HABIT: Human-Aware Behavior and Interaction Training Dataset for Robot Manipulation
Pith reviewed 2026-07-01 05:29 UTC · model grok-4.3
The pith
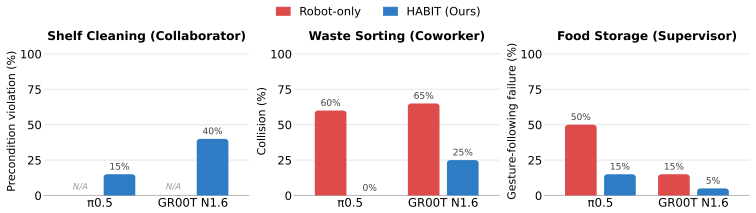
Training on human-present robot data produces synchronization, yielding, and gesture responses absent from human-absent data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
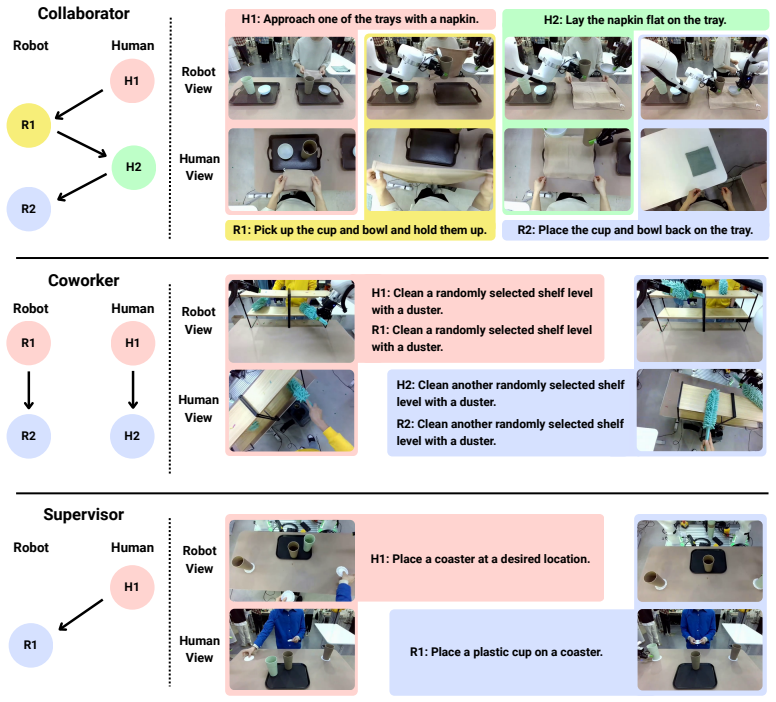
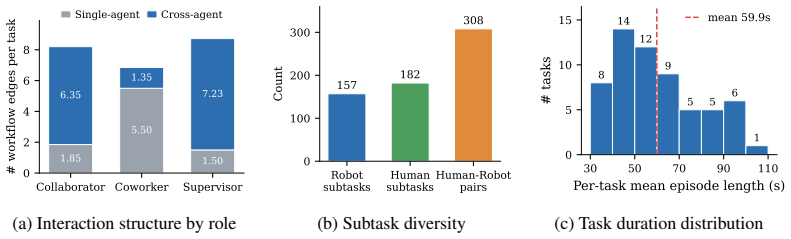
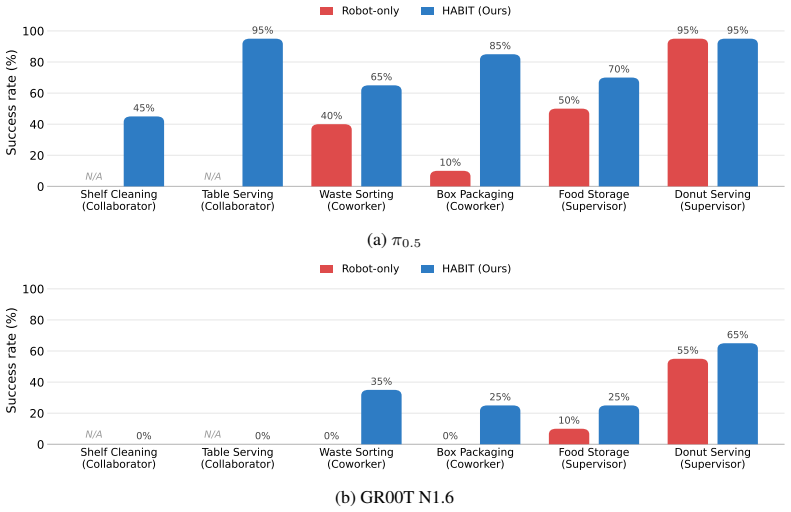
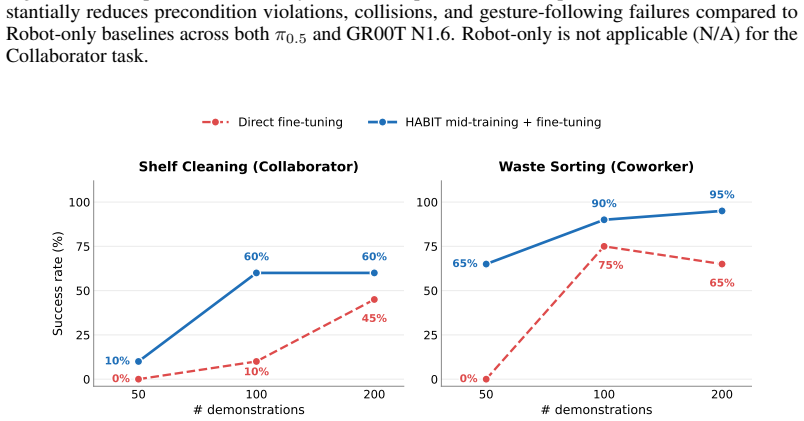
The paper claims that a dataset of robot demonstrations collected with humans present, organized by the three roles of Collaborator, Coworker, and Supervisor and totaling over 10K episodes, produces policies that exhibit human-aware behaviors including spatiotemporal synchronization in joint tasks, yielding in shared-space separate tasks, and gesture grounding in directed tasks; these behaviors do not emerge from training on human-absent data, and the dataset further enables rapid adaptation to new interaction tasks.
What carries the argument
HABIT dataset structured by Collaborator, Coworker, and Supervisor interaction roles, which supplies the human-present demonstrations used to elicit the target behaviors.
If this is right
- Policies trained on HABIT exhibit spatiotemporal synchronization during joint human-robot tasks.
- Policies yield space to humans when both pursue separate tasks in the same environment.
- Policies respond to human gestures as instructions in supervisory settings.
- Training on HABIT produces faster adaptation to previously unseen human-robot interaction tasks.
- Robot policies gain the capacity to operate in environments shared with humans by incorporating this form of data diversity.
Where Pith is reading between the lines
- Future work could measure whether the learned behaviors reduce collision rates or interruptions in unstructured home or factory settings.
- The supervisor role could be extended by pairing the dataset with language models to handle more open-ended instructions.
- Adding metrics of social comfort or task efficiency alongside the reported behaviors would strengthen evidence of practical value.
- Other existing robot benchmarks could be re-collected with humans present to isolate the contribution of this diversity axis.
Load-bearing premise
The three interaction roles and the collected episodes sufficiently represent real-world human-robot dynamics to produce generalizable human-aware policies.
What would settle it
A controlled test in which policies trained on HABIT show no measurable increase in synchronization, yielding, or gesture response compared with policies trained on matched human-absent data would falsify the central claim.
Figures














read the original abstract
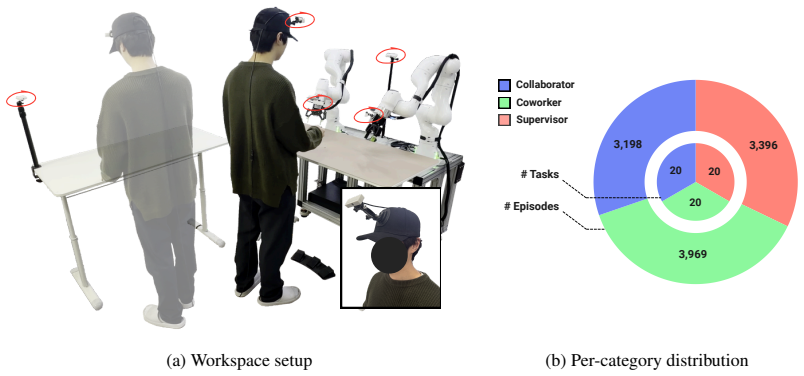
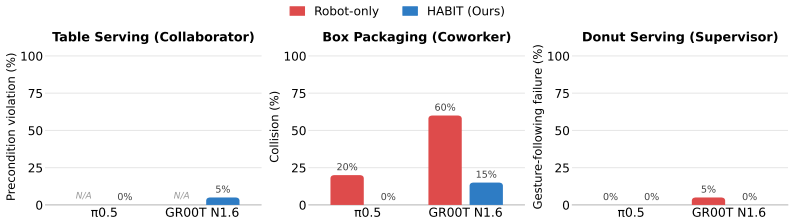
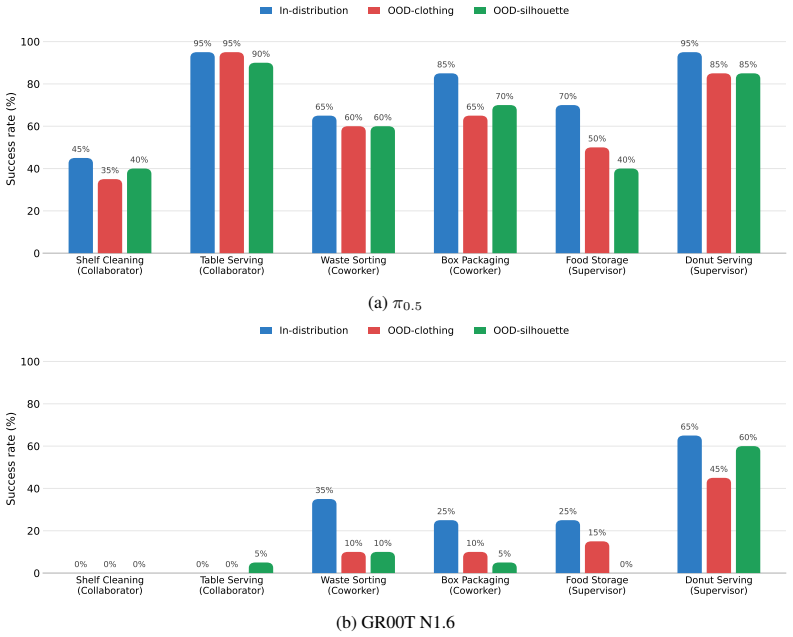
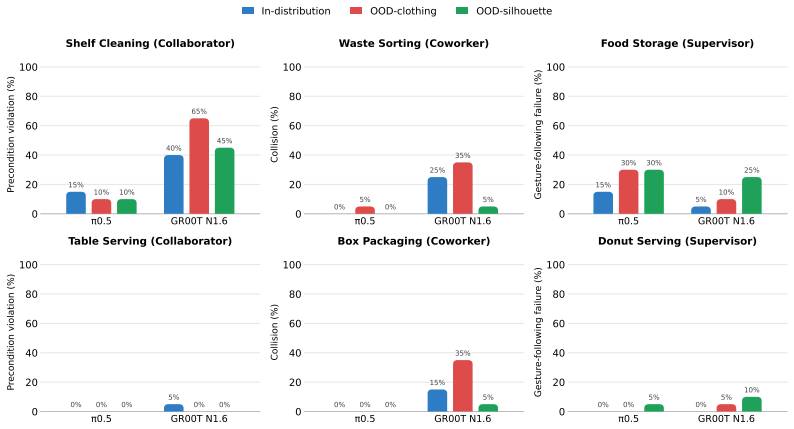
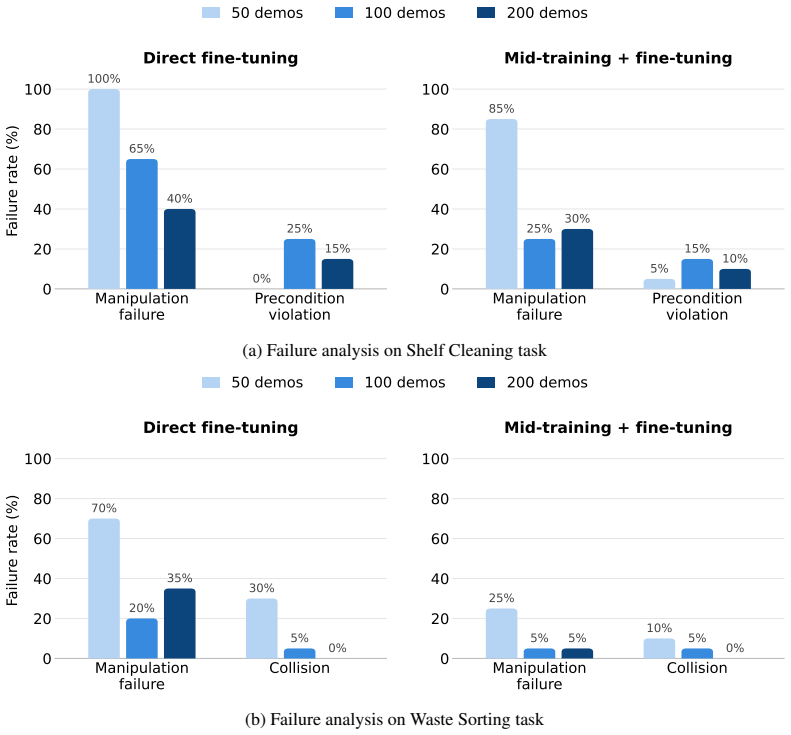
Large-scale demonstration datasets have been central to recent progress in general-purpose robot policies. However, existing datasets are collected in human-absent settings, and policies trained on such data may perform tasks competently in isolation but fail to exhibit human-aware behaviors. To address this gap, we introduce HABIT, a large-scale robot demonstration dataset for human-present environments. We organize tasks into three roles capturing distinct modes of human-robot interaction: Collaborator, where human and robot jointly accomplish a task; Coworker, where they pursue separate tasks in a shared space; and Supervisor, where the human directs the robot. The dataset comprises over 10K episodes and over 160 hours across 60 tasks. Our experiments show that training on human-present data elicits human-aware behaviors that robot-only data fails to produce: spatiotemporal synchronization in Collaborator tasks, yielding in Coworker tasks, and gesture grounding in Supervisor tasks. Moreover, training on HABIT enables rapid adaptation to new human-robot interaction tasks. By introducing human presence as a new axis of dataset diversity, HABIT extends robot policies to environments shared with humans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HABIT, a large-scale robot demonstration dataset comprising over 10K episodes and 160 hours across 60 tasks in human-present environments. Tasks are organized into three interaction roles—Collaborator (joint task accomplishment), Coworker (separate tasks in shared space), and Supervisor (human directs the robot). The central claim is that policies trained on this human-present data exhibit human-aware behaviors (spatiotemporal synchronization, yielding, and gesture grounding) absent in robot-only training, and that the dataset enables rapid adaptation to new human-robot interaction tasks.
Significance. If substantiated, HABIT would provide a useful new resource by adding human presence as an axis of diversity to robot manipulation datasets, potentially supporting development of policies that handle shared environments. The scale and role-based organization are strengths for studying distinct interaction modes. The work supplies a concrete dataset contribution at a time when large-scale demonstrations drive progress in robot learning.
major comments (2)
- [Abstract] Abstract: the claim that training on human-present data elicits spatiotemporal synchronization, yielding, and gesture grounding (absent from robot-only data) and enables rapid adaptation lacks any reported metrics, baseline comparisons, statistical details, or data collection protocols, which are load-bearing for the central empirical claims.
- [Dataset Collection / Experiments] Dataset and Experiments sections: no evidence is supplied that the 60 tasks and collected episodes capture representative human variability in motions, intent signaling, or environmental factors; without this, it is unclear whether observed behaviors arise from human presence per se or from dataset artifacts, directly affecting the generalizability and adaptation assertions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the manuscript and indicate where revisions will strengthen the empirical presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that training on human-present data elicits spatiotemporal synchronization, yielding, and gesture grounding (absent from robot-only data) and enables rapid adaptation lacks any reported metrics, baseline comparisons, statistical details, or data collection protocols, which are load-bearing for the central empirical claims.
Authors: The abstract provides a concise summary of the central findings, while the Experiments section (Section 5) reports the supporting quantitative results, including task success rates, synchronization metrics (e.g., temporal alignment errors), yielding behaviors, gesture recognition accuracy, and adaptation performance with comparisons to robot-only baselines. Statistical details and data collection protocols are described in Sections 3 and 4. We agree the abstract would be strengthened by including a few key metrics; the revised version will incorporate concise quantitative highlights and explicit references to the relevant sections. revision: yes
-
Referee: [Dataset Collection / Experiments] Dataset and Experiments sections: no evidence is supplied that the 60 tasks and collected episodes capture representative human variability in motions, intent signaling, or environmental factors; without this, it is unclear whether observed behaviors arise from human presence per se or from dataset artifacts, directly affecting the generalizability and adaptation assertions.
Authors: Section 3 details the data collection protocol, which involved multiple human participants across varied demographics, motion styles, and environmental conditions to elicit natural variability in the three interaction roles. The Experiments section compares policies trained on HABIT versus robot-only data, showing the emergence of the target behaviors only in the human-present setting. To further substantiate representativeness, the revision will add explicit quantitative analysis of motion variability (e.g., trajectory variance statistics) and intent signaling diversity. revision: partial
Circularity Check
Empirical dataset paper with no derivations or self-referential predictions
full rationale
The paper introduces the HABIT dataset and reports empirical results from training policies on it versus robot-only data. No equations, fitted parameters, or predictions are claimed; the central claims are direct observations from experiments (synchronization, yielding, gesture grounding, adaptation). These are externally falsifiable by replication and do not reduce to inputs by construction. No self-citation load-bearing steps or ansatzes are present. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Bc-z: Zero-shot task generalization with robotic imitation learning
Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. Inconference on Robot Learning, 2022
2022
-
[3]
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Chenxi Wang, Junbo Wang, Haoyi Zhu, and Cewu Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot. InInternational Conference on Robotics and Automation, 2024
2024
-
[4]
Open X- Embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
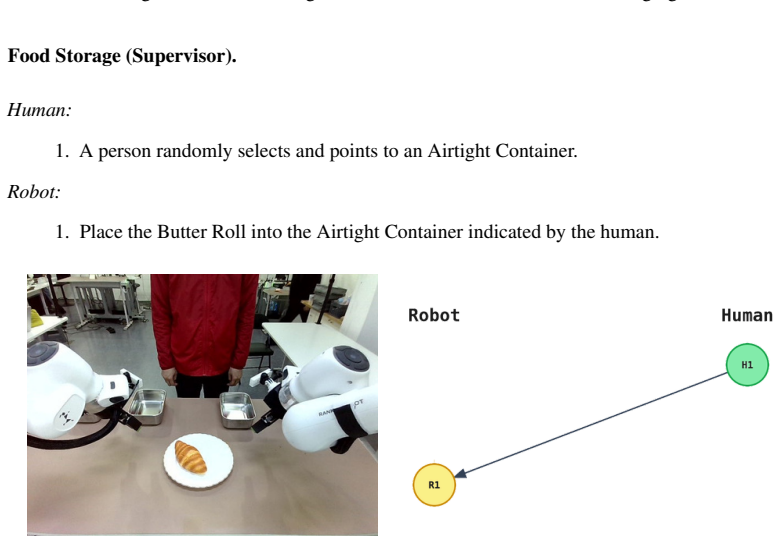
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open X- Embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. InInternational Conference on Robotics and Automation, 2024
2024
-
[5]
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
RoboNet: Large-Scale Multi-Robot Learning
Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, and Chelsea Finn. Robonet: Large-scale multi-robot learning. arXiv preprint arXiv:1910.11215, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[7]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. AgiBot World Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. DROID: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, 2023
2023
-
[10]
Ego4D: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4D: Around the world in 3,000 hours of egocentric video. InIEEE/CVF conference on computer vision and pattern recognition, 2022
2022
-
[11]
Ego-Exo4D: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyl- los Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-Exo4D: Understanding skilled human activity from first-and third-person perspectives. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[12]
EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Ryan Punamiya, Simar Kareer, Zeyi Liu, Josh Citron, Ri-Zhao Qiu, Xiongyi Cai, Alexey Gavryushin, Jiaqi Chen, Davide Liconti, Lawrence Y Zhu, et al. Egoverse: An egocentric human dataset for robot learning from around the world.arXiv preprint arXiv:2604.07607, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Egoscale: Scaling dexterous manipulation with diverse egocentric human data
Ruijie Zheng, Dantong Niu, Yuqi Xie, Jing Wang, Mengda Xu, Yunfan Jiang, Fernando Castañeda, Fengyuan Hu, You Liang Tan, Letian Fu, et al. Egoscale: Scaling dexterous manipulation with diverse egocentric human data.arXiv preprint arXiv:2602.16710, 2026
-
[14]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, 2023
2023
-
[19]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, et al. Cosmos Policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Video Generators are Robot Policies
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic-video: Video-action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Human–robot collaboration: a survey.Interna- tional Journal of Humanoid Robotics, 5(01):47–66, 2008
Andrea Bauer, Dirk Wollherr, and Martin Buss. Human–robot collaboration: a survey.Interna- tional Journal of Humanoid Robotics, 5(01):47–66, 2008
2008
-
[24]
Theory and evaluation of human robot interactions
Jean Scholtz. Theory and evaluation of human robot interactions. InHawaii International Conference on System Sciences, 2003
2003
-
[25]
A taxonomy to structure and analyze human–robot interac- tion.International Journal of Social Robotics, 13(4):833–849, 2021
Linda Onnasch and Eileen Roesler. A taxonomy to structure and analyze human–robot interac- tion.International Journal of Social Robotics, 13(4):833–849, 2021
2021
-
[26]
How to communicate robot motion intent: A scoping review
Max Pascher, Uwe Gruenefeld, Stefan Schneegass, and Jens Gerken. How to communicate robot motion intent: A scoping review. InConference on Human Factors in Computing Systems, 2023
2023
-
[27]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: A vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours
Lerrel Pinto and Abhinav Gupta. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. InInternational conference on robotics and automation, 2016
2016
-
[29]
Multiple interactions made easy (mime): Large scale demonstrations data for imitation
Pratyusha Sharma, Lekha Mohan, Lerrel Pinto, and Abhinav Gupta. Multiple interactions made easy (mime): Large scale demonstrations data for imitation. InConference on robot learning, 2018
2018
-
[30]
Roboturk: A crowdsourcing platform for robotic skill learning through imitation
Ajay Mandlekar, Yuke Zhu, Animesh Garg, Jonathan Booher, Max Spero, Albert Tung, Julian Gao, John Emmons, Anchit Gupta, Emre Orbay, et al. Roboturk: A crowdsourcing platform for robotic skill learning through imitation. InConference on Robot Learning, 2018
2018
-
[31]
Scalable deep reinforcement learning for vision-based robotic manipulation
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. InConference on robot learning, 2018. 12
2018
-
[32]
Dmitry Kalashnikov, Jacob Varley, Yevgen Chebotar, Benjamin Swanson, Rico Jonschkowski, Chelsea Finn, Sergey Levine, and Karol Hausman. Mt-opt: Continuous multi-task robotic reinforcement learning at scale.arXiv preprint arXiv:2104.08212, 2021
-
[33]
BridgeData V2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. BridgeData V2: A dataset for robot learning at scale. InConference on Robot Learning, 2023
2023
-
[34]
RoboCOIN: An Open-Sourced Bimanual Robotic Data Collection for Integrated Manipulation
Shihan Wu, Xuecheng Liu, Shaoxuan Xie, Pengwei Wang, Xinghang Li, Bowen Yang, Zhe Li, Kai Zhu, Hongyu Wu, Yiheng Liu, et al. Robocoin: An open-sourced bimanual robotic data collection for integrated manipulation.arXiv preprint arXiv:2511.17441, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking
Homanga Bharadhwaj, Jay Vakil, Mohit Sharma, Abhinav Gupta, Shubham Tulsiani, and Vikash Kumar. Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking. InInternational Conference on Robotics and Automation, 2024
2024
-
[36]
Galaxea open-world dataset and g0 dual-system vla model.arXiv preprint arXiv:2509.00576, 2025
Tao Jiang, Tianyuan Yuan, Yicheng Liu, Chenhao Lu, Jianning Cui, Xiao Liu, Shuiqi Cheng, Jiyang Gao, Huazhe Xu, and Hang Zhao. Galaxea open-world dataset and g0 dual-system vla model.arXiv preprint arXiv:2509.00576, 2025
-
[37]
Harmonic: A multimodal dataset of assistive human–robot collaboration.The International Journal of Robotics Research, 41(1):3–11, 2022
Benjamin A Newman, Reuben M Aronson, Siddhartha S Srinivasa, Kris Kitani, and Henny Admoni. Harmonic: A multimodal dataset of assistive human–robot collaboration.The International Journal of Robotics Research, 41(1):3–11, 2022
2022
-
[38]
place the k-th donut from the left on the tray
Frederik Plahl, Georgios Katranis, Ilshat Mamaev, and Andrey Morozov. Lihra: A lidar-based hri dataset for automated risk monitoring methods. InIEEE/RSJ International Conference on Intelligent Robots and Systems, 2025. 13 Appendix: HABIT: Human-Aware Behavior and Interaction Training Dataset for Robot Manipulation Figure 10: Robot-side workspace detail. T...
2025
-
[39]
Hand the Duster to the robot
-
[40]
Lift the objects on a randomly selected tier of the Shelf
-
[41]
Once the robot finishes cleaning, lift the objects on the remaining tiers of the Shelf
-
[42]
Receive the Duster from the robot. Robot:
-
[43]
Pick up the Duster from the human
-
[44]
Clean the specific tier of the Shelf with the Duster once objects are removed
-
[45]
Clean the remaining tier of the Shelf with the Duster once objects are removed
-
[46]
Table Serving (Collaborator)
Hand the Duster back to the human. Table Serving (Collaborator). Human: 19 Figure 17: Initial configuration and task workflow for Shelf Cleaning
-
[47]
The human picks up the top napkin from the stack on the human table and walks to the robot table to stand in front of one of the two trays
-
[48]
When the robot lifts the bowl and the cup, the human unfolds the napkin and lays the napkin flat on the tray
-
[49]
The human returns to the human table to pick up another napkin and walks to the robot table to stand in front of the tray without a napkin
-
[50]
When the robot lifts the bowl and the cup, the human unfolds the napkin and lays the napkin flat on the tray. Robot:
-
[52]
Place the Picnic Bowl and Reusable plastic cup back onto the Handle tray in front of the human’s position
-
[53]
Pick up the Picnic Bowl and Reusable plastic cup from the Handle tray in front of the human’s position and hold them in the air
-
[54]
Waste Sorting (Coworker)
Place the Picnic Bowl and Reusable plastic cup back onto the Handle tray in front of the human’s position. Waste Sorting (Coworker). Human:
-
[56]
The human picks up one piece of trash that is not a can and places the trash into the appropriate organizing basket
-
[57]
20 Figure 18: Initial configuration and task workflow for Table Serving
The human picks up one piece of trash that is not a can and places the trash into the appropriate organizing basket. 20 Figure 18: Initial configuration and task workflow for Table Serving
-
[58]
The human picks up one piece of trash that is not a can and places the trash into the appropriate organizing basket. Robot:
-
[59]
Pick up the can waste from the table and place it in the right Fabric basket
-
[60]
Figure 19: Initial configuration and task workflow for Waste Sorting
Pick up the can waste from the table and place it in the right Fabric basket. Figure 19: Initial configuration and task workflow for Waste Sorting. Box Packaging (Coworker). Human:
-
[63]
Pick up an object on the table and put it in the box. 21
-
[64]
Pick up an object on the table and put it in the box
-
[65]
Close the lid of the box facing the person. Robot:
-
[67]
Pick up a Pencil pouch or Stapler and place it inside the Mailer Box closest to the robot
-
[68]
Figure 20: Initial configuration and task workflow for Box Packaging
Close the lid of the Mailer Box closest to the robot. Figure 20: Initial configuration and task workflow for Box Packaging. Food Storage (Supervisor). Human:
-
[69]
A person randomly selects and points to an Airtight Container. Robot:
-
[70]
Figure 21: Initial configuration and task workflow for Food Storage
Place the Butter Roll into the Airtight Container indicated by the human. Figure 21: Initial configuration and task workflow for Food Storage. Donut Serving (Supervisor). Human: 22
-
[71]
Points to the third donut from the left from the robot’s perspective. Robot:
-
[72]
Figure 22: Initial configuration and task workflow for Donut Serving
Pick up the Paper togo box containing the Donut indicated by the person and place it on the Handle tray. Figure 22: Initial configuration and task workflow for Donut Serving. C Model Training Details This section provides the fine-tuning configurations for the two open-source VLAs evaluated through- out the paper, namely π0.5 and GR00T N1.6. Within each m...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.