Recognition: unknown
EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Pith reviewed 2026-05-10 17:03 UTC · model grok-4.3
The pith
Egocentric human demonstrations scale robot policy performance when the data aligns with specific tasks and robot embodiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EgoVerse unifies collection and access for egocentric human data under shared standards, and its replicated experiments establish that robot policy performance improves with larger volumes of human data only when that data aligns with the robot learning objectives across tasks and embodiments.
What carries the argument
The EgoVerse platform and its standardized dataset of 80,000 human manipulation episodes, which enable consistent human-to-robot transfer under common experimental protocols.
If this is right
- Robot policies achieve higher success rates as the amount of aligned human demonstration data grows.
- Shared collection protocols produce comparable results across independent labs and robot hardware.
- A single dataset spanning thousands of tasks and real-world scenes supports broader evaluation of transfer methods.
- Industry and academic partners can contribute new episodes that immediately integrate into the same training pipelines.
Where Pith is reading between the lines
- Data alignment checks or filtering steps may need to precede training to realize scaling benefits.
- Smaller research groups could participate in large studies without maintaining separate data pipelines.
- The approach opens questions about how to measure and improve alignment automatically for new robot setups.
Load-bearing premise
Standardized egocentric human videos contain manipulation skills that transfer effectively to different robot bodies and tasks when formatted and annotated uniformly.
What would settle it
An experiment that increases the volume of aligned human data but observes no corresponding rise in robot policy success rates across the tested embodiments and tasks.
Figures













read the original abstract
Robot learning increasingly depends on large and diverse data, yet robot data collection remains expensive and difficult to scale. Egocentric human data offer a promising alternative by capturing rich manipulation behavior across everyday environments. However, existing human datasets are often limited in scope, difficult to extend, and fragmented across institutions. We introduce EgoVerse, a collaborative platform for human data-driven robot learning that unifies data collection, processing, and access under a shared framework, enabling contributions from individual researchers, academic labs, and industry partners. The current release includes 1,362 hours (80k episodes) of human demonstrations spanning 1,965 tasks, 240 scenes, and 2,087 unique demonstrators, with standardized formats, manipulation-relevant annotations, and tooling for downstream learning. Beyond the dataset, we conduct a large-scale study of human-to-robot transfer with experiments replicated across multiple labs, tasks, and robot embodiments under shared protocols. We find that policy performance generally improves with increased human data, but that effective scaling depends on alignment between human data and robot learning objectives. Together, the dataset, platform, and study establish a foundation for reproducible progress in human data-driven robot learning. Videos and additional information can be found at https://egoverse.ai/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EgoVerse, a collaborative platform and dataset of 1,362 hours (80k episodes) of egocentric human demonstrations spanning 1,965 tasks, 240 scenes, and 2,087 demonstrators, with standardized formats and annotations. It additionally reports a multi-lab study of human-to-robot policy transfer across tasks and embodiments under shared protocols, concluding that policy performance generally improves with increased human data volume but that effective scaling requires alignment between the human data and robot learning objectives.
Significance. If the alignment-dependent scaling result holds under rigorous controls, the work provides a valuable, extensible resource for data-driven robot learning that could reduce reliance on expensive robot data collection. The multi-institutional replication of experiments under shared protocols is a clear strength for reproducibility in the field.
major comments (3)
- [Abstract] Abstract and study protocol description: the central claim that 'effective scaling depends on alignment between human data and robot learning objectives' is not supported by any reported quantitative measure of alignment (e.g., task embedding distance, action-distribution divergence, or pre-training divergence metric) or error analysis, leaving the empirical finding weakly substantiated.
- [Study protocol description] Study protocol description: no explicit retargeting error metrics (e.g., hand-pose to end-effector mapping error) or independent validation of cross-embodiment transfer are provided, which is load-bearing for the assumption that standardized egocentric demonstrations transfer reliably across robot embodiments.
- [Experimental study section] Experimental study section: the protocol does not describe ablations that hold embodiment and task fixed while varying only human data volume, so it remains possible that performance differences arise from unmeasured embodiment mismatch or task selection bias rather than data scale or alignment.
minor comments (2)
- [Abstract] The abstract states that the dataset includes 'manipulation-relevant annotations' and 'tooling for downstream learning'; the main text should enumerate the precise annotation types (e.g., 3D hand poses, object affordances, success labels) and release the exact tooling scripts to support immediate use by other labs.
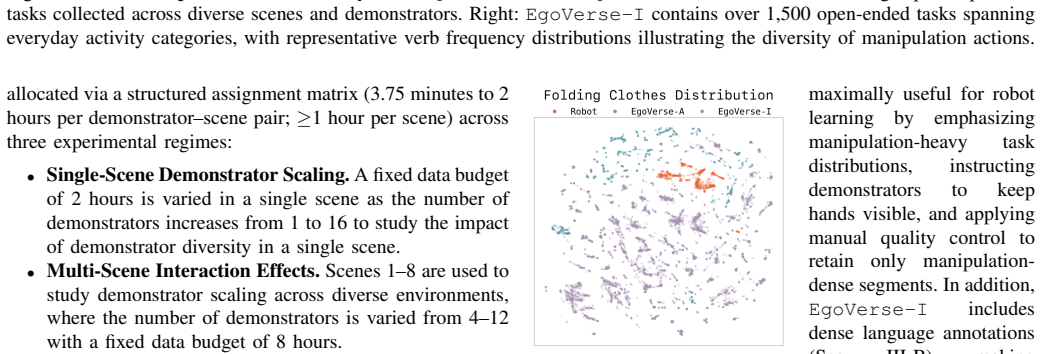
- Dataset statistics are given as aggregate hours and episode counts; adding per-task or per-scene averages (e.g., mean episode duration, number of demonstrators per task) would improve clarity on diversity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and study protocol description: the central claim that 'effective scaling depends on alignment between human data and robot learning objectives' is not supported by any reported quantitative measure of alignment (e.g., task embedding distance, action-distribution divergence, or pre-training divergence metric) or error analysis, leaving the empirical finding weakly substantiated.
Authors: We acknowledge that the alignment-dependent scaling claim relies on comparative observations across tasks and labs rather than explicit quantitative metrics. Performance improvements were more consistent in cases where human demonstrations matched robot task requirements and action spaces, while mismatches showed weaker scaling. To substantiate this, we will add quantitative alignment analysis in the revised manuscript, including task embedding distances and action-distribution divergences computed on available data subsets, along with error analysis of the scaling curves. These additions will appear in the experimental study section and be reflected in the abstract. revision: yes
-
Referee: [Study protocol description] Study protocol description: no explicit retargeting error metrics (e.g., hand-pose to end-effector mapping error) or independent validation of cross-embodiment transfer are provided, which is load-bearing for the assumption that standardized egocentric demonstrations transfer reliably across robot embodiments.
Authors: We agree that the absence of explicit retargeting error metrics weakens the protocol description. The manuscript details the standardization pipeline but omits quantitative validation. In revision, we will incorporate retargeting error metrics such as average hand-pose to end-effector mapping error and validation success rates. We will also add references to independent cross-embodiment validation or include summary statistics from the multi-lab setup to support reliable transfer assumptions. revision: yes
-
Referee: [Experimental study section] Experimental study section: the protocol does not describe ablations that hold embodiment and task fixed while varying only human data volume, so it remains possible that performance differences arise from unmeasured embodiment mismatch or task selection bias rather than data scale or alignment.
Authors: This is a fair critique of the experimental design. The multi-lab protocol varies data volume across tasks and embodiments under shared standards, but does not include explicit ablations isolating volume with fixed embodiment and task. We will revise the experimental study section to better describe the controls employed and discuss potential confounds from mismatch or bias. Where data subsets allow, we will add or clarify approximate ablations; otherwise, we will explicitly acknowledge the limitation while noting how the standardized protocols reduce (but do not eliminate) these risks. revision: partial
Circularity Check
No circularity: empirical dataset release and cross-lab experiments are self-contained
full rationale
The paper introduces the EgoVerse dataset (1,362 hours, 80k episodes) and reports policy scaling results from new human-to-robot transfer experiments replicated across independent labs, tasks, and embodiments under shared protocols. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear; the central claim that performance improves with data volume conditional on alignment is measured directly from the fresh experimental runs rather than derived from prior fitted values or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Egocentric human demonstrations capture manipulation behaviors that can transfer to robot embodiments when standardized and aligned
Forward citations
Cited by 1 Pith paper
-
HumanNet: Scaling Human-centric Video Learning to One Million Hours
HumanNet is a 1M-hour human-centric video dataset with interaction annotations that enables better vision-language-action model performance than equivalent robot data in a controlled test.
Reference graph
Works this paper leans on
-
[1]
Human-to-robot imitation in the wild
Shikhar Bahl, Abhinav Gupta, and Deepak Pathak. Human-to-robot imitation in the wild, 2022. URL https://arxiv.org/abs/2207.09450
-
[2]
Affordances from human videos as a versatile representation for robotics.CVPR, 2023
Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, and Deepak Pathak. Affordances from human videos as a versatile representation for robotics.CVPR, 2023
2023
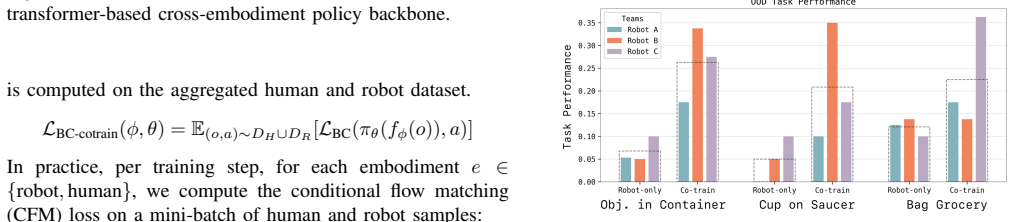
-
[3]
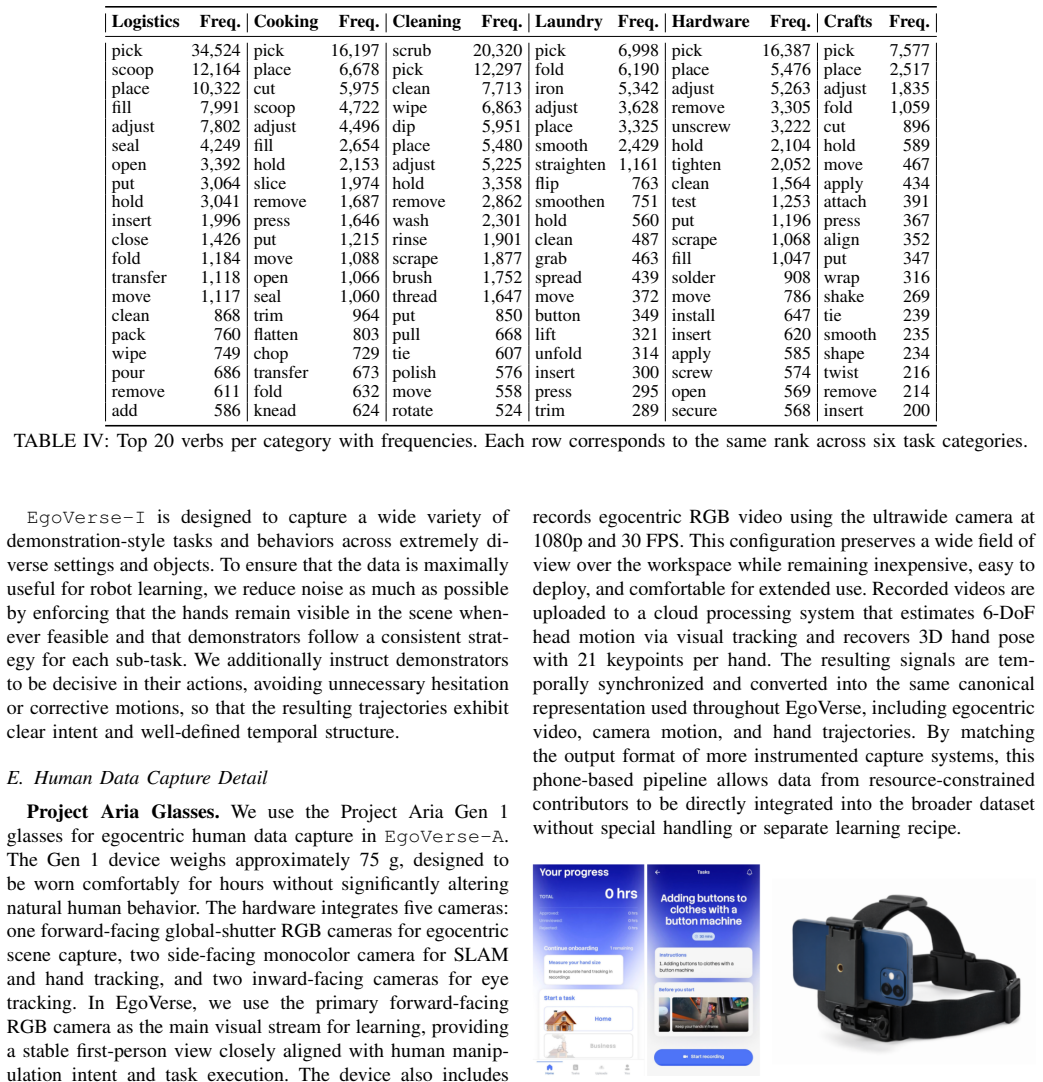
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Fan Zhang, Jade Fountain, Edward Miller, Selen Basol, Richard Newcombe, Robert Wang, et al. Introducing hot3d: An egocentric dataset for 3d hand and object tracking.arXiv preprint arXiv:2406.09598, 2024
-
[4]
Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Com- puter Vision (ECCV), 2024
2024
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π0: A vision- language-action flow model for general robot control, 2024.URL https://arxiv. org/abs/2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
arXiv preprint arXiv:2511.15704 (2025)
Xiongyi Cai, Ri-Zhao Qiu, Geng Chen, Lai Wei, Isabella Liu, Tianshu Huang, Xuxin Cheng, and Xiaolong Wang. In-n-on: Scaling egocentric manipulation with in-the- wild and on-task data.arXiv preprint arXiv:2511.15704, 2025
-
[8]
Freeman, Jitendra Malik, Russ Tedrake, Vincent Sitzmann, and Yilun Du
Boyuan Chen, Tianyuan Zhang, Haoran Geng, Kiwhan Song, William T. Freeman, Jitendra Malik, Russ Tedrake, Vincent Sitzmann, and Yilun Du. Large video planner,
-
[9]
URL http://arxiv.org/abs/2512.15840
work page internal anchor Pith review arXiv
-
[10]
Open-television: Teleoperation with immersive active visual feedback,
Xuxin Cheng, Jialong Li, Shiqi Yang, Ge Yang, and Xiaolong Wang. Open-television: Teleoperation with immersive active visual feedback.arXiv preprint arXiv:2407.01512, 2024
-
[11]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024
2024
-
[12]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal manipulation interface: In-the- wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Da- vide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling egocentric vision: The epic-kitchens dataset. InProceedings of the European conference on computer vision (ECCV), pages 720–736, 2018
2018
-
[14]
Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[15]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Jakob Engel, Kiran Somasundaram, Michael Goesele, Albert Sun, Alexander Gamino, Andrew Turner, Ar- jang Talattof, Arnie Yuan, Bilal Souti, Brighid Mered- ith, Cheng Peng, Chris Sweeney, Cole Wilson, Dan Barnes, Daniel DeTone, David Caruso, Derek Valleroy, Dinesh Ginjupalli, Duncan Frost, Edward Miller, Elias Mueggler, Evgeniy Oleinik, Fan Zhang, Guruprasa...
work page internal anchor Pith review arXiv 2023
-
[16]
Robot utility models: General policies for zero-shot deployment in new environments
Haritheja Etukuru, Norihito Naka, Zijin Hu, Seung- jae Lee, Julian Mehu, Aaron Edsinger, Chris Pax- ton, Soumith Chintala, Lerrel Pinto, and Nur Muham- mad Mahi Shafiullah. Robot utility models: General policies for zero-shot deployment in new environments. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8275–8283. IEEE, 2025
2025
-
[17]
Arctic: A dataset for dexterous bimanual hand-object manipulation
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J Black, and Otmar Hilliges. Arctic: A dataset for dexterous bimanual hand-object manipulation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12943–12954, 2023
2023
-
[18]
Rh20t: A robotic dataset for learning diverse skills in one-shot
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Chenxi Wang, Junbo Wang, Haoyi Zhu, and Cewu Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot.arXiv preprint arXiv:2307.00595, 2023
-
[19]
World models can leverage human videos for dexter- ous manipulation, 2025
Raktim Gautam Goswami, Amir Bar, David Fan, Tsung- Yen Yang, Gaoyue Zhou, Prashanth Krishnamurthy, Michael Rabbat, Farshad Khorrami, and Yann LeCun. World models can leverage human videos for dexter- ous manipulation, 2025. URL https://arxiv.org/abs/2512. 13644
2025
-
[20]
The ”something some- thing” video database for learning and evaluating visual common sense
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The ”something some- thing” video database for learning and evaluating visual common sense. InProceedings of the IE...
2017
-
[21]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jack- son Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995– 19012, 2022
2022
-
[22]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
2024
-
[23]
Irmak Guzey, Haozhi Qi, Julen Urain, Changhao Wang, Jessica Yin, Krishna Bodduluri, Mike Lambeta, Ler- rel Pinto, Akshara Rai, Jitendra Malik, Tingfan Wu, Akash Sharma, and Homanga Bharadhwaj. Dexterity from smart lenses: Multi-fingered robot manipulation with in-the-wild human demonstrations, 2025. URL https://arxiv.org/abs/2511.16661
-
[24]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
work page internal anchor Pith review arXiv 2015
-
[25]
Zihao He, Bo Ai, Tongzhou Mu, Yulin Liu, Weikang Wan, Jiawei Fu, Yilun Du, Henrik I. Christensen, and Hao Su. Scaling cross-embodiment world models for dexterous manipulation, 2025. URL https://arxiv.org/abs/ 2511.01177
-
[26]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video,
Ryan Hoque, Peide Huang, David J Yoon, Mouli Siva- purapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
-
[27]
Data scaling laws in im- itation learning for robotic manipulation
Yingdong Hu, Fanqi Lin, Pingyue Sheng, Chuan Wen, Jiacheng You, and Yang Gao. Data scaling laws in im- itation learning for robotic manipulation.arXiv preprint arXiv:2410.18647, 2024
-
[28]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Oculus reader: Robotic teleoperation interface, 2021
Frederik Ebert Jedrzej Orbik. Oculus reader: Robotic teleoperation interface, 2021. URL https://github.com/ rail-berkeley/oculus reader. Accessed: YYYY-MM-DD
2021
-
[30]
Egomimic: Scaling imitation learning via egocentric video, 2024
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imitation learning via egocentric video, 2024. URL https://arxiv.org/abs/2410. 24221
2024
-
[31]
arXiv preprint arXiv:2512.22414 (2025)
Simar Kareer, Karl Pertsch, James Darpinian, Judy Hoff- man, Danfei Xu, Sergey Levine, Chelsea Finn, and Suraj Nair. Emergence of human to robot transfer in vision- language-action models, 2025. URL https://arxiv.org/abs/ 2512.22414
-
[32]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review arXiv 2024
-
[33]
Marion Lepert, Jiaying Fang, and Jeannette Bohg. Phan- tom: Training robots without robots using only human videos, 2025. URL https://arxiv.org/abs/2503.00779
-
[34]
Amo: Adaptive mo- tion optimization for hyper-dexterous humanoid whole- body control, 2025
Jialong Li, Xuxin Cheng, Tianshu Huang, Shiqi Yang, Ri-Zhao Qiu, and Xiaolong Wang. Amo: Adaptive mo- tion optimization for hyper-dexterous humanoid whole- body control, 2025. URL https://arxiv.org/abs/2505. 03738
2025
-
[35]
Egozero: Robot learning from smart glasses.arXiv preprint arXiv:2505.20290, 2025
Vincent Liu, Ademi Adeniji, Haotian Zhan, Siddhant Haldar, Raunaq Bhirangi, Pieter Abbeel, and Lerrel Pinto. Egozero: Robot learning from smart glasses.arXiv preprint arXiv:2505.20290, 2025
-
[36]
Immimic: Cross-domain imitation from human videos via mapping and interpolation, 2025
Yangcen Liu, Woo Chul Shin, Yunhai Han, Zhenyang Chen, Harish Ravichandar, and Danfei Xu. Immimic: Cross-domain imitation from human videos via mapping and interpolation, 2025. URL https://arxiv.org/abs/2509. 10952
2025
-
[37]
Hoi4d: A 4d egocentric dataset for category- level human-object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. Hoi4d: A 4d egocentric dataset for category- level human-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21013–21022, June 2022
2022
-
[38]
Being-h0: vision-language-action pretraining from large-scale human videos,
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being-h0: Vision-language-action pre- training from large-scale human videos.arXiv preprint arXiv:2507.15597, 2025
-
[39]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, :, Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi ”Jim” Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed,...
work page internal anchor Pith review arXiv 2025
-
[40]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[41]
Egobridge: Domain adapta- tion for generalizable imitation from egocentric human data
Ryan Punamiya, Dhruv Patel, Patcharapong Aphiwetsa, Pranav Kuppili, Lawrence Y Zhu, Simar Kareer, Judy Hoffman, and Danfei Xu. Egobridge: Domain adapta- tion for generalizable imitation from egocentric human data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[42]
Humanoid policy˜ human policy,
Ri-Zhao Qiu, Shiqi Yang, Xuxin Cheng, Chaitanya Chawla, Jialong Li, Tairan He, Ge Yan, David J. Yoon, Ryan Hoque, Lars Paulsen, Ge Yang, Jian Zhang, Sha Yi, Guanya Shi, and Xiaolong Wang. Humanoid policy ˜ human policy.arXiv preprint arXiv:2503.13441, 2025
-
[43]
Juntao Ren, Priya Sundaresan, Dorsa Sadigh, Sanjiban Choudhury, and Jeannette Bohg. Motion tracks: A unified representation for human-robot transfer in few- shot imitation learning, 2025. URL https://arxiv.org/abs/ 2501.06994
-
[44]
What matters in learning from large-scale datasets for robot manipu- lation
Vaibhav Saxena, Matthew Bronars, Nadun Ranawaka Arachchige, Kuancheng Wang, Woo Chul Shin, Soroush Nasiriany, Ajay Mandlekar, and Danfei Xu. What matters in learning from large-scale datasets for robot manipu- lation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[45]
Zeromimic: Distilling robotic manipulation skills from web videos
Junyao Shi, Zhuolun Zhao, Tianyou Wang, Ian Pedroza, Amy Luo, Jie Wang, Jason Ma, and Dinesh Jayaraman. Zeromimic: Distilling robotic manipulation skills from web videos. InInternational Conference on Robotics and Automation (ICRA), 2025
2025
-
[46]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khali- dov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamon- jisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth ´ee Darcet, Th ´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Co...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Avid: Learning multi-stage tasks via pixel-level translation of human videos
Laura Smith, Nikita Dhawan, Marvin Zhang, Pieter Abbeel, and Sergey Levine. Avid: Learning multi-stage tasks via pixel-level translation of human videos.arXiv preprint arXiv:1912.04443, 2019
-
[48]
Gen-0: Embodied foundation mod- els that scale with physical interaction.Generalist AI Blog, 2025
Generalist AI Team. Gen-0: Embodied foundation mod- els that scale with physical interaction.Generalist AI Blog, 2025. https://generalistai.com/blog/nov-04-2025- GEN-0
2025
-
[49]
Octo: An open-source gener- alist robot policy, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag San- keti, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source gener- alist robot policy, 2024. URL https://arxiv.org/abs/24...
2024
-
[50]
Lirui Wang, Xinlei Chen, Jialiang Zhao, and Kaiming He. Scaling proprioceptive-visual learning with het- erogeneous pre-trained transformers, 2024. URL https: //arxiv.org/abs/2409.20537
-
[51]
Any-point trajectory modeling for policy learning, 2023
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajectory modeling for policy learning, 2023
2023
-
[52]
Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators, 2023
Philipp Wu, Yide Shentu, Zhongke Yi, Xingyu Lin, and Pieter Abbeel. Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators, 2023
2023
-
[53]
Available: http://dx.doi.org/10.1109/ IROS51168.2021.9636860
Haoyu Xiong, Quanzhou Li, Yun-Chun Chen, Homanga Bharadhwaj, Samarth Sinha, and Animesh Garg. Learn- ing by watching: Physical imitation of manipulation skills from human videos. In2021 IEEE/RSJ In- ternational Conference on Intelligent Robots and Sys- tems (IROS), pages 7827–7834, 2021. doi: 10.1109/ IROS51168.2021.9636080
-
[54]
Vision in action: Learning active perception from human demonstrations
Haoyu Xiong, Xiaomeng Xu, Jimmy Wu, Yifan Hou, Jeannette Bohg, and Shuran Song. Vision in action: Learning active perception from human demonstrations. arXiv preprint arXiv:2506.15666, 2025
-
[55]
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Hongxu Yin, Sifei Liu, Song Han, Yao Lu, and Xiaolong Wang. Egovla: Learning vision-language-action models from egocentric human videos, 2025. URL https://arxiv.org/ abs/2507.12440
-
[56]
Latent action pretraining from videos,
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, and Minjoon Seo. Latent action pretraining from videos,
-
[57]
URL https://arxiv.org/abs/2410.11758
-
[58]
Osmo: Open- source tactile glove for human-to-robot skill transfer
Jessica Yin, Haozhi Qi, Youngsun Wi, Sayantan Kundu, Mike Lambeta, William Yang, Changhao Wang, Tingfan Wu, Jitendra Malik, and Tess Hellebrekers. Osmo: Open- source tactile glove for human-to-robot skill transfer. arXiv preprint arXiv:2512.08920, 2025
-
[59]
Mink: Python inverse kinematics based on MuJoCo, December 2025
Kevin Zakka. Mink: Python inverse kinematics based on MuJoCo, December 2025. URL https://github.com/ kevinzakka/mink
2025
-
[60]
Ren, Dhruv Shah, and Anirudha Majumdar
Lihan Zha, Apurva Badithela, Michael Zhang, Justin Lidard, Jeremy Bao, Emily Zhou, David Snyder, Allen Z. Ren, Dhruv Shah, and Anirudha Majumdar. Guiding data collection via factored scaling curves, 2025. URL https://arxiv.org/abs/2505.07728
-
[61]
Lawrence Y . Zhu, Pranav Kuppili, Ryan Punamiya, Patcharapong Aphiwetsa, Dhruv Patel, Simar Kareer, Sehoon Ha, and Danfei Xu. Emma: Scaling mobile manipulation via egocentric human data.IEEE Robotics and Automation Letters, 11(3):3087–3094, 2026. doi: 10.1109/LRA.2026.3653320. VIII. APPENDIX A. Table of Contents Appendix Section A Table of Contents B Exte...
-
[62]
At upload time, data collectors are asked to annotateoperator,lab,task,embodiment, robot_name,scene,objects, andis_evalaccording to the schema summarized in Table V
Data Collection and Uploading:EgoVerse-Adata collected using the Aria glasses in the form of.vrsfiles and robot data in lab-specific formats are uploaded using a unified uploading script. At upload time, data collectors are asked to annotateoperator,lab,task,embodiment, robot_name,scene,objects, andis_evalaccording to the schema summarized in Table V. The...
-
[63]
Each row of the SQL table is a single file
SQL Database:The SQL database is a Postgres SQL table with rows that correspond to the schema in Table V and enables easy filtering. Each row of the SQL table is a single file
-
[64]
The daemon consists of 3 Ray clusters
Ray Processing Daemon:EgoVerse-Aand Robot data are processed and have their metadata updated by nightly Ray processing daemons. The daemon consists of 3 Ray clusters. Project Aria Data.For theEgoVerse-Adata, Cluster A responsible for running MPS (Machine Perception Services) runs on a single head node (t3a.2xlarge). It syncs batches of files without corre...
-
[65]
The dataset en- ables scalable, filtered access to large collections of processed episodes across embodiments, tasks, and labs
EgoVerseDataset:We provide a unified dataset interface, EgoVerseDataset, for loading EgoVerse data directly from S3 into training-ready PyTorch datasets. The dataset en- ables scalable, filtered access to large collections of processed episodes across embodiments, tasks, and labs. EgoVerseDatasetresolves valid episodes by querying the SQL database using u...
-
[66]
robot_name
Accessing Data from S3.:Given a set of metadata filters, data are resolved from the SQL database, synchronized from S3, and instantiated as PyTorch dataset objects. Code block 1 shows a simplified example illustrating this process. Listing 1: Simplified example illustrating SQL-based episode resolution, S3 synchronization usings5cmd, and instantiation of ...
-
[67]
We use inverse kinematics on the commanded robot base frame end-effector using the Mink IK Solver [57] to obtain joint angles
Hardware Setup: a)Robot A:We employ a VR teleoperation system using the Meta Oculus 3 headset and Oculus Pro controllers based on the RAIL Lab Oculus Reader [28]. We use inverse kinematics on the commanded robot base frame end-effector using the Mink IK Solver [57] to obtain joint angles. The joint angles are executed by the ARX5 Joint Space Controller. T...
-
[68]
Robot Data Composition:The per-task amount of robot demonstrations per robot and per task is summarized in Table VI. I. Policy Architecture and Learning Detail All learning hyperparameters are specified in Table VII
-
[69]
Cross Embodiment Encoder and Stems: Task # Demos — # Hours Robot A Robot B Robot C object-in-container 100 — 1.2 200 — 2.7 240 — 3.0 bag-grocery 300 — 5.1 150 — 1.67 139 — 1.8 cup-on-saucer 360 — 3.3 183 — 1.0 111 — 1.2 fold-clothes 300 — 3.0 – – TABLE VI: Robot dataset composition across tasks and plat- forms, reported as number of demonstrations and tot...
-
[70]
The Mcontext tokens produced by the encoder are used as the conditioning sequence for the flow-matching decoder
Flow Matching Decoder.:The decoder is parameterized by a multi-block diffusion transformer withN dec layers, Ddec attention heads, and embedding dimensiond dec. The Mcontext tokens produced by the encoder are used as the conditioning sequence for the flow-matching decoder. A noise token sequence of shapeR T×d dec/2 is combined with a learnable positional ...
-
[71]
Co-training with Flow Matching.:As discussed earlier, the total co-training loss is defined as LBC-cotrain =L robot CFM +L human CFM . For a given embodimente, we sample a timestepτ∼ Beta(1.5,1.0)and minimize the error in the predicted vector field: Le CFM =E τ,a0,a1,s h πθ(xτ , τ, fϕ(s))−(a 0 −a 1) 2i , wherex τ =τ a 0 + (1−τ)a 1 denotes the linear proba...
-
[72]
Since experiments are conducted across multiple labs and platforms, the available compute resources and total training time vary
Training Details.:We train the model for 150,000 opti- mization steps with a global batch size of 32–64 and learning rate of1×10 −4. Since experiments are conducted across multiple labs and platforms, the available compute resources and total training time vary. All model hyperparameters are summarized in Table VII. J. Robot Experiment Results
-
[73]
Training Mixture Details:We summarize training data mixtures for the various results reported in the paper below. Flagship Co-train (EV(8hr) + ID(2hr)):For each task, we use a fixed co-training setup that combines 8 hours of EgoVerse-A(EV) human data with 2 hours of in-domain (ID) human data, together with task-matched robot demon- strations. The in-domai...
-
[74]
Images of the training and evaluation objects are in Fig 14
Rollout Evaluation Protocol:We provide more detail of standardized evaluation protocol shared across different labs (robots) below. Images of the training and evaluation objects are in Fig 14. a)object-in-container:The scene contains one object and one container randomly place with the object being closer to the robot vertically than the container. In-dom...
-
[75]
IV-E,Robot Bexhibits a systematic strategy mismatch between human and robot demonstrations, which we hypothesize contributes to the observed degradation in co-training performance
Additional Analysis:As discussed in Sec. IV-E,Robot Bexhibits a systematic strategy mismatch between human and robot demonstrations, which we hypothesize contributes to the observed degradation in co-training performance. This mismatch is illustrated in Fig. 15. In both theEgoVerse-A human demonstrations and theRobot Arobot demonstra- tions, the bag is fi...
-
[76]
While our co-trained policies generally exhibited more robust grasping primitives, there is still room for improvement
Task Failure Modes:Forobject-in-containerandbag- grocery, we saw difficulty with picking primitives in certain parts of the workspace. While our co-trained policies generally exhibited more robust grasping primitives, there is still room for improvement. For thecup-on-saucertask, the object han- dover was difficult, especially for Robot C with a dexterous...
-
[77]
As shown in Figs
Single-scene Demonstrator Scaling:This experiment studies whether adding motion diversity from increasing the number of demonstrators, given a fixed data budget of 2 hours, improves generalization towards unseen demonstrator at the same scene. As shown in Figs. 17(a), 18(a), increasing the number of demonstrators improves performance across both tasks. Fo...
-
[78]
It is evaluated on unseen demonstrators within the same scenes
Multi-scene Demonstrator Scaling:In this study, we extend demonstrator scaling from a fixed single scene to eight scenes to examine whether the scaling effect persists in a multi-scene setting, aligning more closely with our real-world data collection setup. It is evaluated on unseen demonstrators within the same scenes. Given a fixed training data bud- g...
-
[79]
In both tasks, increasing the number of scenes consis- tently reduces Avg-MSE, demonstrating that scene diversity improves generalization, as shown in Figs
Scene Diversity Scaling:Next, we assess how scene diversity and per-scene data allocation affect scene general- ization, evaluated on unseen scenes data collected from other labs. In both tasks, increasing the number of scenes consis- tently reduces Avg-MSE, demonstrating that scene diversity improves generalization, as shown in Figs. 17(d), 18(d). In fol...
-
[80]
As shown in Figs
Mixed Diversity Scaling:Under a fixed 4-hour data budget, we study the joint effect of scaling scene diversity (from 4 to 8 scenes) and demonstrator diversity (from 4 to 8 demonstrators), evaluating on unseen demonstrators and scenes collected in other labs. As shown in Figs. 17(c) and 18(c), increasing scene diversity consistently reduces Avg- MSE for bo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.