Video Models Can Reason with Verifiable Rewards
Pith reviewed 2026-05-19 14:56 UTC · model grok-4.3
The pith
Reinforcement learning with rule-based rewards lets video diffusion models generate trajectories that satisfy explicit spatial and logical constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
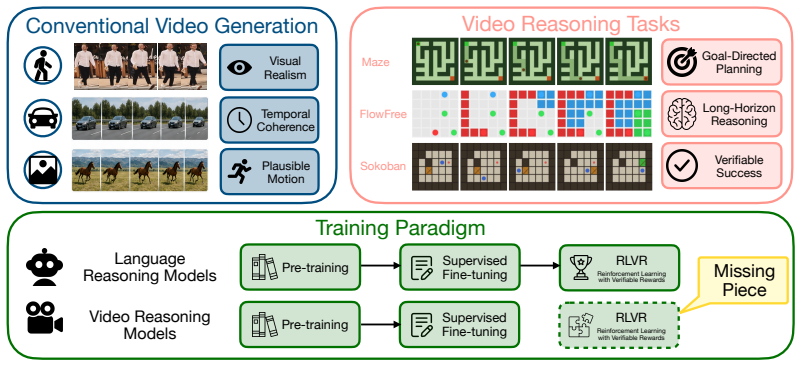
VideoRLVR formulates video reasoning as the generation of verifiable visual trajectories and optimizes diffusion models with an SDE-GRPO backbone, dense decomposed rewards, and an Early-Step Focus strategy that restricts policy updates to the early denoising steps, achieving consistent gains over supervised fine-tuning on Maze, FlowFree, and Sokoban while cutting training latency by roughly 40 percent.
What carries the argument
VideoRLVR optimization recipe built on SDE-GRPO policy updates, dense decomposed rewards that break success into spatial-temporal components, and Early-Step Focus that restricts gradients to the initial denoising phase.
If this is right
- VideoRLVR improves success rates over supervised fine-tuning on Maze, FlowFree, and Sokoban.
- Dense decomposed rewards deliver the largest gains precisely when baseline success rates are low.
- The Early-Step Focus strategy preserves performance while cutting training time by about 40 percent.
- The RL-tuned model exceeds both proprietary and open-source video generators on the tested reasoning benchmarks and on out-of-domain checks.
Where Pith is reading between the lines
- The same verifiable-reward loop could be applied to other video tasks that admit objective scoring, such as physical simulation or instructional video planning.
- Because the method separates reward design from the diffusion backbone, it offers a route to incorporate new constraint types without retraining the entire generator.
- The latency reduction from Early-Step Focus suggests that similar partial-trajectory optimization may be useful in other diffusion-based sequence models.
Load-bearing premise
Success on three procedurally generated domains with objective success criteria shows that the model has acquired reliable rule-consistent visual reasoning that works outside those exact environments.
What would settle it
Test the trained model on a fourth procedurally generated domain with a new set of rules never encountered in training and measure whether success rate remains high without additional fine-tuning.
Figures




read the original abstract
Video diffusion models have made rapid progress in perceptual realism and temporal coherence, but they remain primarily optimized for plausible generation rather than verifiable reasoning. This limitation is especially pronounced in tasks where generated videos must satisfy explicit spatial, temporal, or logical constraints. Inspired by the role of reinforcement learning with verifiable rewards (RLVR) in reasoning-oriented language models, we introduce VideoRLVR, a practical recipe for optimizing video diffusion models with rule-based feedback. VideoRLVR formulates video reasoning as the generation of verifiable visual trajectories and consists of an SDE-GRPO optimization backbone, dense decomposed rewards, and an Early-Step Focus strategy for efficient training. The Early-Step Focus strategy restricts policy optimization to the early denoising phase, reducing training latency by about 40% while preserving performance. We evaluate VideoRLVR on Maze, FlowFree, and Sokoban, three procedurally generated domains with objective success criteria. Across these tasks, VideoRLVR consistently improves over supervised fine-tuning baselines, with dense decomposed rewards proving especially important in low-success-rate settings. Our RL-optimized model also outperforms the evaluated proprietary and open-source video generation models on these verifiable reasoning benchmarks and out-of-domain benchmarks. These results suggest that verifiable RL can move video models beyond perceptual imitation toward more reliable rule-consistent visual reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoRLVR, a method to optimize video diffusion models for verifiable reasoning using reinforcement learning with rule-based feedback. It features an SDE-GRPO optimization backbone, dense decomposed rewards, and an Early-Step Focus strategy that reduces training latency by ~40%. Evaluated on three procedurally generated domains (Maze, FlowFree, Sokoban) with objective success criteria, VideoRLVR shows consistent gains over supervised fine-tuning baselines (especially with dense rewards in low-success settings) and outperforms other video generation models on both in-domain and out-of-domain benchmarks, suggesting a shift from perceptual imitation to reliable rule-consistent visual reasoning.
Significance. If the reported improvements hold under scrutiny, this represents a meaningful step in extending RLVR techniques from language models to video diffusion for tasks with explicit spatial-temporal-logical constraints. The practical efficiency gain from Early-Step Focus and the emphasis on dense rewards are useful contributions. The benchmark-driven evaluation with objective criteria offers concrete, falsifiable results, though broader impact hinges on evidence of generalization beyond the tested environments.
major comments (1)
- [Evaluation section] Evaluation section (and Abstract): The central claim that gains on Maze, FlowFree, and Sokoban demonstrate 'reliable rule-consistent visual reasoning' that generalizes is load-bearing but rests on three domains sharing low-dimensional, fully observable, rule-explicit properties. This risks conflating environment-specific trajectory optimization with transferable logic. The mention of out-of-domain benchmarks lacks quantitative details on domain shift, reward sensitivity, or failure-case analysis, weakening support for the broader reasoning claim.
minor comments (2)
- [Introduction] Expand the SDE-GRPO acronym and provide a short equation or reference on first use in the methods or introduction.
- [Methods] Add a diagram or pseudocode for the Early-Step Focus strategy to clarify how it restricts policy optimization to the early denoising phase.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the concern about the evaluation section and the strength of our generalization claims below, and we outline the revisions we will make to strengthen the presentation.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and Abstract): The central claim that gains on Maze, FlowFree, and Sokoban demonstrate 'reliable rule-consistent visual reasoning' that generalizes is load-bearing but rests on three domains sharing low-dimensional, fully observable, rule-explicit properties. This risks conflating environment-specific trajectory optimization with transferable logic. The mention of out-of-domain benchmarks lacks quantitative details on domain shift, reward sensitivity, or failure-case analysis, weakening support for the broader reasoning claim.
Authors: We appreciate the referee's observation that the three domains share structural similarities. These environments were deliberately chosen because they provide objective, rule-based success criteria that enable verifiable rewards, which is a core requirement of the RLVR framework. The tasks nevertheless differ in their core mechanics—Maze emphasizes path planning, FlowFree requires constraint satisfaction under flow rules, and Sokoban involves object manipulation and planning—thereby exercising distinct aspects of spatial-temporal reasoning. We do not claim that success on these domains proves broad transfer to arbitrary visual reasoning; rather, the results demonstrate that RL with dense decomposed rewards can improve rule adherence beyond supervised fine-tuning in settings where correctness is unambiguously measurable. Regarding out-of-domain benchmarks, we acknowledge that the current text mentions performance improvements but provides insufficient quantitative analysis of domain shift, reward sensitivity, and failure modes. We will revise the Evaluation section (and update the Abstract accordingly) to include additional metrics, a description of the domain-shift characteristics, and representative success/failure examples. This revision will better contextualize the scope of our claims without overstating generalization. revision: partial
Circularity Check
No circularity; empirical method with external objective benchmarks
full rationale
The paper presents VideoRLVR as an empirical optimization recipe (SDE-GRPO backbone, dense decomposed rewards, Early-Step Focus) evaluated on three procedurally generated domains with objective success criteria. Performance gains are reported via direct comparison to supervised fine-tuning baselines and other video models on in-domain and out-of-domain benchmarks. No first-principles derivations, predictions, or uniqueness theorems are claimed that reduce by construction to fitted parameters or self-citations within the paper. The central results rest on external verifiable rewards and benchmark metrics rather than internal redefinitions or load-bearing self-references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video diffusion models can be effectively optimized via policy gradients using rule-based verifiable rewards defined on generated trajectories.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VideoRLVR formulates video reasoning as the generation of verifiable visual trajectories and consists of an SDE-GRPO optimization backbone, dense decomposed rewards, and an Early-Step Focus strategy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dense decomposed rewards that break sparse task success into verifiable structural components
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhaochong An, Orest Kupyn, Théo Uscidda, Andrea Colaco, Karan Ahuja, Serge Belongie, Mar Gonzalez-Franco, and Marta Tintore Gazulla. Vggrpo: Towards world-consistent video generation with 4d latent reward.arXiv preprint arXiv:2603.26599, 2026
-
[2]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1(8):1, 2024
work page 2024
-
[4]
Mmgr: Multi-modal generative reasoning.arXiv preprint arXiv:2512.14691, 2025
Zefan Cai, Haoyi Qiu, Tianyi Ma, Haozhe Zhao, Gengze Zhou, Kung-Hsiang Huang, Parisa Kordjamshidi, Minjia Zhang, Wen Xiao, Jiuxiang Gu, et al. Mmgr: Multi-modal generative reasoning.arXiv preprint arXiv:2512.14691, 2025
-
[5]
Dgpo: discovering multiple strategies with diversity-guided policy optimization
Wentse Chen, Shiyu Huang, Yuan Chiang, Tim Pearce, Wei-Wei Tu, Ting Chen, and Jun Zhu. Dgpo: discovering multiple strategies with diversity-guided policy optimization. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 11390–11398, 2024
work page 2024
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Language-conditioned world modeling for visual navigation.arXiv preprint arXiv:2603.26741, 2026
Yifei Dong, Fengyi Wu, Yilong Dai, Lingdong Kong, Guangyu Chen, Xu Zhu, Qiyu Hu, Tianyu Wang, Johnalbert Garnica, Feng Liu, et al. Language-conditioned world modeling for visual navigation.arXiv preprint arXiv:2603.26741, 2026
-
[8]
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
work page 2023
-
[9]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
work page 2020
-
[10]
Google DeepMind. Gemini 3.1 Pro Model Card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/, February 2026
work page 2026
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Ziyu Guo, Xinyan Chen, Renrui Zhang, Ruichuan An, Yu Qi, Dongzhi Jiang, Xiangtai Li, Manyuan Zhang, Hongsheng Li, and Pheng-Ann Heng. Are video models ready as zero-shot reasoners? an empirical study with the mme-cof benchmark.arXiv preprint arXiv:2510.26802, 2025
-
[13]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Puzzlefusion: Unleashing the power of diffusion models for spatial puzzle solving
Sepidehsadat Sepid Hossieni, Mohammad Amin Shabani, Saghar Irandoust, and Yasutaka Furukawa. Puzzlefusion: Unleashing the power of diffusion models for spatial puzzle solving. Advances in Neural Information Processing Systems, 36:9574–9597, 2023
work page 2023
-
[15]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 10
work page 2022
-
[16]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Learning Adaptive Reasoning Paths for Efficient Visual Reasoning
Yixu Huang, Tinghui Zhu, and Muhao Chen. Learning adaptive reasoning paths for efficient visual reasoning.arXiv preprint arXiv:2604.14568, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Ziqi Huang, Ning Yu, Gordon Chen, Haonan Qiu, Paul Debevec, and Ziwei Liu. Vchain: Chain-of-visual-thought for reasoning in video generation.arXiv preprint arXiv:2510.05094, 2025
-
[19]
How Far is Video Generation from World Model: A Physical Law Perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective.arXiv preprint arXiv:2411.02385, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
All you need to know about kling video 3.0
Kling AI. All you need to know about kling video 3.0. https://kling.ai/blog/ kling-video-3-0-ai-director-features-guide, February 2026
work page 2026
-
[21]
Rui Li, Yuanzhi Liang, Ziqi Ni, Haibing Huang, Chi Zhang, and Xuelong Li. Growing with the generator: Self-paced grpo for video generation.arXiv preprint arXiv:2511.19356, 2025
-
[22]
Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. Branchgrpo: Stable and efficient grpo with structured branching in diffusion models.arXiv preprint arXiv:2509.06040, 2025
-
[23]
From System 1 to System 2: A Survey of Reasoning Large Language Models
Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models.arXiv preprint arXiv:2502.17419, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Diff-control: A stateful diffusion-based policy for imitation learning
Xiao Liu, Yifan Zhou, Fabian Weigend, Shubham Sonawani, Shuhei Ikemoto, and Heni Ben Amor. Diff-control: A stateful diffusion-based policy for imitation learning. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7453–7460. IEEE, 2024
work page 2024
-
[26]
Yang Luo, Xuanlei Zhao, Baijiong Lin, Lingting Zhu, Liyao Tang, Yuqi Liu, Ying-Cong Chen, Shengju Qian, Xin Wang, and Yang You. V-reasonbench: Toward unified reasoning benchmark suite for video generation models.arXiv preprint arXiv:2511.16668, 2025
-
[27]
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
-
[28]
Zhiting Mei, Tenny Yin, Ola Shorinwa, Apurva Badithela, Zhonghe Zheng, Joseph Bruno, Madi- son Bland, Lihan Zha, Asher Hancock, Jaime Fernández Fisac, et al. Video generation models in robotics-applications, research challenges, future directions.arXiv preprint arXiv:2601.07823, 2026
-
[29]
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do gener- ative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
work page 2026
-
[30]
OpenAI. Sora 2 system card. https://openai.com/index/sora-2-system-card/ , September 2025
work page 2025
-
[31]
OpenAI. GPT-5.5 System Card. https://openai.com/index/gpt-5-5-system-card/ , April 2026
work page 2026
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Selena Song, Ziming Xu, Zijun Zhang, Kun Zhou, Jiaxian Guo, Lianhui Qin, and Biwei Huang. Learning plug-and-play memory for guiding video diffusion models.arXiv preprint arXiv:2511.19229, 2025
-
[35]
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Jingqi Tong, Yurong Mou, Hangcheng Li, Mingzhe Li, Yongzhuo Yang, Ming Zhang, Qiguang Chen, Tianyi Liang, Xiaomeng Hu, Yining Zheng, et al. Thinking with video: Video generation as a promising multimodal reasoning paradigm.arXiv preprint arXiv:2511.04570, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
work page 2024
-
[37]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
A very big video reasoning suite.arXiv preprint arXiv:2602.20159, 2026
Maijunxian Wang, Ruisi Wang, Juyi Lin, Ran Ji, Thaddäus Wiedemer, Qingying Gao, Dezhi Luo, Yaoyao Qian, Lianyu Huang, Zelong Hong, et al. A very big video reasoning suite.arXiv preprint arXiv:2602.20159, 2026
-
[39]
Demystifing video reasoning.arXiv preprint arXiv:2603.16870, 2026
Ruisi Wang, Zhongang Cai, Fanyi Pu, Junxiang Xu, Wanqi Yin, Maijunxian Wang, Ran Ji, Chenyang Gu, Bo Li, Ziqi Huang, et al. Demystifing video reasoning.arXiv preprint arXiv:2603.16870, 2026
-
[40]
Video models are zero-shot learners and reasoners
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Arm: Adaptive reasoning model.arXiv preprint arXiv:2505.20258, 2025
Siye Wu, Jian Xie, Yikai Zhang, Aili Chen, Kai Zhang, Yu Su, and Yanghua Xiao. Arm: Adaptive reasoning model.arXiv preprint arXiv:2505.20258, 2025
-
[43]
A Systematic Post-Train Framework for Video Generation
Zeyue Xue, Siming Fu, Jie Huang, Shuai Lu, Haoran Li, Yijun Liu, Yuming Li, Xiaoxuan He, Mengzhao Chen, Haoyang Huang, et al. A systematic post-train framework for video generation.arXiv preprint arXiv:2604.25427, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Cheng Yang, Haiyuan Wan, Yiran Peng, Xin Cheng, Zhaoyang Yu, Jiayi Zhang, Junchi Yu, Xinlei Yu, Xiawu Zheng, Dongzhan Zhou, et al. Reasoning via video: The first evaluation of video models’ reasoning abilities through maze-solving tasks.arXiv preprint arXiv:2511.15065, 2025
-
[46]
Diffusion probabilistic modeling for video generation.Entropy, 25(10):1469, 2023
Ruihan Yang, Prakhar Srivastava, and Stephan Mandt. Diffusion probabilistic modeling for video generation.Entropy, 25(10):1469, 2023
work page 2023
-
[47]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Chenyu Zhang, Daniil Cherniavskii, Antonios Tragoudaras, Antonios V ozikis, Thijmen Nijdam, Derck WE Prinzhorn, Mark Bodracska, Nicu Sebe, Andrii Zadaianchuk, and Efstratios Gavves. Morpheus: Benchmarking physical reasoning of video generative models with real physical experiments.arXiv preprint arXiv:2504.02918, 2025. 12
-
[49]
Tinghui Zhu, Kai Zhang, Jian Xie, and Yu Su. Deductive beam search: Decoding deducible rationale for chain-of-thought reasoning.arXiv preprint arXiv:2401.17686, 2024. 13 A Dataset Generation Details We generate all training and evaluation instances using rule-based algorithms so that each sample has a known valid trajectory and task metadata for automatic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.