Aero-World: Action-Conditioned Aerial Video Generation from Inertial Controls
Pith reviewed 2026-05-20 05:38 UTC · model grok-4.3
The pith
A frozen Physics Probe supplies inertial consistency checks that let a pretrained video diffusion model generate aerial footage aligned with low-level acceleration and rotation commands.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
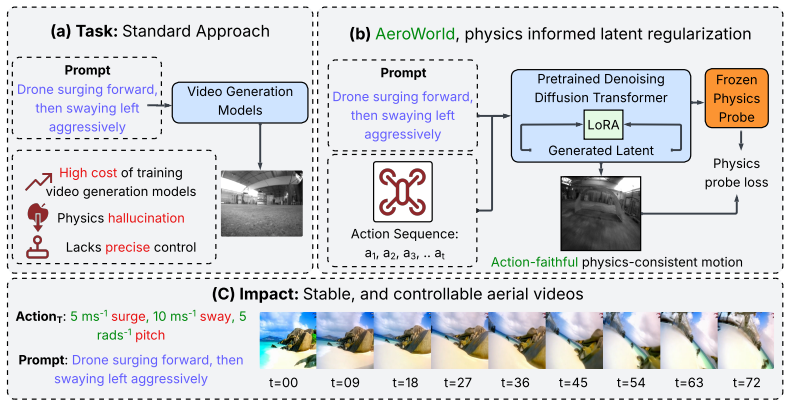
Aero-World converts a pretrained image-to-video diffusion model into a controllable aerial video generator by injecting sequences of translational acceleration and angular velocity through an action-token stream. A frozen latent-space Physics Probe, trained independently on real video-IMU pairs, supplies differentiable inertial-consistency supervision during LoRA finetuning. On the introduced AeroBench, the method raises mean Action Alignment Score from 57.7 to 63.6, lowers FVD to 596.5, raises SSIM to 0.595, and raises Flow-IMU correlation to 0.44, outperforming action-only finetuning and the prior AirScape baseline.
What carries the argument
The frozen latent-space Physics Probe that delivers differentiable inertial-consistency supervision on video-IMU pairs without requiring video decoding during finetuning.
If this is right
- Generated videos show higher agreement with commanded inertial actions as measured by the Action Alignment Score.
- The method improves the quality-consistency trade-off relative to prior action-conditioned baselines.
- AeroBench metrics can be used to compare any future action-conditioned aerial video generator.
- The generated videos can serve as scalable proxy data for training or evaluating aerial agents.
Where Pith is reading between the lines
- The same probe-supervision pattern could be tested on ground-vehicle or manipulator video generation where low-level controls must be respected.
- Running the generated videos through a downstream navigation planner would test whether higher AAS actually improves agent success rates.
- Expanding the Physics Probe training set to more drone models and weather conditions could increase robustness of the supervision signal.
Load-bearing premise
A latent Physics Probe trained once on real video-IMU pairs can give reliable motion-consistency signals when kept frozen during later LoRA adaptation of a video generator.
What would settle it
Ablating the Physics Probe loss during finetuning and measuring no gain (or a drop) in Action Alignment Score and Flow-IMU correlation on AeroBench would falsify the claim.
Figures





read the original abstract
Foundation video models produce visually impressive results, but their use in embodied AI remains limited because they are primarily trained on natural language rather than low-level control signals. This limitation is especially pronounced for aerial flight, where motion occurs in unconstrained 6-DoF space and small errors in ego-motion can produce large trajectory drift. Generating aerial videos that follow fine-grained inertial actions can support scalable training and evaluation of aerial agents by providing a controllable proxy for real-world or expensive simulation data. To address this problem, we propose \textbf{Aero-World}, a method for converting a pretrained image-to-video diffusion model into a controllable aerial video generator. Aero-World injects sequences of translational acceleration and angular velocity into a pretrained latent diffusion transformer through an action-token stream. A frozen latent-space Physics Probe, trained independently on real video--IMU pairs, provides differentiable inertial-consistency supervision during LoRA finetuning while avoiding computationally expensive video decoding. We further propose \textbf{AeroBench}, a benchmark for evaluating whether generated drone videos adhere to low-level action signals. AeroBench uses Action Alignment Score (AAS) to measure agreement with commanded inertial actions and Physical Consistency Rate (PCR) to measure temporal motion stability. On AeroBench, Aero-World improves mean AAS from 57.7 to 63.6 over action-only finetuning and gives a stronger quality-control trade-off than AirScape, with lower FVD (596.5 vs. 1058.6), higher SSIM (0.595 vs. 0.505), and higher Flow-IMU correlation (0.44 vs. 0.20). These results suggest that frozen Physics Probe supervision is a practical mechanism for adapting pretrained video generators toward more action-aligned aerial motion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Aero-World, a method to adapt a pretrained latent diffusion transformer (image-to-video model) into an action-conditioned aerial video generator. It injects sequences of translational acceleration and angular velocity via an action-token stream, uses LoRA finetuning, and employs a frozen latent-space Physics Probe (trained independently on real video-IMU pairs) to supply differentiable inertial-consistency supervision without decoding videos. The authors also propose the AeroBench benchmark, which evaluates generated videos using Action Alignment Score (AAS) for agreement with commanded inertial actions and Physical Consistency Rate (PCR) for temporal stability. Experiments report gains on AeroBench (AAS 57.7 to 63.6), lower FVD (596.5 vs. 1058.6), higher SSIM (0.595 vs. 0.505), and higher Flow-IMU correlation (0.44 vs. 0.20) compared to action-only finetuning and AirScape.
Significance. If the central results hold, the work offers a practical route for injecting low-level inertial control into foundation video models for aerial domains, which could aid scalable training and evaluation of embodied aerial agents. The frozen-probe supervision mechanism and the AeroBench benchmark are concrete contributions that address a gap between language-conditioned video generation and controllable 6-DoF motion synthesis.
major comments (2)
- [§3.2–3.3] §3.2–3.3: The claim that the frozen Physics Probe supplies reliable differentiable inertial-consistency supervision during LoRA finetuning rests on the unverified assumption that probe predictions remain accurate on the distribution of videos produced by the adapting generator. No ablation or error analysis is provided that measures probe accuracy (or gradient quality) on synthetic videos that differ in appearance statistics or ego-motion trajectories from the real video-IMU training pairs; the modest AAS improvement (57.7 → 63.6) could therefore arise from noisy or biased gradients rather than true inertial fidelity.
- [§4.1 and Table 1] §4.1 and Table 1: The experimental comparison with AirScape and the action-only baseline lacks reported error bars, dataset split details, and full hyperparameter specifications for the Physics Probe and LoRA stages. Without these, it is difficult to assess whether the reported gains on AAS, FVD, SSIM, and Flow-IMU correlation are robust or sensitive to implementation choices.
minor comments (2)
- [§3] The notation for the action-token stream and the precise architecture of the Physics Probe (e.g., input dimensionality, latent-space projection) should be defined more explicitly with equations or a diagram to aid reproducibility.
- [§4] AeroBench metric definitions (AAS and PCR) are introduced in §4 but would benefit from a short pseudocode or explicit formula in the main text rather than only in the supplement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2–3.3] §3.2–3.3: The claim that the frozen Physics Probe supplies reliable differentiable inertial-consistency supervision during LoRA finetuning rests on the unverified assumption that probe predictions remain accurate on the distribution of videos produced by the adapting generator. No ablation or error analysis is provided that measures probe accuracy (or gradient quality) on synthetic videos that differ in appearance statistics or ego-motion trajectories from the real video-IMU training pairs; the modest AAS improvement (57.7 → 63.6) could therefore arise from noisy or biased gradients rather than true inertial fidelity.
Authors: We agree that an explicit validation of the Physics Probe on generated videos would provide stronger support for the supervision mechanism. The probe is trained on real video-IMU pairs and kept frozen precisely to preserve its learned motion priors, and the consistent gains across AAS, FVD, SSIM, and Flow-IMU correlation suggest the gradients are useful. Nevertheless, we did not quantify probe error or gradient quality on the adapting generator’s outputs. In the revised manuscript we will add an ablation that measures the probe’s prediction accuracy and the resulting gradient norms on a held-out set of videos sampled from the finetuned model. revision: yes
-
Referee: [§4.1 and Table 1] §4.1 and Table 1: The experimental comparison with AirScape and the action-only baseline lacks reported error bars, dataset split details, and full hyperparameter specifications for the Physics Probe and LoRA stages. Without these, it is difficult to assess whether the reported gains on AAS, FVD, SSIM, and Flow-IMU correlation are robust or sensitive to implementation choices.
Authors: We acknowledge that the current experimental section omits several details required for full reproducibility and robustness assessment. In the revised version we will report mean and standard deviation over at least three independent runs with different random seeds, explicitly describe the train/validation/test splits used for both AeroBench and the Physics Probe training data, and provide complete hyperparameter tables for the probe pre-training stage and the subsequent LoRA adaptation (including learning rates, rank, alpha, and training steps). revision: yes
Circularity Check
No significant circularity; supervision and evaluation are externally grounded
full rationale
The derivation relies on a Physics Probe trained independently on real video-IMU pairs to supply inertial-consistency loss during LoRA adaptation of a pretrained diffusion model. AeroBench evaluation metrics (AAS, PCR) and reported gains (e.g., AAS 57.7→63.6) are measured on held-out generated videos against commanded actions, not by construction from the same fitted quantities. No self-definitional reduction, fitted-input-as-prediction, or load-bearing self-citation chain appears in the provided derivation; the central claim remains falsifiable against external real IMU data and the new benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained image-to-video latent diffusion transformer can be effectively adapted via LoRA while preserving visual quality
invented entities (2)
-
Physics Probe
no independent evidence
-
AeroBench
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A frozen latent-space Physics Probe, trained independently on real video–IMU pairs, provides differentiable inertial-consistency supervision during LoRA finetuning
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AAS and PCR metrics on AeroBench for 6-DoF action alignment
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Yang Zhou, Hao Shao, Letian Wang, Zhuofan Zong, Hongsheng Li, and Steven L Waslander. Drivinggen: A comprehensive benchmark for generative video world models in autonomous driving.arXiv preprint arXiv:2601.01528,
-
[7]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chat- topadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11,
work page 2025
-
[12]
Yuancheng Xu, Wenqi Xian, Li Ma, Julien Philip, Ahmet Levent Ta¸ sel, Yiwei Zhao, Ryan Burgert, Mingming He, Oliver Hermann, Oliver Pilarski, et al. Virtually being: Customizing camera- controllable video diffusion models with multi-view performance captures.arXiv preprint arXiv:2510.14179,
-
[13]
Jinkun Hao, Mingda Jia, Ruiyan Wang, Xihui Liu, Ran Yi, Lizhuang Ma, Jiangmiao Pang, and Xudong Xu. Egosim: Egocentric world simulator for embodied interaction generation.arXiv preprint arXiv:2604.01001,
-
[14]
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
10 Xiaojie Xu, Zhengyuan Lin, Kang He, Yukang Feng, Xiaofeng Mao, Yuanyang Yin, Kaipeng Zhang, and Yongtao Ge. Worldmark: A unified benchmark suite for interactive video world models.arXiv preprint arXiv:2604.21686,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Liang Heng, Jiadong Xu, Yiwen Wang, Xiaoqi Li, Muhe Cai, Yan Shen, Juan Zhu, Guanghui Ren, and Hao Dong. Imagine2act: Leveraging object-action motion consistency from imagined goals for robotic manipulation.arXiv preprint arXiv:2509.17125,
-
[16]
How Far is Video Generation from World Model: A Physical Law Perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective.arXiv preprint arXiv:2411.02385,
work page internal anchor Pith review arXiv
-
[17]
Do generative video models understand physical principles?
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles?arXiv preprint arXiv:2501.09038,
work page internal anchor Pith review arXiv
-
[18]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
doi: 10.1109/LRA.2026. 3653405. Jeffrey Delmerico, Titus Cieslewski, Henri Rebecq, Matthias Faessler, and Davide Scaramuzza. Are we ready for autonomous drone racing? the UZH-FPV drone racing dataset. InIEEE Int. Conf. Robot. Autom. (ICRA),
-
[20]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual description.arXiv preprint arXiv:2210.02399,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Gong Ming, and Nan Duan. Dragnuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089,
work page internal anchor Pith review arXiv
-
[25]
ACM. doi: 10.1145/3746027. 3758180. URLhttps://doi.org/10.1145/3746027.3758180. 11 Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
-
[26]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, et al. A generalist agent.arXiv preprint arXiv:2205.06175,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Dronevla: Vla based aerial manipulation.arXiv preprint arXiv:2601.13809,
Fawad Mehboob, Monijesu James, Amir Habel, Jeffrin Sam, Miguel Altamirano Cabrera, and Dzmitry Tsetserukou. Dronevla: Vla based aerial manipulation.arXiv preprint arXiv:2601.13809,
-
[29]
Valerii Serpiva, Artem Lykov, Artyom Myshlyaev, Muhammad Haris Khan, Ali Alridha Abdulkarim, Oleg Sautenkov, and Dzmitry Tsetserukou. Racevla: Vla-based racing drone navigation with human-like behaviour.arXiv preprint arXiv:2503.02572,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.