A Good Talk Does not Look Like a Summary, It Teaches You! Measuring Takeaways from Paper-to-Video Talks
Pith reviewed 2026-06-30 00:57 UTC · model grok-4.3
The pith
Generated videos from papers mention key topics and follow structure but fail to explain background concepts or why methods work.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
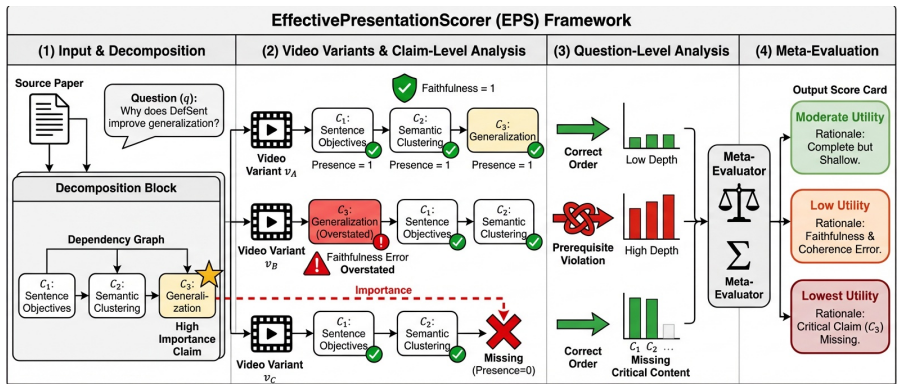
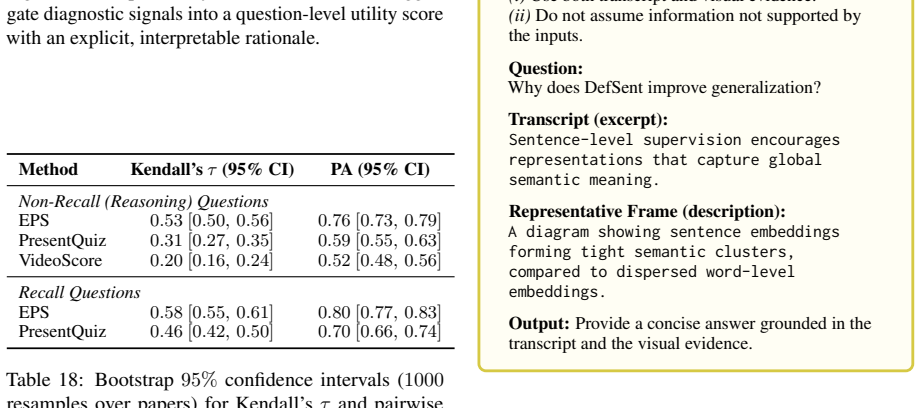
EffectivePresentationScorer shows that current paper-to-video systems produce outputs that mention the correct topics and follow the paper's outline but fail to introduce prerequisite concepts or clarify the rationale behind the method, and these instructional failures are not detected by prior evaluation metrics that emphasize content presence instead of explanatory quality.
What carries the argument
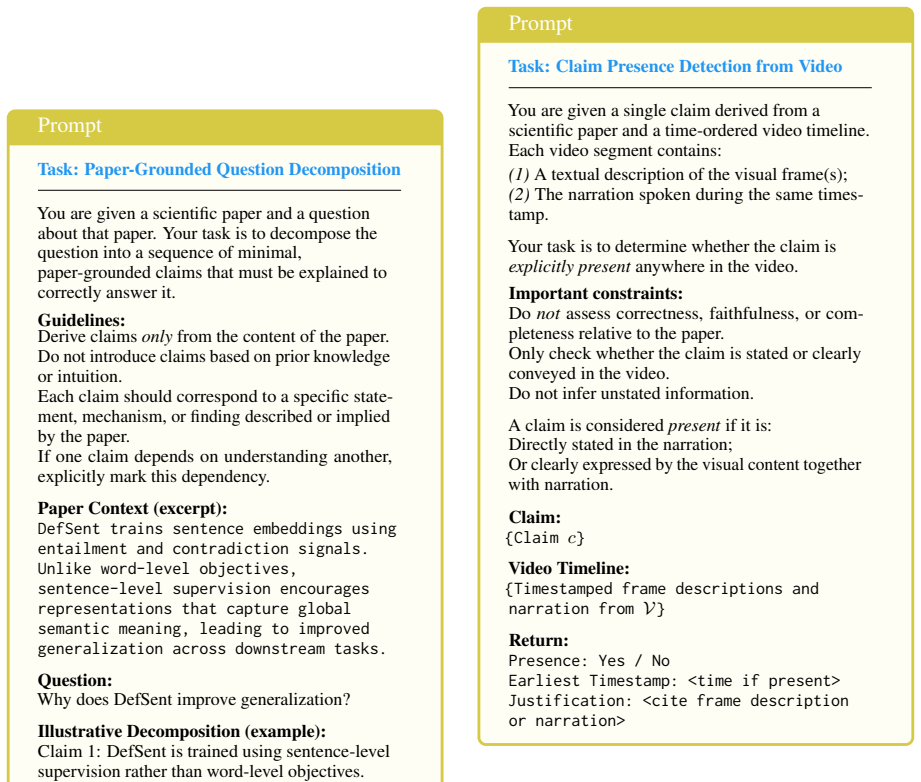
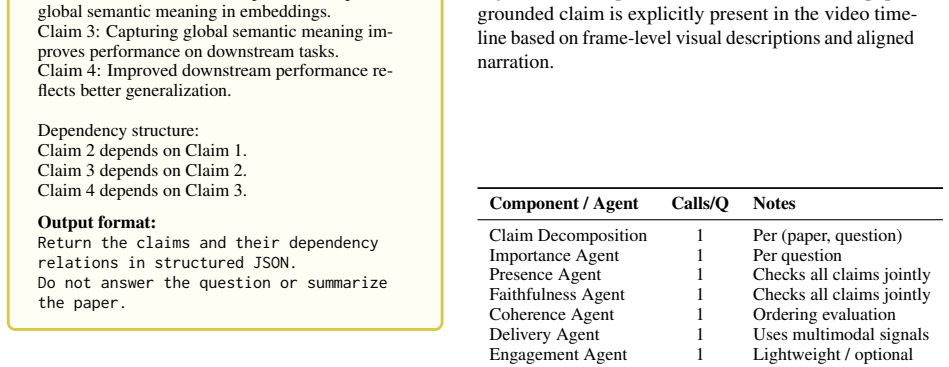
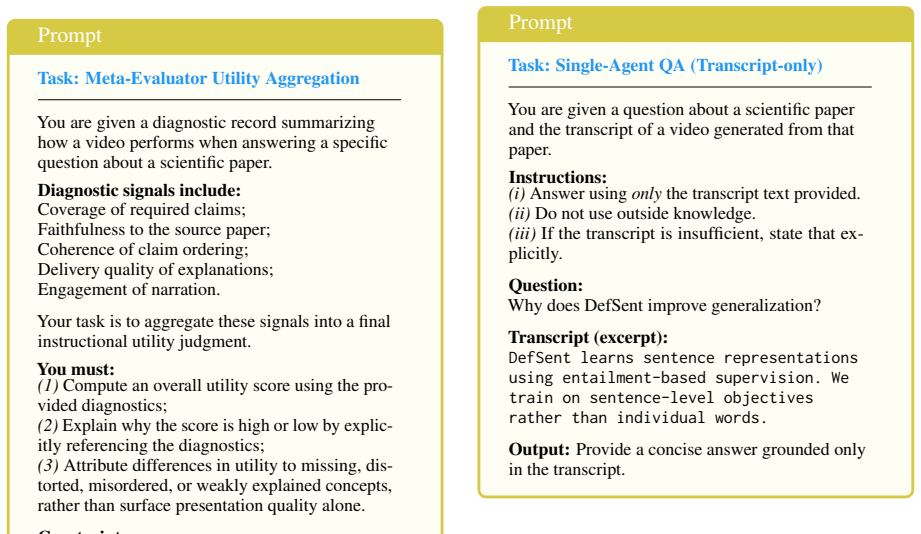
EffectivePresentationScorer, a framework that applies three checks for instructional quality: clear explanation of main ideas, introduction of needed background concepts, and connection of technical details to the main contribution.
If this is right
- Video generation systems must add explicit mechanisms for background explanation and rationale rather than relying on paper structure alone.
- Evaluation of scientific videos should incorporate instructional checks instead of stopping at topic coverage or visual metrics.
- Educational use of automated paper videos requires new quality thresholds that penalize missing prerequisites.
- Designers of paper-to-video tools need to model viewer knowledge gaps that the original paper assumes are already filled.
Where Pith is reading between the lines
- The same scorer could be adapted to evaluate other formats such as slide decks or podcast scripts from papers.
- If generation models were trained with an auxiliary loss that rewards background introduction, the instructional scores might rise without changing topic coverage.
- Longer videos that insert short explanatory segments before technical sections could address the observed gaps.
Load-bearing premise
The three checks for clear explanations, background concepts, and contribution links are enough to judge whether a video teaches effectively.
What would settle it
A controlled study in which viewers watch the generated videos and then answer questions about prerequisites and method rationale, compared against the scorer's pass/fail decisions on the same videos.
Figures





read the original abstract
Automatically generated videos from scientific papers are increasingly used for education and research dissemination. However, existing evaluation metrics mainly measure visual quality or whether key points from the paper appear in the video without assessing whether the video actually helps viewers understand the ideas. We introduce EffectivePresentationScorer, a framework for evaluating the instructional quality of scientific presentation videos. It checks whether a video explains the main ideas clearly, introduces needed background concepts, and connects technical details to the main contribution of the paper. When we apply EffectivePresentationScorer to the existing paper-to-video generation systems, we find that generated videos mention the correct topics and follow the structure of the paper but fail to explain prerequisite concepts or clarify why the method works. These failures are often ignored by existing video evaluation metrics, which focus on content presence rather than explanatory quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EffectivePresentationScorer, a framework for evaluating the instructional quality of automatically generated scientific presentation videos. It defines three checks—whether the video explains main ideas clearly, introduces needed background concepts, and connects technical details to the paper's main contribution—and applies the scorer to existing paper-to-video systems. The central finding is that generated videos mention correct topics and follow paper structure but fail to explain prerequisites or clarify why methods work, a shortcoming not captured by prior metrics that focus on content presence rather than explanatory quality.
Significance. If the scorer can be shown to correlate with human judgments of teaching effectiveness, the work would provide a needed distinction between content-coverage metrics and instructional value, potentially guiding future paper-to-video systems toward better educational outcomes. The absence of any validation data or implementation details in the current manuscript leaves this potential unrealized.
major comments (2)
- [Abstract] Abstract: The central claim that generated videos 'fail to explain prerequisite concepts or clarify why the method works' rests entirely on EffectivePresentationScorer being a reliable indicator of instructional quality. No implementation details, inter-rater agreement, correlation with viewer comprehension tests, or human validation data are reported for the three checks, so the reported distinction from existing content-presence metrics is unsupported.
- [Abstract] Abstract: The three checks are presented as sufficient indicators of teaching value, yet the manuscript supplies no evidence that they are independent of simple topic-presence detection or that they predict actual viewer understanding; this makes the finding that existing systems 'mention the correct topics... but fail to explain' circular with the scorer definition itself.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for validation of EffectivePresentationScorer. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that generated videos 'fail to explain prerequisite concepts or clarify why the method works' rests entirely on EffectivePresentationScorer being a reliable indicator of instructional quality. No implementation details, inter-rater agreement, correlation with viewer comprehension tests, or human validation data are reported for the three checks, so the reported distinction from existing content-presence metrics is unsupported.
Authors: We agree that the current manuscript does not report inter-rater agreement, correlation with comprehension tests, or human validation data for the three checks. The implementation details of the checks (clear explanation of ideas, prerequisite introduction, and contribution linkage) are defined in Section 3 based on established educational principles from the learning sciences literature. However, the absence of empirical validation against human judgments is a limitation. We will add a new subsection detailing the operational definitions with examples and include a small-scale human validation study correlating scorer outputs with viewer comprehension scores in the revised version. revision: yes
-
Referee: [Abstract] Abstract: The three checks are presented as sufficient indicators of teaching value, yet the manuscript supplies no evidence that they are independent of simple topic-presence detection or that they predict actual viewer understanding; this makes the finding that existing systems 'mention the correct topics... but fail to explain' circular with the scorer definition itself.
Authors: The checks are intended to assess explanatory depth rather than mere presence (e.g., by requiring that prerequisites appear before technical details and that method steps are explicitly tied to the paper's core claim). We acknowledge that without supporting evidence this distinction can appear definitional. In revision we will add concrete video examples demonstrating cases where topic coverage is high yet the checks flag explanatory gaps, and we will report initial correlation results from the planned human study to show independence from presence-only metrics. revision: yes
Circularity Check
No circularity: new scorer defined independently and applied to external systems
full rationale
The paper defines EffectivePresentationScorer via three explicit checks (clear main-idea explanation, background introduction, technical-to-contribution linkage) and applies it to outputs from prior paper-to-video systems. No equations, parameters, or claims reduce by construction to the inputs; the finding that videos mention topics but fail explanatory checks follows directly from the new definition without self-referential fitting, renaming, or self-citation chains. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[3]
2025 , eprint=
Paper2Video: Automatic Video Generation from Scientific Papers , author=. 2025 , eprint=
2025
-
[5]
Bloom's taxonomy of cognitive learning objectives
Adams, Nancy E. Bloom's taxonomy of cognitive learning objectives. J Med Libr Assoc
-
[6]
2024 , eprint=
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models , author=. 2024 , eprint=
2024
-
[7]
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and Wang, Yaohui and Chen, Xinyuan and Wang, Limin and Lin, Dahua and Qiao, Yu and Liu, Ziwei , booktitle=
-
[8]
CLIPS core: A Reference-free Evaluation Metric for Image Captioning
Hessel, Jack and Holtzman, Ari and Forbes, Maxwell and Le Bras, Ronan and Choi, Yejin. CLIPS core: A Reference-free Evaluation Metric for Image Captioning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.595
-
[9]
Publications Manual , year = "1983", publisher =
1983
-
[10]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[11]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[12]
Dan Gusfield , title =. 1997
1997
-
[13]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[14]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[15]
2019 , eprint=
Towards Accurate Generative Models of Video: A New Metric & Challenges , author=. 2019 , eprint=
2019
-
[16]
2021 , eprint=
Item Response Theory -- A Statistical Framework for Educational and Psychological Measurement , author=. 2021 , eprint=
2021
-
[17]
2025 , eprint=
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. 2025 , eprint=
2025
-
[18]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Lingen: Towards high-resolution minute-length text-to-video generation with linear computational complexity , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[19]
arXiv preprint arXiv:2502.11079 , year=
Phantom: Subject-consistent video generation via cross-modal alignment , author=. arXiv preprint arXiv:2502.11079 , year=
-
[20]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Identity-preserving text-to-video generation by frequency decomposition , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[21]
2022 , eprint=
Make-A-Video: Text-to-Video Generation without Text-Video Data , author=. 2022 , eprint=
2022
-
[22]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[23]
2021 , eprint=
Emerging Properties in Self-Supervised Vision Transformers , author=. 2021 , eprint=
2021
-
[25]
2024 , eprint=
VideoPhy: Evaluating Physical Commonsense for Video Generation , author=. 2024 , eprint=
2024
-
[27]
2024 , eprint=
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection , author=. 2024 , eprint=
2024
-
[28]
2025 , eprint=
Mobile-VideoGPT: Fast and Accurate Video Understanding Language Model , author=. 2025 , eprint=
2025
-
[30]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[31]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[32]
Annotating Educational Questions for Student Response Analysis
Godea, Andreea and Nielsen, Rodney. Annotating Educational Questions for Student Response Analysis. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[33]
Sustainability , VOLUME =
Timbi-Sisalima, Cristian and Sánchez-Gordón, Mary and Otón-Tortosa, Salvador and Mendoza-González, Ricardo , TITLE =. Sustainability , VOLUME =. 2024 , NUMBER =
2024
-
[34]
Proceedings of the 11th International Conference on Intelligent Tutoring Systems , pages =
Long, Yanjin and Aleven, Vincent , title =. Proceedings of the 11th International Conference on Intelligent Tutoring Systems , pages =. 2012 , isbn =. doi:10.1007/978-3-642-30950-2_115 , abstract =
-
[35]
C. P. Ormell , title =. Educational Research , volume =. 1974 , publisher =. doi:10.1080/0013188740170101 , URL =
-
[36]
2024 , eprint=
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models , author=. 2024 , eprint=
2024
-
[38]
Niekrenz, Lukas and Spreckelsen, Cord. How to design effective educational videos for teaching evidence-based medicine to undergraduate learners - systematic review with complementing qualitative research to develop a practicable guide. Med Educ Online
-
[43]
Students' Perceptions of Creating Educational Videos as a Teaching and Learning Strategy
Ram \'o n-Arbu \'e s, Enrique and Bl \'a zquez-Ornat, Isabel and Sagarra-Romero, Luc \' a and Benito-Ruiz, Eva and Ant \'o n-Solanas, Isabel and G \'o mez-Torres, Piedad. Students' Perceptions of Creating Educational Videos as a Teaching and Learning Strategy. Nurse Educ
-
[45]
2024 , eprint=
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models , author=. 2024 , eprint=
2024
-
[47]
2025 , eprint=
Video models are zero-shot learners and reasoners , author=. 2025 , eprint=
2025
-
[48]
ArXiv , year =
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation , author =. ArXiv , year =
-
[49]
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
Reimers, Nils and Gurevych, Iryna. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. 2020
2020
-
[50]
2008--2025 , archivePrefix =
GROBID , howpublished =. 2008--2025 , archivePrefix =
2008
-
[53]
Psychology of learning and motivation , volume=
Multimedia learning , author=. Psychology of learning and motivation , volume=. 2002 , publisher=
2002
-
[55]
2017 , school=
The Influence of Testing and Content Presentation Method on Mandatory Federal Employee Training , author=. 2017 , school=
2017
-
[56]
Steven J. Lysne and Brant G. Miller , title =. Journal of College Science Teaching , volume =. 2017 , publisher =. doi:10.2505/4/jcst17\_046\_06\_100 , URL =
-
[58]
and Liu, Lei and Ober, Teresa M
Watts, Field M. and Liu, Lei and Ober, Teresa M. and Song, Yi and Jusino-Del Valle, Euvelisse and Zhai, Xiaoming and Wang, Yun and Liu, Ninghao , TITLE =. Education Sciences , VOLUME =. 2025 , NUMBER =
2025
-
[59]
2026 , eprint=
Developing Authentic Simulated Learners for Mathematics Teacher Learning: Insights from Three Approaches with Large Language Models , author=. 2026 , eprint=
2026
-
[60]
Journal of Geoscience Education , year=
Instructional Utility and Learning Efficacy of Common Active Learning Strategies , author=. Journal of Geoscience Education , year=
-
[61]
2025 , eprint=
LecEval: An Automated Metric for Multimodal Knowledge Acquisition in Multimedia Learning , author=. 2025 , eprint=
2025
-
[62]
de Koning , and Halszka Jarodzka
Kevin Ackermans, Björn B. de Koning , and Halszka Jarodzka. 2025. https://doi.org/10.1016/j.learninstruc.2025.102137 Instructional videos and deeper processing: Insights and applications . Learning and Instruction, 98:102137
-
[63]
Nancy E Adams. 2015. Bloom's taxonomy of cognitive learning objectives. J Med Libr Assoc, 103(3):152--153
2015
-
[64]
Paul Ayres and Kevin Ackermans. 2025. https://doi.org/10.1016/j.learninstruc.2024.102077 Some do's and don'ts of educational videos . Learning and Instruction, 96:102077
-
[65]
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. 2024. https://arxiv.org/abs/2406.03520 Videophy: Evaluating physical commonsense for video generation . Preprint, arXiv:2406.03520
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Jie Cao, Ha Nguyen, Selim Yavuz, Boran Yu, Shuguang Wang, Pavneet Kaur Bharaj, and Dionne Cross Francis. 2026. https://arxiv.org/abs/2604.04361 Developing authentic simulated learners for mathematics teacher learning: Insights from three approaches with large language models . Preprint, arXiv:2604.04361
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[67]
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, Kai Wang, Quy Duc Do, Yuansheng Ni, Bohan Lyu, Yaswanth Narsupalli, Rongqi Fan, Zhiheng Lyu, Bill Yuchen Lin, and Wenhu Chen. 2024 a . https://doi.org/10.18653/v1/2024.emnlp-main.127 V ideo S core: Building automatic metrics to sim...
-
[68]
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, Kai Wang, Quy Duc Do, Yuansheng Ni, Bohan Lyu, Yaswanth Narsupalli, Rongqi Fan, Zhiheng Lyu, Yuchen Lin, and Wenhu Chen. 2024 b . https://arxiv.org/abs/2406.15252 Videoscore: Building automatic metrics to simulate fine-grained huma...
-
[69]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. 2024 a . VBench : Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Patter...
2024
-
[70]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. 2024 b . https://arxiv.org/abs/2411.13503 Vbench++: Comprehensive and versatile benchmark suite for video generative models . Preprint, arX...
-
[71]
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. 2024. https://doi.org/10.18653/v1/2024.acl-long.663 VIES core: Towards explainable metrics for conditional image synthesis evaluation . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12268--12290, Bangkok, Thailand. Associa...
- [72]
-
[73]
Dongqi Liu, Chenxi Whitehouse, Xi Yu, Louis Mahon, Rohit Saxena, Zheng Zhao, Yifu Qiu, Mirella Lapata, and Vera Demberg. 2025. https://doi.org/10.18653/v1/2025.acl-long.310 What is that talk about? a video-to-text summarization dataset for scientific presentations . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics...
- [74]
-
[75]
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, and Lichao Sun. 2024 b . https://arxiv.org/abs/2402.17177 Sora: A review on background, technology, limitations, and opportunities of large vision models . Preprint, arXiv:2402.17177
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
Richard E Mayer. 2002. Multimedia learning. In Psychology of learning and motivation, volume 41, pages 85--139. Elsevier
2002
-
[77]
McConnell, LeeAnna Young Chapman, Charles Douglas Czajka, Jason P
David A. McConnell, LeeAnna Young Chapman, Charles Douglas Czajka, Jason P. Jones, Katherine Ryker, and Jennifer Wiggen. 2017. https://api.semanticscholar.org/CorpusID:85462730 Instructional utility and learning efficacy of common active learning strategies . Journal of Geoscience Education, 65:604 -- 625
2017
-
[78]
Ishani Mondal, Shwetha S, Anandhavelu Natarajan, Aparna Garimella, Sambaran Bandyopadhyay, and Jordan Boyd-Graber. 2024. https://doi.org/10.18653/v1/2024.eacl-long.163 Presentations by the humans and for the humans: Harnessing LLM s for generating persona-aware slides from documents . In Proceedings of the 18th Conference of the European Chapter of the As...
-
[79]
Lukas Niekrenz and Cord Spreckelsen. 2024. How to design effective educational videos for teaching evidence-based medicine to undergraduate learners - systematic review with complementing qualitative research to develop a practicable guide. Med Educ Online, 29(1):2339569
2024
-
[80]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. https://arxiv.org/abs/2103.00020 Learning transferable visual models from natural language supervision . Preprint, arXiv:2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[81]
Enrique Ram \'o n-Arbu \'e s, Isabel Bl \'a zquez-Ornat, Luc \' a Sagarra-Romero, Eva Benito-Ruiz, Isabel Ant \'o n-Solanas, and Piedad G \'o mez-Torres. 2025. Students' perceptions of creating educational videos as a teaching and learning strategy. Nurse Educ, 50(4):E219--E224
2025
-
[82]
Nils Reimers and Iryna Gurevych. 2019. https://doi.org/10.18653/v1/D19-1410 Sentence- BERT : Sentence embeddings using S iamese BERT -networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982--3992, Hong Kong, Chi...
-
[83]
Nils Reimers and Iryna Gurevych. 2020. https://arxiv.org/abs/2004.09813 Making monolingual sentence embeddings multilingual using knowledge distillation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics
-
[84]
Ehud Reiter. 2025. https://doi.org/10.1162/coli.a.18 We should evaluate real-world impact . Computational Linguistics, 51(4):1419--1431
-
[85]
Edward Sun, Yufang Hou, Dakuo Wang, Yunfeng Zhang, and Nancy X. R. Wang. 2021. https://doi.org/10.18653/v1/2021.naacl-main.111 D 2 S : Document-to-slide generation via query-based text summarization . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 140...
-
[86]
John Sweller. 1994. https://doi.org/10.1016/0959-4752(94)90003-5 Cognitive load theory, learning difficulty, and instructional design . Learning and Instruction, 4(4):295--312
-
[87]
John Sweller. 2024. https://doi.org/10.1016/j.lindif.2024.102423 Cognitive load theory and individual differences . Learning and Individual Differences, 110:102423
-
[88]
Hayato Tsukagoshi, Ryohei Sasano, and Koichi Takeda. 2021. https://doi.org/10.18653/v1/2021.acl-short.52 D ef S ent: Sentence embeddings using definition sentences . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers),...
-
[89]
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. 2019. https://arxiv.org/abs/1812.01717 Towards accurate generative models of video: A new metric & challenges . Preprint, arXiv:1812.01717
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[90]
Field M. Watts, Lei Liu, Teresa M. Ober, Yi Song, Euvelisse Jusino-Del Valle, Xiaoming Zhai, Yun Wang, and Ninghao Liu. 2025. https://doi.org/10.3390/educsci15111507 A framework for designing an ai chatbot to support scientific argumentation . Education Sciences, 15(11)
-
[91]
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. 2025. https://arxiv.org/abs/2509.20328 Video models are zero-shot learners and reasoners . Preprint, arXiv:2509.20328
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[92]
Yuxiang Wu, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. 2021. https://doi.org/10.18653/v1/2021.acl-short.57 Training adaptive computation for open-domain question answering with computational constraints . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference ...
- [93]
-
[94]
Joy Lim Jia Yin, Daniel Zhang-Li, Jifan Yu, Haoxuan Li, Shangqing Tu, Yuanchun Wang, Zhiyuan Liu, Huiqin Liu, Lei Hou, Juanzi Li, and Bin Xu. 2025. https://arxiv.org/abs/2505.02078 Leceval: An automated metric for multimodal knowledge acquisition in multimedia learning . Preprint, arXiv:2505.02078
-
[95]
Hao Zheng, Xinyan Guan, Hao Kong, Wenkai Zhang, Jia Zheng, Weixiang Zhou, Hongyu Lin, Yaojie Lu, Xianpei Han, and Le Sun. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.728 PPTA gent: Generating and evaluating presentations beyond text-to-slides . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14413--14...
- [96]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.