REVIEW 3 major objections 1 minor 21 references
Reviewed by Pith at T0; open to challenge.
T0 means a machine referee read the full paper against a public rubric. The mark states how deep the mechanical check went, never who wrote it. the ladder, T0–T4 →
T0 review · grok-4.3
Large language models fail to sustain deception or strategic impact when playing fascists in Secret Hitler.
2026-05-25 00:34 UTC pith:C4LUW4KO
load-bearing objection New metrics and framework for Secret Hitler give a testbed for LLM deception, but the results probably track state-tracking collapse more than sustained manipulation skill. the 3 major comments →
Evaluating Large Language Models in a Complex Hidden Role Game
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
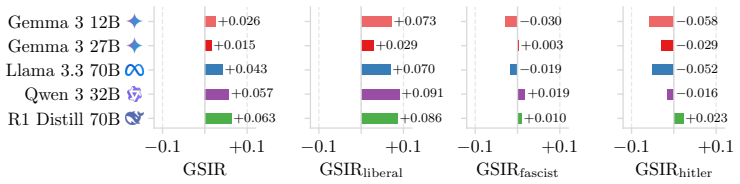
Benchmarking reveals a clear gap between conversational fluency and strategic depth: rule-based agents match expert human voting decisions 86.7 percent of the time while Llama 3.1 70B reaches only 59.7 percent accuracy. Models assigned fascist roles consistently generate negative Game State Impact Rates, fail to retain deception, and produce games about 40 percent shorter than human games. Neither chain-of-thought prompting nor internal memory improves outcomes and can degrade fascist win rates by as much as 23.2 percent.
What carries the argument
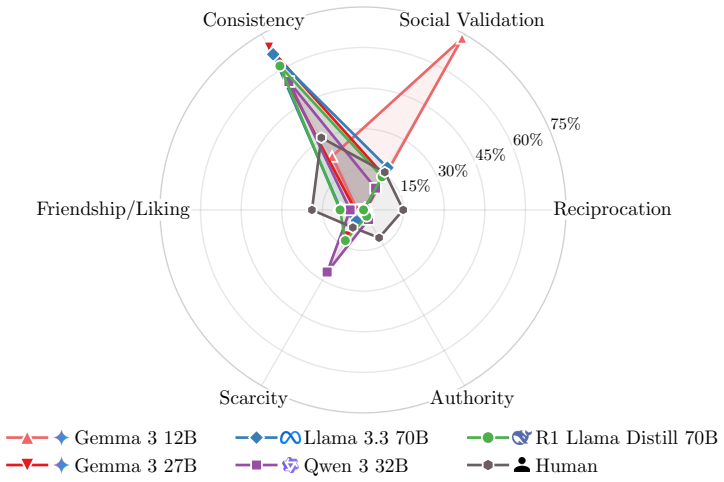
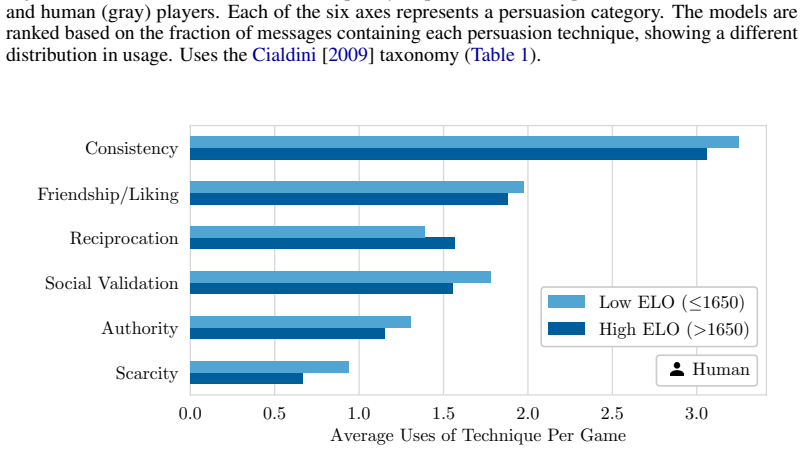
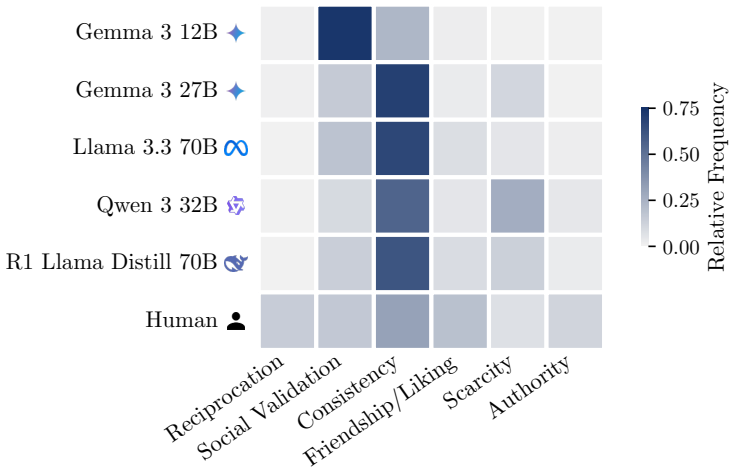
The Secret Hitler game environment together with the three custom metrics (Role Identification Accuracy, Deception Retention Rate, Game State Impact Rate) that track how well agents identify roles, maintain lies, and alter overall game trajectories.
Load-bearing premise
The rules and scoring of Secret Hitler serve as a faithful stand-in for general deceptive capability rather than merely testing surface fluency or prompt sensitivity.
What would settle it
Repeated trials in which an LLM achieves fascist win rates, deception retention, and game lengths statistically indistinguishable from or superior to human players would falsify the ineffectiveness claim.
If this is right
- Current LLM architectures remain ineffective at complex multi-turn manipulation.
- Rule-based agents align with human expert decisions more closely than any tested model.
- Common reasoning enhancements produce no benefit and can actively harm performance in deception tasks.
- The released framework supplies a standardized, reproducible environment for measuring future progress in deceptive capability.
- Detecting the point at which models master these behaviors will matter for alignment monitoring.
Where Pith is reading between the lines
- The same metrics could be ported to other hidden-role games to test whether the observed gap generalizes beyond Secret Hitler.
- The performance drop when models are given chain-of-thought or memory hints at limits in long-horizon consistency rather than simple knowledge retrieval.
- If models later close the gap on these metrics, the framework would provide an early-warning signal for real-world manipulation risks.
- Human players may already be using cues that current models do not yet replicate to detect and counter model deception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an open-source framework for evaluating LLMs in the social deduction game Secret Hitler and defines three new metrics (Role Identification Accuracy, Deception Retention Rate, Game State Impact Rate) to quantify reasoning, persuasion, and deception. It benchmarks multiple LLMs against rule-based agents and human games, reports that LLMs achieve only 59.7% voting alignment (vs. 86.7% for rule-based), produce negative fascist impact scores, yield ~40% shorter games, and show no gains (or up to 23.2% worse win rates) from Chain-of-Thought or internal memory, concluding that current architectures remain ineffective at complex multi-turn manipulation.
Significance. If the metrics are shown to isolate deception from state-tracking, the work supplies a reproducible testbed and concrete empirical baselines that could support future alignment research on multi-agent deception. The open-source framework and direct comparison to rule-based and human performance are strengths.
major comments (3)
- [Metrics definitions and results (abstract and §4)] The central claim that models are ineffective at sustaining multi-turn deception rests on Deception Retention Rate and Game State Impact Rate serving as valid proxies. These metrics are computed inside a partially observed game whose state must be maintained by the LLM across turns; without an ablation that supplies ground-truth state mid-game (or tests deception in an otherwise identical fully-observed setting), low scores are consistent with known state-tracking collapse rather than inability to generate persuasive language given perfect information.
- [Abstract and experimental results] The reported 59.7% voting alignment for Llama 3.1 70B versus 86.7% for rule-based agents, the 23.2% worse win rates under reasoning enhancements, and the 40% shorter games are presented without sample sizes, error bars, number of games per condition, or statistical tests, making it impossible to determine whether the performance gap is robust or sensitive to post-hoc prompt or game-rule choices.
- [Reasoning-enhancement experiments] The claim that neither Chain-of-Thought nor internal memory improves performance is load-bearing for the broader conclusion about current architectures, yet the paper supplies no description of how these techniques were implemented, how many trials were run, or whether the 23.2% degradation is measured on the same metric suite or on win rate alone.
minor comments (1)
- [Metric definitions] Clarify the exact formulas for Role Identification Accuracy, Deception Retention Rate, and Game State Impact Rate, including how votes, actions, and game logs are mapped to each score.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, with revisions planned where the concerns identify gaps in the current manuscript.
read point-by-point responses
-
Referee: [Metrics definitions and results (abstract and §4)] The central claim that models are ineffective at sustaining multi-turn deception rests on Deception Retention Rate and Game State Impact Rate serving as valid proxies. These metrics are computed inside a partially observed game whose state must be maintained by the LLM across turns; without an ablation that supplies ground-truth state mid-game (or tests deception in an otherwise identical fully-observed setting), low scores are consistent with known state-tracking collapse rather than inability to generate persuasive language given perfect information.
Authors: The metrics are defined and computed within the standard partially-observed rules of Secret Hitler precisely because the task requires both state tracking and deception; isolating one from the other would change the evaluation target. We agree, however, that the current text does not sufficiently discuss this potential confound. We will add an explicit limitations paragraph noting that low scores may partly reflect state-tracking failures and outlining future ablations that supply ground-truth state. revision: yes
-
Referee: [Abstract and experimental results] The reported 59.7% voting alignment for Llama 3.1 70B versus 86.7% for rule-based agents, the 23.2% worse win rates under reasoning enhancements, and the 40% shorter games are presented without sample sizes, error bars, number of games per condition, or statistical tests, making it impossible to determine whether the performance gap is robust or sensitive to post-hoc prompt or game-rule choices.
Authors: The experimental section of the manuscript states the total number of games run per model and condition, but we acknowledge that error bars, per-condition sample sizes, and statistical tests are not reported. In the revision we will add these details together with the results of appropriate significance tests. revision: yes
-
Referee: [Reasoning-enhancement experiments] The claim that neither Chain-of-Thought nor internal memory improves performance is load-bearing for the broader conclusion about current architectures, yet the paper supplies no description of how these techniques were implemented, how many trials were run, or whether the 23.2% degradation is measured on the same metric suite or on win rate alone.
Authors: We will expand the methods subsection on reasoning enhancements to describe the exact prompting templates used for Chain-of-Thought, the memory mechanism, the number of trials per condition, and to state explicitly that the 23.2 % figure is the change in fascist win rate. revision: yes
Circularity Check
No circularity: empirical benchmarking with external baselines
full rationale
The paper introduces a game framework and three metrics (Role Identification Accuracy, Deception Retention Rate, Game State Impact Rate) then reports empirical results by running LLMs, rule-based agents, and referencing human games. No equations, fitted parameters, self-citations, or derivations are present in the provided text. Claims rest on direct comparison to independent external baselines rather than any reduction of outputs to inputs by construction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
read the original abstract
Quantifying the deceptive potential of Large Language Models (LLMs) is critical for AI safety, yet difficult to achieve in uncontrolled environments. This work investigates the reasoning, persuasion, and deceptive capabilities of LLMs within the social deduction game Secret Hitler. I introduce an open-source framework and novel metrics to measure performance: Role Identification Accuracy, Deception Retention Rate, and Game State Impact Rate. By benchmarking models against rule-based algorithms and human games, I identify a gap between conversational ability and strategic depth. The study also analyzes the impact of reasoning-enhancement techniques on win rates and strategic reasoning. Neither Chain-of-Thought prompting nor internal memory bring improvements in performance, with up to 23.2% worse win rates for fascist roles. While rule-based agents align with expert human voting decisions 86.7% of the time, models like Llama 3.1 70B achieve only a 59.7% accuracy. Models playing as Fascists consistently yield negative impact scores and fail to sustain deception, resulting in roughly 40% shorter games compared to humans. These findings suggest that current architectures remain ineffective at complex, multi-turn manipulation. As capabilities advance, detecting when models begin to master these deceptive behaviors is crucial. The developed framework serves as a reproducible testbed for future alignment research.
Figures













Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the new Deception Retention Rate (DRR), which quantifies how effectively an agent conceals its hidden identity... Game State Impact Rate (GSIR)... Role Identification Accuracy (RIA)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Models playing as Fascists consistently yield negative impact scores and fail to sustain deception, resulting in roughly 40% shorter games
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sijing Chen, Lu Xiao, and Jin Mao
URLhttps://arxiv.org/abs/2404.18231. Sijing Chen, Lu Xiao, and Jin Mao. Persuasion strategies of misinformation-containing posts in the social media. 58(5):102665, 2021. ISSN 0306-4573. doi: 10.1016/j.ipm.2021.102665. URL https://www.sciencedirect.com/science/article/pii/S0306457321001539. Yuheng Cheng, Ceyao Zhang, Zhengwen Zhang, Xiangrui Meng, Sirui Ho...
-
[2]
URLhttps://arxiv.org/abs/2505.12923. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi De...
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Caleb DeLeeuw, Gaurav Chawla, Aniket Sharma, and Vanessa Dietze. The secret agenda: LLMs strategically lie and our current safety tools are blind, 2025. URL https://arxiv.org/abs/ 2509.20393. Silin Du and Xiaowei Zhang. Helmsman of the masses? evaluate the opinion leadership of large language models in the werewolf gam...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
doi: 10.18653/v1/2024.naacl-long.123
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.123. URL https://aclanthology.org/2024.naacl-long.123/. Niv Eckhaus, Uri Berger, and Gabriel Stanovsky. Time to talk: LLM agents for asynchronous group communication in mafia games. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings...
-
[5]
URLhttps://arxiv.org/abs/2503.19786. Satvik Golechha and Adrià Garriga-Alonso. Among us: A sandbox for measuring and detecting agentic deception, 2025. URLhttps://arxiv.org/abs/2504.04072. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
ISBN 978-1-108-83555-8. URL https://www.cambridge.org/core/books/social- media-and-democracy/misinformation-disinformation-and-online-propaganda/ D14406A631AA181839ED896916598500. Jiaxian Guo, Bo Yang, Paul Yoo, Bill Yuchen Lin, Yusuke Iwasawa, and Yutaka Matsuo. Suspicion- agent: Playing imperfect information games with theory of mind aware GPT-4, 2023. ...
-
[7]
ISSN 2577-8439. doi: 10.63562/2577-8439.1111. URL https://orb.binghamton.edu/ nejcs/vol7/iss2/5. Sihao Hu, Tiansheng Huang, Gaowen Liu, Ramana Rao Kompella, Fatih Ilhan, Selim Furkan Tekin, Yichang Xu, Zachary Yahn, and Ling Liu. A survey on large language model-based game agents,
-
[8]
URLhttps://arxiv.org/abs/2404.02039. 37 Wenyue Hua, Lizhou Fan, Lingyao Li, Kai Mei, Jianchao Ji, Yingqiang Ge, Libby Hemphill, and Yongfeng Zhang. War and peace (WarAgent): Large language model-based multi-agent simulation of world wars, 2023. URLhttps://arxiv.org/abs/2311.17227. Wenyue Hua, Ollie Liu, Lingyao Li, Alfonso Amayuelas, Julie Chen, Lucas Jia...
-
[9]
Evaluating large language models in theory of mind tasks.arXiv preprint arXiv:2302.02083,
ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.2405460121. URL https://pnas.org/ doi/10.1073/pnas.2405460121. 38 Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th ...
-
[10]
doi: 10.18653/v1/2024.emnlp-main.383
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.383. URL https://aclanthology.org/2024.emnlp-main.383/. Aengus Lynch, Benjamin Wright, and Caleb Larson. Agentic misalignment: How LLMs could be insider threats. 2025. URL https://www.anthropic.com/research/agentic- misalignment. Ji Ma. Computational basis of LLM’s decision making...
-
[11]
Bayesian Social Deduction with Graph-Informed Language Models
URLhttps://arxiv.org/abs/2506.17788. Jack Reinhardt. Competing in a complex hidden role game with information set monte carlo tree search, 2020. URLhttps://arxiv.org/abs/2005.07156. Alexander Rogiers, Sander Noels, Maarten Buyl, and Tijl De Bie. Persuasion with large language models: a survey, 2024. URLhttps://arxiv.org/abs/2411.06837. 41 Bidipta Sarkar, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/access.2024.3406644 2020
-
[12]
doi: 10.18653/v1/2024.aiwolfdial-1.6
Association for Computational Linguistics. doi: 10.18653/v1/2024.aiwolfdial-1.6. URL https://aclanthology.org/2024.aiwolfdial-1.6/. Samuel M. Taylor and Benjamin K. Bergen. Do large language models exhibit spontaneous rational deception?, 2025. URLhttps://arxiv.org/abs/2504.00285. Fujio Toriumi, Hirotaka Osawa, Michimasa Inaba, Daisuke Katagami, Kosuke Sh...
-
[13]
URLhttps://arxiv.org/abs/2410.10479. Shenzhi Wang, Chang Liu, Zilong Zheng, Siyuan Qi, Shuo Chen, Qisen Yang, Andrew Zhao, Chaofei Wang, Shiji Song, and Gao Huang. Avalon’s game of thoughts: Battle against deception through recursive contemplation, 2023. URLhttps://arxiv.org/abs/2310.01320. Tianhe Wang and Tomoyuki Kaneko. Application of deep reinforcemen...
-
[14]
arXiv preprint arXiv:2309.04658 , year=
URLhttps://arxiv.org/abs/2309.04658. Zelai Xu, Chao Yu, Fei Fang, Yu Wang, and Yi Wu. Language agents with reinforcement learning for strategic play in the werewolf game. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024b. URLhttps: //openreview.net/forum?id=usUPvQH3XK. Zelai Xu,...
-
[15]
URLhttps://openreview.net/pdf?id=WE_vluYUL-X
OpenReview.net, 2023. URLhttps://openreview.net/pdf?id=WE_vluYUL-X. Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, and Weiyan Shi. How johnny can persuade LLMs to jailbreak them: Rethinking persuasion to challenge AI safety by humanizing LLMs. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of ...
-
[16]
Early Game ( -0.229):In an opening situation at round 1 with 0L–0F policies enacted, a starting deck composition of 6L–11F cards, a liberal president, no unlocked powers, and no role information available, the deck’s fascist bias creates a slightly unfavorable position for liberals despite the balanced policy track
-
[17]
Mid-Game Crisis (-0.457):A representative mid-game state at round 7 features 1L–3F policies enacted, a fascist president holding execution power, and liberals correctly identifying the fascist president. Despite accurate role identification by liberals, the combination of policy disadvantage, poor deck composition, and dangerous executive power in fascist...
-
[18]
Balanced Mid-Game (+0.037):Another mid-game configuration at round 6 contains 2L–2F policies enacted, a liberal president without powers, and liberals correctly identifying the fascist player. The policy track appears balanced, but the heavily fascist-biased deck composition counteracts the liberal president advantage, resulting in a nearly neutral score ...
-
[19]
Hitler Danger (-0.326):A different example at round 8 with 1L–3F policies enacted, a liberal president holding investigate power, and liberals misidentifying Hitler as liberal after three fascist policies illustrates the impact of misinformation. This misidentification creates substantial election risk, overwhelming the liberal president’s investigative a...
-
[20]
Late Game Liberal Advantage (+0.531):A late-game scenario at round 10 shows liberals with 4L–2F policies enacted (one away from victory). With a liberal president, no unlocked powers, and liberals correctly identifying both Hitler and the fascist player, the strong policy advantage and excellent role information outweigh the poor deck state, yielding a mo...
-
[21]
Dire Situation (-0.579):In a high-pressure late-game position at round 12, 1L–5F policies have been enacted (fascists one away from victory), a fascist president wielding execution power, and some role identification by liberals. The imminent fascist policy victory combined with executive control in fascist hands produces a strongly fascist-favored score,...
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.