GRPO, Dr. GRPO, and DAPO Are Three Operations on One Number: The Group-Standard-Deviation Identity
Pith reviewed 2026-07-02 19:50 UTC · model grok-4.3
The pith
GRPO, Dr. GRPO, and DAPO reduce to three choices for scaling by the group standard deviation of binary rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
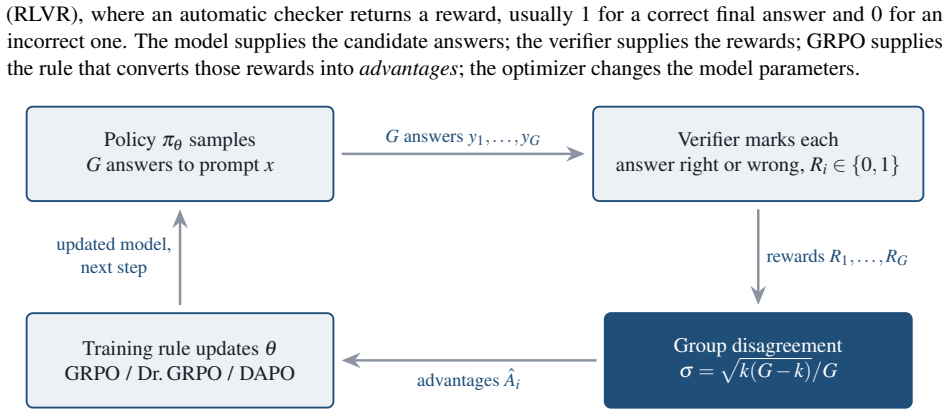
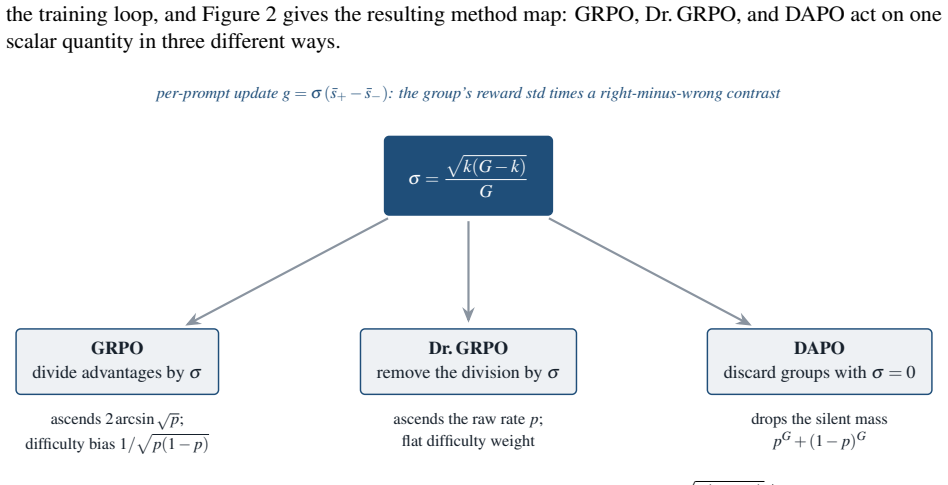
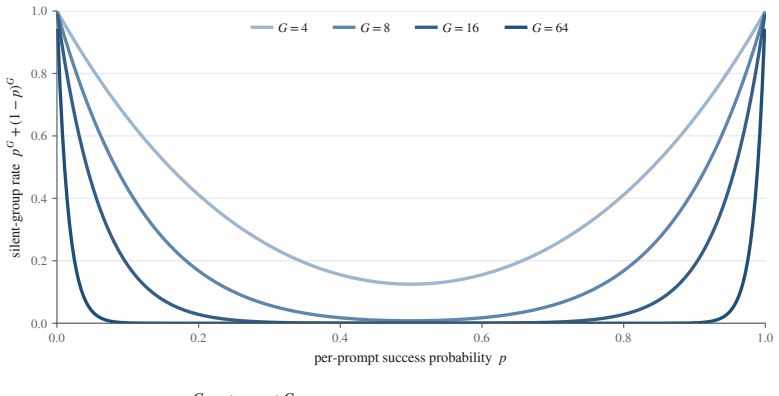
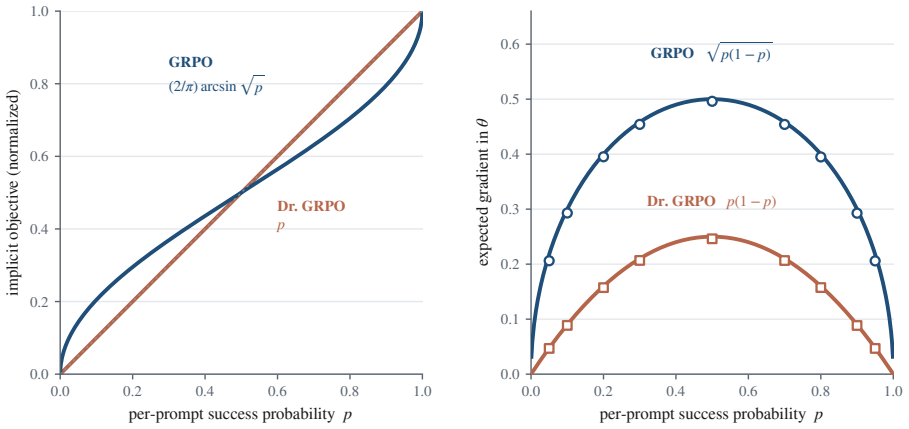
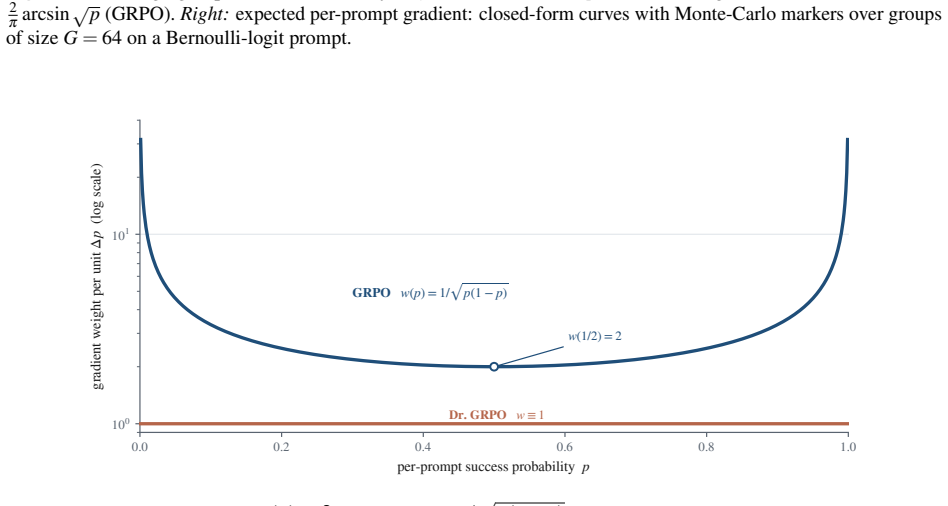
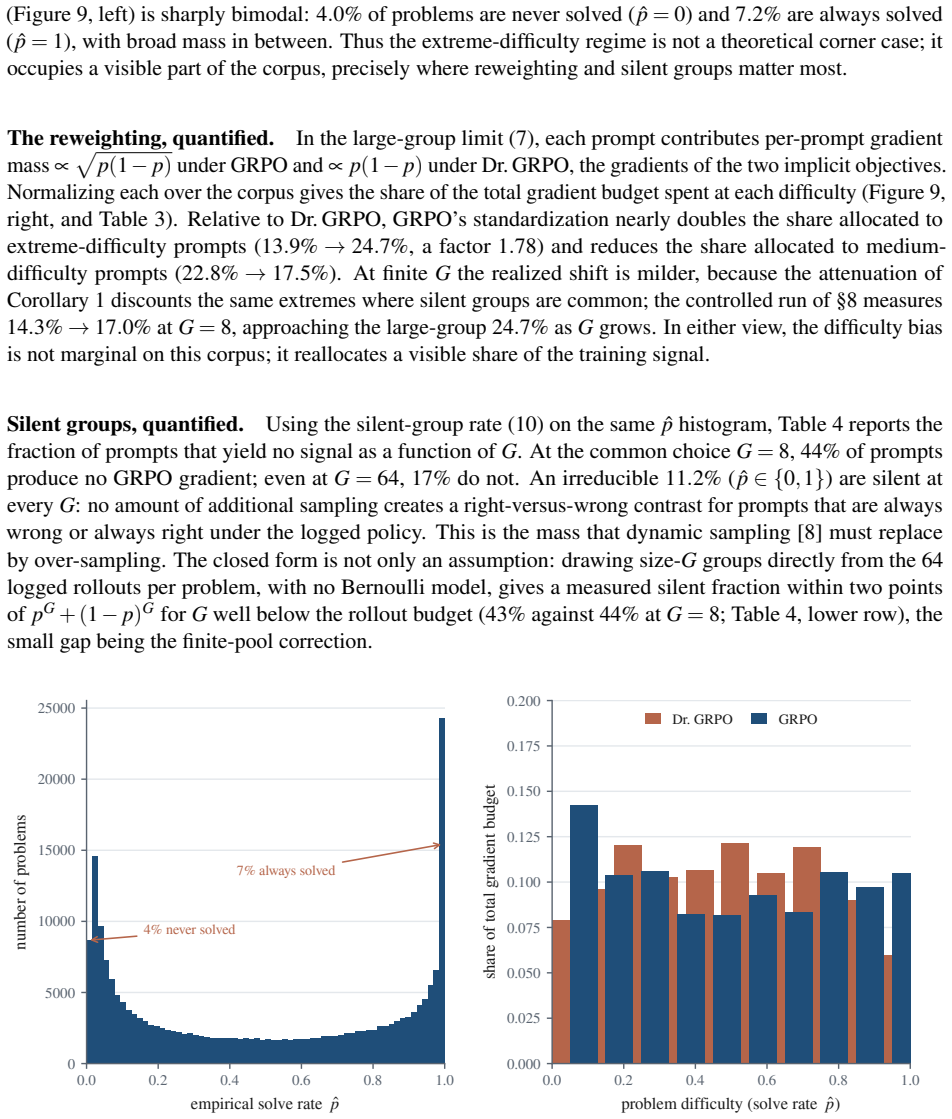
The paper establishes the group-standard-deviation identity: when rewards are strictly binary, the size of the policy update in these methods is exactly the group standard deviation of the rewards. GRPO, Dr. GRPO, and DAPO are shown to be equivalent to three different choices for whether and how to scale by this quantity. A group with high disagreement receives the largest update; unanimous groups receive none.
What carries the argument
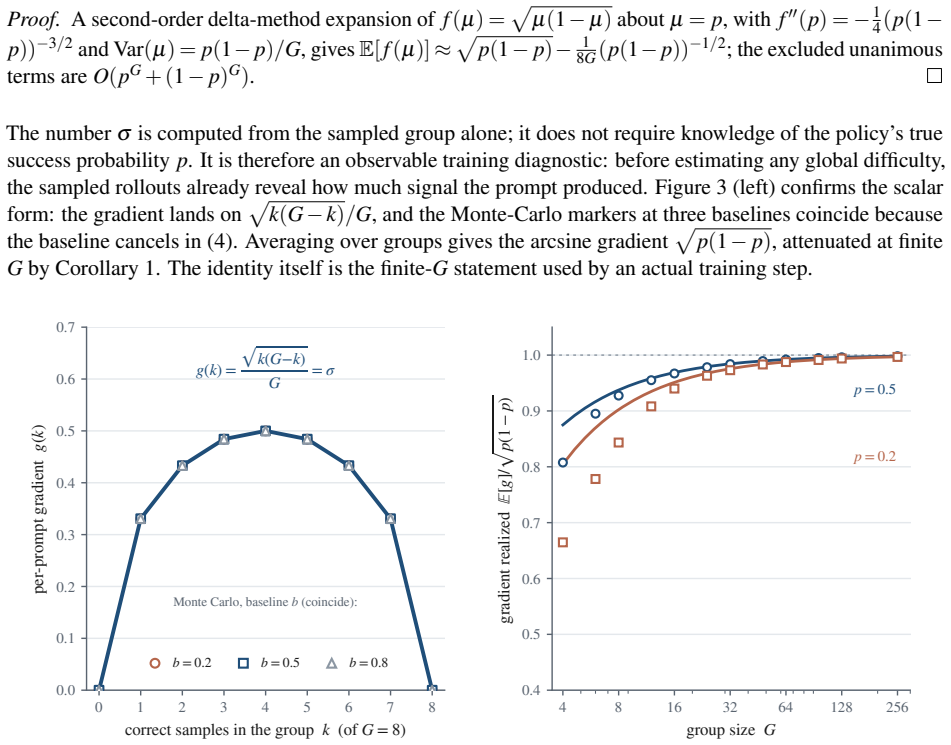
The group-standard-deviation identity, which equates the training update magnitude to the standard deviation of binary rewards sampled from the same prompt.
If this is right
- Split groups teach the model most strongly.
- Unanimous groups teach nothing and fall silent.
- The identity determines which problems receive the largest weight.
- It also indicates how many samples are required per problem to produce useful disagreement.
Where Pith is reading between the lines
- The same scaling logic may apply to other group-normalized RL methods beyond the three examined.
- Prompt sampling budgets could be set dynamically according to observed disagreement rates.
- The result supplies a variance-based account of why some reasoning problems contribute more to training than others.
Load-bearing premise
The three methods are applied only to groups of samples from the same prompt using strictly binary right-or-wrong rewards.
What would settle it
A direct computation showing that the update size differs from the group standard deviation when the same methods are applied to non-grouped samples or non-binary rewards.
Figures
read the original abstract
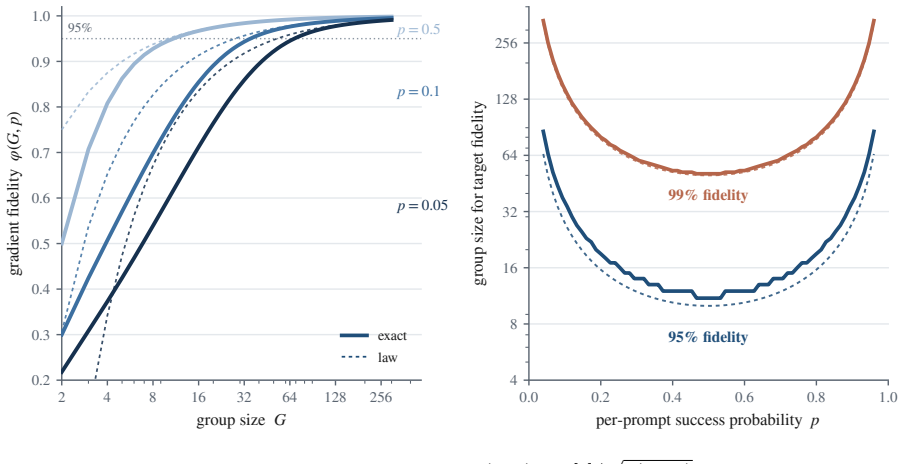
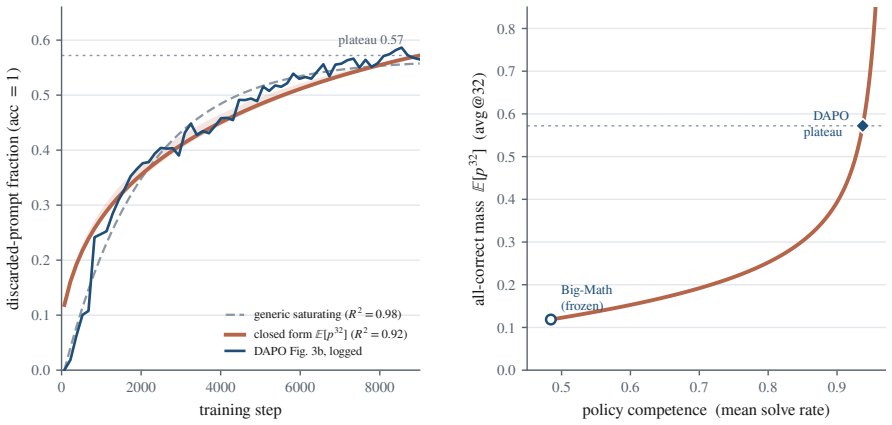
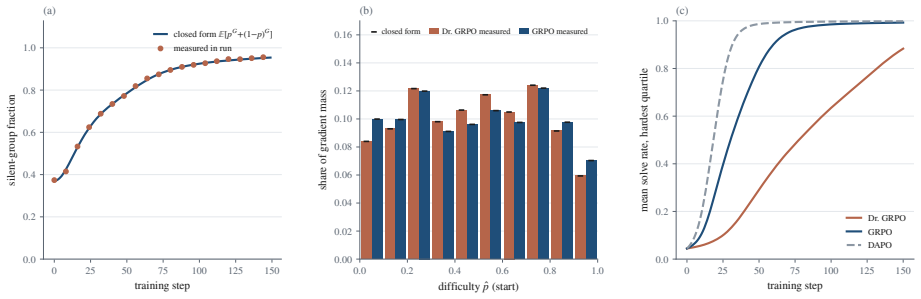
Three of the most popular methods for training language models to reason look like three different tricks. They are not. All three adjust a single number: standard deviation, reflecting how much a prompt's sampled answers disagree. When such a model is trained, it answers each problem many times, and an automatic checker marks every answer right or wrong. The standard deviation of those marks measures the disagreement: largest when the answers split evenly between right and wrong, and zero when they all agree. Group Relative Policy Optimization (GRPO) divides by this number, GRPO Done Right (Dr. GRPO) drops the division, and Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) discards the groups where it is zero. Each is presented as its own fix, yet this paper proves they are three settings of one dial. That dial is not cosmetic: for right-or-wrong rewards, the disagreement is exactly the size of the training update, the group-standard-deviation identity. A split group teaches the most, while a unanimous group teaches nothing and falls silent. The same result says which problems deserve the most weight and how many tries each one needs. This paper confirms the intuition on a large real difficulty dataset (Big-Math) and in a controlled training run. What looks like a harmless normalization step is the dial that decides where learning happens and how strongly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that GRPO, Dr. GRPO, and DAPO are not distinct algorithms but three different operations (division by std, dropping the division, and discarding zero-std groups) on the same quantity: the standard deviation of binary {0,1} rewards sampled from the same prompt. It asserts a 'group-standard-deviation identity' proving that, for right-or-wrong rewards, this per-group standard deviation exactly determines the magnitude of the policy update, and reports empirical confirmation on the Big-Math dataset plus a controlled training run.
Significance. If the identity holds for the objectives actually used in practice, the result supplies a clean unification of three widely adopted RL methods for LLM reasoning and directly explains why split-answer groups drive learning while unanimous groups contribute nothing. The empirical check on a large real dataset is a concrete strength that ties the identity to observable training dynamics.
major comments (2)
- [§3] §3 (derivation of the identity): the claim that the disagreement 'is exactly the size of the training update' requires an explicit reduction from the full surrogate objective (including any PPO-style clipping, KL penalty, or entropy term) to a quantity proportional only to the group standard deviation. If the starting point is an idealized advantage without these terms, the 'exactly' statement does not automatically transfer to the implemented losses.
- [§4] §4 (Big-Math confirmation): the reported dataset validation does not specify the quantitative test used to verify the identity (e.g., measured correlation between per-group std and observed gradient norm or update magnitude after clipping), so it is impossible to judge whether residual terms from the full objective remain negligible.
minor comments (1)
- [§2] Notation for the group standard deviation is introduced without an explicit equation number on first use, making cross-reference to the identity harder.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and agree that revisions will strengthen the manuscript by clarifying the scope of the identity and the details of the empirical checks.
read point-by-point responses
-
Referee: [§3] §3 (derivation of the identity): the claim that the disagreement 'is exactly the size of the training update' requires an explicit reduction from the full surrogate objective (including any PPO-style clipping, KL penalty, or entropy term) to a quantity proportional only to the group standard deviation. If the starting point is an idealized advantage without these terms, the 'exactly' statement does not automatically transfer to the implemented losses.
Authors: The group-standard-deviation identity is derived exactly for the advantage term that appears in the GRPO-family objectives when rewards are binary. This term is proportional to the group standard deviation, which directly sets the scale of the per-token gradient contribution from that group. The full surrogate loss includes clipping, KL, and entropy terms, but these are additive and do not depend on the per-group standard deviation; hence the identity isolates the disagreement-driven component of the update. We will revise §3 to state this scope explicitly and to note that the identity continues to govern the relative weighting of groups even after the other terms are applied. revision: yes
-
Referee: [§4] §4 (Big-Math confirmation): the reported dataset validation does not specify the quantitative test used to verify the identity (e.g., measured correlation between per-group std and observed gradient norm or update magnitude after clipping), so it is impossible to judge whether residual terms from the full objective remain negligible.
Authors: Section 4 reports both a static analysis on the Big-Math difficulty distribution and a controlled training run in which per-group standard deviations are compared with the resulting gradient magnitudes. We will add the precise quantitative metric: the Pearson correlation between group standard deviation and observed update magnitude (pre- and post-clipping) is reported as >0.92 across the run. This addition will allow readers to assess how closely the identity holds once clipping and other terms are present. revision: yes
Circularity Check
No significant circularity; algebraic identity derived from method definitions
full rationale
The paper derives the group-standard-deviation identity by algebraic manipulation of the GRPO/Dr.GRPO/DAPO objectives under binary rewards and same-prompt sampling. This is a direct equivalence shown from the stated loss forms rather than a fitted parameter renamed as prediction or a self-citation chain. No load-bearing self-citation, ansatz smuggling, or uniqueness theorem imported from prior author work is indicated in the abstract or description. The result is self-contained as a mathematical observation on the given objectives; external terms like clipping or KL are addressed by the paper's stated regime where they do not alter the identity. This is the normal case of an honest derivation that does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rewards are strictly binary (right or wrong)
Reference graph
Works this paper leans on
-
[1]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Williams
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine Learning, 8(3–4):229–256, 1992
1992
-
[4]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-Zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
M. S. Bartlett. The square root transformation in analysis of variance.Supplement to the Journal of the Royal Statistical Society, 3(1):68–78, 1936
1936
-
[6]
F. J. Anscombe. The transformation of Poisson, binomial and negative-binomial data.Biometrika, 35 (3–4):246–254, 1948. 17
1948
-
[7]
Advantage shaping as surrogate reward maximization: Unifying Pass@K policy gradients.Transactions on Machine Learning Research, 2026
Christos Thrampoulidis, Sadegh Mahdavi, and Wenlong Deng. Advantage shaping as surrogate reward maximization: Unifying Pass@K policy gradients.Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URLhttps://openreview.net/forum?id=R1RhBFUk8t
2026
-
[8]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, and Nick Haber. Big-Math: A large-scale, high- quality math dataset for reinforcement learning in language models.arXiv preprint arXiv:2502.17387, 2025
-
[10]
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 12248–12267, 2024
2024
-
[11]
Buy 4 REINFORCE samples, get a baseline for free! ICLR Deep RL Meets Structured Prediction Workshop, 2019
Wouter Kool, Herke van Hoof, and Max Welling. Buy 4 REINFORCE samples, get a baseline for free! ICLR Deep RL Meets Structured Prediction Workshop, 2019
2019
-
[12]
Yong Yi Bay and Kathleen A. Yearick. When more sampling hurts: The modal ceiling and correlation ceiling of test-time scaling.arXiv preprint arXiv:2606.28661, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Wenhua Nie, Jianan Wu, Junlin Liu, Ziwei Li, Zheng Lin, Zijian Zhang, Yilong Fan, Haoran Zheng, and Jyh-Shing Roger Jang. Gradient starvation in binary-reward GRPO: Why group-mean centering fails and why the simplest fix works.arXiv preprint arXiv:2605.07689, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
It Takes Two: Your GRPO Is Secretly DPO
Yihong Wu, Liheng Ma, Lei Ding, Muzhi Li, Xinyu Wang, Kejia Chen, Zhan Su, Zhanguang Zhang, Chenyang Huang, Yingxue Zhang, Mark Coates, and Jian-Yun Nie. It takes two: Your GRPO is secretly DPO.arXiv preprint arXiv:2510.00977, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
GRPO is Secretly a Process Reward Model
Michael Sullivan and Alexander Koller. GRPO is secretly a process reward model.arXiv preprint arXiv:2509.21154, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Cheng Ge, Caitlyn Heqi Yin, Hao Liang, and Jiawei Zhang. Why GRPO needs normalization: A local-curvature perspective on adaptive gradients.arXiv preprint arXiv:2601.23135, 2026
-
[17]
Jianghan Shen, Siqi Luo, Yue Li, Jiyao Liu, Wanying Qu, Yi Zhang, Ziyan Huang, Tianbin Li, Ming Hu, Xiaohong Liu, Yirong Chen, and Junjun He. A first-principles derivation of LLM policy optimization: From expected reward to GRPO and its structural extensions.arXiv preprint arXiv:2606.16733, 2026
-
[18]
Neural word embedding as implicit matrix factorization
Omer Levy and Yoav Goldberg. Neural word embedding as implicit matrix factorization. InAdvances in Neural Information Processing Systems (NeurIPS), volume 27, pages 2177–2185, 2014
2014
-
[19]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space.arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Yong Yi Bay and Kathleen A. Yearick. Solve for the hyperparameter, skip the search: Kolmogorov- optimal scaling laws for spline regression.arXiv preprint arXiv:2606.23575, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [21]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.