REVIEW 2 major objections 86 references
LGMT reveals that LLMs often give inconsistent answers to logically equivalent problems, exposing defects missed by static benchmarks.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-07-04 01:20 UTC pith:CQDAFVWK
load-bearing objection LGMT tries to use FOL equivalences for metamorphic testing of LLM reasoning consistency, but the abstract leaves the natural-language equivalence step and the experimental details too thin to judge the results. the 2 major comments →
LGMT: Logic-Grounded Metamorphic Testing for Evaluating the Reasoning Reliability of LLMs
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
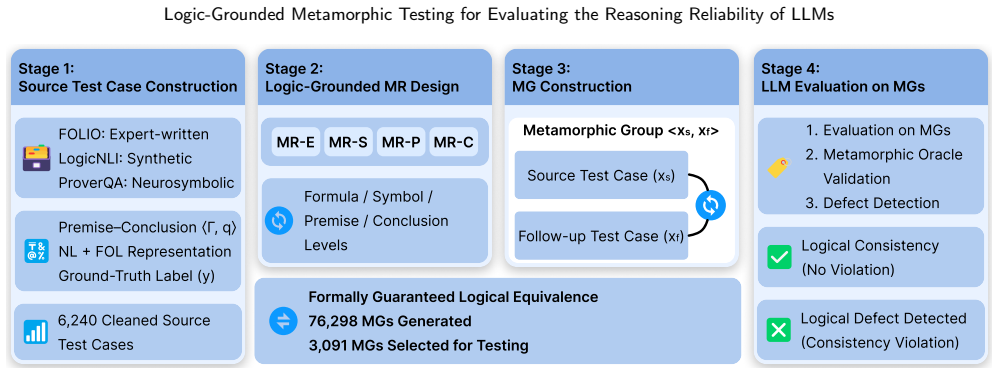
LGMT derives metamorphic relations from first-order logic equivalences, builds sets of semantically invariant test cases, and identifies reasoning defects by checking whether an LLM's outputs remain consistent across each set; experiments on six state-of-the-art models show that this procedure detects substantial defects that static reference-based evaluations miss.
What carries the argument
Metamorphic relations derived from formal logical equivalences in first-order logic, used to generate semantically invariant inputs whose cross-case output consistency is checked without an external oracle.
Load-bearing premise
If an LLM reasons reliably, it will give the same answer to inputs that first-order logic proves to be semantically equivalent.
What would settle it
Re-running the six-LLM experiments and finding that the fraction of inconsistent answers across LGMT pairs is no higher than the error rate reported by conventional reference-based benchmarks on the same questions.
If this is right
- Traditional static benchmarks overestimate LLM reasoning capability by missing inconsistencies under logical transformations.
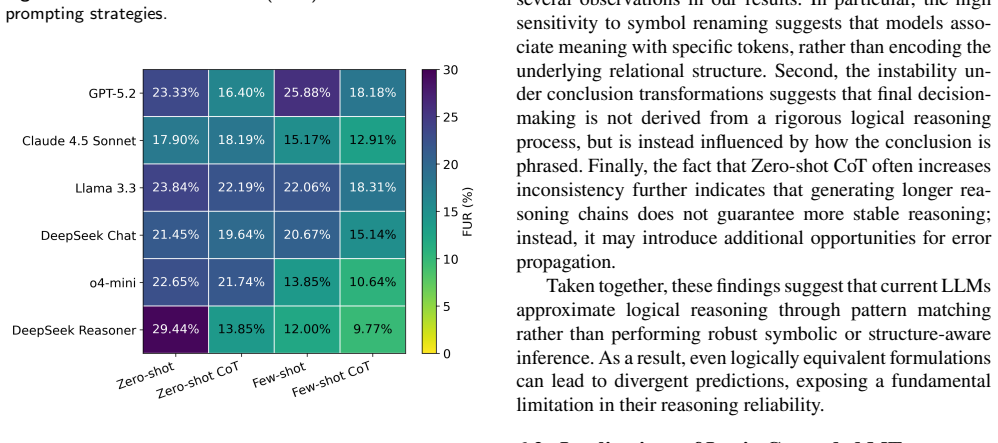
- LLMs remain particularly sensitive to symbol-level and conclusion-level variations even when the underlying logic is unchanged.
- Few-shot chain-of-thought prompting reduces but does not remove the detected inconsistencies.
- LLM evaluation should shift from isolated correctness checks toward explicit tests of robustness under logical invariance.
Where Pith is reading between the lines
- LGMT-style consistency checks could be folded into training loops to penalize models that violate logical equivalences.
- The same metamorphic construction might be applied to non-FOL domains such as arithmetic identities or code refactoring equivalence.
- Automated generation of FOL-derived test suites could become a standard component of future reasoning benchmarks.
- High inconsistency rates may indicate that current LLMs rely more on surface patterns than on internalized logical rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
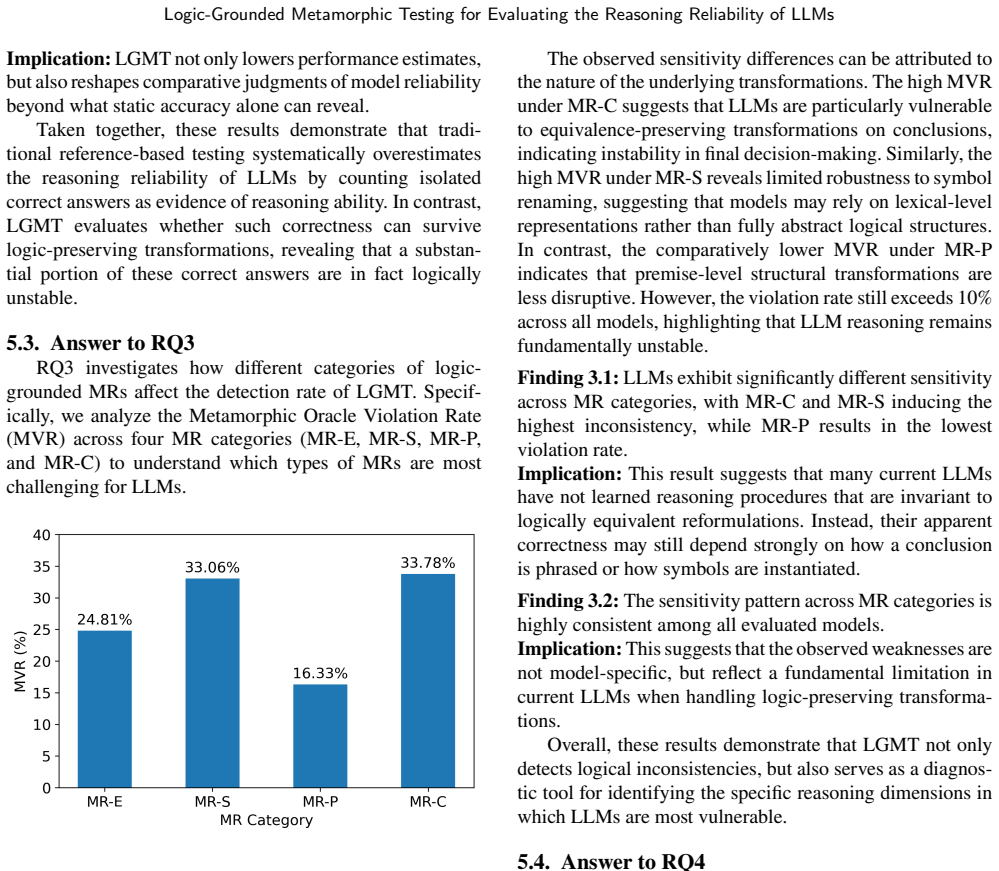
Summary. The paper proposes LGMT, an oracle-free metamorphic testing framework that derives relations from first-order logic equivalences to generate semantically invariant prompt variants and detect LLM reasoning defects via cross-case inconsistency. Experiments on six state-of-the-art LLMs are claimed to reveal substantial hidden defects missed by reference-based benchmarks, with particular sensitivity to symbol-level and conclusion-level variations; advanced prompting only partially mitigates the issues. The work advocates shifting evaluation toward robustness under logical invariance.
Significance. If the FOL-derived relations preserve semantic equivalence in natural-language instantiations without surface-form artifacts, the approach would offer a scalable, reference-free method for diagnosing reasoning reliability beyond static benchmarks, with potential to improve evaluation practices in the field.
major comments (2)
- [Abstract] Abstract (LGMT construction paragraph): The central claim that inconsistencies under metamorphic relations indicate reasoning defects requires that the natural-language instantiations of FOL equivalences remain semantically equivalent. No concrete examples of relations, validation against surface-form artifacts (e.g., quantifier rephrasing or negation placement), or checks that LLMs process the variants identically in meaning are provided; this assumption is load-bearing for interpreting reported defects as reliability failures rather than prompt artifacts.
- [Abstract] Abstract (experimental results paragraph): The claim that LGMT 'exposes substantial hidden defects' on six LLMs is presented without dataset size, number of metamorphic relations tested, statistical significance tests, error bars, or exact consistency metrics, preventing assessment of whether the data support the strength of the conclusion over traditional evaluations.
Simulated Author's Rebuttal
We appreciate the referee's feedback highlighting areas where the abstract could better support its claims. We will revise the abstract accordingly and provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract (LGMT construction paragraph): The central claim that inconsistencies under metamorphic relations indicate reasoning defects requires that the natural-language instantiations of FOL equivalences remain semantically equivalent. No concrete examples of relations, validation against surface-form artifacts (e.g., quantifier rephrasing or negation placement), or checks that LLMs process the variants identically in meaning are provided; this assumption is load-bearing for interpreting reported defects as reliability failures rather than prompt artifacts.
Authors: The full manuscript provides concrete examples of the metamorphic relations, along with a description of how they are derived from FOL equivalences and validated for semantic equivalence through human review to rule out surface-form artifacts. We acknowledge that the abstract does not detail this due to length constraints. We will revise the abstract to include a brief statement on the validation of semantic equivalence. revision: yes
-
Referee: [Abstract] Abstract (experimental results paragraph): The claim that LGMT 'exposes substantial hidden defects' on six LLMs is presented without dataset size, number of metamorphic relations tested, statistical significance tests, error bars, or exact consistency metrics, preventing assessment of whether the data support the strength of the conclusion over traditional evaluations.
Authors: Detailed experimental information, including dataset sizes, the number of metamorphic relations tested, statistical tests, and consistency metrics with error bars, is presented in the full manuscript. The abstract provides a high-level overview. To address the concern, we will add specific quantitative highlights to the experimental results paragraph in the abstract, such as the number of relations and key inconsistency rates. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via external FOL
full rationale
The LGMT framework is constructed by deriving metamorphic relations directly from standard first-order logic equivalences, which are external mathematical facts not defined or fitted within the paper. The consistency-checking oracle is applied to LLM outputs on these transformed cases without any parameter fitting to the target results, self-referential definitions, or load-bearing self-citations. The central empirical claim (exposure of defects) follows from applying this independent construction to LLMs and is not equivalent to the inputs by construction. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
read the original abstract
Large Language Models (LLMs) achieve strong performance on logical reasoning benchmarks, yet their reliability remains uncertain. Existing evaluations rely on static benchmarks, which fail to assess robustness under logically equivalent transformations and often overestimate reasoning capability. We propose LGMT (Logic-Grounded Metamorphic Testing), an oracle-free framework that leverages first-order logic (FOL) to evaluate LLM reasoning. By deriving metamorphic relations from formal logical equivalences, LGMT constructs semantically invariant test cases and detects reasoning defects through cross-case consistency checking. Experiments on six state-of-the-art LLMs show that LGMT exposes substantial hidden defects missed by traditional reference-based evaluations. We further find that models are particularly sensitive to symbol-level and conclusion-level variations, and that advanced prompting such as Few-shot CoT only partially mitigates these issues. These results suggest that LLM evaluation should move beyond isolated correctness toward robustness under logical invariance. LGMT provides a principled and scalable approach for diagnosing reasoning failures.
Figures



Reference graph
Works this paper leans on
-
[1]
Cao, C., Li, M., Dai, J., Yang, J., Zhao, Z., Zhang, S., et al., 2025. Towards advanced mathematical reasoning for llms via first-order logic theorem proving, in: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics. pp. 12429–12449. doi:10.18653/v1/2025. emnlp-main.628
-
[2]
Chen, S., Jin, S., Xie, X., 2021. Testing your question answer- ing software via asking recursively, in: Preceeding of the Interna- tionalConferenceonAutomatedSoftwareEngineering,pp.104–116. doi:10.1109/ASE51524.2021.9678670
-
[3]
Metamorphic testing: A new approach for generating next test cases
Chen, T.Y., Cheung, S.C., Yiu, S.M., 1998. Metamorphic testing: A new approach for generating next test cases. Technical Report HKUST-CS98-01.HongKongUniversityofScienceandTechnology
work page 1998
-
[4]
Chen,T.Y.,Kuo,F.C.,Liu,H.,Poon,P.L.,Towey,D.,Tse,T.H.,etal.,
-
[5]
Metamorphictesting:areviewofchallengesandopportunities. ACM Computing Surveys 51, 1–27. doi:10.1145/3143561
-
[6]
https://doi.org/10.48550/arXiv
Cho,S.,Ruberto,S.,Terragni,V.,2025. Metamorphictestingoflarge languagemodelsfornaturallanguageprocessing.doi:10.48550/arXiv. 2511.02108
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark,P.,Cowhey,I.,Etzioni,O.,Khot,T.,Sabharwal,A.,Schoenick, C., et al., 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. doi:10.48550/ARXIV.1803.05457
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1803.05457 2018
-
[8]
Clark, P., Tafjord, O., Richardson, K., 2021. Transformers as soft reasoners over language, in: Proceedings of the International Joint Conference on Artificial Intelligence, pp. 3882–3890
work page 2021
-
[9]
Errors of measurement in statistics
Cochran, W.G., 1968. Errors of measurement in statistics. Techno- metrics 10, 637–666. doi:10.1080/00401706.1968.10490621
-
[10]
Dalvi, B., Jansen, P., Tafjord, O., Xie, Z., Smith, H., Pipatanangkura, L., et al., 2021. Explaining answers with entailment trees, in: Proceedingsofthe2021ConferenceonEmpiricalMethodsinNatural LanguageProcessing,AssociationforComputationalLinguistics.pp. 7358–7370. doi:10.18653/v1/2021.emnlp-main.585
-
[11]
DeepSeek,Liu, A.,Feng, B.,Xue, B.,Wang, B.,Wu,B., etal., 2025. Deepseek-v3 technical report. doi:10.48550/arXiv.2412.19437
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2025
-
[12]
DeepSeek-AI, Zhu, Q., Guo, D., Shao, Z., Yang, D., Wang, P., et al.,
-
[13]
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. doi:10.48550/arXiv.2406.11931
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.11931
-
[14]
Dziri, N., Lu, X., Sclar, M., Li, X.L., Jiang, L., Lin, B.Y., et al.,
-
[15]
Faith and fate: limits of transformers on compositionality, in: Proceedings of the International Conference on Neural Information Processing Systems, pp. 70293–70332
-
[16]
Ghosh, B., Hasan, S., Arafat, N.A., Khan, A., 2025. Logical consis- tency of large language models in fact-checking, in: The Thirteenth International Conference on Learning Representations. URL:https: //openreview.net/forum?id=SimlDuN0YT
work page 2025
-
[17]
Guan, Y., Wang, D., Chu, Z., Wang, S., Ni, F., Song, R., et al., 2023. Intelligentvirtualassistantswithllm-basedprocessautomation.URL: https://arxiv.org/abs/2312.06677,arXiv:2312.06677
-
[18]
Fine-grained prediction of reading comprehension from eye movements,
Han, S., Schoelkopf, H., Zhao, Y., Qi, Z., Riddell, M., Zhou, W., et al., 2024. Folio: natural language reasoning with first-order logic, in: Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 22017–22031. doi:10.18653/v1/ 2024.emnlp-main.1229
-
[19]
Holliday, W.H., Mandelkern, M., Zhang, C.E., 2024. Conditional andmodalreasoninginlargelanguagemodels,in:Proceedingsofthe Conference on Empirical Methods in Natural Language Processing, pp. 3800–3821. doi:10.18653/v1/2024.emnlp-main.222
-
[20]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., et al.,
-
[21]
Asurveyonhallucinationinlargelanguagemodels:Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems 43, 1–55. doi:10.1145/3703155
-
[22]
Hyun, S., Guo, M., Babar, M.A., 2024. Metal: metamorphic testing frameworkforanalyzinglarge-languagemodelqualities,in:Proceed- ing of the IEEE Conference on Software Testing, Verification and Validation, IEEE. pp. 117–128. doi:10.1109/ICST60714.2024.00019
-
[23]
Jiang,J.,Wang,J.,Yan,Y.,Liu,Y.,Zhu,J.,Zhang,M.,etal.,2025.Do largelanguagemodelsexcelincomplexlogicalreasoningwithformal language?, in: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 16889–16914. doi:10. 18653/v1/2025.emnlp-main.855
work page 2025
-
[24]
Jimenez, C.E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., et al.,
-
[25]
Swe-bench: Can language models resolve real-world github issues? doi:10.48550/arXiv.2310.06770
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770
-
[26]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., etal.,2020. Retrieval-augmentedgenerationforknowledge-intensive nlp tasks, in: Advances in Neural Information Processing Systems, Curran Associates, Inc.. pp. 9459–9474
work page 2020
-
[27]
Drowzee: metamorphic testing for fact-conflicting hallucination detection in large language models
Li, N., Li, Y., Liu, Y., Shi, L., Wang, K., Wang, H., 2024. Drowzee: metamorphic testing for fact-conflicting hallucination detection in large language models. Proceedings of the ACM on Programming Languages 8, 1843–1872. doi:10.1145/3689776
-
[28]
Evaluating the Logical Reasoning Abilities of Large Reasoning Models
Liu, H., Ding, Y., Fu, Z., Zhang, C., Liu, X., Zhang, Y., 2025. Evaluating the logical reasoning abilities of large reasoning models. doi:10.48550/arXiv.2505.11854
-
[29]
Liu, J., Cui, L., Liu, H., Huang, D., Wang, Y., Zhang, Y., 2021. Logiqa: a challenge dataset for machine reading comprehension with logical reasoning, in: Proceedings of the International Joint Confer- enceonArtificialIntelligence,pp.3622–3628. URL:https://dl.acm. org/doi/10.5555/3491440.3491941
-
[30]
Luo,M.,Kumbhar,S.,shen,M.,Parmar,M.,Varshney,N.,Banerjee, P.,etal.,2023. Towardslogiglue:Abriefsurveyandabenchmarkfor analyzing logical reasoning capabilities of language models. doi:10. 48550/ARXIV.2310.00836
-
[31]
Mondorf, P., Plank, B., 2024. Beyond accuracy: Evaluating the reasoning behavior of large language models - a survey, in: First Conference on Language Modeling. URL:https://openreview.net/ forum?id=Lmjgl2n11u
work page 2024
-
[32]
Murphy, C., Kaiser, G.E., Hu, L., Wu, L., 2008. Properties of machine learning applications for use in metamorphic testing, in: ProceedingsoftheInternationalConferenceonSoftwareEngineering & Knowledge Engineering, Knowledge Systems Institute Graduate School. pp. 867–872
work page 2008
-
[33]
Olausson, T., Gu, A., Lipkin, B., Zhang, C., Solar-Lezama, A., Tenenbaum, J., et al., 2023. Linc: a neurosymbolic approach for logicalreasoningbycombininglanguagemodelswithfirst-orderlogic provers, in: Proceedings of the Conference on Empirical Methods in NaturalLanguageProcessing,pp.5153–5176. doi:10.18653/v1/2023. emnlp-main.313
-
[34]
Pan, L., Albalak, A., Wang, X., Wang, W.Y., 2023. Logic-lm: Empoweringlargelanguagemodelswithsymbolicsolversforfaithful logical reasoning, in: Proceeding of the Conference on Empirical MethodsinNaturalLanguageProcessing. URL:https://openreview. net/forum?id=nWXMv949ZH¬eId=qt0t8SsVvT
work page 2023
-
[35]
Park, S., Subramonyam, H., Kulkarni, C., 2024. Thinking assistants: Llm-based conversational assistants that help users think by asking rather than answering. URL:https://arxiv.org/abs/2312.06024, arXiv:2312.06024
-
[36]
Parmar, M., Patel, N., Varshney, N., Nakamura, M., Luo, M., Mashetty,S.,etal.,2024. Logicbench:Towardssystematicevaluation oflogicalreasoningabilityoflargelanguagemodels,in:Proceedings Zenghui Zhou et al.:Preprint submitted to ElsevierPage 16 of 25 Logic-Grounded Metamorphic Testing for Evaluating the Reasoning Reliability of LLMs oftheAnnualMeetingoftheA...
-
[37]
Patel, N., Kulkarni, M., Parmar, M., Budhiraja, A., Nakamura, M., Varshney, N., et al., 2024. Multi-logieval: towards evaluating multi- step logical reasoning ability of large language models, in: Proceed- ings of the Conference on Empirical Methods in Natural Language Processing, pp. 20856–20879. doi:10.18653/v1/2024.emnlp-main. 1160
-
[38]
Qi, C., Ma, R., Li, B., Du, H., Hui, B., Wu, J., et al., 2024. Large language models meet symbolic provers for logical reasoning eval- uation, in: Proceeding of the International Conference on Learning Representations. URL:https://openreview.net/forum?id=C25SgeXWjE
work page 2024
-
[39]
Code Llama: Open Foundation Models for Code
Rozière, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X.E., et al., 2024. Code llama: Open foundation models for code. doi:10. 48550/arXiv.2308.12950
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Saparov, A., He, H., 2022. Language models are greedy reasoners: a systematic formal analysis of chain-of-thought, in: The International Conference on Learning Representations. URL:https://openreview. net/forum?id=qFVVBzXxR2V
work page 2022
-
[41]
IEEETransactionsonSoftwareEngineering 42, 805–824
Segura,S.,Fraser,G.,Sanchez,A.B.,Ruiz-Cortés,A.,2016.Asurvey onmetamorphictesting. IEEETransactionsonSoftwareEngineering 42, 805–824. doi:10.1109/TSE.2016.2532875
-
[42]
Singh,S.,2024. Arelargelanguagemodelsgoodatfuzzyreasoning?, in: Proceedings of the International Conference on Computational Intelligence and Intelligent Systems, pp. 1–6. doi:10.1145/3708778. 3708779
-
[43]
Sinha, K., Sodhani, S., Dong, J., Pineau, J., Hamilton, W.L., 2019. Clutrr: a diagnostic benchmark for inductive reasoning from text, in: ProceedingsoftheConferenceonEmpiricalMethodsinNaturalLan- guage Processing and the International Joint Conference on Natural Language Processing, pp. 4505–4514. doi:10.18653/v1/D19-1458
-
[44]
Metarag: Metamorphic testing for hallucination detection in rag systems
Sok, C., Luz, D., Haddam, Y., 2025. Metarag: Metamorphic testing for hallucination detection in rag systems. doi:10.48550/arXiv.2509. 09360
-
[45]
Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., et al., 2023. Challenging big-bench tasks and whether chain- of-thought can solve them, in: Findings of the Association for Com- putational Linguistics: ACL 2023, pp. 13003–13051. doi:10.18653/ v1/2023.findings-acl.824
work page 2023
-
[46]
Tafjord, O., Dalvi, B., Clark, P., 2021. Proofwriter: generating implications,proofs,andabductivestatementsovernaturallanguage, in: Findings of the Association for Computational Linguistics: ACL- IJCNLP 2021, pp. 3621–3634. doi:10.18653/v1/2021.findings-acl. 317
-
[47]
Tian, J., Li, Y., Chen, W., Xiao, L., He, H., Jin, Y., 2021. Diagnosing the first-order logical reasoning ability through logicnli, in: Proceed- ings of the Conference on Empirical Methods in Natural Language Processing, pp. 3738–3747. doi:10.18653/v1/2021.emnlp-main.303
-
[48]
Wan, Y., Wang, W., Yang, Y., Yuan, Y., Huang, J.t., He, P., et al.,
-
[49]
Logicasker: Evaluating and improving the logical reasoning ability of large language models, in: Proceedings of the International Conference on Empirical Methods in Natural Language Processing, pp. 2124–2155. doi:10.18653/v1/2024.emnlp-main.128
-
[50]
Wang, X., Wei, J., Schuurmans, D., Le, Q.V., Chi, E.H., Narang, S., et al., 2022. Self-consistency improves chain of thought reasoning in language models, in: The Eleventh International Conference on Learning Representations
work page 2022
-
[51]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., et al., 2022. Chain-of-thought prompting elicits reasoning in large language models, in: Proceedings of the International Conference on Neural Information Processing Systems, pp. 24824–24837
work page 2022
-
[52]
A systematic literature review of hallucinations in large language models
Woesle, C., Fischer-Brandies, L., Buettner, R., 2025. A systematic literature review of hallucinations in large language models. IEEE Access 13, 148231–148253. doi:10.1109/ACCESS.2025.3601206
-
[53]
Detecting and reducing the factual hallucinations of large language models with metamorphic testing
Wu, W., Cao, Y., Yi, N., Ou, R., Zheng, Z., 2025. Detecting and reducing the factual hallucinations of large language models with metamorphic testing. Proceedings of the ACM on Software Engineering 2, 1432–1453. doi:10.1145/3715784
-
[54]
Testing and validating machine learning classifiers by metamorphic testing
Xie,X.,Ho,J.W.K.,Murphy,C.,Kaiser,G.,Xu,B.,Chen,T.Y.,2011. Testing and validating machine learning classifiers by metamorphic testing. Journal of Systems and Software 84, 544–558. doi:10.1016/ j.jss.2010.11.920
work page 2011
-
[55]
Are largelanguagemodelsreallygoodlogicalreasoners?acomprehensive evaluation and beyond
Xu, F., Lin, Q., Han, J., Zhao, T., Liu, J., Cambria, E., 2025. Are largelanguagemodelsreallygoodlogicalreasoners?acomprehensive evaluation and beyond. IEEE Transactions on Knowledge and Data Engineering 37, 1620–1634. doi:10.1109/TKDE.2025.3536008
-
[56]
arXiv preprint arXiv:2404.18824 , year=
Xu,R.,Wang,Z.,Fan,R.Z.,Liu,P.,2024. Benchmarkingbenchmark leakage in large language models. doi:10.48550/arXiv.2404.18824
-
[57]
Hal- lucination detection in large language models with metamorphic relations
Yang, B., Al Mamun, M.A., Zhang, J.M., Uddin, G., 2025a. Hal- lucination detection in large language models with metamorphic relations. Proceedings of the ACM on Software Engineering 2, 425–
-
[58]
Hallucinationdetectionfor llm-based text-to-sql generation via two-stage metamorphic testing
Yang,B.,Xia,Y.,Sun,W.,Liu,Y.,2025b. Hallucinationdetectionfor llm-based text-to-sql generation via two-stage metamorphic testing. doi:10.48550/arXiv.2512.22250
-
[59]
Yu, W., Jiang, Z., Dong, Y., Feng, J., 2020. Reclor: a reading comprehension dataset requiring logical reasoning, in: Proceedings oftheInternationalConferenceonLearningRepresentations. doi:10. 48550/arXiv.2002.04326
-
[60]
A survey of large language model agents for question answering,
Yue,M.,2025. Asurveyoflargelanguagemodelagentsforquestion answering. doi:10.48550/arXiv.2503.19213
-
[61]
Zhang, D., Li, Z.Z., Zhang, M.L., Zhang, J., Liu, Z., Yao, Y., et al.,
-
[62]
IEEE Transactions on Pattern Analysis and Machine Intelligence , 1–20doi:10.1109/TPAMI.2025.3637037
From system 1 to system 2: A survey of reasoning large lan- guage models. IEEE Transactions on Pattern Analysis and Machine Intelligence , 1–20doi:10.1109/TPAMI.2025.3637037
-
[63]
Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., et al.,
-
[64]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models. doi:10.48550/arXiv.2205.10625
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.10625
-
[65]
Toolqa: A dataset for llm question answering with external tools
Zhuang, Y., Yu, Y., Wang, K., Sun, H., Zhang, C., 2023. Toolqa: A dataset for llm question answering with external tools. Advances in Neural Information Processing Systems 36, 50117–50143. Zenghui Zhou et al.:Preprint submitted to ElsevierPage 17 of 25 Logic-Grounded Metamorphic Testing for Evaluating the Reasoning Reliability of LLMs A. Completeness of M...
work page 2023
-
[67]
All citizens of Lawton Park use the zip code 98199
-
[69]
Conclusion Tom is a citizen of Washington
Daniel uses the zip code 98199. Conclusion Tom is a citizen of Washington. The ground-truth label of this instance isUnknown, since no premise connects Lawton Park or Seattle to Wash- ington. (2) FOL Representation.The corresponding symbolic representation is shown below. Premises 1.NeighbourhoodIn(lawtonPark, seattle) 2.forall x. (ResidentOf(x, lawtonPar...
-
[70]
LawtonParkisaneighborhoodinSeattle
-
[71]
For every person, either they are not a citizenofLawtonPark,ortheyusethezip code 98199
-
[72]
Tom is a citizen of Lawton Park
-
[73]
Conclusion Tom is a citizen of Washington
Daniel uses the zip code 98199. Conclusion Tom is a citizen of Washington. (5)ModelOutputsandOracleDecision.Letthemodel outputsforthesourceandfollow-uptestcasesbedenotedas 𝑦𝑠and𝑦 𝑓,respectively.UnderLGMT,ametamorphicoracle violationoccurs if 𝑦𝑠 ≠𝑦 𝑓 Since the transformation preserves logical equivalence, the correct reasoning outcome should remain unchang...
-
[75]
Zero Explanation: Do not generate any reasoning, thought processes, or introductory text. Provide only the final judgment. ↪ ↪ # Output Format: You must output a single, strictly formatted JSON object. The JSON must contain exactly one key: "label".↪ The value for "label" must be exactly one of the following strings: "True", "False", or "Unknown".↪ Output...
-
[77]
Step-by-Step Deduction: You must perform a rigorous, step-by-step logical deduction. Act like a formal proof system. Clearly state how the premises interact to evaluate the conclusion. Do not skip logical steps. ↪ ↪ ↪ ↪ # Output Format: You must output a single, strictly formatted JSON object. The JSON must contain exactly two keys: "reasoning" and "label...
-
[79]
Zero Explanation: Do not generate any reasoning, thought processes, or introductory text. Provide only the final judgment. ↪ ↪ # Output Format: You must output a single, strictly formatted JSON object. The JSON must contain exactly one key: "label".↪ The value for "label" must be exactly one of the following strings: "True", "False", or "Unknown".↪ Output...
-
[80]
Your evaluation must rely strictly on formal logical structure
Pure Formal Logic: Treat all provided premises as absolute truth, regardless of real-world facts. Your evaluation must rely strictly on formal logical structure. ↪ ↪ ↪
-
[81]
Step-by-Step Deduction: You must perform a rigorous, step-by-step logical deduction. Act like a formal proof system. Clearly state how the premises interact to evaluate the conclusion. Do not skip logical steps. ↪ ↪ ↪ ↪ # Output Format: You must output a single, strictly formatted JSON object. The JSON must contain exactly two keys: "reasoning" and "label...
-
[82]
**Logical Connectives (Scope by Structure)** - **AND (&)**: Use "both A and B". If A is a complex sub-formula, use a comma: "both A, and B".↪ - **OR (|)**: Use "either A or B". - **Biconditional (<->)**: Use "A if and only if B". (Use a comma before'if'if A is complex).↪ - **Negation (-)**: Always use the prefix "it is not the case that".↪ Zenghui Zhou et...
-
[83]
**Conditional Symbol Handling** - **Standard Word** (e.g.,`Bitter(x)`,`Jadiel`): Use natural phrasing.↪ Example:`Bitter(Jadiel)`-> "Jadiel is Bitter"; `-Bitter(Jadiel)`-> "it is not the case that Jadiel is Bitter". ↪ ↪ - **Abstract/Placeholder** (e.g.,`Pre1(x)`, `Con1`): Use formal phrasing.↪ Example:`Pre1(x)`-> "x has property Pre1"; `-Pre1(x)`-> "it is ...
-
[84]
**Quantifiers & Variables** - Keep the order strictly left-to-right. -`all x.`-> "For all x, " -`exists x.`-> "There exists at least one x, such that "↪ - **NO Pronouns**: Always repeat the variable (x, y) or entity name. Never use "it", "he", or "they".↪
-
[85]
it is not the case that it is not the case that A
**No Simplification** - **Double Negation (--A)**: Translate as "it is not the case that it is not the case that A".↪ - **Redundancy (A | A)**: Translate as "either A is true or A is true".↪ - **Constants**:`& 1`-> "...and it is logically true";`| 0`-> "...or it is logically false".↪ # Examples for Reference - FOL: --Orange(Stanley) -> {"translation": "it...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.