KYA: A Framework-Agnostic Trust Layer for Autonomous Systems with Verifiable Provenance and Hierarchical Policy Composition
Pith reviewed 2026-06-29 22:06 UTC · model grok-4.3
The pith
KYA uses five primitives to create a framework-agnostic trust and governance layer that makes autonomous system actions authorized, policy-conforming, and verifiable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KYA is an open-source framework-agnostic trust and governance layer composed of five primitives that together provide trust, governance, and evidentiary assurance for autonomous systems, ensuring actions are authorized, policy-conforming, and post-hoc verifiable.
What carries the argument
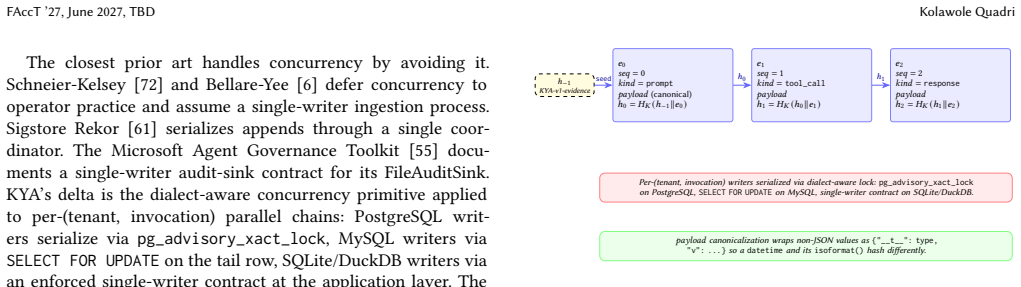
The five primitives: a four-gate inbound apply pipeline, an only-tighten composition algebra over a three-channel multi-tenant hierarchy, KYP for schema-level unification of trust scoring, auditable interaction-multiplier amplification over an AIVSS-shaped additive baseline, and two-axis delegation attribution with static premium and runtime debit.
If this is right
- Autonomous system actions become authorized through the inbound pipeline.
- Hierarchical policies compose in an only-tighten manner across multi-tenant channels.
- Trust scores unify across human users, AI agents, and service accounts via KYP.
- Interaction multipliers amplify scores audibly over baseline.
- Delegation in multi-agent setups attributes responsibility via static and runtime mechanisms.
Where Pith is reading between the lines
- Integration with observability tools could provide complete system assurance.
- The design might apply to broader multi-agent or distributed systems beyond the tested frameworks.
- High performance metrics suggest suitability for real-time autonomous operations.
- The adversarial detection rate points to potential in securing against multi-agent attacks.
Load-bearing premise
The five primitives and their adapters for multiple frameworks implement the behavior correctly without inconsistencies or security gaps in all scenarios.
What would settle it
Finding an adversarial input from the PyRIT or Garak sets that bypasses the detection or a framework adapter where policy conformance fails.
Figures





read the original abstract
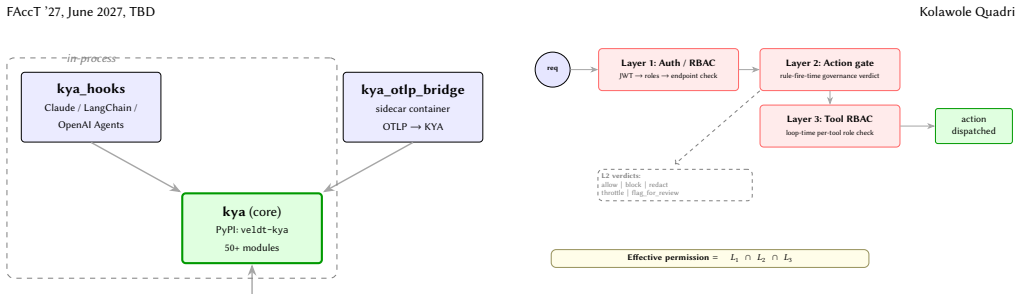
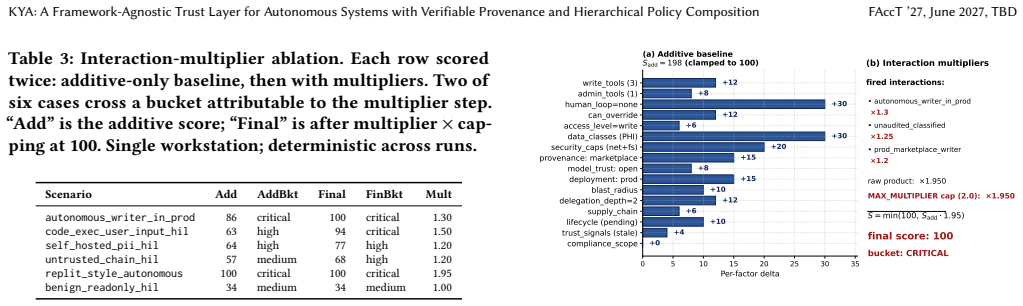
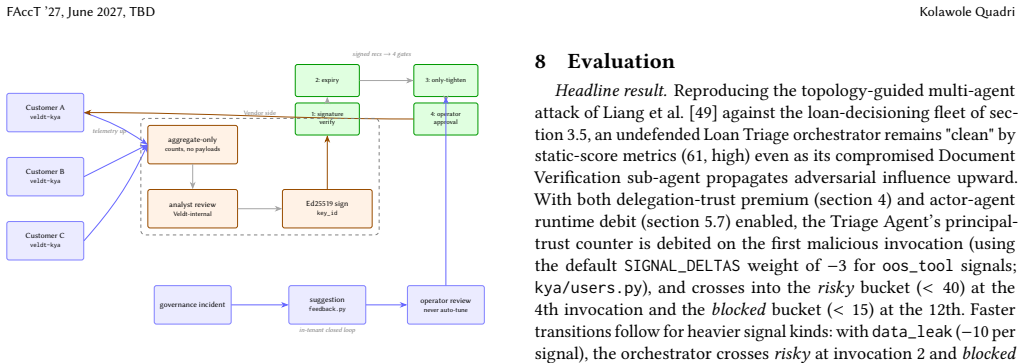
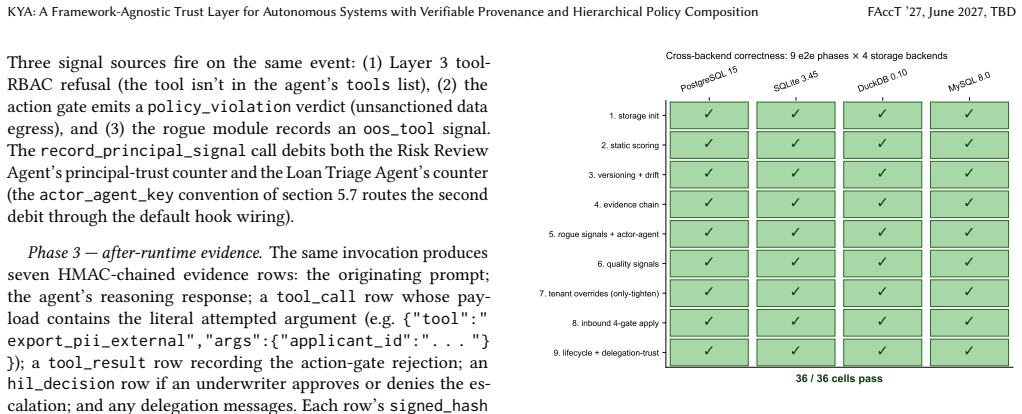
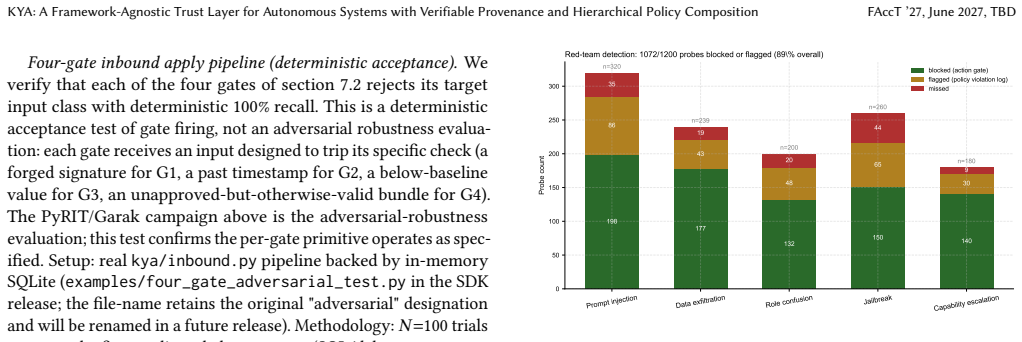
KYA (Know Your Agents) is an open-source, framework-agnostic trust and governance layer for autonomous systems, composed of five primitives: (1) a four-gate inbound apply pipeline; (2) an only-tighten composition algebra over a three-channel multi-tenant hierarchy; (3) KYP (Know Your Principal), a schema-level unification of trust scoring across human users, AI agents, and service accounts; (4) auditable interaction-multiplier amplification over an AIVSS-shaped additive baseline; and (5) two-axis delegation attribution: a static premium for risky delegates and a runtime debit for actual delegate misbehavior in multi-agent fan-out. Together these span three pillars (trust, governance, and evidentiary assurance), making an autonomous system's actions authorized, policy-conforming, and post-hoc verifiable: where observability answers how long, how much, and what path, KYA answers was it authorized, did it conform, and can it be verified; it composes with observability rather than replacing it. It ships native adapters for 15+ agent frameworks. On a 4 by 9 cross-backend matrix all 36 cells pass; the pure-function scorer runs sub-millisecond at p99 and the system sustains ~ 1,800 ops/sec at 20 concurrent workers with HMAC chain integrity preserved end-to-end. KYA detects 89% of 1,200 adversarial probes from PyRIT and Garak, including the recently-published topology-guided multi-agent attack. The system is available under Apache 2.0 as the veldt-kya package on PyPI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
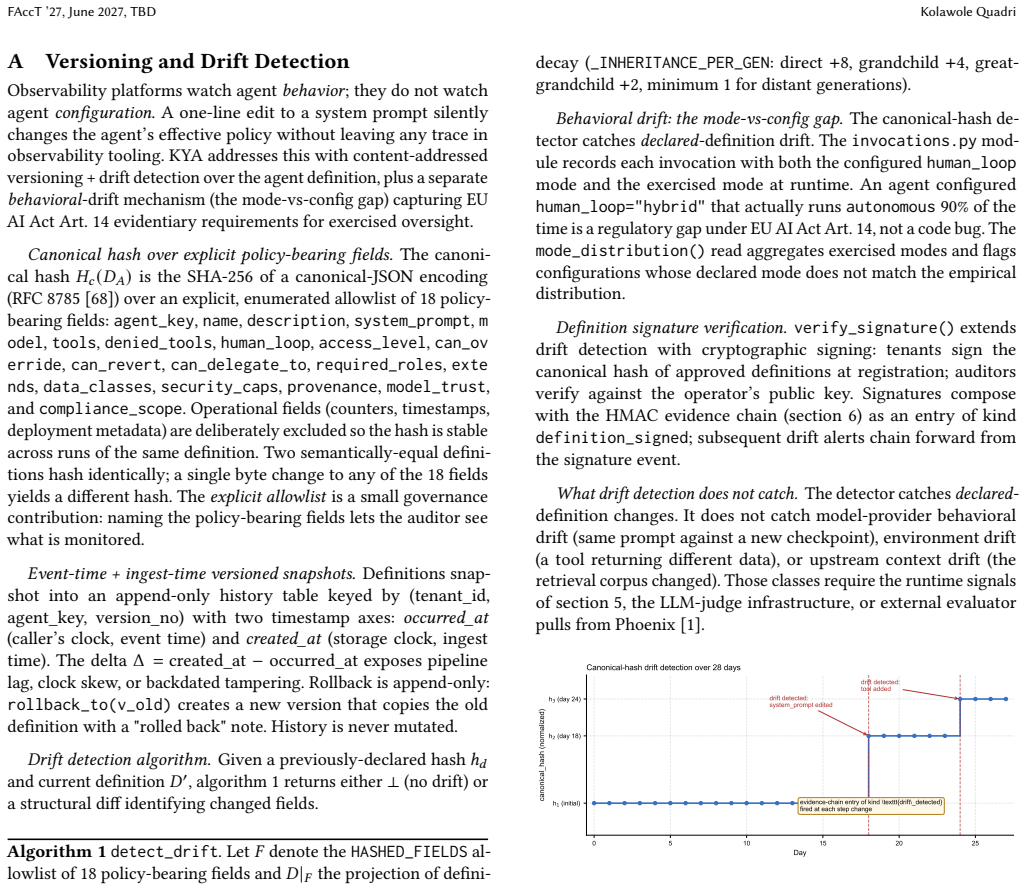
Summary. The paper introduces KYA (Know Your Agents), an open-source framework-agnostic trust and governance layer for autonomous systems. It defines five primitives—a four-gate inbound apply pipeline, an only-tighten composition algebra over a three-channel multi-tenant hierarchy, the KYP schema unifying trust scoring for users/agents/service accounts, an auditable interaction-multiplier over an AIVSS-shaped baseline, and two-axis delegation attribution (static premium plus runtime debit)—that together claim to deliver authorization, policy conformance, and post-hoc verifiability across 15+ agent frameworks. The work reports that a 4×9 cross-backend test matrix passes in all 36 cells, the scorer runs sub-millisecond at p99, the system sustains ~1,800 ops/sec, and 89% of 1,200 PyRIT/Garak adversarial probes (including topology-guided attacks) are detected. The system is released under Apache 2.0.
Significance. If the primitives and adapters are shown to preserve the stated invariants, the contribution would be significant: it supplies a composable, provenance-preserving policy layer that can be inserted into existing agent runtimes without replacing observability tooling. The open-source release and native adapters for many frameworks would make the approach immediately usable for hardening multi-agent deployments where authorization and auditability are required.
major comments (3)
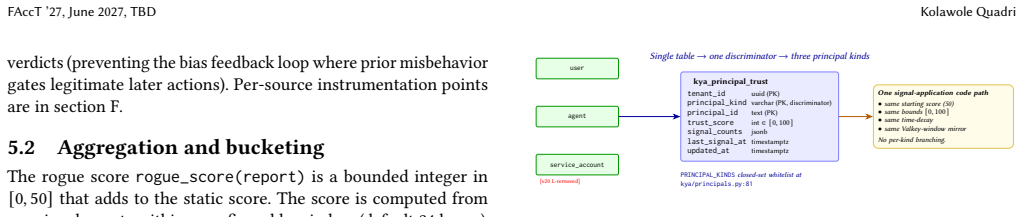
- [Evaluation] Evaluation section: the claim that the five primitives together 'guarantee authorization, policy conformance, and post-hoc verifiability' rests solely on the statement that 'all 36 cells pass' in the 4×9 cross-backend matrix. No description of the test cases, the specific invariants checked per cell, or the failure modes considered is supplied, so it is impossible to determine whether the only-tighten algebra or the inbound pipeline actually prevents the inconsistencies the skeptic note identifies.
- [Evaluation] Adversarial evaluation: the 89% detection rate on 1,200 PyRIT/Garak probes is reported without per-category breakdown, false-positive rate, or analysis of the 11% undetected probes. Because the central security claim includes coverage of 'recently-published topology-guided multi-agent attack,' the absence of this granularity leaves the detection guarantee unsupported.
- [Performance] Performance claims: sub-millisecond p99 latency for the pure-function scorer and ~1,800 ops/sec throughput at 20 workers are stated without hardware platform, workload definition, or comparison to baseline policy engines, rendering the numbers non-reproducible and their relevance to the security properties unclear.
minor comments (1)
- [Abstract] The term 'AIVSS-shaped' is used without an inline definition or reference; a brief expansion or citation would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the evaluation section requires greater transparency to support the claims. We agree that additional details are needed and will revise the manuscript to address each point. No standing objections apply, as all comments can be met with expanded descriptions and data in the revision.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the claim that the five primitives together 'guarantee authorization, policy conformance, and post-hoc verifiability' rests solely on the statement that 'all 36 cells pass' in the 4×9 cross-backend matrix. No description of the test cases, the specific invariants checked per cell, or the failure modes considered is supplied, so it is impossible to determine whether the only-tighten algebra or the inbound pipeline actually prevents the inconsistencies the skeptic note identifies.
Authors: We acknowledge that the current manuscript provides insufficient detail on the 4×9 cross-backend matrix. The revision will expand the Evaluation section with: (1) explicit test case descriptions covering authorization checks, policy application under the only-tighten algebra, and provenance verification; (2) the specific invariants verified per cell (e.g., no policy relaxation, end-to-end HMAC integrity, and correct delegation attribution); and (3) considered failure modes, including potential inconsistencies in multi-tenant hierarchies. This will allow independent assessment of whether the primitives enforce the stated guarantees. revision: yes
-
Referee: [Evaluation] Adversarial evaluation: the 89% detection rate on 1,200 PyRIT/Garak probes is reported without per-category breakdown, false-positive rate, or analysis of the 11% undetected probes. Because the central security claim includes coverage of 'recently-published topology-guided multi-agent attack,' the absence of this granularity leaves the detection guarantee unsupported.
Authors: The referee is correct that the adversarial results lack necessary granularity. The revised manuscript will add a per-category breakdown of the 1,200 probes (e.g., by attack type including topology-guided), the observed false-positive rate, and an analysis of the undetected 11%, specifically addressing whether any undetected cases involved the topology-guided multi-agent attack. This will provide stronger evidence for the detection claims. revision: yes
-
Referee: [Performance] Performance claims: sub-millisecond p99 latency for the pure-function scorer and ~1,800 ops/sec throughput at 20 workers are stated without hardware platform, workload definition, or comparison to baseline policy engines, rendering the numbers non-reproducible and their relevance to the security properties unclear.
Authors: We agree the performance figures require additional context for reproducibility and relevance. The revision will specify the hardware platform, define the workload (including agent count, policy complexity, and concurrency model), and include comparisons to baseline policy engines. We will also discuss how the measured latency and throughput support real-time enforcement of the security invariants. revision: yes
Circularity Check
No circularity; system description and empirical test results are independent of any self-referential derivation.
full rationale
The manuscript presents a framework composed of five explicitly enumerated primitives (inbound pipeline, only-tighten algebra, KYP unification, interaction-multiplier, two-axis delegation) together with reported outcomes from a 4x9 test matrix and 1,200 adversarial probes. No equations, first-principles derivations, or predictions appear in the supplied text. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work are present. The performance and detection figures are stated as direct measurements rather than quantities forced by the primitives' definitions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five primitives are sufficient to span trust, governance, and evidentiary assurance across frameworks.
invented entities (1)
-
Four-gate inbound apply pipeline, only-tighten composition algebra, KYP schema, AIVSS-shaped interaction-multiplier, two-axis delegation attribution
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024.Phoenix: AI Observability and Evaluation
Arize AI. 2024.Phoenix: AI Observability and Evaluation
2024
-
[2]
1998.Refinement Calculus: A System- atic Introduction
Ralph-Johan Back and Joakim von Wright. 1998.Refinement Calculus: A System- atic Introduction. Springer
1998
-
[3]
Mike Bayer and the SQLAlchemy authors. 2024. SQLAlchemy — The Database Toolkit for Python. https://www.sqlalchemy.org/
2024
-
[4]
Elliott Bell and Leonard J
D. Elliott Bell and Leonard J. LaPadula. 1976.Secure Computer System: Unified Exposition and Multics Interpretation. Technical Report ESD-TR-75-306. MITRE Corporation
1976
-
[5]
Mihir Bellare, Ran Canetti, and Hugo Krawczyk. 1996. Keying Hash Functions for Message Authentication. InAdvances in Cryptology — CRYPTO ’96. Springer, 1–15
1996
-
[6]
Mihir Bellare and Bennet S. Yee. 1997.Forward Integrity for Secure Audit Logs. Technical Report CS98-580. Dept. of Computer Science, UC San Diego
1997
-
[7]
Bernstein, Niels Duif, Tanja Lange, Peter Schwabe, and Bo-Yin Yang
Daniel J. Bernstein, Niels Duif, Tanja Lange, Peter Schwabe, and Bo-Yin Yang
-
[8]
High-speed high-security signatures.Journal of Cryptographic Engineering 2, 2 (2012), 77–89
2012
-
[9]
2011.SR 11-7: Supervisory Guidance on Model Risk Management
Board of Governors of the Federal Reserve System and Office of the Comptroller of the Currency. 2011.SR 11-7: Supervisory Guidance on Model Risk Management. Technical Report. Federal Reserve
2011
-
[10]
Bren- dan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Bren- dan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. 2017. Practical Secure Aggregation for Privacy-Preserving Machine Learning. InPro- ceedings of the 2017 ACM Conference on Computer and Communications Security. 1175–1191
2017
-
[11]
Braintrust Data. 2024. Braintrust: AI Evaluation Platform. https://braintrust.dev
2024
-
[12]
Quinn Burke, Anjo Vahldiek-Oberwagner, Michael Swift, and Patrick McDaniel
-
[13]
It's a Feature, Not a Bug: Secure and Auditable State Rollback for Confidential Cloud Applications
It’s a Feature, Not a Bug: Secure and Auditable State Rollback for Confi- dential Cloud Applications. InIEEE Symposium on Security and Privacy (S&P). arXiv:2511.13641
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Tomer Jordi Chaffer. 2025. Know Your Agent: Governing AI Identity on the Agentic Web.SSRN Electronic Journal(2025). doi:10.2139/ssrn.5162127
- [15]
-
[16]
Cloud Native Computing Foundation. 2024. OpenTelemetry: Observability Frame- work for Cloud-Native Software. https://opentelemetry.io/
2024
-
[17]
Cloudflare. 2022. Improving the WAF with Machine Learning. https://blog. cloudflare.com/waf-ml/
2022
-
[18]
Crosby and Dan S
Scott A. Crosby and Dan S. Wallach. 2009. Efficient Data Structures for Tamper- Evident Logging. InUSENIX Security Symposium
2009
-
[19]
Joseph W. Cutler, Craig Disselkoen, Aaron Eline, Shaobo He, Kyle Headley, Michael Hicks, Kesha Hietala, John Kastner, Anwar Mamat, Matt McCutchen, Neha Rungta, Bhakti Shah, Emina Torlak, and Andrew Wells. 2024. Cedar: A New Language for Expressive, Fast, Safe, and Analyzable Authorization.Proc. ACM Pro- gram. Lang. (OOPSLA1)8 (2024), 670–697. arXiv:2403.0...
-
[20]
Dorothy E. Denning. 1976. A Lattice Model of Secure Information Flow.Commun. ACM19, 5 (1976), 236–243
1976
- [21]
-
[22]
2014.The Algorithmic Foundations of Differential Privacy
Cynthia Dwork and Aaron Roth. 2014.The Algorithmic Foundations of Differential Privacy. Vol. 9. 211–407 pages
2014
-
[23]
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. 2024. RA- GAs: Automated Evaluation of Retrieval Augmented Generation. InProc. 18th Conference of the European Chapter of the ACL: System Demonstrations. 150–158
2024
-
[24]
European Parliament and Council. 2024. Regulation (EU) 2024/1689 on Artificial Intelligence (Artificial Intelligence Act). Official Journal of the European Union
2024
-
[25]
Marcelo Fernandez. 2026. Agent Control Protocol: Admission Control for Agent Actions. arXiv:2603.18829
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
FIRST.Org, Inc. 2019. Common Vulnerability Scoring System v3.1: Specification Document. https://www.first.org/cvss/v3.1/specification-document
2019
-
[27]
Garry A. Gabison and R. Patrick Xian. 2025. Inherent and emergent liability issues in LLM-based agentic systems: a principal-agent perspective. InREALM Workshop at ACL 2025. arXiv:2504.03255
-
[28]
Galileo Technologies. 2024. Galileo: AI Reliability and Evaluation Platform. https://galileo.ai
2024
-
[29]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, et al. 2024. A framework for few-shot language model evaluation. doi:10.5281/zenodo.12608602
- [30]
-
[31]
Google Cloud. 2024. Google Cloud IAM Deny Policies. https://cloud.google.com/ iam/docs/deny-overview
2024
-
[32]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. InProc. 16th ACM Workshop on Artificial Intelligence and Security (AISec). 79–90. KYA: A Framework-Agnostic Trust Layer for Autonomous Sys...
2023
-
[33]
Ken Huang, Kyriakos Rock Lambros, Jerry Huang, Yasir Mehmood, Ham- mad Atta, Joshua Beck, Vineeth Sai Narajala, Muhammad Zeeshan Baig, et al
-
[34]
AAGATE: A NIST AI RMF-Aligned Governance Platform for Agentic AI. arXiv:2510.25863 [cs.CR]
-
[35]
IBM. 2024. What is SOAR (Security Orchestration, Automation and Re- sponse)? https://www.ibm.com/think/topics/security-orchestration-automation- response
2024
-
[36]
International Organization for Standardization. 2023. ISO/IEC 42001:2023 — Information technology — Artificial intelligence — Management system
2023
-
[37]
Keromytis, Steven M
Sotiris Ioannidis, Angelos D. Keromytis, Steven M. Bellovin, and Jonathan M. Smith. 2000. Implementing a Distributed Firewall. InProc. 7th ACM Conf. on Computer and Communications Security (CCS). ACM, 190–199
2000
-
[38]
2024.DeepEval
Jeffrey Ip and Kritin Vongthongsri. 2024.DeepEval. https://github.com/confident- ai/deepeval
2024
-
[39]
ISO/IEC 2025.ISO/IEC 42005:2025 Information technology — Artificial intelligence — AI System Impact Assessment. ISO/IEC
2025
-
[40]
Istio Project. 2024. Istio Authorization Policy. https://istio.io/latest/docs/ reference/config/security/authorization-policy/
2024
- [41]
-
[42]
2021.STIX Version 2.1, OASIS Standard
Bret Jordan, Rich Piazza, and Trey Darley. 2021.STIX Version 2.1, OASIS Standard. Technical Report. OASIS
2021
-
[43]
Brendan McMahan, Brendan Avent, Aurelien Bellet, et al
Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aurelien Bellet, et al. 2021. Advances and Open Problems in Federated Learning.Foundations and Trends in Machine Learning14, 1–2 (2021), 1–210
2021
-
[44]
Kamvar, Mario T
Sepandar D. Kamvar, Mario T. Schlosser, and Hector Garcia-Molina. 2003. The EigenTrust Algorithm for Reputation Management in P2P Networks. InProc. 12th Int. Conf. on World Wide Web (WWW). ACM, 640–651
2003
- [45]
-
[46]
Kephart and David M
Jeffrey O. Kephart and David M. Chess. 2003. The Vision of Autonomic Computing. IEEE Computer36, 1 (2003), 41–50
2003
-
[47]
2023.Langfuse: Open Source LLM Engineering Platform
Marc Klingen, Maximilian Deichmann, and Clemens Rawert. 2023.Langfuse: Open Source LLM Engineering Platform
2023
-
[48]
Trishank Karthik Kuppusamy, Akan Brown, Sebastien Awwad, Damon McCoy, Russ Bielawski, Cameron Mott, Sam Lauzon, Andre Weimerskirch, and Justin Cappos. 2016. Uptane: Securing Software Updates for Automobiles. In14th ESCAR Europe
2016
-
[49]
LangChain, Inc. 2024. LangSmith: Observability and Evaluation Platform for LLM Applications. https://smith.langchain.com
2024
-
[50]
2013.Certificate Transparency
Ben Laurie, Adam Langley, and Emilia Kasper. 2013.Certificate Transparency. RFC 6962. IETF
2013
-
[51]
Percy Liang, Rishi Bommasani, Tony Lee, et al . 2023. Holistic Evaluation of Language Models.Transactions on Machine Learning Research(2023)
2023
-
[52]
Ruichao Liang, Le Yin, Jing Chen, Yebo Feng, Cong Wu, Xiaoyu Zhang, Huang- peng Gu, Zijian Zhang, and Yang Liu. 2025. Don’t Trust Your Upstream: Exploiting LLM Multi-Agent System via Topology-Guided Adversarial Propagation.arXiv preprint(2025). arXiv:2512.04129
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [53]
-
[54]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. 2017. Communication-Efficient Learning of Deep Net- works from Decentralized Data. InArtificial Intelligence and Statistics (AISTATS)
2017
-
[55]
Microsoft Agent Governance Toolkit contributors. 2026. Cross-organization policy federation (follow-up to ADR-0007). https://github.com/microsoft/agent- governance-toolkit/issues/1386
2026
-
[56]
Microsoft AI Red Team. 2024. PyRIT: Python Risk Identification Toolkit for Generative AI. https://github.com/Azure/PyRIT
2024
-
[57]
Microsoft Learn. 2024. Use Signed Policies to Protect Windows Defender Appli- cation Control Against Tampering. https://learn.microsoft.com/en-us/windows/ security/application-security/application-control/
2024
-
[58]
Microsoft Open Source. 2026. Agent Governance Toolkit: Open-source Runtime Security for AI Agents. https://github.com/microsoft/agent-governance-toolkit. Public preview, MIT License, April 2026
2026
-
[59]
Who Done It?
Mark S. Miller, Jed Donnelley, and Alan H. Karp. 2007. Delegating Responsibility in Digital Systems: Horton’s “Who Done It?”. In2nd USENIX Workshop on Hot Topics in Security (HotSec)
2007
-
[60]
Yohei Nakajima. 2026. The Log is the Agent: Event-Sourced Reactive Graphs for Auditable, Forkable Agentic Systems. https://arxiv.org/abs/2605.21997. arXiv:2605.21997 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
2023.Artificial Intelligence Risk Management Framework (AI RMF 1.0)
National Institute of Standards and Technology. 2023.Artificial Intelligence Risk Management Framework (AI RMF 1.0). Technical Report NIST AI 100-1. U.S. Department of Commerce
2023
-
[62]
2024.Artificial Intelligence Risk Management Framework: Generative AI Profile
National Institute of Standards and Technology. 2024.Artificial Intelligence Risk Management Framework: Generative AI Profile. Technical Report NIST AI 600-1. U.S. Department of Commerce
2024
- [63]
-
[64]
Zachary Newman, John Speed Meyers, and Santiago Torres-Arias. 2022. Sigstore: Software Signing for Everybody. InACM CCS
2022
-
[65]
Okta. 2026. Non-human and Human Identities: A Unified Approach. https://www. okta.com/blog/ai/non-human-and-human-identities-a-unified-approach/
2026
-
[66]
Open Policy Agent Authors. 2024. Open Policy Agent: Bundles — Signing and Verification. https://www.openpolicyagent.org/docs/management-bundles
2024
-
[67]
OpenAI. 2023. Evals: A Framework for Evaluating LLMs. https://github.com/ openai/evals
2023
-
[68]
2025.AIVSS Scoring System For OW ASP Agentic AI Core Security Risks v0.5
OWASP Foundation. 2025.AIVSS Scoring System For OW ASP Agentic AI Core Security Risks v0.5. Technical Report. OWASP. https://aivss.owasp.org/
2025
-
[69]
Daniel Ramage and Stefano Mazzocchi. 2020. Federated Analytics: Collaborative Data Science without Data Collection. Google Research Blog
2020
- [70]
-
[71]
2020.JSON Canonicalization Scheme (JCS)
Anders Rundgren, Bret Jordan, and Samuel Erdtman. 2020.JSON Canonicalization Scheme (JCS). RFC 8785. IETF
2020
-
[72]
Justin Samuel, Nick Mathewson, Justin Cappos, and Roger Dingledine. 2010. Survivable Key Compromise in Software Update Systems. InProc. 17th ACM Conf. on Computer and Communications Security (CCS). ACM, 61–72
2010
-
[73]
Brell Sanwouo et al. 2025. Breaking the Loop: AWARE is the New MAPE-K. In Proc. 33rd ACM Intl. Conf. on the Foundations of Software Engineering (FSE 2025) — Ideas, Visions, and Reflections. doi:10.1145/3696630.3728512
- [74]
-
[75]
Bruce Schneier and John Kelsey. 1998. Cryptographic Support for Secure Logs on Untrusted Machines. InUSENIX Security Symposium
1998
- [76]
-
[77]
Tingda Shen, Yebo Feng, Konglin Zhu, Xiaojun Jia, Yang Liu, and Lin Zhang
-
[78]
Sealing the Audit-Runtime Gap for LLM Skills
Sealing the Audit-Runtime Gap for LLM Skills. arXiv:2605.05274
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Nate Soares, Benja Fallenstein, Eliezer Yudkowsky, and Stuart Armstrong. 2015. Corrigibility. InWorkshops at the Twenty-Ninth AAAI Conference on Artificial Intelligence
2015
-
[80]
Renan Souza, Amal Gueroudji, Stephen DeWitt, Daniel Rosendo, Tirthankar Ghosal, Robert Ross, Prasanna Balaprakash, and Rafael Ferreira da Silva. 2025. PROV-AGENT: Unified Provenance for Tracking AI Agent Interactions in Agentic Workflows. InIEEE Int’l Conf. on e-Science. arXiv:2508.02866
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.