserving its original visual-language reasoning pipeline') would benefit from a concrete diagram or pseudocode showing the interface points.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, acknowledging limitations where they exist and outlining targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the dynamic-aware supervision (position, finite-difference velocity/acceleration, heading, local target) produces trajectories that 'better satisfy UAV motion characteristics' and bridge to 'executable UAV motion' rests on soft losses only; no hard constraints on thrust, actuator limits, or higher-order dynamics are described, and no evaluation of physical feasibility or tracking error under a UAV dynamics model is provided. This directly undermines the executability claim.
Authors: We agree that the supervision consists solely of soft losses without hard constraints on thrust or actuator limits, and that no physical feasibility evaluation or tracking error under a UAV dynamics model is reported. The finite-difference terms are intended to promote smoother, more UAV-plausible trajectories in the learned distribution. We will revise the abstract and method description to remove or qualify language implying direct executability and will add an explicit limitations paragraph noting the absence of dynamics-model validation. revision: yes
-
Referee: [Abstract] Abstract (and Experiments section): headline metric gains (+4.69 NDTW, +2.14 SR, -4.51 m NE) are reported without baseline descriptions, ablation results isolating the contribution of each dynamic loss, error bars, or statistical tests. This makes it impossible to verify that the dynamic supervision, rather than other components of the Spline-DiT or flow-matching setup, drives the improvements.
Authors: The experiments section already describes the baselines and reports aggregate gains relative to the strongest baseline. However, the current ablations do not fully isolate every individual dynamic loss term with error bars and statistical tests. We will expand the ablation table in the revision to include per-loss contributions, add error bars, and report statistical significance where sample sizes permit; the abstract will be updated to reference the key baselines. revision: partial
Circularity Check
No circularity: training losses and benchmark metrics are independent
full rationale
The paper trains a Spline-DiT generator via flow matching on expert B-spline trajectories, augmented by finite-difference dynamic losses. Navigation metrics (NDTW, SDTW, SR, NE) are computed on the external OpenUAV benchmark and are not fitted quantities or self-referential predictions. No equations, self-citations, or uniqueness claims appear in the provided text that would reduce any claimed result to its inputs by construction. The derivation chain is a standard supervised generative model evaluated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Dai, E. Zheng, W. Cheng, J. Chen, Z. Feng, W. Yang, Drl: An ef- ficient heterogeneous spatial feature interaction framework for uav self- localization, Pattern Recognition 177 (2026) 113330
2026
-
[2]
Y . Gu, W. Chen, D. Peng, Uav-based multimodal object detection via fea- ture enhancement and dynamic gated fusion, Pattern Recognition 172 (2026) 112722
2026
-
[3]
Dewangan, M
B. Dewangan, M. Srinivas, Amsf-yolo: An attention-based multi-scale fea- ture extraction model for uav small object detection, Pattern Recognition 177 (2026) 113303
2026
-
[4]
Anderson, Q
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. Sunderhauf, I. Reid, S. Gould, A. Van Den Hengel, Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments, in: Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 3674–3683
2018
-
[5]
Speaker-Follower Models for Vision-and-Language Navigation
D. Fried, R. Hu, V . Cirik, A. Rohrbach, J. Andreas, L.-P. Morency, T. Berg- Kirkpatrick, K. Saenko, D. Klein, T. Darrell, Speaker-follower models for vision-and-language navigation, arXiv preprint arXiv:1806.02724 (2018). arXiv:1806.02724
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
K. He, Y . Jing, Y . Huang, Z. Lu, D. An, L. Wang, Memory-adaptive vision- and-language navigation, Pattern Recognition 153 (2024) 110511
2024
-
[7]
Mohammadi, E
B. Mohammadi, E. Abbasnejad, Y . Qi, Q. Wu, A. Van Den Hengel, J. Q. Shi, Parameter-efficient action planning with large language models for vision- and-language navigation, Pattern Recognition 172 (2026) 112462
2026
- [8]
- [9]
- [10]
- [11]
- [12]
-
[13]
S. Chen, P.-L. Guhur, C. Schmid, I. Laptev, History aware multi- modal transformer for vision-and-language navigation, arXiv preprint arXiv:2110.13309 (2021). arXiv:2110.13309
-
[14]
S. Chen, P.-L. Guhur, M. Tapaswi, C. Schmid, I. Laptev, Think global, act lo- cal: Dual-scale graph transformer for vision-and-language navigation, arXiv preprint arXiv:2202.11742 (2022). arXiv:2202.11742
- [15]
-
[16]
MapNav: A Novel Memory Representation via Annotated Semantic Maps for Vision-and-Language Navigation
L. Zhang, X. Hao, Q. Xu, Q. Zhang, X. Zhang, P. Wang, J. Zhang, Z. Wang, S. Zhang, R. Xu, Mapnav: A novel memory representation via annotated semantic maps for vision-and-language navigation, arXiv preprint arXiv:2502.13451 (2025). arXiv:2502.13451
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
-
[18]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al., Palm-e: An embodied multi- modal language model, in: International Conference on Machine Learning, 2023, pp. 8469–8488. 32
2023
-
[19]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choroman- ski, T. Ding, D. Driess, A. Dubey, C. Finn, et al., Rt-2: Vision-language- action models transfer web knowledge to robotic control, arXiv preprint arXiv:2307.15818 (2023). arXiv:2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al., Openvla: An open-source vision-language-action model, arXiv preprint arXiv:2406.09246 (2024). arXiv:2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
D. Jing, J. Nie, T. Zhang, J. Liu, H. Yao, Z. Lu, M. Ding, Tem- povla: Learning speed-controllable vision-language-action policies (2026). arXiv:2606.06491. URLhttps://arxiv.org/abs/2606.06491
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
S. Liu, H. Zhang, Y . Qi, P. Wang, Y . Zhang, Q. Wu, Aerialvln: Vision-and- language navigation for uavs, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15384–15394
2023
- [23]
- [24]
-
[25]
Optimal Trajectory-Planning of UAVs via B-Splines and Disjunctive Programming
A. Babaei, A. Karimi, Optimal trajectory-planning of uavs via b-splines and disjunctive programming, arXiv preprint arXiv:1807.02931 (2018). arXiv:1807.02931
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [26]
- [27]
- [28]
- [29]
-
[30]
C. Chi, S. Feng, S. Du, Z. Xu, E. Cousineau, B. Burchfiel, S. Song, Diffu- sion policy: Visuomotor policy learning via action diffusion, arXiv preprint arXiv:2303.04137 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.,π 0: A vision-language-action flow model for general robot control, arXiv preprint arXiv:2410.24164 (2024). arXiv:2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [32]
-
[33]
S. Shah, D. Dey, C. Lovett, A. Kapoor, Airsim: High-fidelity visual and physical simulation for autonomous vehicles, in: Field and Service Robotics, 2017
2017
- [34]
-
[35]
Embodied navigation foundation model, 2025
J. Zhang, A. Li, Y . Qi, M. Li, J. Liu, S. Wang, H. Liu, G. Zhou, Y . Wu, X. Li, et al., Embodied navigation foundation model, arXiv preprint arXiv:2509.12129 (2025)
- [36]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.