SurgVista: Long-Horizon Surgical World Modeling with Plausible Instrument-Tissue Dynamics
Pith reviewed 2026-06-26 18:07 UTC · model grok-4.3
The pith
SurgVista generates long-horizon surgical video predictions with consistent instrument-tissue interactions by enforcing deformation coherence and adapting to drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
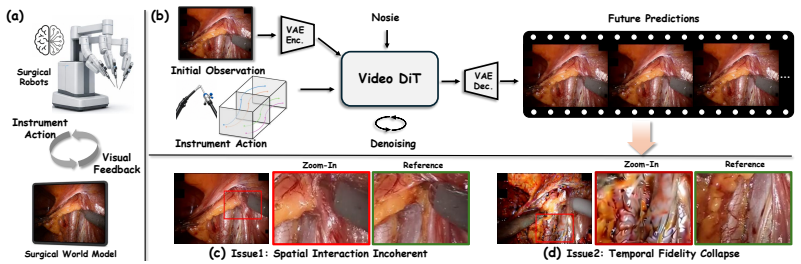
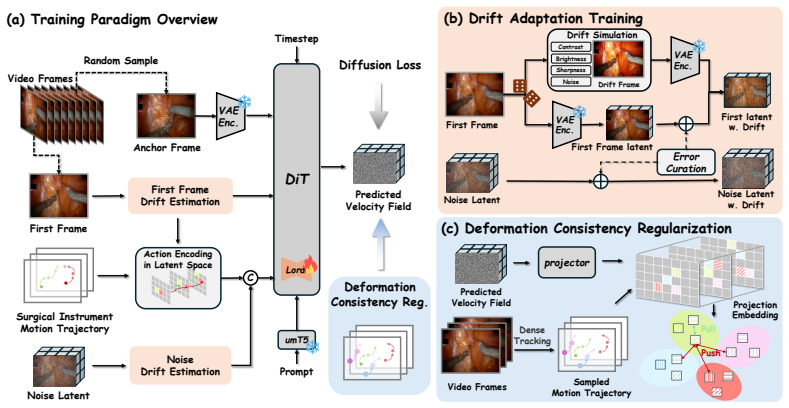
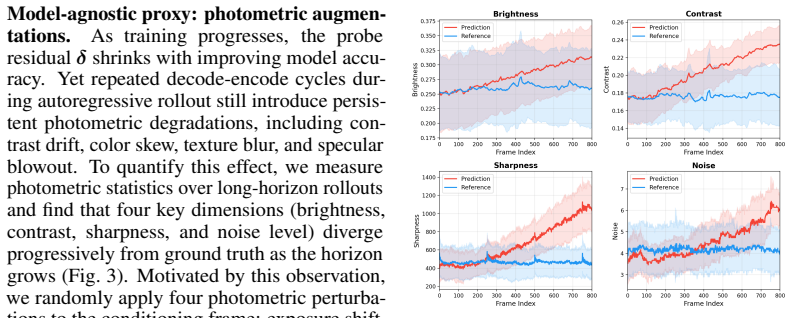
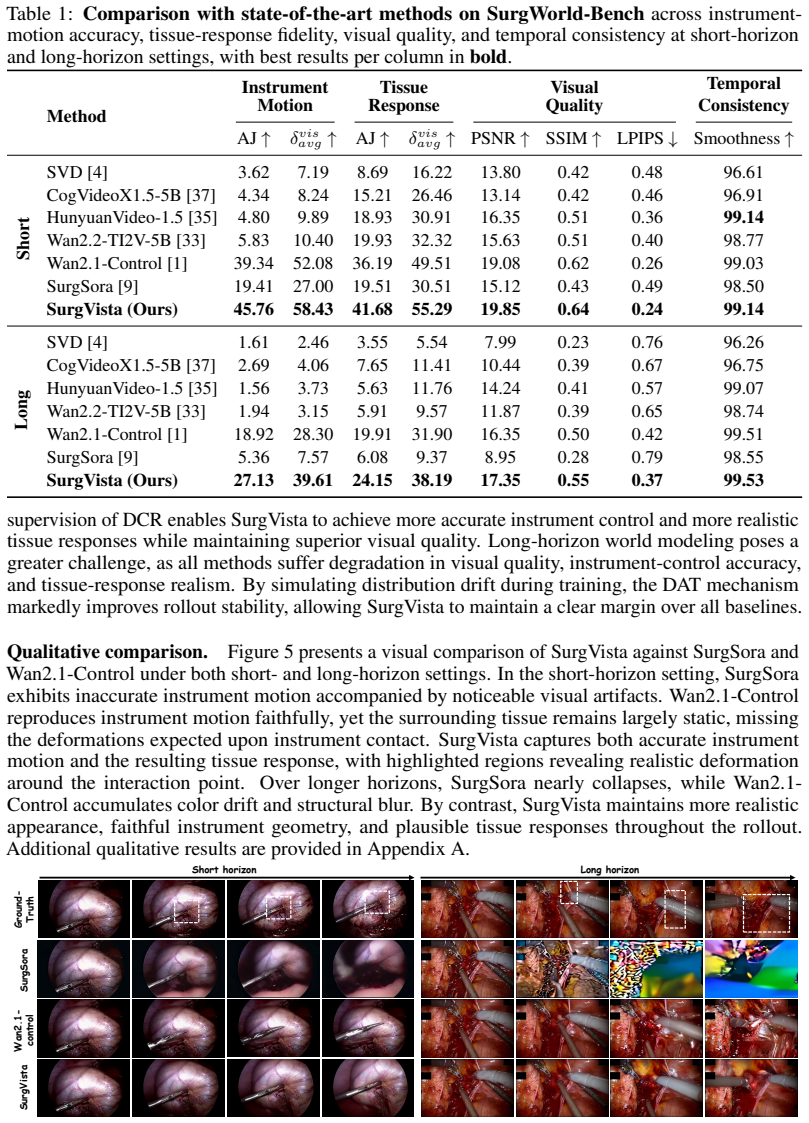
SurgVista mitigates spatial interaction incoherence and temporal fidelity collapse in surgical world models through Deformation Consistency Regularization, which extracts scene-point trajectories from training videos and enforces cross-frame coherence through latent contrastive learning to strengthen physically consistent instrument-tissue dynamics, and Drift Adaptation Training, which mitigates long-horizon drift by perturbing conditioning frames with online prediction residuals and photometric augmentations calibrated to long-horizon drift statistics, sustaining visual fidelity over extended rollouts, as shown by consistent outperformance on SurgWorld-Bench with gains that widen at longer
What carries the argument
Deformation Consistency Regularization extracts scene-point trajectories and enforces cross-frame coherence via latent contrastive learning; Drift Adaptation Training perturbs conditioning frames with residuals and augmentations to counter drift accumulation.
If this is right
- Prediction quality and interaction fidelity hold up better than prior methods as the number of future frames increases.
- Instrument contact produces spatially consistent tissue deformation instead of incoherent motion.
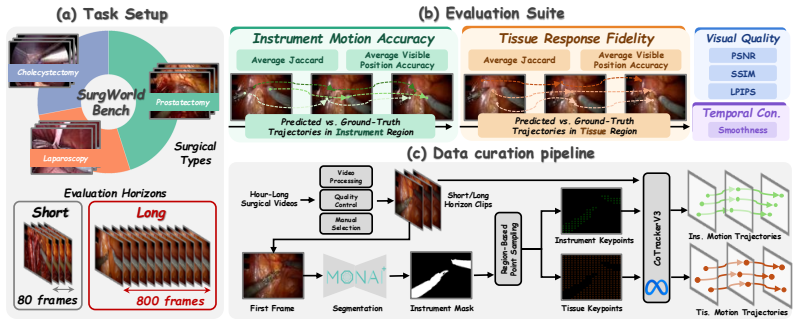
- The introduced benchmark separates evaluation of motion accuracy from tissue-response fidelity across diverse procedures.
- World-model training can proceed without direct in vivo exploration by generating extended action-conditioned sequences.
Where Pith is reading between the lines
- The trajectory-based contrastive approach could transfer to video prediction tasks involving other deformable surfaces outside surgery.
- If the methods scale, they would lower the volume of expert demonstrations needed for policy learning in contact-rich robotics.
- A direct test would compare the learned dynamics against measured force or deformation data from instrumented phantoms.
Load-bearing premise
Enforcing cross-frame coherence on extracted scene-point trajectories through latent contrastive learning produces physically consistent instrument-tissue dynamics rather than merely visually plausible motion.
What would settle it
Long-horizon rollouts that produce tissue deformations violating basic physical constraints such as volume conservation or elasticity rules, while still scoring high on visual and contrastive metrics.
Figures
read the original abstract
Scaling robot policy learning for autonomous surgery is challenging, as expert demonstrations are expensive and in vivo exploration poses substantial safety risks. Surgical world models address this by generating realistic, action-conditioned future frames from an initial observation, but existing methods exhibit two persistent failure modes: spatial interaction incoherence, where visible instrument contact fails to induce spatially consistent tissue deformation, and temporal fidelity collapse, where prediction errors compound across autoregressive rollouts and progressively corrupt visual quality. We present SurgVista, a surgical world model that mitigates both failures through two training recipes. Deformation Consistency Regularization extracts scene-point trajectories from training videos and enforces cross-frame coherence through latent contrastive learning, strengthening physically consistent instrument-tissue dynamics. Drift Adaptation Training mitigates long-horizon drift by perturbing conditioning frames with online prediction residuals and photometric augmentations calibrated to long-horizon drift statistics, sustaining visual fidelity over extended rollouts. To enable rigorous evaluation, we further introduce SurgWorld-Bench, featuring diverse procedure types, long-range rollouts, and decoupled metrics for instrument-motion accuracy and tissue-response fidelity. Extensive experiments show that SurgVista consistently outperforms state-of-the-art methods across visual quality, temporal consistency, and interaction fidelity, with gains widening as the prediction horizon grows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SurgVista, a surgical world model for generating action-conditioned future frames in robotic surgery. It proposes two training recipes—Deformation Consistency Regularization, which extracts scene-point trajectories from videos and applies latent contrastive learning to enforce cross-frame coherence, and Drift Adaptation Training, which perturbs conditioning frames with prediction residuals and photometric augmentations—to address spatial interaction incoherence and temporal fidelity collapse. The work also introduces SurgWorld-Bench for evaluating long-range rollouts with decoupled metrics on instrument motion and tissue response. Experiments claim that SurgVista outperforms state-of-the-art methods on visual quality, temporal consistency, and interaction fidelity, with gains increasing over longer prediction horizons.
Significance. If validated, the contributions could meaningfully advance world-model-based policy learning for autonomous surgery by mitigating key failure modes in long-horizon prediction. The introduction of SurgWorld-Bench provides a useful standardized evaluation resource for the community. The trajectory-based contrastive regularization is a reasonable attempt to inject consistency priors without explicit physics simulation.
major comments (3)
- [Section 3.1] Section 3.1 (Deformation Consistency Regularization): the claim that latent contrastive learning on extracted scene-point trajectories yields 'physically consistent instrument-tissue dynamics' lacks supporting evidence; the method enforces cross-frame coherence in latent space but provides no ablation, comparison to physics-based simulators, or biomechanical measurements to distinguish physical validity from temporally smooth but non-physical motion.
- [SurgWorld-Bench and evaluation] SurgWorld-Bench description and evaluation metrics: the decoupled 'tissue-response fidelity' metric is presented as capturing interaction quality, yet the paper does not demonstrate that it measures adherence to real biomechanical constraints rather than visual or kinematic plausibility; this distinction is load-bearing for the central claim that the regularization produces physically consistent dynamics.
- [Experiments] Experiments section: while outperformance is asserted across visual quality, temporal consistency, and interaction fidelity with widening gains at longer horizons, the manuscript supplies no quantitative tables, specific metric values, baseline implementations, or statistical tests in the provided description, preventing assessment of whether the data actually support the stated claims.
minor comments (1)
- [Abstract] Abstract: including at least one key quantitative result (e.g., a primary metric improvement at a given horizon) would strengthen the summary of contributions.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment point by point below, providing clarifications and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Section 3.1] Section 3.1 (Deformation Consistency Regularization): the claim that latent contrastive learning on extracted scene-point trajectories yields 'physically consistent instrument-tissue dynamics' lacks supporting evidence; the method enforces cross-frame coherence in latent space but provides no ablation, comparison to physics-based simulators, or biomechanical measurements to distinguish physical validity from temporally smooth but non-physical motion.
Authors: We agree that the regularization enforces cross-frame coherence in latent space via contrastive learning on trajectories and does not explicitly model or validate physical laws. The phrasing 'physically consistent' in the manuscript is interpretive rather than directly evidenced by biomechanical data. We will revise Section 3.1 and related claims to describe the outcome as 'plausible instrument-tissue dynamics' consistent with observed trajectories. We will add an ablation isolating the regularization's effect on coherence metrics. Direct comparisons to physics-based simulators or biomechanical measurements are not feasible within this data-driven framework without new resources. revision: partial
-
Referee: [SurgWorld-Bench and evaluation] SurgWorld-Bench description and evaluation metrics: the decoupled 'tissue-response fidelity' metric is presented as capturing interaction quality, yet the paper does not demonstrate that it measures adherence to real biomechanical constraints rather than visual or kinematic plausibility; this distinction is load-bearing for the central claim that the regularization produces physically consistent dynamics.
Authors: We concur that the tissue-response fidelity metric evaluates visual and kinematic alignment with observed deformations rather than verifying biomechanical constraints. This is an inherent limitation of video-based evaluation. We will revise the SurgWorld-Bench description and central claims to specify that the metric assesses visual plausibility and consistency with real data trajectories, removing implications of biomechanical validation. revision: yes
-
Referee: [Experiments] Experiments section: while outperformance is asserted across visual quality, temporal consistency, and interaction fidelity with widening gains at longer horizons, the manuscript supplies no quantitative tables, specific metric values, baseline implementations, or statistical tests in the provided description, preventing assessment of whether the data actually support the stated claims.
Authors: The complete manuscript contains quantitative tables with specific metric values, baseline implementation details, and statistical test results in the Experiments section. We will ensure these elements are clearly highlighted and cross-referenced in the revised submission to facilitate assessment. revision: no
- Direct biomechanical measurements or comparisons against physics-based simulators to substantiate physical validity claims, as these require additional data collection and expertise outside the current video-based study.
Circularity Check
No significant circularity; training recipes and metrics are independently specified.
full rationale
The paper defines two explicit training procedures—Deformation Consistency Regularization (extracting trajectories then applying latent contrastive learning) and Drift Adaptation Training (perturbing frames with residuals and augmentations)—as new recipes that address stated failure modes. These are not shown to reduce to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. Evaluation relies on a new benchmark with decoupled metrics for instrument motion and tissue response, presented as empirical comparisons rather than derivations that collapse to inputs by construction. No uniqueness theorems, ansatzes via prior self-work, or renaming of known results appear in the provided description. The central claims remain falsifiable via the stated visual, temporal, and interaction metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pixel-wise recognition for holistic surgical scene understanding // Medical Image Analysis
Ayobi Nicolás, Rodríguez Santiago, Pérez Alejandra, Hernández Isabela, Aparicio Nicolás, Dessevres Eugénie, Peña Sebastián, Santander Jessica, Caicedo Juan Ignacio, Fernández Nicolás, others. Pixel-wise recognition for holistic surgical scene understanding // Medical Image Analysis. 2025. 103726
2025
-
[2]
Hierasurg: Hierarchy-aware diffusion model for surgical video generation // International Conference on Medical Image Computing and Computer-Assisted Intervention
Biagini Diego, Navab Nassir, Farshad Azade. Hierasurg: Hierarchy-aware diffusion model for surgical video generation // International Conference on Medical Image Computing and Computer-Assisted Intervention. 2025. 310–319
2025
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann Andreas, Dockhorn Tim, Kulal Sumith, Mendelevitch Daniel, Kilian Maciej, Lorenz Dominik, Levi Yam, English Zion, Voleti Vikram, Letts Adam, others. Stable video diffusion: Scaling latent video diffusion models to large datasets // arXiv preprint arXiv:2311.15127. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Genie: generative interactive environments // Proceedings of the 41st International Conference on Machine Learning
Bruce Jake, Dennis Michael, Edwards Ashley, Parker-Holder Jack, Shi Yuge, Hughes Edward, Lai Matthew, Mavalankar Aditi, Steigerwald Richie, Apps Chris, others. Genie: generative interactive environments // Proceedings of the 41st International Conference on Machine Learning. 2024. 4603–4623
2024
-
[5]
MONAI: An open-source framework for deep learning in healthcare
Cardoso M Jorge, Li Wenqi, Brown Richard, Ma Nic, Kerfoot Eric, Wang Yiheng, Murrey Benjamin, Myronenko Andriy, Zhao Can, Yang Dong, others. Monai: An open-source framework for deep learning in healthcare // arXiv preprint arXiv:2211.02701. 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Diffusion forcing: Next-token prediction meets full-sequence diffusion // Advances in Neural Information Processing Systems
Chen Boyuan, Martí Monsó Diego, Du Yilun, Simchowitz Max, Tedrake Russ, Sitzmann Vincent. Diffusion forcing: Next-token prediction meets full-sequence diffusion // Advances in Neural Information Processing Systems. 2024. 37. 24081–24125
2024
-
[7]
A simple framework for contrastive learning of visual representations // International conference on machine learning
Chen Ting, Kornblith Simon, Norouzi Mohammad, Hinton Geoffrey. A simple framework for contrastive learning of visual representations // International conference on machine learning. 2020. 1597–1607
2020
-
[8]
Surgsora: Object-aware diffusion model for controllable surgical video generation // International Conference on Medical Image Computing and Computer-Assisted Intervention
Chen Tong, Yang Shuya, Wang Junyi, Bai Long, Ren Hongliang, Zhou Luping. Surgsora: Object-aware diffusion model for controllable surgical video generation // International Conference on Medical Image Computing and Computer-Assisted Intervention. 2025. 521–531
2025
-
[9]
Chu Ruihang, He Yefei, Chen Zhekai, Zhang Shiwei, Xu Xiaogang, Xia Bin, Wang Dingdong, Yi Hongwei, Liu Xihui, Zhao Hengshuang, others. Wan-move: Motion-controllable video generation via latent trajectory guidance // arXiv preprint arXiv:2512.08765. 2025
-
[10]
Robotic surgery // Nature Reviews Bioengineering
Ciuti Gastone, Webster III Robert J, Kwok Ka-Wai, Menciassi Arianna. Robotic surgery // Nature Reviews Bioengineering. 2025. 3, 7. 565–578
2025
-
[11]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Cui Justin, Wu Jie, Li Ming, Yang Tao, Li Xiaojie, Wang Rui, Bai Andrew, Ban Yuanhao, Hsieh Cho-Jui. Self-Forcing++: Towards Minute-Scale High-Quality Video Generation // arXiv preprint arXiv:2510.02283. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Doersch Carl, Gupta Ankush, Markeeva Larisa, Recasens Adria, Smaira Lucas, Aytar Yusuf, Carreira Joao, Zisserman Andrew, Yang Yi. Tap-vid: A benchmark for tracking any point in a video // Advances in Neural Information Processing Systems. 2022. 35. 13610–13626. [14]Ha David, Schmidhuber Jürgen. World models // arXiv preprint arXiv:1803.10122. 2018. 2, 3. 440
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Dream to Control: Learning Behaviors by Latent Imagination
Hafner Danijar, Lillicrap Timothy, Ba Jimmy, Norouzi Mohammad. Dream to control: Learning behaviors by latent imagination // arXiv preprint arXiv:1912.01603. 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[14]
Mastering Diverse Domains through World Models
Hafner Danijar, Pasukonis Jurgis, Ba Jimmy, Lillicrap Timothy. Mastering diverse domains through world models // arXiv preprint arXiv:2301.04104. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Momentum contrast for unsupervised visual representation learning // Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He Kaiming, Fan Haoqi, Wu Yuxin, Xie Saining, Girshick Ross. Momentum contrast for unsupervised visual representation learning // Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020. 9729–9738
2020
-
[16]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
He Xianglong, Peng Chunli, Liu Zexiang, Wang Boyang, Zhang Yifan, Cui Qi, Kang Fei, Jiang Biao, An Mengyin, Ren Yangyang, others. Matrix-game 2.0: An open-source real-time and streaming interactive world model // arXiv preprint arXiv:2508.13009. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
He Yufan, Guo Pengfei, Xu Mengya, Li Zhaoshuo, Myronenko Andriy, Imans Dillan, Liu Bingjie, Yang Dongren, Gu Mingxue, Ji Yongnan, others. SurgWorld: Learning Surgical Robot Policies from Videos via World Modeling // arXiv preprint arXiv:2512.23162. 2025. 10
-
[18]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text // Proceedings of the Computer Vision and Pattern Recognition Conference
Henschel Roberto, Khachatryan Levon, Poghosyan Hayk, Hayrapetyan Daniil, Tadevosyan Vahram, Wang Zhangyang, Navasardyan Shant, Shi Humphrey. Streamingt2v: Consistent, dynamic, and extendable long video generation from text // Proceedings of the Computer Vision and Pattern Recognition Conference
-
[19]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang Xun, Li Zhengqi, He Guande, Zhou Mingyuan, Shechtman Eli. Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion // arXiv preprint arXiv:2506.08009. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Vbench: Comprehensive benchmark suite for video generative models // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang Ziqi, He Yinan, Yu Jiashuo, Zhang Fan, Si Chenyang, Jiang Yuming, Zhang Yuanhan, Wu Tianxing, Jin Qingyang, Chanpaisit Nattapol, others. Vbench: Comprehensive benchmark suite for video generative models // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. 21807–21818
2024
-
[21]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos // Proceedings of the IEEE/CVF International Conference on Computer Vision
Karaev Nikita, Makarov Yuri, Wang Jianyuan, Neverova Natalia, Vedaldi Andrea, Rupprecht Christian. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos // Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025. 6013–6022
2025
-
[22]
Stable Video Infinity: Infinite-Length Video Generation with Error Recycling // International Conference on Learning Representations 2025 (ICLR 2025)
Li Wuyang, Pan Wentao, Luan Po-Chien, Gao Yang, Alahi Alexandre. Stable Video Infinity: Infinite-Length Video Generation with Error Recycling // International Conference on Learning Representations 2025 (ICLR 2025). 2026
2025
-
[23]
Elucidating the Exposure Bias in Diffusion Models // 12th International Conference on Learning Representations, ICLR 2024
Ning Mang, Li Mingxiao, Su Jianlin, Salah Albert Ali, Ertugrul Itir Onal. Elucidating the Exposure Bias in Diffusion Models // 12th International Conference on Learning Representations, ICLR 2024. 2024
2024
-
[24]
Cholectrack20: A multi-perspective tracking dataset for surgical tools // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Nwoye Chinedu Innocent, Elgohary Kareem, Srinivas Anvita, Zaid Fauzan, Lavanchy Joël L, Padoy Nicolas. Cholectrack20: A multi-perspective tracking dataset for surgical tools // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2025. 8942–8952
2025
-
[25]
Rapuri Sampath, Seenivasan Lalithkumar, Schneider Dominik, Soberanis-Mukul Roger, He Yufan, Ding Hao, Xu Jiru, Yu Chenhao, Jing Chenyan, Guo Pengfei, others. SAW: Toward a Surgical Action World Model via Controllable and Scalable Video Generation // arXiv preprint arXiv:2603.13024. 2026
-
[26]
General-purpose foundation models for increased autonomy in robot-assisted surgery // Nature Machine Intelligence
Schmidgall Samuel, Kim Ji Woong, Kuntz Alan, Ghazi Ahmed Ezzat, Krieger Axel. General-purpose foundation models for increased autonomy in robot-assisted surgery // Nature Machine Intelligence. 2024. 6, 11. 1275–1283
2024
-
[27]
Generalization in generation: A closer look at exposure bias // Proceedings of the 3rd Workshop on Neural Generation and Translation
Schmidt Florian. Generalization in generation: A closer look at exposure bias // Proceedings of the 3rd Workshop on Neural Generation and Translation. 2019. 157–167
2019
-
[28]
History-Guided Video Diffusion // International Conference on Machine Learning
Song Kiwhan, Chen Boyuan, Simchowitz Max, Du Yilun, Tedrake Russ, Sitzmann Vincent. History-Guided Video Diffusion // International Conference on Machine Learning. 2025. 56242–56280
2025
-
[29]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Sun Wenqiang, Zhang Haiyu, Wang Haoyuan, Wu Junta, Wang Zehan, Wang Zhenwei, Wang Yunhong, Zhang Jun, Wang Tengfei, Guo Chunchao. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling // arXiv preprint arXiv:2512.14614. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Turkcan Mehmet Kerem, Ballo Mattia, Filicori Filippo, Kostic Zoran. Towards Suturing World Models: Learning Predictive Models for Robotic Surgical Tasks // arXiv preprint arXiv:2503.12531. 2025
-
[31]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team, Wang Ang, Ai Baole, Wen Bin, Mao Chaojie, Xie Chen-Wei, Chen Di, Yu Feiwu, Zhao Haiming, Yang Jianxiao, others. Wan: Open and advanced large-scale video generative models // arXiv preprint arXiv:2503.20314. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Wang Zile, Liu Zexiang, Li Jaixing, Huang Kaichen, Xu Baixin, Kang Fei, An Mengyin, Wang Peiyu, Jiang Biao, Wei Yichen, others. Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory // arXiv preprint arXiv:2604.08995. 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
HunyuanVideo 1.5 Technical Report
Wu Bing, Zou Chang, Li Changlin, Huang Duojun, Yang Fang, Tan Hao, Peng Jack, Wu Jianbing, Xiong Jiangfeng, Jiang Jie, others. Hunyuanvideo 1.5 technical report // arXiv preprint arXiv:2511.18870. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Medical World Model // Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang Yijun, Wang Zhao-Yang, Liu Qiuping, Sun Shuwen, Wang Kang, Chellappa Rama, Zhou Zongwei, Yuille Alan, Zhu Lei, Zhang Yu-Dong, others. Medical World Model // Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025. 8319–8329
2025
-
[35]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang Zhuoyi, Teng Jiayan, Zheng Wendi, Ding Ming, Huang Shiyu, Xu Jiazheng, Yang Yuanming, Hong Wenyi, Zhang Xiaohan, Feng Guanyu, others. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer // arXiv preprint arXiv:2408.06072. 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
arXiv preprint arXiv:2504.12626 (2025)
Zhang Lvmin, Cai Shengqu, Li Muyang, Wetzstein Gordon, Agrawala Maneesh. Frame context packing and drift prevention in next-frame-prediction video diffusion models // arXiv preprint arXiv:2504.12626. 2025
-
[37]
The unreasonable effectiveness of deep features as a perceptual metric // Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang Richard, Isola Phillip, Efros Alexei A, Shechtman Eli, Wang Oliver. The unreasonable effectiveness of deep features as a perceptual metric // Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. 586–595. [40]Zia Aneeq, Berniker Max, Garcia Nespolo Rogerio, Perreault Conor, Bhattacharyya Kiran, Liu Xi, Wang Ziheng, Kon...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.