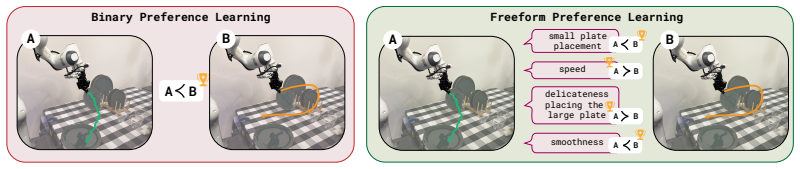
Freeform Preference Learning for Robotic Manipulation
Pith reviewed 2026-07-01 04:55 UTC · model grok-4.3
The pith
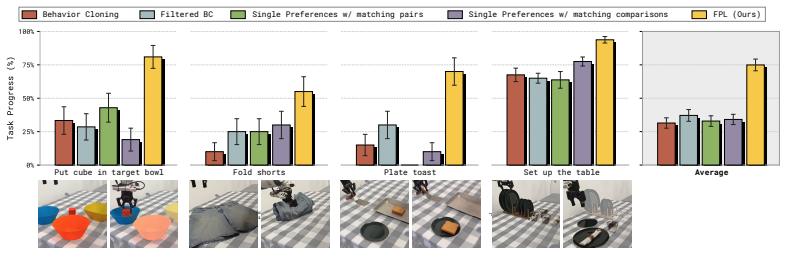
Freeform natural-language preferences on separate axes produce a language-conditioned reward model that improves long-horizon robotic manipulation by 38 percentage points over sparse and binary baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
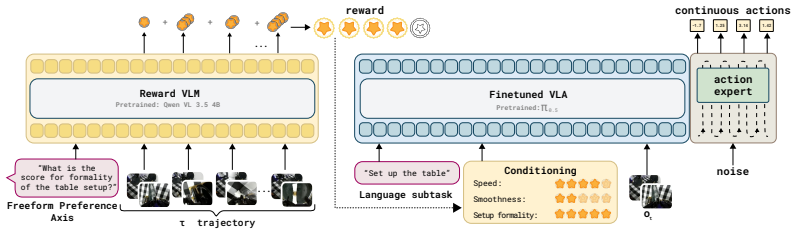
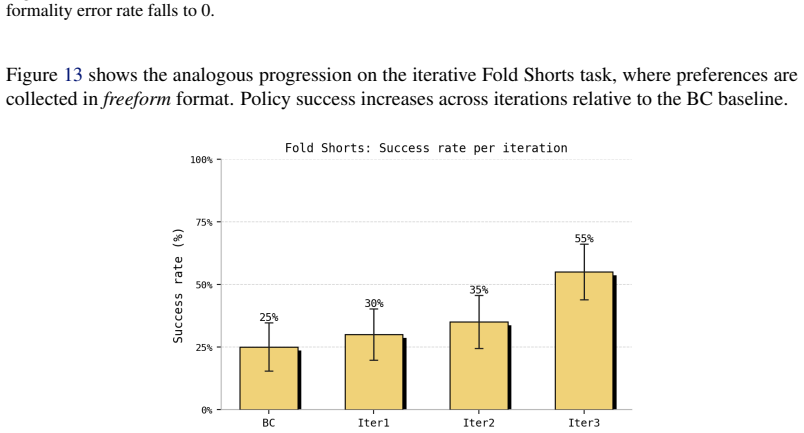
FPL collects pairwise preferences along multiple user-specified natural-language axes rather than single overall binary judgments, then trains a language-conditioned reward model that maps any trajectory together with an axis label to a scalar reward for that axis. A reward-conditioned policy is trained on this model and evaluated on four real-world and two simulated long-horizon manipulation tasks, where it outperforms sparse-reward and binary-preference baselines by 38 percentage points. The same model yields dense progress signals without manual subtask segmentation, produces behavior compositions not present in the collected data, and permits a user to steer the deployed policy toward di
What carries the argument
The language-conditioned reward model that receives a trajectory and a natural-language preference label and outputs the corresponding axis-specific reward value.
If this is right
- Policies trained with the multi-axis reward model achieve measurably higher success rates on long-horizon manipulation tasks than those trained with sparse or binary rewards.
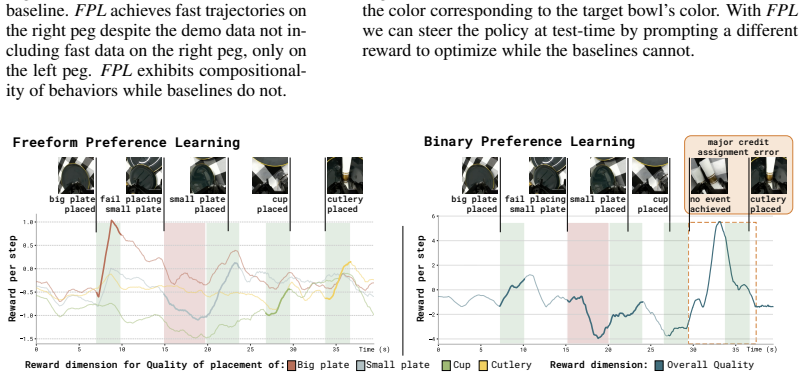
- Dense progress signals appear in the reward model without any explicit subtask segmentation in the data.
- The policy exhibits compositionality, producing behavior combinations absent from the training trajectories.
- At test time the same policy can be steered toward different behaviors by supplying new natural-language preference labels without retraining.
Where Pith is reading between the lines
- The axis-based annotation format may lower the cognitive load on human labelers compared with making holistic binary judgments.
- If the reward model generalizes across axes, the same trained model could support rapid adaptation to new tasks that share some of the same quality dimensions.
- The approach could be tested in other sequential decision domains where multiple independent quality criteria matter simultaneously.
Load-bearing premise
Pairwise preferences collected independently on separate natural-language axes can be combined into one coherent language-conditioned reward model that generalizes to unseen trajectories and supports compositionality.
What would settle it
An experiment in which the learned reward model produces inconsistent or non-generalizing scores when preference axes are recombined or when applied to new task trajectories would falsify the central claim.
Figures



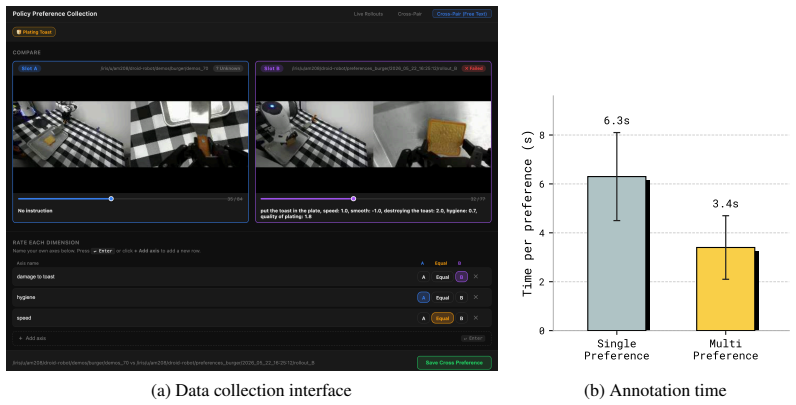
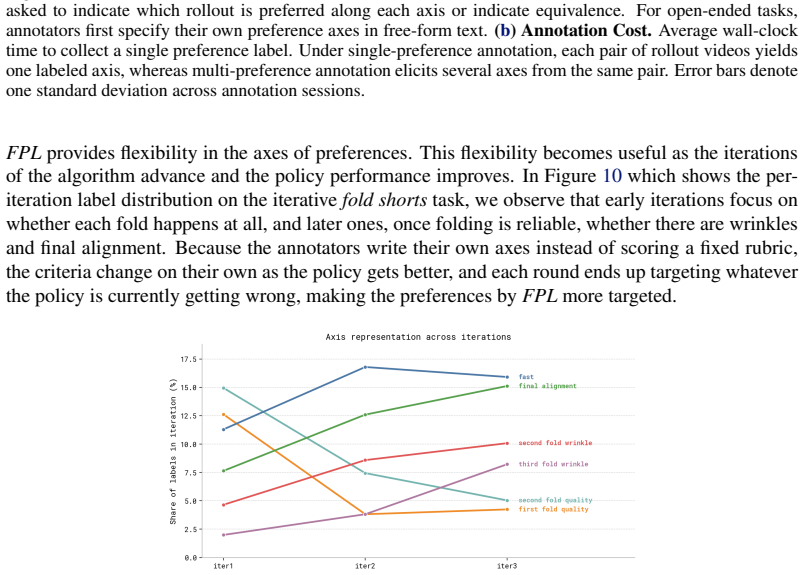
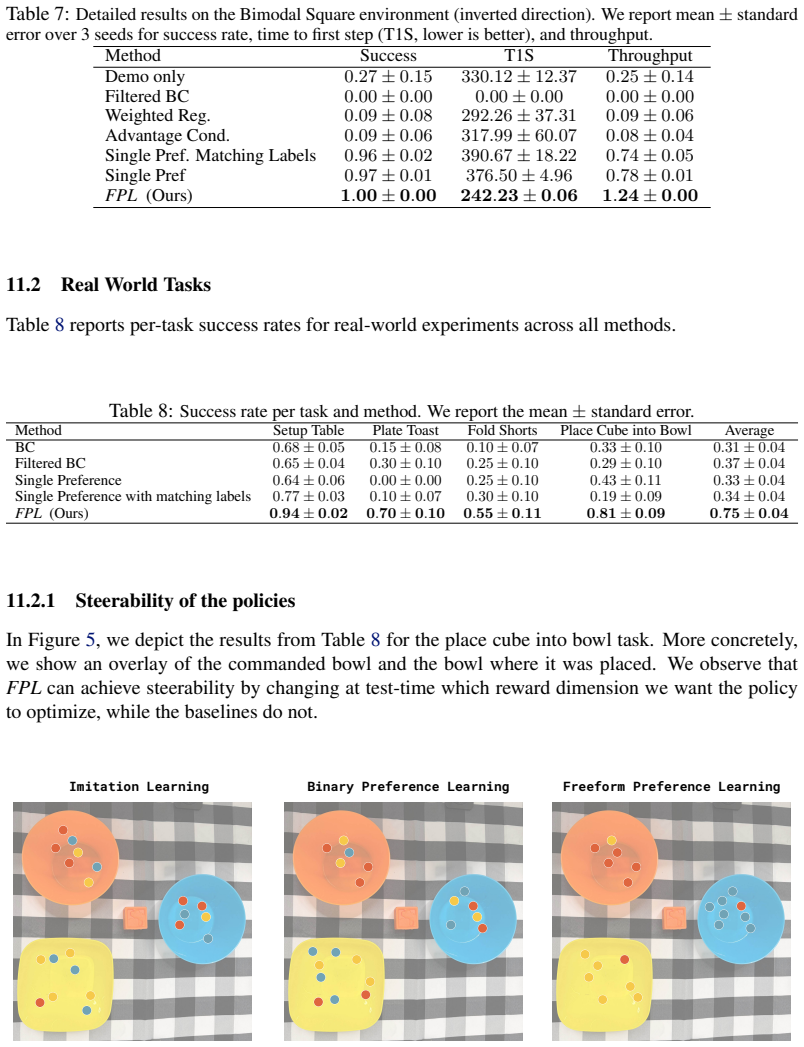
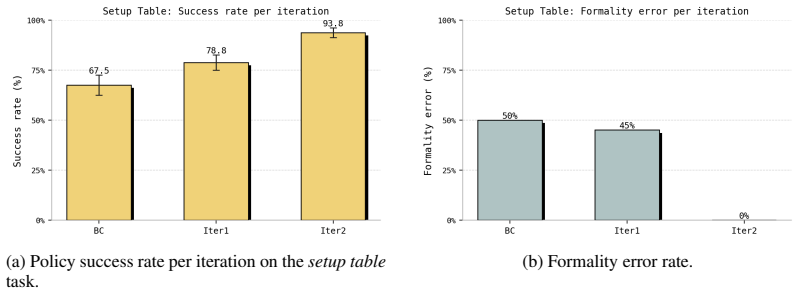

read the original abstract
Reward design remains a central bottleneck for autonomous robot policy improvement, especially in long-horizon manipulation tasks where sparse success labels provide too little signal and binary preferences collapse many competing notions of quality into one ambiguous signal. We introduce Freeform Preference Learning (FPL), a method for learning robot policies from freeform human preferences. Rather than asking annotators which of two trajectories is better overall, FPL lets them define natural-language preference axes, such as speed, safety, quality of placement, or carefulness, and provide pairwise preferences along each axis. These annotations are used to learn a language-conditioned reward model that maps a trajectory and preference label to an axis-specific reward. We use this model to train a reward-conditioned policy that optimizes across the multiple human-specified dimensions. Across four real-world and two simulated long-horizon manipulation tasks, FPL improves over sparse-reward and binary-preference methods by 38 percentage points. Beyond improved performance, FPL learns dense progress signals without explicit subtask segmentation, shows compositionality of behavior not present in the data, and allows users to steer the policy towards different behaviors at test time without retraining. Blog post with videos available at https://freeform-pl.github.io/fpl.website/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Freeform Preference Learning (FPL) for robotic manipulation. Annotators supply pairwise preferences along multiple natural-language axes (speed, safety, placement quality, carefulness) instead of binary overall judgments. These annotations train a language-conditioned reward model that maps a trajectory plus axis label to an axis-specific reward signal. A reward-conditioned policy is then trained to optimize across the human-specified dimensions. On four real-world and two simulated long-horizon manipulation tasks, FPL is reported to improve success rates by 38 percentage points over sparse-reward and binary-preference baselines. Additional claims include acquisition of dense progress signals without subtask labels, emergence of compositional behavior absent from the training data, and test-time steering of the policy toward different axis weightings without retraining.
Significance. If the performance gains and generalization properties are substantiated, the work would offer a practical route to richer preference signals in long-horizon robotics without dense reward engineering. The ability to collect axis-specific preferences and obtain a composable language-conditioned reward model could reduce ambiguity in human feedback and enable post-training behavioral steering. These features would be notable contributions provided the reward model demonstrably integrates independent axes into coherent, generalizing signals rather than axis-specific correlations.
major comments (2)
- [Experiments] Experiments section: The central performance claim of a 38 percentage point improvement is presented without reported statistical significance tests, exact baseline implementations, data-split details, or controls for potential confounds (e.g., total annotation budget, trajectory length distributions). This information is required to determine whether the gains are attributable to the freeform multi-axis mechanism rather than implementation differences.
- [Method, Experiments] Method and Experiments sections: The claim that the language-conditioned reward model supports compositionality for unseen axis combinations and trajectories rests on the assumption that independent per-axis preferences integrate into a single coherent signal. No quantitative evaluation on held-out axis combinations, reward-model accuracy on novel label pairings, or ablations isolating composition from downstream policy effects is provided; without such tests the generalization and steering claims cannot be verified.
minor comments (2)
- [Abstract] Abstract: The 38 percentage point figure should be accompanied by standard error or significance information to allow immediate assessment of the result.
- [Method] The manuscript should include a clear description of how multiple axis rewards are aggregated or conditioned during policy training (e.g., any weighting scheme or multi-objective formulation).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central performance claim of a 38 percentage point improvement is presented without reported statistical significance tests, exact baseline implementations, data-split details, or controls for potential confounds (e.g., total annotation budget, trajectory length distributions). This information is required to determine whether the gains are attributable to the freeform multi-axis mechanism rather than implementation differences.
Authors: We agree that these details are necessary to substantiate the performance claims. In the revised manuscript we will report statistical significance tests (including p-values and confidence intervals), provide precise descriptions and references for all baseline implementations, detail the data splits used, and include controls that equalize total annotation budget and trajectory length distributions across conditions. These additions will allow readers to attribute improvements specifically to the multi-axis preference collection mechanism. revision: yes
-
Referee: [Method, Experiments] Method and Experiments sections: The claim that the language-conditioned reward model supports compositionality for unseen axis combinations and trajectories rests on the assumption that independent per-axis preferences integrate into a single coherent signal. No quantitative evaluation on held-out axis combinations, reward-model accuracy on novel label pairings, or ablations isolating composition from downstream policy effects is provided; without such tests the generalization and steering claims cannot be verified.
Authors: We acknowledge that the current version presents compositionality and steering primarily through qualitative examples and policy behavior. To provide quantitative support, the revision will add evaluations on held-out axis combinations, reward-model accuracy metrics on novel label pairings, and ablations that isolate the contribution of the language-conditioned reward model from downstream policy training. These experiments will directly test whether independent per-axis signals integrate into coherent, generalizing rewards. revision: yes
Circularity Check
No significant circularity in the empirical method or claims.
full rationale
The paper presents FPL as an empirical learning procedure: axis-specific pairwise preferences are collected, a language-conditioned reward model is trained on them, and a policy is optimized against the resulting rewards. Performance is reported via direct comparison to external baselines (sparse-reward and binary-preference methods) on held-out tasks. No equations, derivations, or self-citations are described that reduce the reported gains or compositionality claims to quantities defined by the fitted parameters themselves. The central assumption about axis integration is an empirical hypothesis tested by the experiments rather than a definitional or self-referential step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human preferences along distinct natural-language axes are independent and can be modeled separately by a language-conditioned reward model.
Reference graph
Works this paper leans on
-
[1]
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine. Serl: A software suite for sample-efficient robotic reinforcement learning, 2024
2024
-
[2]
End-to-End Robotic Reinforcement Learning without Reward Engineering
A. Singh, L. Yang, K. Hartikainen, C. Finn, and S. Levine. End-to-end robotic reinforcement learning without reward engineering.arXiv preprint arXiv:1904.07854, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[3]
Kalashnikov, A
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhoucke, et al. Qt-opt: Scalable deep reinforcement learning for vision- based robotic manipulation. InCoRL, pages 651–673, 2018
2018
-
[4]
Robometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
A. Liang, Y . Korkmaz, J. Zhang, M. Hwang, A. Anwar, S. Kaushik, A. Shah, A. S. Huang, L. Zettlemoyer, D. Fox, et al. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [5]
- [6]
-
[7]
Deep reinforcement learning from human preferences
P. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences, 2017. URLhttps://arxiv.org/abs/1706.03741
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [8]
-
[9]
Sadigh, A
D. Sadigh, A. D. Dragan, S. S. Sastry, and S. A. Seshia. Active preference-based learn- ing of reward functions. InRobotics: Science and Systems, 2017. URLhttps://api. semanticscholar.org/CorpusID:12226563
2017
-
[10]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017. URLhttp://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welin- der, P. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback, 2022. 10
2022
-
[12]
Z. Wu, Y . Hu, W. Shi, N. Dziri, A. Suhr, P. Ammanabrolu, N. A. Smith, M. Ostendorf, and H. Hajishirzi. Fine-grained human feedback gives better rewards for language model training. Advances in Neural Information Processing Systems, 36:59008–59033, 2023
2023
-
[13]
K. Lee, L. Smith, and P. Abbeel. Pebble: Feedback-efficient interactive reinforcement learn- ing via relabeling experience and unsupervised pre-training. InInternational Conference on Machine Learning, 2021
2021
-
[14]
Torne, M
M. Torne, M. Balsells, Z. Wang, S. Desai, T. Chen, P. Agrawal, and A. Gupta. Breadcrumbs to the goal: goal-conditioned exploration from human-in-the-loop feedback. InAdvances in Neural Information Processing Systems, 2023
2023
-
[15]
Hwang, L
M. Hwang, L. Weihs, C. Park, K. Lee, A. Kembhavi, and K. Ehsani. Promptable behav- iors: Personalizing multi-objective rewards from human preferences. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16216–16226, 2024
2024
-
[16]
T. Chen, M. Tippur, S. Wu, V . Kumar, E. Adelson, and P. Agrawal. Visual dexterity: In- hand reorientation of novel and complex object shapes.Science Robotics, 8(84):eadc9244,
-
[17]
URLhttps://www.science.org/doi/abs/10
doi:10.1126/scirobotics.adc9244. URLhttps://www.science.org/doi/abs/10. 1126/scirobotics.adc9244
-
[18]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
2021
-
[19]
J. Schmidhuber. Reinforcement learning upside down: Don’t predict rewards–just map them to actions.arXiv preprint arXiv:1912.02875, 2019
- [20]
-
[21]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
P. Intelligence.π 0: A vision-language-action flow model for general robot control, 2024. URL https://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA. Gr00t n1: An open foundation model for generalist humanoid robots, 2025. URL https://arxiv.org/abs/2503.14734
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [25]
-
[26]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[27]
A. Ren, J. Lidard, L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. InInternational Conference on Learning Representations, volume 2025, pages 77288–77329, 2025. 11
2025
-
[28]
C. Xu, J. T. Springenberg, M. Equi, A. Amin, A. Esmail, S. Levine, and L. Ke. Rl token: Bootstrapping online rl with vision-language-action models.arXiv preprint arXiv:2604.23073, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Ankile, A
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal. From imitation to refinement- residual rl for precise assembly. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 01–08. IEEE, 2025
2025
- [30]
- [31]
-
[32]
A. Pan, W. Xu, L. Wang, and H. Ren. Additional planning with multiple objectives for rein- forcement learning.Know.-Based Syst., 193(C), Apr. 2020. ISSN 0950-7051. doi:10.1016/j. knosys.2019.105392. URLhttps://doi.org/10.1016/j.knosys.2019.105392
work page doi:10.1016/j 2020
-
[33]
K. V . Moffaert, M. M. Drugan, and A. Now ´e. Scalarized multi-objective reinforcement learning: Novel design techniques.2013 IEEE Symposium on Adaptive Dynamic Program- ming and Reinforcement Learning (ADPRL), pages 191–199, 2013. URLhttps://api. semanticscholar.org/CorpusID:15980735
2013
-
[34]
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[35]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[36]
K. Lee, L. M. Smith, and P. Abbeel. PEBBLE: feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre-training. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 ofProceedings of Machine Learning Research, ...
2021
-
[37]
M. Balsells, M. Torne, Z. Wang, S. Desai, P. Agrawal, and A. Gupta. Autonomous robotic reinforcement learning with asynchronous human feedback.arXiv preprint arXiv:2310.20608, 2023
-
[38]
Hejna, R
J. Hejna, R. Rafailov, H. Sikchi, C. Finn, S. Niekum, W. B. Knox, and D. Sadigh. Contrastive preference learning: Learning from human feedback without reinforcement learning. InInter- national Conference on Learning Representations, volume 2024, pages 18770–18798, 2024
2024
-
[39]
Hejna and D
J. Hejna and D. Sadigh. Inverse preference learning: Preference-based rl without a reward function.Advances in Neural Information Processing Systems, 36:18806–18827, 2023
2023
-
[40]
Biyik and D
E. Biyik and D. Sadigh. Batch active preference-based learning of reward functions. In 2nd Annual Conference on Robot Learning, CoRL 2018, Z ¨urich, Switzerland, 29-31 October 2018, Proceedings, volume 87 ofProceedings of Machine Learning Research, pages 519–528. PMLR, 2018. URLhttp://proceedings.mlr.press/v87/biyik18a.html
2018
-
[41]
A. Bobu, M. Wiggert, C. Tomlin, and A. D. Dragan. Inducing structure in reward learning by learning features.The International Journal of Robotics Research, 41(5):497–518, 2022. 12
2022
- [42]
-
[43]
Liang, J
Y . Liang, J. He, G. Li, P. Li, A. Klimovskiy, N. Carolan, J. Sun, J. Pont-Tuset, S. Young, F. Yang, et al. Rich human feedback for text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19401–19411, 2024
2024
- [44]
- [45]
-
[46]
A. Peng, A. Bobu, B. Z. Li, T. R. Sumers, I. Sucholutsky, N. Kumar, T. L. Griffiths, and J. A. Shah. Preference-conditioned language-guided abstraction. InProceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, pages 572–581, 2024
2024
-
[47]
D. Team. DROID: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems XX, Delft, The Netherlands, July 15-19, 2024, 2024. doi:10.15607/RSS.2024.XX
-
[48]
URLhttps://doi.org/10.15607/RSS.2024.XX.120
-
[49]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InarXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[50]
X. B. Peng, A. Kumar, G. Zhang, and S. Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[51]
Levine, C
S. Levine, C. Finn, T. Darrell, and P. Abbeel. End-to-end training of deep visuomotor policies. The Journal of Machine Learning Research, 17(1):1334–1373, 2016
2016
-
[52]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[53]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, K. Lin, A. Maddukuri, S. Nasiri- any, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learn- ing.arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[54]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence.π 0.5: a vision-language-action model with open-world generalization, 2025. URLhttps://arxiv.org/abs/2504.16054. 13 Appendix 7 Experimental details In this section, we will go over the details of the simulation 7.2 and real-world 7.1 experiments presented in the paper. 7.1 Real-World Tasks All four real-world tasks (see Fig. 7) use the DRO...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.