Trust Your Instincts: Confidence-Driven Test-Time RL for Vision-Language-Action Models
Pith reviewed 2026-06-30 05:59 UTC · model grok-4.3
The pith
Vision-language-action models can self-improve at test time by treating high-confidence trajectories as intrinsic rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
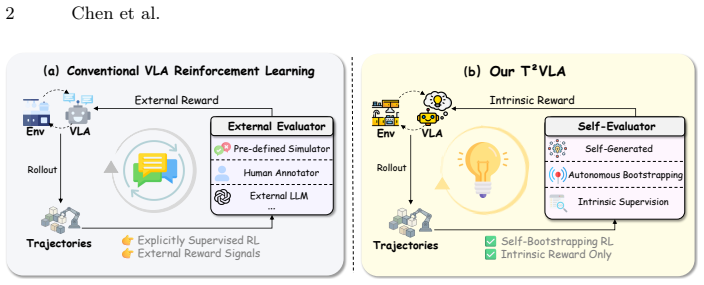
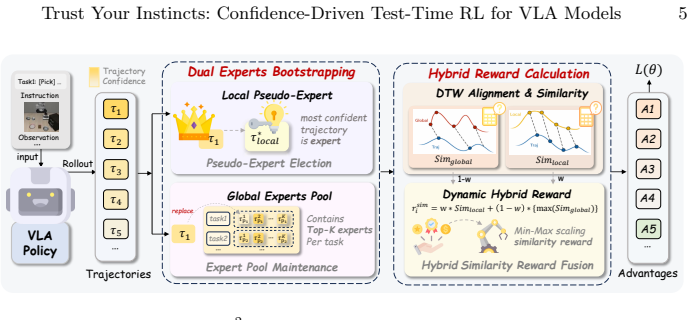
T^2VLA performs test-time policy improvement in VLAs by using trajectory-level similarity to high-confidence expert demonstrations as an intrinsic reward signal, together with a Confidence-Driven Dual Expert Bootstrapping mechanism that dynamically balances a Local Pseudo-Expert for exploration against a Global Expert Pool for stability, thereby achieving effective learning without any external environmental feedback.
What carries the argument
Confidence-Driven Dual Expert Bootstrapping mechanism that generates intrinsic rewards from model confidence and balances local exploration with global stability.
If this is right
- Outperforms supervised imitation-learning baselines on the LIBERO and RoboTwin benchmarks.
- Approaches the performance level of oracle RL that receives ground-truth rewards.
- Operates without external reward feedback while still producing measurable policy improvement.
- Transfers across distinct VLA architectures including OpenVLA-OFT and the pi series.
Where Pith is reading between the lines
- The same confidence-as-reward idea may extend to other autoregressive generation settings where success is hard to measure externally.
- Test-time self-bootstrapping could lower the data-collection cost of training embodied agents by reusing the model's own outputs.
- If confidence tracks success reliably, future VLAs might incorporate lightweight test-time updates as a standard deployment step.
Load-bearing premise
Similarity to high-confidence trajectories reliably indicates task success when no external reward is available.
What would settle it
A controlled test in which high-confidence trajectories are systematically unsuccessful yet the method still reports policy gains.
Figures
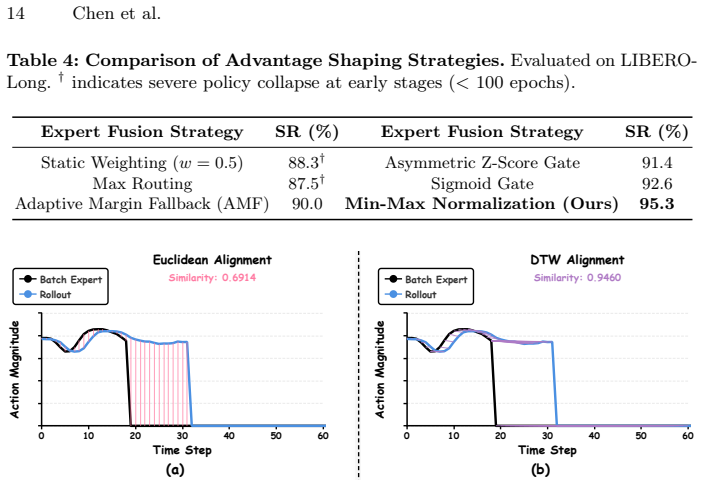
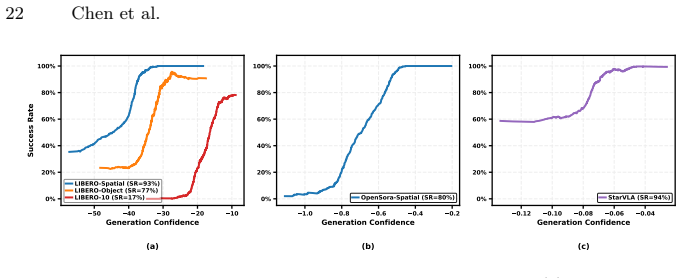
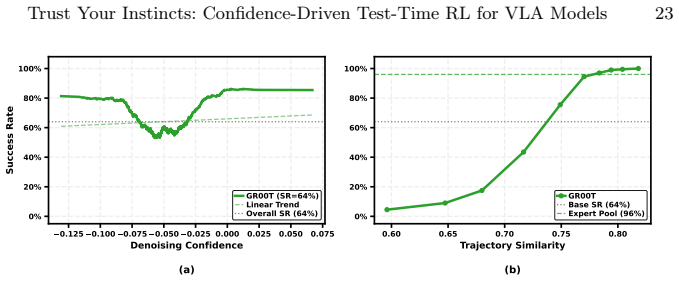
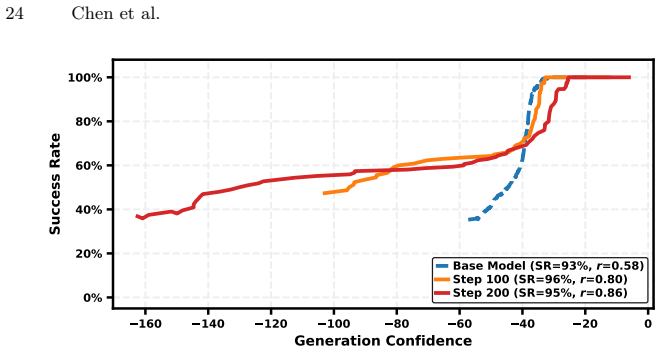
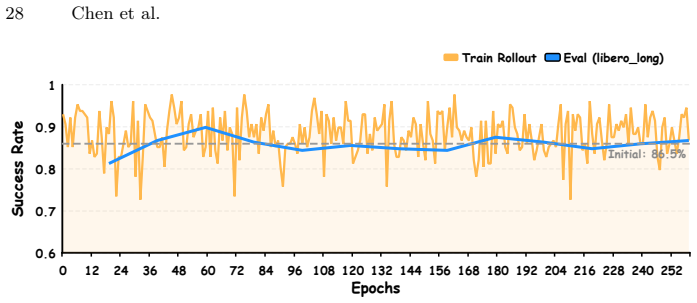
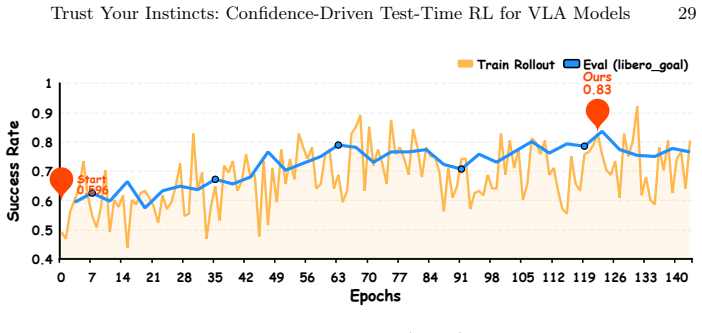
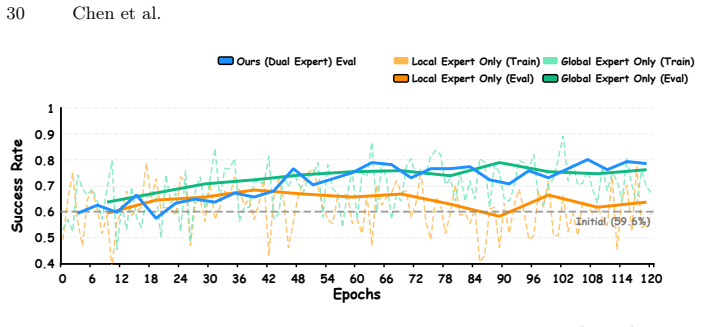
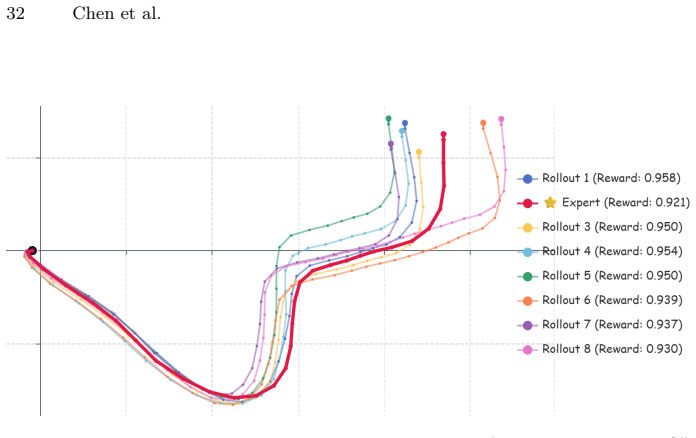
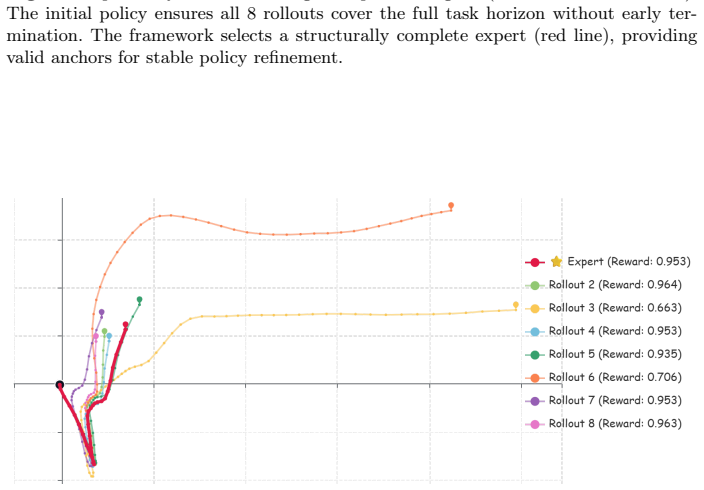
read the original abstract
Reinforcement learning (RL) has become indispensable for pushing Vision-Language-Action Models (VLAs) beyond static imitation learning. However, existing RL methods typically require external environmental feedback, relying on predefined success signals to guide policy updates. In this work, we show that VLA models possess useful internal evaluative capabilities: in discrete-action VLAs, trajectories with higher generation confidence are significantly more likely to succeed. Based on this observation, we introduce T^2VLA (Test-time VLA), an architecture-agnostic test-time RL framework that enables VLA models to achieve self-bootstrapping policy improvement. Instead of relying on external rewards, T^2VLA leverages trajectory-level similarity to high-confidence expert demonstrations as an intrinsic reward signal. In addition, we propose a Confidence-Driven Dual Expert Bootstrapping mechanism, which dynamically balances a Local Pseudo-Expert for exploration and a Global Expert Pool for training stability. Extensive experiments on the LIBERO and RoboTwin benchmarks show that T^2VLA consistently outperforms supervised baselines and approaches oracle RL performance with ground-truth rewards, achieving effective improvement without external reward feedback. Furthermore, T^2VLA adapts to distinct VLA paradigms, including both OpenVLA-OFT and the pi series.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper observes that in discrete-action VLAs, higher generation confidence trajectories are significantly more likely to succeed. It introduces T^2VLA, an architecture-agnostic test-time RL method that defines an intrinsic reward via trajectory-level similarity to high-confidence expert demonstrations, augmented by a Confidence-Driven Dual Expert Bootstrapping mechanism (local pseudo-expert for exploration, global expert pool for stability). Experiments on LIBERO and RoboTwin benchmarks claim that T^2VLA outperforms supervised baselines and approaches oracle RL performance with ground-truth rewards, while adapting to OpenVLA-OFT and pi-series VLAs.
Significance. If the central results hold, the work demonstrates a practical route to self-bootstrapping improvement in VLAs at test time without external reward signals or environment feedback. This could reduce dependence on hand-crafted success detectors in robotics deployment. The architecture-agnostic framing and dual-expert design are notable strengths if the similarity proxy is shown to be reliable.
major comments (3)
- [§3 (Method)] The motivating observation (higher confidence predicts success) is scoped to discrete-action VLAs, yet the method is presented as architecture-agnostic and applied to multiple VLA paradigms; the manuscript must clarify whether the confidence-success correlation was verified for continuous-action or other paradigms, or whether the similarity metric substitutes without re-validation.
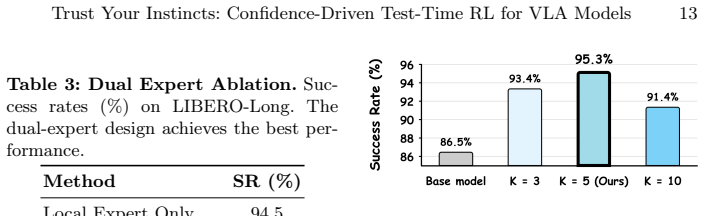
- [§3.2 (Reward Definition) and §5 (Experiments)] The intrinsic reward is defined via trajectory-level similarity to high-confidence expert rollouts rather than confidence directly. The central claim that this produces reliable policy improvement requires explicit evidence that the chosen similarity metric (action or latent space) maintains a strong positive correlation with ground-truth task success; without such validation or ablation, the self-bootstrapping loop rests on an unverified proxy.
- [§5 (Experiments)] Table or figure reporting benchmark results (LIBERO/RoboTwin) should include statistical controls, data-split details, and confidence intervals; the abstract-level claim of "consistently outperforms" and "approaches oracle RL" cannot be assessed for robustness without these.
minor comments (2)
- [§3] Notation for the similarity metric and the dual-expert weighting should be introduced with explicit equations to avoid ambiguity in the bootstrapping mechanism.
- [§3.1] Clarify whether the high-confidence expert demonstrations are drawn from the same policy or held-out data, as this affects potential circularity in the reward signal.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications and proposed revisions where appropriate. Our responses focus on strengthening the manuscript without misrepresenting the presented results.
read point-by-point responses
-
Referee: [§3 (Method)] The motivating observation (higher confidence predicts success) is scoped to discrete-action VLAs, yet the method is presented as architecture-agnostic and applied to multiple VLA paradigms; the manuscript must clarify whether the confidence-success correlation was verified for continuous-action or other paradigms, or whether the similarity metric substitutes without re-validation.
Authors: The manuscript explicitly scopes the motivating observation to discrete-action VLAs in both the abstract and §3. The architecture-agnostic claim refers to the overall T²VLA framework (similarity-based intrinsic reward + dual-expert bootstrapping), which does not require direct access to per-token confidence at inference. For continuous-action paradigms (e.g., certain pi-series variants), the similarity metric is used as a direct substitute without re-validating the confidence-success correlation in those settings. We will revise §3 to make this scoping and substitution explicit, including a short note that the correlation verification remains limited to the discrete case examined in the motivating experiments. revision: yes
-
Referee: [§3.2 (Reward Definition) and §5 (Experiments)] The intrinsic reward is defined via trajectory-level similarity to high-confidence expert rollouts rather than confidence directly. The central claim that this produces reliable policy improvement requires explicit evidence that the chosen similarity metric (action or latent space) maintains a strong positive correlation with ground-truth task success; without such validation or ablation, the self-bootstrapping loop rests on an unverified proxy.
Authors: We agree that the reward relies on trajectory similarity rather than raw confidence and that direct validation of the similarity-success correlation would strengthen the central claim. The current manuscript motivates the proxy via the discrete-action observation but does not include an explicit ablation correlating the chosen similarity metric against ground-truth success. We will add this analysis (e.g., a correlation plot or ablation table) to §5 in the revision. revision: yes
-
Referee: [§5 (Experiments)] Table or figure reporting benchmark results (LIBERO/RoboTwin) should include statistical controls, data-split details, and confidence intervals; the abstract-level claim of "consistently outperforms" and "approaches oracle RL" cannot be assessed for robustness without these.
Authors: The referee correctly identifies that the reported results lack explicit confidence intervals, multi-seed statistics, and detailed data-split descriptions. We will revise the experimental section and associated tables/figures to include means ± standard deviation over multiple random seeds, clarify the train/test splits used, and add the requested statistical controls. revision: yes
Circularity Check
No significant circularity; derivation relies on external observation and benchmark validation.
full rationale
The paper's core claim rests on an empirical observation (higher generation confidence correlates with success in discrete-action VLAs) used to motivate an intrinsic reward defined as trajectory similarity to high-confidence expert rollouts. This is presented as an architecture-agnostic test-time RL method with experimental results on LIBERO and RoboTwin showing outperformance over supervised baselines. No equations or definitions are provided in the available text that reduce the reward signal or performance gains to the inputs by construction (e.g., no self-referential normalization or fitted parameter renamed as prediction). The bootstrapping mechanism is the intended self-improvement loop, not a definitional equivalence. Self-citations, if present, are not load-bearing for the central result. The derivation is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
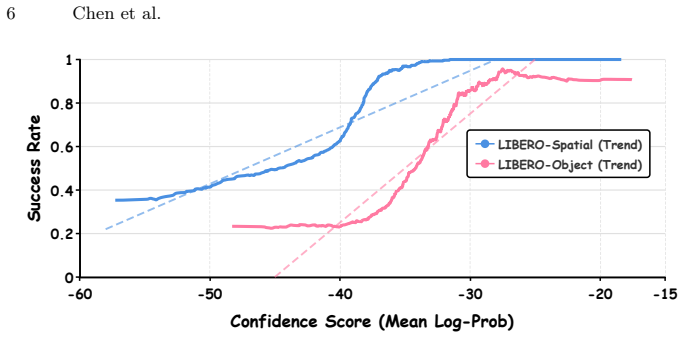
- domain assumption Trajectories with higher generation confidence are significantly more likely to succeed
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2512.14666 (2025)
Bai, Z., Gao, C., Shou, M.Z.: Evolve-vla: Test-time training from environment feed- back for vision-language-action models. arXiv preprint arXiv:2512.14666 (2025)
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A Vision-Language-Action Flow Model for General Robot Control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Bu, Q., Yang, Y., Cai, J., Gao, S., Ren, G., Yao, M., Luo, P., Li, H.: Uni- vla: Learning to act anywhere with task-centric latent actions. arXiv preprint arXiv:2505.06111 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: Conference on Robot Learning
Chebotar, Y., Vuong, Q., Hausman, K., Xia, F., Lu, Y., Irpan, A., Kumar, A., Yu, T., Herzog, A., Pertsch, K., et al.: Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions. In: Conference on Robot Learning. pp. 3909–3928. PMLR (2023)
2023
-
[7]
Chen,D.,Wang,D.,Darrell,T.,Ebrahimi,S.:Contrastivetest-timeadaptation.In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 295–305 (2022)
2022
-
[8]
arXiv preprint arXiv:2510.25889 (2025)
Chen, K., Liu, Z., Zhang, T., Guo, Z., Xu, S., Lin, H., Zang, H., Li, X., Zhang, Q., Yu, Z., et al.:πRL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models. arXiv preprint arXiv:2510.25889 (2025)
-
[9]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y., Li, Z., Liang, Q., Lin, X., Ge, Y., Gu, Z., et al.: Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
Community, S.: Starvla: A lego-like codebase for vision-language-action model de- veloping. arXiv preprint arXiv:2604.05014 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
PaLM-E: An Embodied Multimodal Language Model
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Geng, J., Cai, F., Wang, Y., Koeppl, H., Nakov, P., Gurevych, I.: A survey of confidence estimation and calibration in large language models. In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 6577–6595 (2024)
2024
-
[13]
arXiv preprint arXiv:2509.22643 (2025)
Guo, W., Lu, G., Deng, H., Wu, Z., Tang, Y., Wang, Z.: Vla-reasoner: Empowering vision-language-action models with reasoning via online monte carlo tree search. arXiv preprint arXiv:2509.22643 (2025)
-
[14]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Guo, Y., Zhang, J., Chen, X., Ji, X., Wang, Y.J., Hu, Y., Chen, J.: Improving vision-language-action model with online reinforcement learning. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 15665–15672. IEEE (2025)
2025
-
[15]
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
Huang, C.P., Wu, Y.H., Chen, M.H., Wang, Y.C.F., Yang, F.E.: Thinkact: Vision- language-action reasoning via reinforced visual latent planning. arXiv preprint arXiv:2507.16815 (2025) Trust Your Instincts: Confidence-Driven Test-Time RL for VLA Models 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
arXiv preprint arXiv:2508.02219 (2025)
Huang, D., Fang, Z., Zhang, T., Li, Y., Zhao, L., Xia, C.: Co-rft: Efficient fine- tuning of vision-language-action models through chunked offline reinforcement learning. arXiv preprint arXiv:2508.02219 (2025)
-
[17]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π0.5: a Vision-Language-Action Model with Open-World Generalization. arXiv preprint arXiv:2504.16054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
In: Forty-first International Conference on Machine Learning (2024)
Karamcheti, S., Nair, S., Balakrishna, A., Liang, P., Kollar, T., Sadigh, D.: Pris- matic vlms: Investigating the design space of visually-conditioned language models. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[19]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. arXiv preprint arXiv:2502.19645 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Li, H., Zuo, Y., Yu, J., Zhang, Y., Yang, Z., Zhang, K., Zhu, X., Zhang, Y., Chen, T., Cui, G., et al.: Simplevla-rl: Scaling vla training via reinforcement learning. arXiv preprint arXiv:2509.09674 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
arXiv preprint arXiv:2508.06266 (2025)
Li, Z., Yang, R., Chen, R., Luo, Z., Chen, L.: Adpro: a test-time adaptive diffusion policy via manifold-constrained denoising and task-aware initialization for robotic manipulation. arXiv preprint arXiv:2508.06266 (2025)
-
[23]
Li, Z., Liu, J., Dong, Z., Teng, T., Rouxel, Q., Caldwell, D., Chen, F.: Towards deploying vla without fine-tuning: Plug-and-play inference-time vla policy steering via embodied evolutionary diffusion. arXiv preprint arXiv:2511.14178 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Advances in Neural Information Processing Systems36, 44776–44791 (2023)
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmark- ing knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36, 44776–44791 (2023)
2023
-
[25]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[26]
arXiv preprint arXiv:2602.03973 (2026)
Liu, S., Singh, I.S., Xu, Y., Duan, J., Krishna, R.: Vls: Steering pretrained robot policies via vision-language models. arXiv preprint arXiv:2602.03973 (2026)
-
[27]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., Zhu, J.: Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
Lu, G., Guo, W., Zhang, C., Zhou, Y., Jiang, H., Gao, Z., Tang, Y., Wang, Z.: Vla- rl: Towards masterful and general robotic manipulation with scalable reinforcement learning. arXiv preprint arXiv:2505.18719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Mandlekar, A., Xu, D., Wong, J., Nasiriany, S., Wang, C., Kulkarni, R., Fei-Fei, L., Savarese, S., Zhu, Y., Martín-Martín, R.: What matters in learning from offline human demonstrations for robot manipulation. arXiv preprint arXiv:2108.03298 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
arXiv preprint arXiv:2410.13816 (2024)
Nakamoto, M., Mees, O., Kumar, A., Levine, S.: Steering your generalists: Improv- ing robotic foundation models via value guidance. arXiv preprint arXiv:2410.13816 (2024)
-
[31]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., Zhu, Y.: Robocasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv:2406.02523 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
arXiv preprint arXiv:2508.12211 (2025) 18 Chen et al
Neary, C., Younis, O.G., Kuramshin, A., Aslan, O., Berseth, G.: Improving pre- trained vision-language-action policies with model-based search. arXiv preprint arXiv:2508.12211 (2025) 18 Chen et al
-
[33]
In: Findings of the Association for Computational Linguistics: ACL 2025
Nguyen, D., Payani, A., Mirzasoleiman, B.: Beyond semantic entropy: Boosting llm uncertainty quantification with pairwise semantic similarity. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 4530–4540 (2025)
2025
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peng, T., Li, M., Yuan, J., Zhou, H., Xia, R., Zhang, R., Bai, L., Mao, S., Wang, B., Zhou, A., et al.: Chimera: Improving generalist model with domain-specific experts. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3011–3022 (2025)
2025
-
[35]
In: Proceedings of the 18th ACM SIGKDD interna- tional conference on Knowledge discovery and data mining
Rakthanmanon, T., Campana, B., Mueen, A., Batista, G., Westover, B., Zhu, Q., Zakaria, J., Keogh, E.: Searching and mining trillions of time series subsequences under dynamic time warping. In: Proceedings of the 18th ACM SIGKDD interna- tional conference on Knowledge discovery and data mining. pp. 262–270 (2012)
2012
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Google AI1, 11 (2025)
Silver, D., Sutton, R.S.: Welcome to the era of experience. Google AI1, 11 (2025)
2025
-
[38]
arXiv preprint arXiv:2506.09684 (2025)
Song, H., Ji, R., Shi, N., Lai, F., Kontar, R.A.: Inv-entropy: A fully probabilis- tic framework for uncertainty quantification in language models. arXiv preprint arXiv:2506.09684 (2025)
-
[39]
In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Song, W., Zhao, H., Ding, P., Cui, C., Lyu, S., Fan, Y., Wang, D.: Germ: A generalist robotic model with mixture-of-experts for quadruped robot. In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 11879–11886. IEEE (2024)
2024
-
[40]
Interactive Post-Training for Vision-Language-Action Models
Tan, S., Dou, K., Zhao, Y., Krähenbühl, P.: Interactive post-training for vision- language-action models. arXiv preprint arXiv:2505.17016 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Octo: An Open-Source Generalist Robot Policy
Team, O.M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al.: Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Tent: Fully Test-time Adaptation by Entropy Minimization
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: Tent: Fully test-time adaptation by entropy minimization. arXiv preprint arXiv:2006.10726 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[43]
arXiv preprint arXiv:2512.02834 (2025)
Yang, S., Zhang, Y., He, H., Pan, L., Li, X., Bai, C., Li, X.: Steering vision- language-action models as anti-exploration: A test-time scaling approach. arXiv preprint arXiv:2512.02834 (2025)
-
[44]
Yuan, J., Zhang, B., Gong, K., Yue, X., Shi, B., Qiao, Y., Chen, T.: Reg-tta3d: Betterregressionmakesbettertest-timeadaptive3dobjectdetection.In:European conference on computer vision. pp. 197–213. Springer (2024)
2024
-
[45]
arXiv preprint arXiv:2510.06710 (2025)
Zang, H., Wei, M., Xu, S., Wu, Y., Guo, Z., Wang, Y., Lin, H., Shi, L., Xie, Y., Xu, Z., et al.: Rlinf-vla: A unified and efficient framework for vla+ rl training. arXiv preprint arXiv:2510.06710 (2025)
-
[46]
arXiv preprint arXiv:2505.07395 (2025)
Zhang, H., Zhuang, Z., Zhao, H., Ding, P., Lu, H., Wang, D.: Reinbot: Amplifying robot visual-language manipulation with reinforcement learning. arXiv preprint arXiv:2505.07395 (2025)
-
[47]
arXiv preprint arXiv:2411.19309 (2024)
Zhang, Z., Zheng, K., Chen, Z., Jang, J., Li, Y., Han, S., Wang, C., Ding, M., Fox, D., Yao, H.: Grape: Generalizing robot policy via preference alignment. arXiv preprint arXiv:2411.19309 (2024)
-
[48]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T.Z., Kumar, V., Levine, S., Finn, C.: Learning fine-grained bimanual ma- nipulation with low-cost hardware. arXiv preprint arXiv:2304.13705 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Open-Sora: Democratizing Efficient Video Production for All
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024) Trust Your Instincts: Confidence-Driven Test-Time RL for VLA Models 19
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
In: Conference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023)
2023
-
[51]
TTRL: Test-Time Reinforcement Learning
Zuo, Y., Zhang, K., Sheng, L., Qu, S., Cui, G., Zhu, X., Li, H., Zhang, Y., Long, X., Hua, E., et al.: Ttrl: Test-time reinforcement learning. arXiv preprint arXiv:2504.16084 (2025) 20 Chen et al. Appendix A Overview This appendix provides additional technical details and experimental results for T2VLA. The content is organized as follows: –Section B: Det...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
We additionally evaluate OpenVLA-OFT using action-conditioned observa- tions synthesized by an OpenSora world model [49]
In particular, the relationship remains visible on LIBERO-10 even when the initial success rate is only approximately17%, indicating that the confidence ordering is not limited to already strong policies. We additionally evaluate OpenVLA-OFT using action-conditioned observa- tions synthesized by an OpenSora world model [49]. As shown in Figure 6(b), highe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.