Darwin Mobile Agent: A Roadmap for Self-Evolution
Pith reviewed 2026-06-29 16:42 UTC · model grok-4.3
The pith
The most effective path to general adaptive agents is to remove human priors and let intelligence emerge from interaction with complex mobile GUI environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Darwin Mobile Agent supplies both the cloud-phone infrastructure and the conceptual roadmap needed to move from supervised mobile control toward fully autonomous reinforcement learning, by treating the mobile GUI as a Big World proxy and by outlining the staged removal of human priors from task curricula, outcome verification, and memory management.
What carries the argument
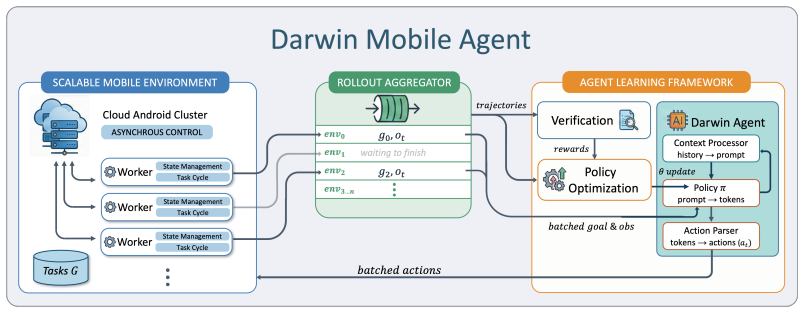
The asynchronous agent-environment loop running across many parallel cloud-phone instances, which removes the data-collection bottleneck and supports stable policy optimization as the initial stage of self-evolution.
If this is right
- Policy optimization becomes feasible at scale inside real mobile interfaces without manual task engineering.
- Agents can progress through successive stages that eliminate human input from curricula, verification, and memory.
- The same parallel-cloud setup can support the later stages of the roadmap once the first stage succeeds.
- The resulting agents would exhibit adaptive behavior across previously unseen mobile applications.
Where Pith is reading between the lines
- The same removal-of-priors logic could be applied to other rich interfaces such as web browsers or robotic sensors.
- Success would imply that large-scale unsupervised interaction data can substitute for curated training sets in many domains.
- A direct test would track whether agents begin inventing their own sub-goals that were never supplied by the initial curriculum.
Load-bearing premise
The mobile GUI domain contains enough openness and complexity that intelligence will appear once human-designed tasks, checks, and memory rules are taken away.
What would settle it
Training agents for extended periods inside the Darwin framework and observing that they acquire no new capabilities on apps or tasks never shown during training would show the domain lacks sufficient richness.
Figures
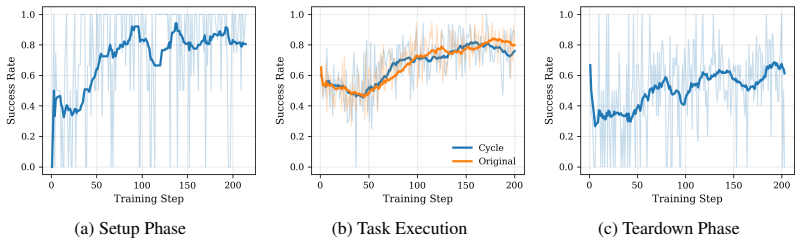
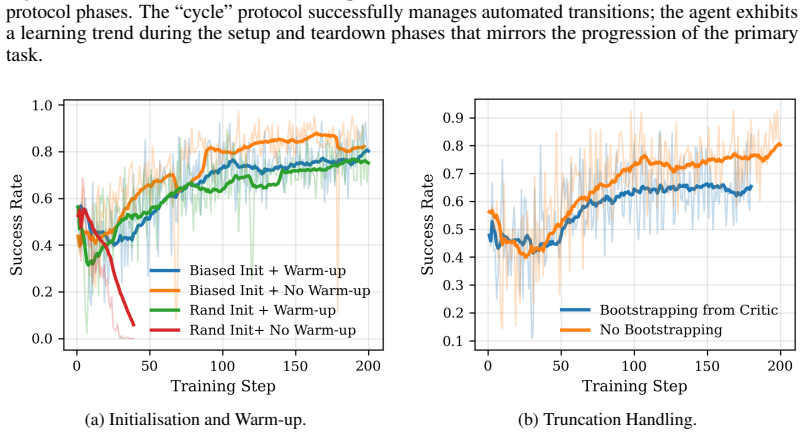
read the original abstract
The goal of artificial intelligence is to create agents capable of general, adaptive behaviour in open-ended environments. Guided by the "Bitter Lesson", we argue that the most effective path toward this goal is to systematically remove human priors and allow intelligence to naturally emerge through interaction with a "Big World" that is orders of magnitude more complex than the agent itself. We propose the mobile Graphical User Interface (GUI) as a practical proxy for such a world and introduce Darwin Mobile Agent, an open-source infrastructure designed as a foundation for autonomous reinforcement learning in this domain. This framework addresses the data-collection bottleneck in real-world mobile interactions by using an asynchronous agent-environment loop across parallel cloud-phone instances. We further propose a conceptual roadmap to systematically remove human priors from three fundamental pillars of a self-evolving agent: task curricula, outcome verification, and memory management. We validate that the Darwin infrastructure provides the stability and scalability required for the first stage of this roadmap: policy optimisation in the GUI domain. This work establishes the practical and theoretical foundation necessary to move toward truly autonomous, self-evolving GUI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Darwin Mobile Agent, an open-source infrastructure using asynchronous agent-environment loops across parallel cloud-phone instances to address data-collection bottlenecks for reinforcement learning in the mobile GUI domain. It presents this domain as a practical proxy for a 'Big World' and outlines a conceptual roadmap for systematically removing human priors from task curricula, outcome verification, and memory management to enable emergent intelligence. The paper asserts that the infrastructure has been validated for stability and scalability sufficient to support the first stage of policy optimisation in this domain.
Significance. If the infrastructure proves stable and scalable and the mobile-GUI proxy supplies adequate complexity once priors are removed, the work could provide a practical foundation for studying autonomous, self-evolving agents and reduce reliance on human-designed curricula and verifiers. The explicit roadmap for prior removal across three pillars is a clear organising contribution. The significance remains prospective because the manuscript is a proposal and infrastructure description rather than an empirical demonstration of emergence or prior removal.
major comments (2)
- [Abstract] Abstract: the claim that 'We validate that the Darwin infrastructure provides the stability and scalability required for the first stage of this roadmap' is load-bearing for positioning the infrastructure as the foundation for the proposed self-evolution program, yet the manuscript supplies no experimental setup, metrics, baselines, or results to support this validation.
- [Roadmap] Roadmap section (conceptual pillars): the proposal to remove human priors from outcome verification and memory management is presented without a concrete mechanism or falsifiable test for how verification and memory will be replaced by emergent processes once the infrastructure is in place, leaving the central hypothesis ungrounded beyond the initial policy-optimisation stage.
minor comments (1)
- The term 'Big World' is used repeatedly without a precise operational definition or reference to prior literature that would allow readers to assess the claimed orders-of-magnitude complexity difference.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential of the infrastructure and the organizing value of the roadmap. Our manuscript is positioned as an infrastructure proposal together with a high-level conceptual roadmap; we address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'We validate that the Darwin infrastructure provides the stability and scalability required for the first stage of this roadmap' is load-bearing for positioning the infrastructure as the foundation for the proposed self-evolution program, yet the manuscript supplies no experimental setup, metrics, baselines, or results to support this validation.
Authors: We agree that the validation claim requires substantiation. The current text asserts stability on the basis of the asynchronous design and initial cloud-phone deployments but contains no formal experimental protocol, metrics, baselines, or quantitative results. We will revise the abstract to remove or qualify the claim and will add a short section describing any available preliminary stability observations or explicitly note the absence of formal validation. revision_made: yes revision: yes
-
Referee: [Roadmap] Roadmap section (conceptual pillars): the proposal to remove human priors from outcome verification and memory management is presented without a concrete mechanism or falsifiable test for how verification and memory will be replaced by emergent processes once the infrastructure is in place, leaving the central hypothesis ungrounded beyond the initial policy-optimisation stage.
Authors: The roadmap is deliberately conceptual and identifies the three pillars as directions for subsequent research once the infrastructure enables the first stage of policy optimization. No concrete mechanisms or falsifiable tests are supplied because these steps lie beyond the scope of the present proposal. We will revise the text to state explicitly that the verification and memory pillars are high-level objectives without current implementations. The grounding for the initial stage rests on the infrastructure's capacity to support RL without human-designed task curricula; the later pillars remain prospective. revision_made: partial revision: partial
Circularity Check
No significant circularity
full rationale
The manuscript is a conceptual proposal and infrastructure roadmap rather than a derivation or empirical study containing fitted parameters, predictions, or mathematical claims. No load-bearing steps reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains; the central hypothesis (removing human priors to enable emergence in a mobile-GUI proxy) is presented as a guiding principle supported by a basic stability validation, with no internal reduction to its own inputs. The work is self-contained as an engineering and conceptual foundation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Bitter Lesson: removing human priors and scaling compute yields superior AI performance
invented entities (1)
-
Darwin Mobile Agent infrastructure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Three dogmas of reinforcement learning.arXiv preprint arXiv:2407.10583,
David Abel, Mark K Ho, and Anna Harutyunyan. Three dogmas of reinforcement learning.arXiv preprint arXiv:2407.10583,
-
[2]
URLhttps://arxiv.org/abs/2511.21631. Michael Bowling, John D Martin, David Abel, and Will Dabney. Settling the reward hypothesis. In International Conference on Machine Learning, pages 3003–3020. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Rethinking the foundations for continual reinforcement learning.arXiv preprint arXiv:2504.08161,
Esraa Elelimy, David Szepesvari, Martha White, and Michael Bowling. Rethinking the foundations for continual reinforcement learning.arXiv preprint arXiv:2504.08161,
-
[4]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-Group policy optimization for LLM agent training.arXiv preprint arXiv:2505.10978,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Martin Klissarov, Akhil Bagaria, Ziyan Luo, George Konidaris, Doina Precup, and Marlos C Machado. Discovering temporal structure: An overview of hierarchical reinforcement learning.arXiv preprint arXiv:2506.14045,
-
[7]
Ning Li, Xiangmou Qu, Jiamu Zhou, Jun Wang, Muning Wen, Kounianhua Du, Xingyu Lou, Qiuying Peng, and Weinan Zhang. MobileUse: A GUI agent with hierarchical reflection for autonomous mobile operation.arXiv preprint arXiv:2507.16853,
-
[8]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
14 Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. UI-TARS: Pioneering automated GUI interaction with native agents.arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. AndroidWorld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URL https: //openreview.net/forum?id=qPMLvJxtPK. Daniel Toyama, Philippe Hamel, Anita Gergely, Gheorghe Comanici, Amelia Glaese, Zafarali Ahmed, Tyler Jackson, Shibl Mourad, and Doina Precup. AndroidEnv: A reinforcement learning platform for Android.arXiv preprint arXiv:2105.13231,
-
[14]
URL http://arxiv.org/abs/2105. 13231. Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, et al. Mobile-Agent-v3: Fundamental agents for GUI automation. arXiv preprint arXiv:2508.15144,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, et al. V APO: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
e-commerce, social, utilities) derived from production applications with visually dynamic interfaces and naturally occurring UI variations
The tasks for each experiment are selected from SPA-Bench (Chen et al., 2025), which covers diverse everyday workflows (e.g. e-commerce, social, utilities) derived from production applications with visually dynamic interfaces and naturally occurring UI variations. It includes both English and Chinese instructions, enabling evaluation of multilingual agent...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.