Compatibility-Aware Dynamic Fine-Tuning for Large Language Models
Pith reviewed 2026-07-05 02:17 UTC · model glm-5.2
The pith
Down-weighting mismatched training data stabilizes LLM fine-tuning
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
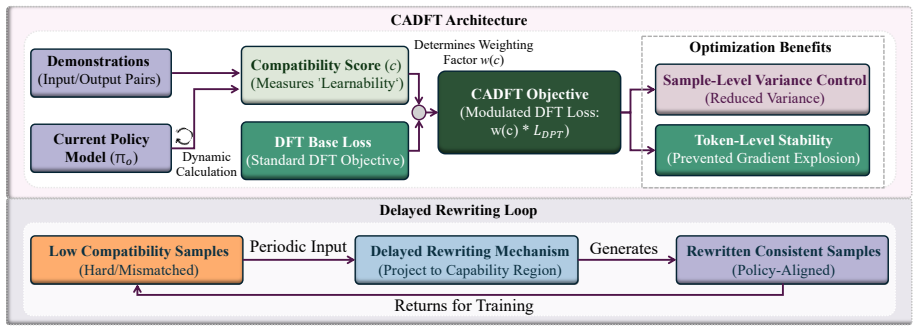
The central finding is that samples the model currently assigns low probability to produce disproportionately high-variance gradients during fine-tuning, and that dynamically down-weighting these samples based on batch-normalized likelihood scores reduces optimization variance and improves generalization across mathematical reasoning, code generation, and multimodal reasoning tasks. The paper provides empirical evidence (Table 8, Figure 3) that low-compatibility samples induce gradient variance roughly 2-4x higher than high-compatibility samples, and shows that compatibility-aware reweighting lowers overall gradient variance from 2.61 (DFT) to 1.72 (CADFT) while improving accuracy across all
What carries the argument
Compatibility-Aware Dynamic Fine-Tuning (CADFT): a training objective that extends Dynamic Fine-Tuning by multiplying each sample's DFT loss by a weight w = exp(-beta * max(0, c_hat)), where c_hat is the z-score-normalized, length-averaged negative log-likelihood of the sample under the current model. Lower-likelihood samples receive exponentially decaying weights, suppressing their gradient contributions. An optional delayed rewriting mechanism replaces targets of persistently incompatible samples with model-generated samples after a warm-up phase.
If this is right
- If sample-level compatibility is a major variance source, then dataset curation for LLM fine-tuning should account for dynamic model-sample alignment, not just static quality metrics.
- The compatibility signal could serve as a real-time training diagnostic, flagging which portions of a dataset are being underutilized and might benefit from rewriting or curriculum reordering.
- The delayed rewriting mechanism suggests a middle ground between pure imitation and self-generated training, where the model's own outputs gradually replace incompatible supervision in a controlled way.
- If CADFT provides stronger RL initialization, the boundary between supervised and reinforcement learning may be more continuous than typically assumed, with variance reduction in SFT directly benefiting downstream policy optimization.
Where Pith is reading between the lines
- The compatibility signal is model-relative and shifts during training, which means the same dataset could require different reweighting schedules depending on the base model and its training stage — a property that could enable adaptive curriculum learning without external difficulty annotations.
- If low-likelihood samples sometimes contain genuinely novel reasoning patterns the model needs to learn, then aggressive down-weighting could create a compatibility trap where the model converges to its existing inductive biases and fails to acquire new capabilities — the delayed rewriting mechanism partially addresses this but only for samples that remain incompatible after warm-up.
- The batch-normalized z-score approach means compatibility is defined relative to the current batch composition, so shuffling strategy and batch composition could interact with the reweighting in ways that affect training dynamics.
Load-bearing premise
The method treats length-normalized negative log-likelihood as a valid proxy for whether a training example is a good learning target — meaning samples the model already assigns high probability to are considered compatible and up-weighted, while samples the model finds surprising are down-weighted. If some low-likelihood samples actually contain the most informative learning signal (genuinely novel patterns the model needs to acquire), then down-weighting them would trade短期
What would settle it
If a controlled experiment showed that forcing the model to train on low-compatibility samples (with gradient clipping instead of down-weighting) produced equal or better generalization, the core premise that high-variance samples should be suppressed rather than confronted would be undermined.
Figures
read the original abstract
Supervised Fine-Tuning (SFT) is the predominant paradigm for aligning large language models (LLMs), yet it suffers from optimization instability and limited generalization. Recent work attributes this issue to pathological gradient scaling and proposes Dynamic Fine-Tuning (DFT) to correct it at the token level. However, DFT assumes all demonstrations are equally suitable learning targets, an assumption violated by the strong heterogeneity of large-scale instruction data, where demonstration-policy mismatch induces high-variance updates at the sample level. We introduce Compatibility-Aware Dynamic Fine-Tuning (CADFT), a principled extension of DFT that controls sample-level optimization variance. CADFT derives a dynamic, policy-dependent compatibility signal from model likelihoods to modulate supervised updates, suppressing high-variance gradients from incompatible demonstrations. We further propose a delayed, low-frequency compatibility-guided rewriting strategy to transform persistently incompatible demonstrations into learnable targets. We show that CADFT can be interpreted as a variance-controlled estimator that generalizes token-level stabilization in DFT to the sample level. Extensive experiments demonstrate improved stability, generalization, and cold-start reinforcement learning initialization, while remaining fully supervised and independent of explicit reward modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Compatibility-Aware Dynamic Fine-Tuning (CADFT), which extends Dynamic Fine-Tuning (DFT) by introducing a sample-level compatibility signal derived from length-normalized negative log-likelihood. Samples with low model likelihood (high NLL) are down-weighted via an exponential decay function, and a delayed rewriting mechanism optionally reformulates persistently incompatible demonstrations. The method is evaluated on mathematical reasoning, code generation, and multimodal reasoning benchmarks across multiple model families, showing consistent but modest gains over DFT and SFT. Ablations examine the compatibility definition, weighting function shape, and rewriting schedule.
Significance. The paper addresses a reasonable problem: DFT corrects token-level gradient scaling but does not account for sample-level heterogeneity in demonstration quality. The idea of using model likelihood as a dynamic compatibility signal is simple and practically implementable. The ablation in Table 7 (inverse weighting hurts, exponential decay helps) and the gradient variance analysis in Tables 8-9 provide useful empirical evidence that the mechanism is doing something structured rather than serving as noise injection. The delayed rewriting ablation (Table 10) is a informative negative result showing that aggressive rewriting degrades performance. However, the theoretical contribution in §3.5 is thin, and the empirical claims rest on single-run results without variance estimates.
major comments (4)
- §3.5: The variance reduction argument is essentially tautological. The paper defines compatibility via gradient magnitude (low likelihood → high gradient norm, as stated in §3.1 and §3.5), then shows that down-weighting high-gradient-norm samples reduces the weighted second moment E[||g̃||²]. This is true by construction of the weighting function w(ĉ) = exp(-β·max(0, ĉ)). The claim that CADFT 'acts as a variance-controlled estimator' (§3.5, final paragraph) does not establish that variance reduction improves generalization—it only establishes that the weighted variance is lower. The paper needs either (a) a formal argument connecting weighted gradient variance reduction to generalization bounds, or (b) a clear acknowledgment that the theoretical section is motivational rather than probative, with the empirical results carrying the claim.
- Tables 1-6: No error bars, confidence intervals, or multiple-seed results are reported for any configuration. The gains over DFT range from +0.75 to +4.29 points on math (Table 1), +2.30 to +3.51 on code (Table 2), and +1.71 to +2.60 on multimodal (Table 3). In LLM fine-tuning, run-to-run variance of 1-3 points on benchmarks like MATH and HumanEval is well-documented, and Average@16 evaluation (used for all math benchmarks) can amplify small quality differences. Without at least 3 seeds and standard deviations for the main results, the central claim of 'consistent outperformance' is not distinguishable from training noise. This is load-bearing because the empirical results are the primary support for the method, given the tautological theory.
- §4.1 (Training Details): The training datasets are entirely unspecified. The paper does not state the data size, composition, source, or how data was curated for SFT/DFT/CADFT across math, code, and multimodal settings. Without this information, it is impossible to assess whether the compatibility signal is doing meaningful work or whether results are sensitive to data composition. This is a standard expectation for fine-tuning papers and must be included.
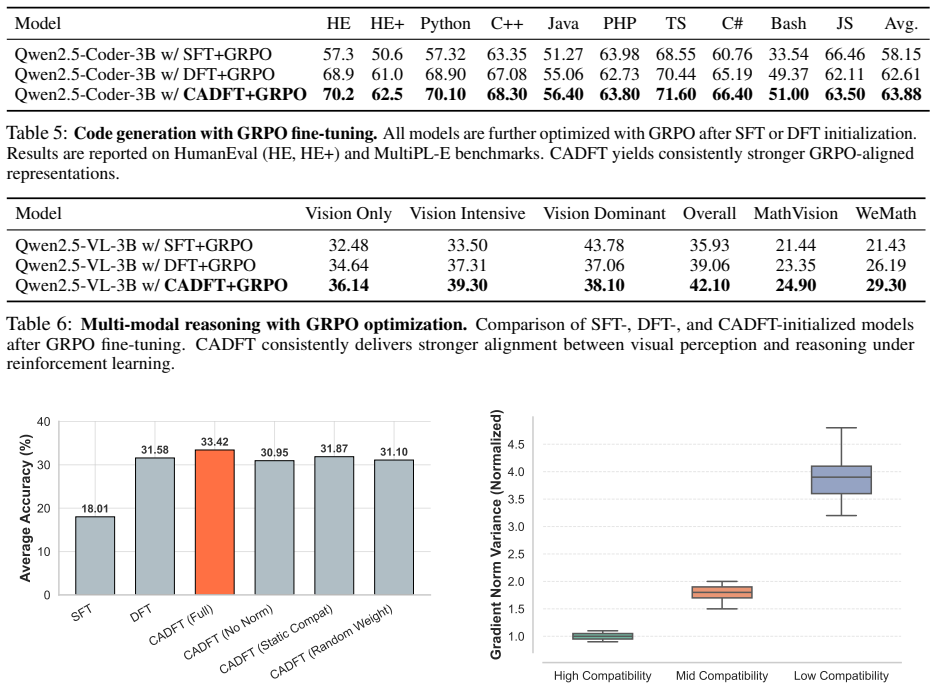
- §3.2, Eq. (2): The core assumption that length-normalized NLL is a valid proxy for 'compatibility' is not tested against the alternative hypothesis that low-likelihood samples contain the most informative learning signal (e.g., genuinely novel reasoning patterns). Table 8 shows that low-compatibility samples have higher gradient variance (3.92 vs 1.00), but this does not establish that down-weighting them improves learning—it could equally indicate that the model is learning the most from these high-variance samples. The paper would benefit from an analysis showing what happens to performance if low-compatibility samples are removed entirely (not just down-weighted), to test whether they are noise or signal.
minor comments (7)
- §3.4, Algorithm 1, line 15: The algorithm says 'Identify small subset S ⊂ D with highest moving-average compatibility scores' but the text in §3.4 says 'persistently high moving-average compatibility scores.' Since lower craw means higher compatibility (§3.2), this should say 'lowest craw' or 'highest compatibility' consistently. The current wording is ambiguous about whether 'high' refers to craw or to compatibility.
- Table 1: The base model scores for LLaMA-3.2-3B (1.63, 1.36, 1.01, 0.41, 1.56) are extremely low compared to other models. A brief note explaining why this model's zero-shot performance is so low would help readers contextualize the gains.
- Figure 2: The y-axis label 'Average Accuracy (%)' does not specify which benchmark. Given the values (31.58, 33.42), this appears to be Qwen2.5-Math-1.5B on the math average, but this should be stated explicitly.
- §3.3, Eq. (4): The weighting function uses max(0, ĉ_i), which means samples with ĉ ≤ 0 (better than batch average) get weight 1.0. This is a reasonable design choice but the paper should note that this creates a non-smooth point at ĉ = 0, which could matter for optimization dynamics.
- Table 8: The gradient variance values (1.00, 1.78, 3.92) are presented without specifying how gradient norm variance was computed (over what window, how many steps, which model). This should be clarified.
- §4.3: The GRPO training details mention 'learning rate 1e-6' but do not specify the number of GRPO training steps or total compute budget.
- The paper uses 'compatibility' throughout but the relationship between compatibility and difficulty is never fully disentangled. A brief discussion of whether the compatibility signal captures something beyond sample difficulty would strengthen the contribution.
Simulated Author's Rebuttal
We thank the referee for a careful and constructive review. The comments on the theoretical section, the absence of error bars, the missing training data description, and the need for a removal-based ablation are all well-taken. We address each below and indicate where revisions will be made.
read point-by-point responses
-
Referee: §3.5: The variance reduction argument is essentially tautological. The paper defines compatibility via gradient magnitude (low likelihood → high gradient norm, as stated in §3.1 and §3.5), then shows that down-weighting high-gradient-norm samples reduces the weighted second moment E[||g̃||²]. This is true by construction of the weighting function w(ĉ) = exp(-β·max(0, ĉ)). The claim that CADFT 'acts as a variance-controlled estimator' (§3.5, final paragraph) does not establish that variance reduction improves generalization—it only establishes that the weighted variance is lower. The paper needs either (a) a formal argument connecting weighted gradient variance reduction to generalization bounds, or (b) a clear acknowledgment that the theoretical section is motivational rather than probative, with the empirical results carrying the claim.
Authors: The referee is correct that §3.5 as written is essentially motivational: the variance reduction follows from the construction of w(ĉ), and we do not provide a formal link from weighted gradient variance to a generalization bound. We agree this should be stated honestly rather than presented as a probative theoretical contribution. In the revision, we will reframe §3.5 explicitly as a motivational analysis that (i) formalizes the intuition behind the weighting design and (ii) is supported empirically by the gradient variance measurements in Tables 8–9 and the downstream performance results. We will remove or soften the language claiming CADFT 'acts as a variance-controlled estimator' in a formal sense, and instead describe it as a heuristic variance-reduction mechanism whose effectiveness is validated empirically. We will not claim a generalization bound that we cannot substantiate. revision: yes
-
Referee: Tables 1–6: No error bars, confidence intervals, or multiple-seed results are reported for any configuration. The gains over DFT range from +0.75 to +4.29 points on math (Table 1), +2.30 to +3.51 on code (Table 2), and +1.71 to +2.60 on multimodal (Table 3). In LLM fine-tuning, run-to-run variance of 1–3 points on benchmarks like MATH and HumanEval is well-documented, and Average@16 evaluation (used for all math benchmarks) can amplify small quality differences. Without at least 3 seeds and standard deviations for the main results, the central claim of 'consistent outperformance' is not distinguishable from training noise. This is load-bearing because the empirical results are the primary support for the method, given the tautological theory.
Authors: This is a fair and important concern. We will add multi-seed results (3 seeds) with standard deviations for the main configurations in Tables 1–3. We will prioritize the Qwen2.5-Math-1.5B and Qwen2.5-Coder-3B settings, which are the most computationally tractable, and report mean ± std for each benchmark. For the larger models (7B+), we will add at least one additional seed where feasible and note where only single runs are available. We agree that without variance estimates the claim of 'consistent outperformance' is not fully supported, and we will adjust the language accordingly—framing results as 'consistent across the settings tested' with explicit variance information rather than making unqualified superiority claims. We will also add a note on Average@16 variance specifically. revision: yes
-
Referee: §4.1 (Training Details): The training datasets are entirely unspecified. The paper does not state the data size, composition, source, or how data was curated for SFT/DFT/CADFT across math, code, and multimodal settings. Without this information, it is impossible to assess whether the compatibility signal is doing meaningful work or whether results are sensitive to data composition. This is a standard expectation for fine-tuning papers and must be included.
Authors: The referee is correct that this information is missing and should be included. In the revision, we will add a dedicated paragraph in §4.1 specifying, for each task domain (math, code, multimodal): the training dataset name and source, approximate size, composition, and any curation or filtering applied. We follow the DFT training protocol of Wu et al. (2025) and use the same training data as that work; we will state this explicitly and cite the specific datasets. We will also clarify that SFT, DFT, and CADFT use identical training data within each domain, so the comparison is controlled for data composition. revision: yes
-
Referee: §3.2, Eq. (2): The core assumption that length-normalized NLL is a valid proxy for 'compatibility' is not tested against the alternative hypothesis that low-likelihood samples contain the most informative learning signal (e.g., genuinely novel reasoning patterns). Table 8 shows that low-compatibility samples have higher gradient variance (3.92 vs 1.00), but this does not establish that down-weighting them improves learning—it could equally indicate that the model is learning the most from these high-variance samples. The paper would benefit from an analysis showing what happens to performance if low-compatibility samples are removed entirely (not just down-weighted), to test whether they are noise or signal.
Authors: This is a thoughtful point. The binary weighting ablation in Table 7 (CADFT (Binary), I[ĉ < τ]) partially addresses this: hard-filtering low-compatibility samples yields 30.88, below DFT (31.58) and well below the soft exponential weighting (33.42). This suggests that completely removing low-compatibility samples is harmful, consistent with the hypothesis that they contain some useful signal. However, the referee's specific request—a removal-based ablation that discards (rather than reweights) low-compatibility samples—is not exactly what Table 7 tests, since the binary variant still applies full weight to retained samples and zero to others, rather than removing them from the dataset. We will add an explicit ablation where the bottom-k% compatibility samples are removed from the training set entirely (not just zero-weighted), for k ∈ {10, 20, 30}, and report performance. This will directly test whether low-compatibility samples are noise or signal. We expect, based on the binary weighting result, that moderate removal may help slightly while aggressive removal hurts, but we will report whatever the data shows. revision: yes
Circularity Check
No significant circularity. The §3.5 variance-reduction claim is trivially true but not circular by construction; empirical results are on external benchmarks.
full rationale
The paper's core derivation chain is: (1) define compatibility as length-normalized NLL (Eq. 2), (2) normalize it (Eq. 3), (3) apply exponential decay weighting (Eq. 4), (4) claim variance reduction (§3.5). The §3.5 'theoretical perspective' states that under the assumption that low-compatibility samples have high gradient norms, down-weighting them reduces the weighted second moment E[||g̃||²]. This is trivially true—multiplying any subset of gradients by weights < 1 reduces the second moment—but it is not circular in the strict sense: compatibility is defined via NLL (Eq. 2), while gradient norm is a separate quantity. The link between them is stated as an assumption ('Under the commonly observed assumption that incompatible or low-probability demonstrations induce disproportionately large gradient norms') and supported empirically (Table 8, Figure 3), not derived from the compatibility definition itself. For SFT the NLL-to-gradient-norm link is approximately mathematical (gradient of -log p scales as 1/p), but for DFT gradients (which scale as 1+log p) the link is genuinely empirical. The empirical performance claims (Tables 1–6) are measured on external benchmarks (Math500, HumanEval, etc.) and are not circular. DFT (Wu et al., 2025) is cited as the base method but is by different authors, so there is no self-citation chain. Self-citations (Zhou et al. 2023–2026) appear only in related work for background context and are not load-bearing. The one minor concern is that the 'theoretical' contribution in §3.5 is essentially a tautology rather than a substantive derivation, but this is a weakness of depth, not circularity.
Axiom & Free-Parameter Ledger
free parameters (8)
- β (compatibility sensitivity) =
1.0
- ε (normalization stability) =
1e-6
- T_warm (rewriting warm-up steps) =
3000
- K (rewriting interval) =
1000
- Rewrite fraction =
0.005
- Replacement probability =
0.5
- Nucleus sampling p =
0.9
- Sampling temperature T =
0.7
axioms (3)
- domain assumption Low model likelihood on a demonstration implies high gradient variance and poor learning signal.
- domain assumption DFT's token-level gradient correction (Wu et al. 2025) is correct and beneficial.
- ad hoc to paper Batch-level z-score normalization provides a meaningful relative compatibility signal across training.
Reference graph
Works this paper leans on
-
[1]
Zhao and Kelvin Guu and Adams Wei Yu and Brian Lester and Nan Du and Andrew M
Jason Wei and Maarten Bosma and Vincent Y. Zhao and Kelvin Guu and Adams Wei Yu and Brian Lester and Nan Du and Andrew M. Dai and Quoc V. Le , title =. The Tenth International Conference on Learning Representations,. 2022 , url =
work page 2022
-
[2]
Chunting Zhou and Pengfei Liu and Puxin Xu and Srinivasan Iyer and Jiao Sun and Yuning Mao and Xuezhe Ma and Avia Efrat and Ping Yu and Lili Yu and Susan Zhang and Gargi Ghosh and Mike Lewis and Luke Zettlemoyer and Omer Levy , editor =. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, ...
work page 2023
-
[3]
Scaling Instruction-Finetuned Language Models , journal =
Hyung Won Chung and Le Hou and Shayne Longpre and Barret Zoph and Yi Tay and William Fedus and Yunxuan Li and Xuezhi Wang and Mostafa Dehghani and Siddhartha Brahma and Albert Webson and Shixiang Shane Gu and Zhuyun Dai and Mirac Suzgun and Xinyun Chen and Aakanksha Chowdhery and Alex Castro. Scaling Instruction-Finetuned Language Models , journal =. 2024 , url =
work page 2024
-
[4]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation , booktitle =
Ajay Mandlekar and Danfei Xu and Josiah Wong and Soroush Nasiriany and Chen Wang and Rohun Kulkarni and Li Fei. What Matters in Learning from Offline Human Demonstrations for Robot Manipulation , booktitle =. 2021 , url =
work page 2021
-
[5]
Christiano and Jan Leike and Tom B
Paul F. Christiano and Jan Leike and Tom B. Brown and Miljan Martic and Shane Legg and Dario Amodei , editor =. Deep Reinforcement Learning from Human Preferences , booktitle =. 2017 , url =
work page 2017
-
[6]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , editor =...
work page 2022
-
[7]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai and Andy Jones and Kamal Ndousse and Amanda Askell and Anna Chen and Nova DasSarma and Dawn Drain and Stanislav Fort and Deep Ganguli and Tom Henighan and Nicholas Joseph and Saurav Kadavath and Jackson Kernion and Tom Conerly and Sheer El Showk and Nelson Elhage and Zac Hatfield. Training a Helpful and Harmless Assistant with Reinforcement Lea...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862 2022
-
[8]
Proximal Policy Optimization Algorithms
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. CoRR , volume =. 2017 , url =. 1707.06347 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Energy and Policy Considerations for Deep Learning in
Emma Strubell and Ananya Ganesh and Andrew McCallum , editor =. Energy and Policy Considerations for Deep Learning in. Proceedings of the 57th Conference of the Association for Computational Linguistics,. 2019 , url =. doi:10.18653/V1/P19-1355 , timestamp =
work page internal anchor Pith review doi:10.18653/v1/p19-1355 2019
-
[10]
Faster Acceleration for Steepest Descent , booktitle =
Cedar Site Bai and Brian Bullins , editor =. Faster Acceleration for Steepest Descent , booktitle =. 2025 , url =
work page 2025
-
[11]
Manning and Stefano Ermon and Chelsea Finn , editor =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , booktitle =. 2023 , url =
work page 2023
-
[12]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.03300 , eprinttype =. 2402.03300 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[13]
Bridging Supervised Learning and Reinforcement Learning in Math Reasoning , journal =
Huayu Chen and Kaiwen Zheng and Qinsheng Zhang and Ganqu Cui and Yin Cui and Haotian Ye and Tsung. Bridging Supervised Learning and Reinforcement Learning in Math Reasoning , journal =. 2025 , url =. doi:10.48550/ARXIV.2505.18116 , eprinttype =. 2505.18116 , timestamp =
-
[14]
Yuhao Du and Zhuo Li and Pengyu Cheng and Zhihong Chen and Yuejiao Xie and Xiang Wan and Anningzhe Gao , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.11026 , eprinttype =. 2502.11026 , timestamp =
-
[15]
Bo Wang and Qinyuan Cheng and Runyu Peng and Rong Bao and Peiji Li and Qipeng Guo and Linyang Li and Zhiyuan Zeng and Yunhua Zhou and Xipeng Qiu , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.00018 , eprinttype =. 2507.00018 , timestamp =
-
[16]
Siyu Chen and Heejune Sheen and Tianhao Wang and Zhuoran Yang , editor =. Training Dynamics of Multi-Head Softmax Attention for In-Context Learning: Emergence, Convergence, and Optimality (extended abstract) , booktitle =. 2024 , url =
work page 2024
-
[17]
Chongli Qin and Jost Tobias Springenberg , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.12856 , eprinttype =. 2507.12856 , timestamp =
-
[18]
Shiyue Zhang and Shijie Wu and Ozan Irsoy and Steven Lu and Mohit Bansal and Mark Dredze and David S. Rosenberg , title =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.502 , timestamp =
-
[19]
Focal Loss for Dense Object Detection , booktitle =
Tsung. Focal Loss for Dense Object Detection , booktitle =. 2017 , url =. doi:10.1109/ICCV.2017.324 , timestamp =
-
[20]
Lingyuan Liu and Mengxiang Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.06135 , eprinttype =. 2508.06135 , timestamp =
-
[21]
Yongliang Wu and Yizhou Zhou and Zhou Ziheng and Yingzhe Peng and Xinyu Ye and Xinting Hu and Wenbo Zhu and Lu Qi and Ming. On the Generalization of. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.05629 , eprinttype =. 2508.05629 , timestamp =
-
[22]
Le and Sergey Levine and Yi Ma , title =
Tianzhe Chu and Yuexiang Zhai and Jihan Yang and Shengbang Tong and Saining Xie and Dale Schuurmans and Quoc V. Le and Sergey Levine and Yi Ma , title =. Forty-second International Conference on Machine Learning,. 2025 , url =
work page 2025
-
[23]
Gokul Swamy and Sanjiban Choudhury and Wen Sun and Zhiwei Steven Wu and J. Andrew Bagnell , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.01067 , eprinttype =. 2503.01067 , timestamp =
-
[24]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell and Yuntao Bai and Anna Chen and Dawn Drain and Deep Ganguli and Tom Henighan and Andy Jones and Nicholas Joseph and Benjamin Mann and Nova DasSarma and Nelson Elhage and Zac Hatfield. A General Language Assistant as a Laboratory for Alignment , journal =. 2021 , url =. 2112.00861 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Abbas Abdolmaleki and Bilal Piot and Bobak Shahriari and Jost Tobias Springenberg and Tim Hertweck and Michael Bloesch and Rishabh Joshi and Thomas Lampe and Junhyuk Oh and Nicolas Heess and Jonas Buchli and Martin A. Riedmiller , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[26]
Curriculum learning , booktitle =
Yoshua Bengio and J. Curriculum learning , booktitle =. 2009 , url =. doi:10.1145/1553374.1553380 , timestamp =
-
[27]
Llama Team , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[28]
Shuai Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and Sibo Song and Kai Dang and Peng Wang and Shijie Wang and Jun Tang and Humen Zhong and Yuanzhi Zhu and Ming. Qwen2.5-VL Technical Report , journal =. 2025 , url =. doi:10.48550/ARXIV.2502.13923 , eprinttype =. 2502.13923 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[29]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang and Beichen Zhang and Binyuan Hui and Bofei Gao and Bowen Yu and Chengpeng Li and Dayiheng Liu and Jianhong Tu and Jingren Zhou and Junyang Lin and Keming Lu and Mingfeng Xue and Runji Lin and Tianyu Liu and Xingzhang Ren and Zhenru Zhang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2409.12122 , eprinttype =. 2409.12122 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12122 2024
-
[30]
Qwen2.5-Coder Technical Report
Binyuan Hui and Jian Yang and Zeyu Cui and Jiaxi Yang and Dayiheng Liu and Lei Zhang and Tianyu Liu and Jiajun Zhang and Bowen Yu and Kai Dang and An Yang and Rui Men and Fei Huang and Xingzhang Ren and Xuancheng Ren and Jingren Zhou and Junyang Lin , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2409.12186 , eprinttype =. 2409.12186 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12186 2024
-
[31]
Ramasesh and Ambrose Slone and Cem Anil and Imanol Schlag and Theo Gutman
Aitor Lewkowycz and Anders Andreassen and David Dohan and Ethan Dyer and Henryk Michalewski and Vinay V. Ramasesh and Ambrose Slone and Cem Anil and Imanol Schlag and Theo Gutman. Solving Quantitative Reasoning Problems with Language Models , booktitle =. 2022 , url =
work page 2022
-
[32]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2501.12948 , eprinttype =. 2501.12948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[33]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , editor =. Measuring Mathematical Problem Solving With the. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year =
work page 2021
-
[34]
Federico Cassano and John Gouwar and Daniel Nguyen and Sydney Nguyen and Luna Phipps. MultiPL-E:. 2023 , url =. doi:10.1109/TSE.2023.3267446 , timestamp =
-
[35]
Jiawei Liu and Chunqiu Steven Xia and Yuyao Wang and Lingming Zhang , editor =. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation , booktitle =. 2023 , url =
work page 2023
-
[36]
Evaluating Large Language Models Trained on Code
Mark Chen and Jerry Tworek and Heewoo Jun and Qiming Yuan and Henrique Pond. Evaluating Large Language Models Trained on Code , journal =. 2021 , url =. 2107.03374 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[37]
Renrui Zhang and Dongzhi Jiang and Yichi Zhang and Haokun Lin and Ziyu Guo and Pengshuo Qiu and Aojun Zhou and Pan Lu and Kai. 2024 , url =. doi:10.1007/978-3-031-73242-3\_10 , timestamp =
-
[38]
Chaoqun He and Renjie Luo and Yuzhuo Bai and Shengding Hu and Zhen Leng Thai and Junhao Shen and Jinyi Hu and Xu Han and Yujie Huang and Yuxiang Zhang and Jie Liu and Lei Qi and Zhiyuan Liu and Maosong Sun , editor =. OlympiadBench:. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , ur...
-
[39]
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning? , booktitle =
Runqi Qiao and Qiuna Tan and Guanting Dong and Minhui Wu and Chong Sun and Xiaoshuai Song and Jiapeng Wang and Zhuoma Gongque and Shanglin Lei and Yifan Zhang and Zhe Wei and Miaoxuan Zhang and Runfeng Qiao and Xiao Zong and Yida Xu and Peiqing Yang and Zhimin Bao and Muxi Diao and Chen Li and Honggang Zhang , editor =. We-Math: Does Your Large Multimodal...
work page 2025
-
[40]
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , booktitle =
Ke Wang and Junting Pan and Weikang Shi and Zimu Lu and Houxing Ren and Aojun Zhou and Mingjie Zhan and Hongsheng Li , editor =. Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , booktitle =. 2024 , url =
work page 2024
-
[41]
The Thirteenth International Conference on Learning Representations , year=
Weak to strong generalization for large language models with multi-capabilities , author=. The Thirteenth International Conference on Learning Representations , year=
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Less is more: Vision representation compression for efficient video generation with large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[43]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Visual in-context learning for large vision-language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
work page 2024
-
[44]
From medical llms to versatile medical agents: A comprehensive survey , author=. Authorea Preprints , year=
-
[45]
From Pattern Recognizers to Personalized Companions: A Survey of Large Language Models in Mental Health , author=. 2025 , publisher=
work page 2025
-
[46]
Improving medical large vision-language models with abnormal-aware feedback , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[47]
The Fourteenth International Conference on Learning Representations , year=
From Broad Exploration to Stable Synthesis: Entropy-Guided Optimization for Autoregressive Image Generation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[48]
Clinical Cognition Alignment for Gastrointestinal Diagnosis with Multimodal LLMs
Clinical Cognition Alignment for Gastrointestinal Diagnosis with Multimodal LLMs , author=. arXiv preprint arXiv:2603.20698 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
arXiv preprint arXiv:2512.12302 , year=
From Human Intention to Action Prediction: Intention-Driven End-to-End Autonomous Driving , author=. arXiv preprint arXiv:2512.12302 , year=
-
[50]
arXiv preprint arXiv:2512.01282 , year=
Kardia-r1: Unleashing llms to reason toward understanding and empathy for emotional support via rubric-as-judge reinforcement learning , author=. arXiv preprint arXiv:2512.01282 , year=
-
[51]
arXiv preprint arXiv:2512.07273 , year=
RVLF: A Reinforcing Vision-Language Framework for Gloss-Free Sign Language Translation , author=. arXiv preprint arXiv:2512.07273 , year=
-
[52]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Self-rewarding large vision-language models for optimizing prompts in text-to-image generation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.