Mural: Transferring LLM knowledge to image generation via Mixture-of-Transformers
Pith reviewed 2026-06-30 09:20 UTC · model grok-4.3
The pith
A frozen LLM transfers its knowledge to guide image generation when attention is shared with a diffusion model in Mixture-of-Transformers, using only standard text-image pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretrained LLM knowledge can guide image synthesis under standard text-to-image training paradigms, without interleaved multimodal signals or explicit reasoning supervision, when a frozen reasoning-capable LLM is integrated with a diffusion-based image generator via shared attention within the Mixture-of-Transformers architecture; this produces strong benchmark performance and emergent behaviors absent from the training data.
What carries the argument
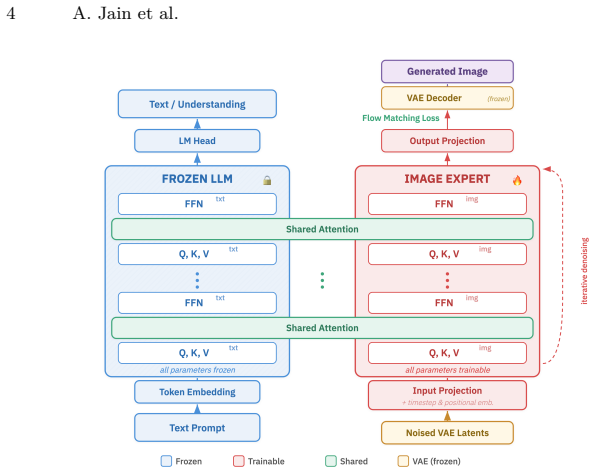
Mixture-of-Transformers architecture with shared attention, which keeps the frozen LLM's parameters active and able to shape the diffusion process during training on text-image pairs.
If this is right
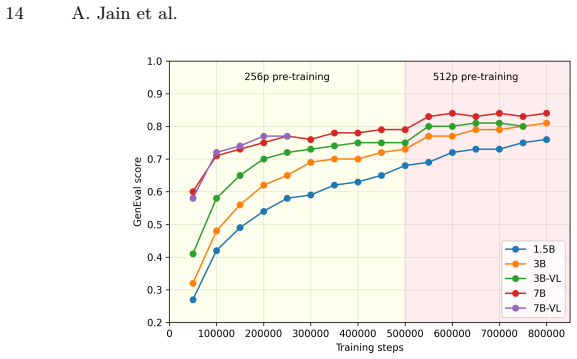
- The models reach 0.85 on GenEval, 86.75 on DPG-Bench, and 0.66 on WISE when inference-time reasoning is used.
- Behaviors absent from training data emerge, including cross-lingual image generation, color-guided composition, and emoji or ASCII scene construction.
- Generation can be steered by the LLM's world knowledge without explicit supervision.
- The LLM's intrinsic knowledge remains accessible during ordinary text-to-image training.
Where Pith is reading between the lines
- Shared-attention designs may allow knowledge transfer across other modality pairs without large aligned datasets.
- The results suggest that explicit multimodal pretraining is not always required for aligned generation capabilities.
- Scaling the size of the frozen LLM could strengthen the observed emergent behaviors.
- The same mechanism might support efficient multimodal extensions in resource-limited settings.
Load-bearing premise
Shared attention between the frozen LLM and the image generator keeps the LLM's knowledge accessible and transferable without any extra multimodal data or supervision.
What would settle it
An ablation that removes the shared attention links while keeping the LLM frozen would eliminate the reported benchmark gains and emergent behaviors.
Figures





read the original abstract
Leveraging capabilities of large language models (LLMs) in text-to-image (T2I) synthesis is an important research direction. In this work we investigate whether the knowledge of a frozen LLM can be effectively utilized in T2I generation when trained exclusively on standard text-image pairs. We integrate a frozen, reasoning-capable LLM with a diffusion-based image generator via shared attention within the Mixture-of-Transformers (MoT) architecture. Our experiments span two critical questions: (1) what degree of the LLM's intrinsic knowledge remains accessible during T2I training, and (2) what novel capabilities emerge in the resulting system. Across established benchmarks, our models achieve strong performance among unified understanding-generation systems: 0.85 on GenEval, 86.75 on DPG-Bench, and 0.66 on WISE with inference-time reasoning, using only text-image data. Remarkably, we uncover emergent behaviors absent from training data, including cross-lingual image generation, color-guided composition, emoji / ASCII scene construction, and generation directed by world knowledge. These results demonstrate that pretrained LLM knowledge can guide image synthesis under standard text-to-image training paradigms, without interleaved multimodal signals or explicit reasoning supervision. Our findings open new avenues for harnessing frozen model capabilities in resource-constrained multimodal learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mural, which integrates a frozen reasoning-capable LLM into a diffusion-based T2I generator via shared attention in the Mixture-of-Transformers (MoT) architecture. Trained exclusively on standard text-image pairs (no interleaved multimodal data or explicit reasoning supervision), it reports strong benchmark results among unified systems (0.85 GenEval, 86.75 DPG-Bench, 0.66 WISE with inference-time reasoning) and claims emergent capabilities including cross-lingual generation, color-guided composition, emoji/ASCII scene construction, and world-knowledge-directed outputs. The central thesis is that pretrained LLM knowledge remains accessible and useful for guiding image synthesis under these constraints.
Significance. If the isolation of LLM knowledge transfer holds, the result would be significant for multimodal learning: it would demonstrate that frozen LLM capabilities can be transferred to generation tasks using only text-image pairs and shared attention, without the cost of multimodal pretraining or interleaved signals. This could enable more resource-efficient unified models and explain emergent behaviors arising from joint training. The reported benchmark numbers and listed emergent behaviors, if robust, would support broader claims about leveraging existing model knowledge in constrained settings.
major comments (2)
- [Abstract / experimental setup] Abstract / experimental setup: the central claim that 'pretrained LLM knowledge can guide image synthesis' via shared attention in MoT requires evidence that the gains derive from the LLM's intrinsic (pretrained) knowledge rather than from joint MoT training with any sufficiently expressive text encoder. No ablation is described that replaces the frozen pretrained LLM with a randomly initialized transformer of matched capacity while holding the MoT architecture, shared attention, and diffusion training fixed. Without this control, the benchmark scores and emergent behaviors remain compatible with the alternative that any expressive text encoder integrated via shared attention would yield similar joint-training effects.
- [Abstract] Abstract: the reported scores (0.85 GenEval, 86.75 DPG-Bench, 0.66 WISE) and emergent behaviors are presented as evidence for the accessibility of LLM knowledge, yet the description contains no controls, baseline comparisons, or error analysis that would allow attribution to the frozen LLM component specifically. This is load-bearing for the two critical questions posed in the abstract.
minor comments (1)
- [Abstract] The abstract states results 'with inference-time reasoning' for the WISE score but does not specify the exact mechanism or whether it relies on the LLM component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for stronger controls to attribute results specifically to pretrained LLM knowledge. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / experimental setup] Abstract / experimental setup: the central claim that 'pretrained LLM knowledge can guide image synthesis' via shared attention in MoT requires evidence that the gains derive from the LLM's intrinsic (pretrained) knowledge rather than from joint MoT training with any sufficiently expressive text encoder. No ablation is described that replaces the frozen pretrained LLM with a randomly initialized transformer of matched capacity while holding the MoT architecture, shared attention, and diffusion training fixed. Without this control, the benchmark scores and emergent behaviors remain compatible with the alternative that any expressive text encoder integrated via shared attention would yield similar joint-training effects.
Authors: We agree that an ablation replacing the frozen pretrained LLM with a randomly initialized transformer of matched capacity would more conclusively isolate the contribution of pretraining. Our experiments demonstrate that the frozen LLM enables strong benchmark performance and emergent behaviors under standard text-image training, but we acknowledge this does not rule out similar effects from any expressive encoder. We will add a limitations discussion noting this gap and the computational cost of such controls. revision: partial
-
Referee: [Abstract] Abstract: the reported scores (0.85 GenEval, 86.75 DPG-Bench, 0.66 WISE) and emergent behaviors are presented as evidence for the accessibility of LLM knowledge, yet the description contains no controls, baseline comparisons, or error analysis that would allow attribution to the frozen LLM component specifically. This is load-bearing for the two critical questions posed in the abstract.
Authors: The abstract frames the results as arising from integration of a frozen reasoning-capable LLM. We will revise the abstract and main text to more precisely qualify the claims, explicitly note the absence of random-initialization controls, and add a brief discussion of alternative explanations consistent with joint training effects. revision: partial
- Absence of an ablation replacing the pretrained LLM with a randomly initialized transformer of matched capacity (requires new large-scale experiments beyond current resources).
Circularity Check
No circularity: empirical claims rest on experimental outcomes, not definitional reductions
full rationale
The manuscript describes an architecture (MoT with shared attention between frozen LLM and diffusion generator) and reports benchmark scores plus emergent behaviors from training on text-image pairs. No equations, parameter-fitting steps presented as predictions, or load-bearing self-citations appear in the provided text. The central claim—that pretrained LLM knowledge remains accessible and useful—is framed as an empirical finding rather than a derivation that reduces to its own inputs by construction. This is the normal case of a self-contained experimental paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: CVPR (2023)
Bao, F., Nie, S., Xue, K., Cao, Y., Li, C., Su, H., Zhu, J.: All are worth words: A ViT backbone for diffusion models. In: CVPR (2023)
2023
-
[2]
Computer Science (2023)
Betker, J., Goh, G., Jing, L., Brooks, T., Wang, J., Li, L., Ouyang, L., Zhuang, J., Lee, J., Guo, Y., et al.: Improving image generation with better captions. Computer Science (2023)
2023
-
[3]
https://blackforestlabs.ai/ (2024)
Black Forest Labs: FLUX.1. https://blackforestlabs.ai/ (2024)
2024
-
[4]
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
Cai, Q., Chen, J., Chen, Y., Li, Y., Long, F., Pan, Y., Qiu, Z., Zhang, Y., Gao, F., Xu, P., et al.: HiDream-I1: A high-efficient image generative foundation model with sparse diffusion transformer. arXiv preprint arXiv:2505.22705 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team: Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
In: ICML (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024)
2024
-
[9]
Gao, Y., Gong, L., Guo, Q., Hou, X., Lai, Z., Li, F., Li, L., Lian, X., Liao, C., Liu, L., et al.: Seedream 3.0 technical report. arXiv preprint arXiv:2504.11346 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
NeurIPS (2023)
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. NeurIPS (2023)
2023
-
[11]
In: CVPR (2025)
Han, J., Liu, J., Jiang, Y., Yan, B., Zhang, Y., Yuan, Z., Peng, B., Liu, X.: Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. In: CVPR (2025)
2025
-
[12]
NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS (2020)
2020
-
[13]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Hu, X., Wang, R., Fang, Y., Fu, B., Cheng, P., Yu, G.: ELLA: Equip diffusion mod- els with LLM for enhanced semantic alignment. arXiv preprint arXiv:2403.05135 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
In: NeurIPS (2024)
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation without vector quantization. In: NeurIPS (2024)
2024
-
[15]
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
Liang, W., Yu, L., Luo, L., Iyer, S., Dong, N., Zhou, C., Ghosh, G., Lewis, M., Yih, W.t., Zettlemoyer, L., et al.: Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models. arXiv preprint arXiv:2411.04996 (2024) 16 A. Jain et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Lin, B., Li, Z., Cheng, X., Niu, Y., Ye, Y., He, X., Yuan, S., Yu, W., Wang, S., Ge, Y., et al.: Uniworld-v1: High-resolution semantic encoders for unified visual understanding and generation. arXiv preprint arXiv:2506.03147 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
In: ICLR (2023)
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: ICLR (2023)
2023
-
[18]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[19]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Niu, Y., Ning, M., Zheng, M., Jin, W., Lin, B., Jin, P., Liao, J., Feng, C., Ning, K., Zhu, B., et al.: WISE: A world knowledge-informed semantic evaluation for text-to-image generation. arXiv preprint arXiv:2503.07265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Cosmos 3: Omnimodal World Models for Physical AI
Nvidia: Cosmos 3: Omnimodal World Models for Physical AI. arXiv preprint arXiv:2606.02800 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
https://openai.com/index/hello-gpt-4o/ (2024)
OpenAI: GPT-4o. https://openai.com/index/hello-gpt-4o/ (2024)
2024
-
[22]
Transfer between Modalities with MetaQueries
Pan, X., Shukla, S.N., Singh, A., Zhao, Z., Mishra, S.K., Wang, J., Xu, Z., Chen, J., Li, K., Juefei-Xu, F., et al.: Transfer between modalities with metaqueries. arXiv preprint arXiv:2504.06256 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
In: ICCV (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023)
2023
-
[24]
In: ICLR (2024)
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. In: ICLR (2024)
2024
-
[25]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[26]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
In: NeurIPS (2025)
Shi, W., Han, X., Zhou, C., Liang, W., Lin, X., Zettlemoyer, L., Yu, L.: LMFu- sion: Adapting pretrained language models for multimodal generation. In: NeurIPS (2025)
2025
-
[28]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., et al.: Omnigen2: Exploration to advanced multimodal generation. arXiv preprint arXiv:2506.18871 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. arXiv preprint arXiv:2408.12528 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al.: Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2024) Mural 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
NeurIPS (2019)
Zhang, B., Sennrich, R.: Root mean square layer normalization. NeurIPS (2019)
2019
-
[36]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., Levy, O.: Transfusion: Predict the next token and diffuse images with one multi-modal model. arXiv preprint arXiv:2408.11039 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.