HaloGuard 1.0: An Open Weights Constitutional Classifier for Multilingual AI Safety
Pith reviewed 2026-07-03 14:36 UTC · model grok-4.3
The pith
An 0.8B open-weights constitutional classifier tops multilingual prompt-safety benchmarks at 90.9 average F1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
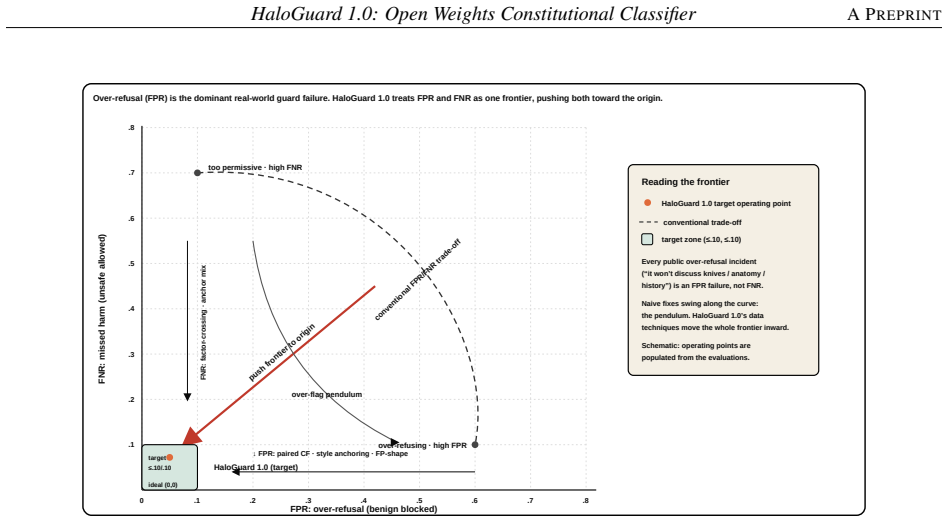
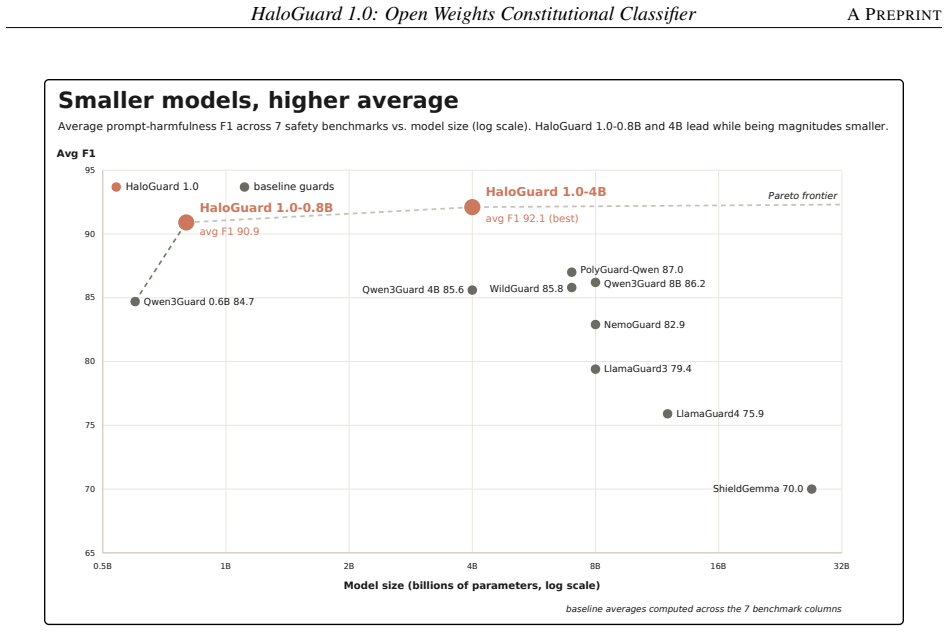
HaloGuard 1.0-0.8B attains the best average F1 (90.9) of any open guard evaluated, outperforming baselines up to 27B parameters while holding false-positive rate to 4.3 and false-negative rate to 9.5. The 4B variant reaches 92.1 F1 and 3.5 FPR. Most apparent missed-harm cases in remaining failures are benchmark mislabels rather than genuine model misses. An always-on adversarial red-teaming protocol continuously hardens the guard against content-level and agentic attacks.
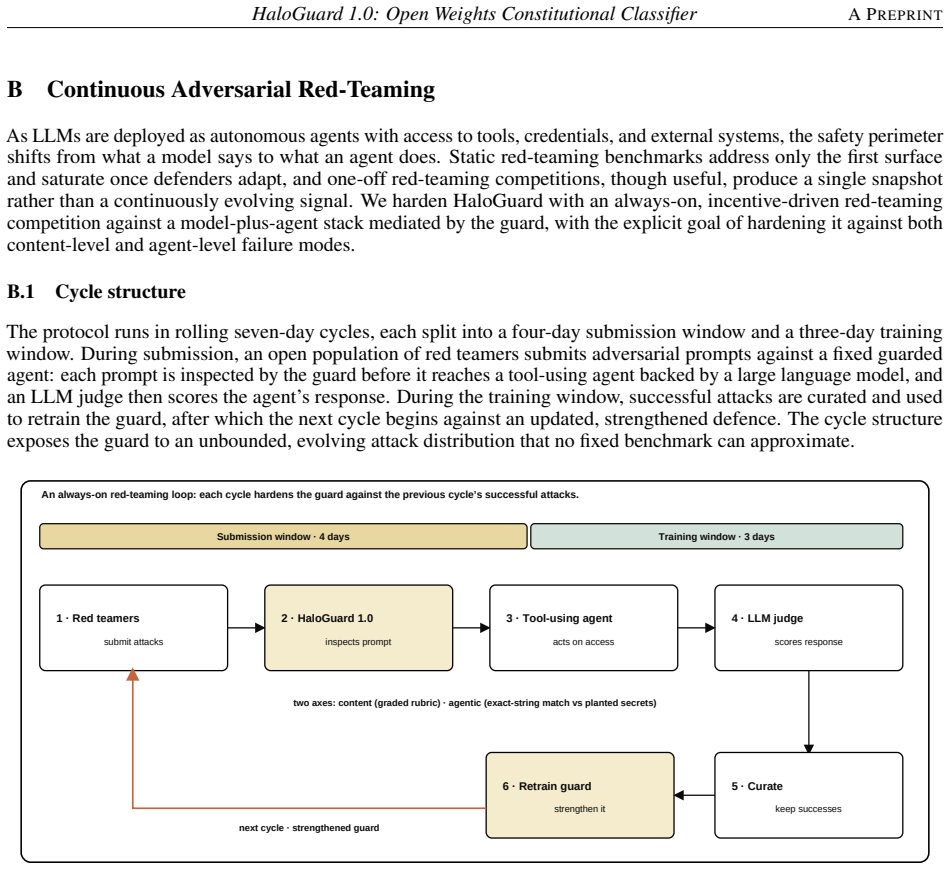
What carries the argument
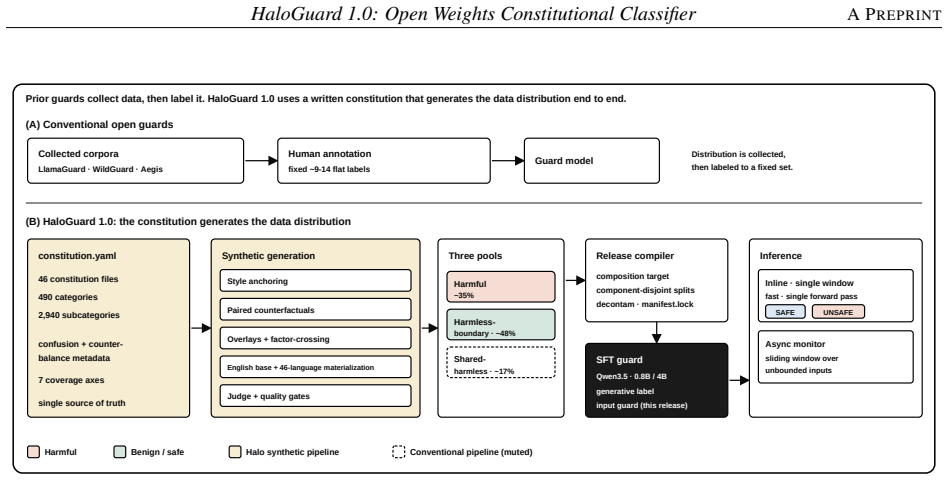
The safety constitution of 46 policies and 2,940 subcategories that drives synthetic data generation with one-to-one paired counterfactuals holding topic and vocabulary fixed while flipping intent, plus a two-tier harmless design and balanced multilingual materialisation across 46 languages treating language as surface form.
If this is right
- The 0.8B model delivers 90.9 average F1 with FPR 4.3 and FNR 9.5 across the evaluated benchmarks.
- The 4B variant spends added capacity on improved precision, reaching 92.1 F1 and 3.5 FPR.
- Structured adjudication shows most remaining failures trace to benchmark label errors rather than model shortcomings.
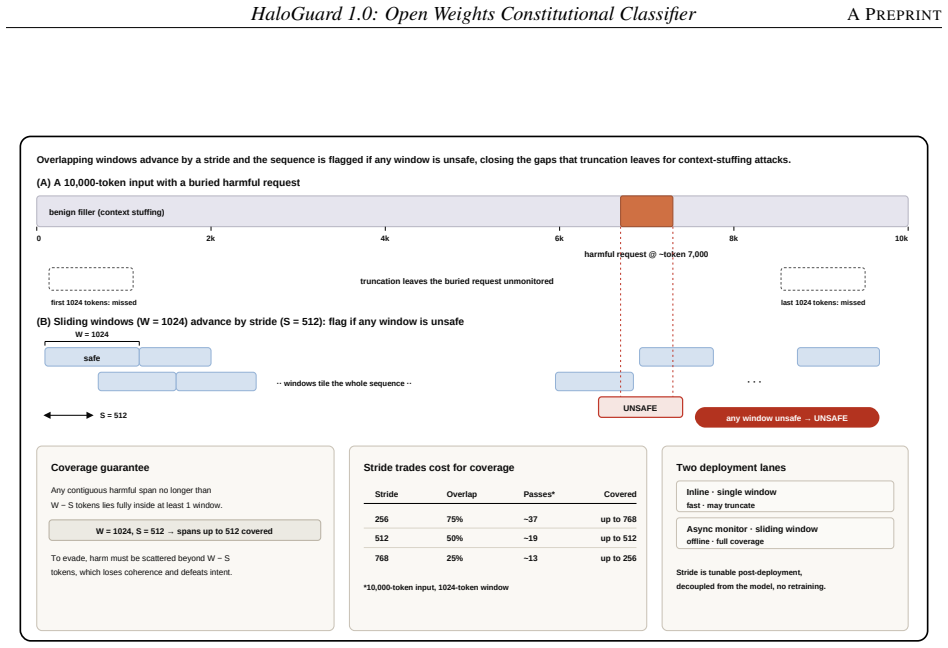
- Continuous adversarial red-teaming hardens the model against both content-level and agentic attacks.
Where Pith is reading between the lines
- The constitution-driven synthetic data pipeline could be reused for other classification tasks that require fine-grained boundary detection.
- Public release of the weights enables independent verification on fresh benchmarks that were not used in training or evaluation.
- Treating language as surface form rather than adversarial signal may reduce unintended language-based disparities in safety decisions.
Load-bearing premise
The seven prompt-safety benchmarks used for evaluation are representative of real-world safety requirements and free of systematic label errors that would inflate reported performance.
What would settle it
A new, independently constructed and labeled prompt-safety benchmark on which the HaloGuard models record substantially lower average F1 than the reported 90.9 would falsify the central performance claim.
Figures


read the original abstract
We present HaloGuard 1.0, an open-weights implementation of the constitutional-classifier paradigm for input safety. It achieves state-of-the-art performance on English and multilingual prompt-safety benchmarks at roughly one-tenth the model size of current leading open guard models. The safety constitution is the organising structure of the corpus: a natural-language constitution of 46 policies and 2,940 subcategories drives synthetic data generation, with exhaustive one-to-one paired counterfactuals that hold topic and vocabulary fixed while flipping intent, a two-tier harmless design that separately targets boundary and baseline false positives (FPs), and balanced multilingual materialisation across 46 languages that treats language as a surface form appearing on both sides of the boundary rather than as an adversarial signal. Across seven prompt-safety benchmarks, HaloGuard 1.0-0.8B attains the best average F1 (90.9) of any open guard we evaluate, outperforming baselines up to 27B parameters (over 30 times larger) while holding false-positive rate (FPR) to 4.3 and false-negative rate (FNR) to 9.5. The HaloGuard 1.0-4B variant reaches average F1 of 92.1 and FPR of 3.5, spending its extra capacity on precision rather than recall. A structured adjudication of the remaining failures indicates that most apparent missed-harm cases are benchmark mislabels rather than genuine model misses. An always-on adversarial red-teaming protocol continuously hardens the guard against both content-level and agentic attacks. We release the models as open weights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HaloGuard 1.0, an open-weights constitutional classifier for input safety. Using a natural-language constitution of 46 policies and 2,940 subcategories, it generates synthetic training data with exhaustive one-to-one counterfactual pairs, a two-tier harmless design, and balanced multilingual materialisation across 46 languages. The 0.8B model achieves the highest average F1 score of 90.9 across seven prompt-safety benchmarks, outperforming larger open guard models up to 27B parameters, with FPR of 4.3 and FNR of 9.5. The 4B variant improves to F1 92.1 and FPR 3.5. An adjudication suggests most remaining errors are benchmark mislabels. The models are released as open weights.
Significance. If the performance claims hold without contamination from the evaluation benchmarks in the training data pipeline, this would represent a significant advance in efficient, multilingual AI safety classification. It would demonstrate that detailed constitutional synthetic data generation can enable small models to achieve superior safety performance compared to much larger models, with implications for accessible and open safety tools. The open-weights release and the structured approach to data generation are notable strengths.
major comments (3)
- [Abstract] Abstract: The headline performance metrics (average F1 90.9, FPR 4.3, FNR 9.5 for the 0.8B model) are reported without accompanying details on train/test splits, benchmark construction, or confirmation that the seven benchmarks did not influence the synthetic data generation or hyperparameter choices. This omission makes it impossible to verify the central claim against the possibility of benchmark-specific fitting.
- [Abstract] Abstract (adjudication paragraph): The finding that most apparent missed-harm cases are benchmark mislabels indicates that the reported F1 may partly reflect label noise or distributional overlap with the 2,940 subcategories rather than genuine generalisation. No independent human re-annotation or out-of-distribution test set is described that would falsify this.
- [Abstract] Synthetic data generation description (Abstract): The constitution of 46 policies and 2,940 subcategories, combined with one-to-one counterfactual pairs and multilingual materialisation, creates a risk that evaluation benchmarks share structural artifacts or phrasing patterns; the manuscript provides no explicit check that the benchmarks are free of such overlap with the training corpus.
minor comments (1)
- [Abstract] Abstract: The mention of an 'always-on adversarial red-teaming protocol' lacks any implementation details or quantitative results, which would help assess its contribution to the reported robustness.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important points about verifiability and potential overlap that we address below. We will revise the abstract and add supporting analyses to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance metrics (average F1 90.9, FPR 4.3, FNR 9.5 for the 0.8B model) are reported without accompanying details on train/test splits, benchmark construction, or confirmation that the seven benchmarks did not influence the synthetic data generation or hyperparameter choices. This omission makes it impossible to verify the central claim against the possibility of benchmark-specific fitting.
Authors: The full manuscript details the train/test splits (synthetic data split 80/20 with all benchmarks held completely out), benchmark construction from standard public sources, and explicit statements that benchmarks played no role in data generation or hyperparameter selection. These appear in the Methods and Evaluation sections. We will add a single sentence to the abstract summarizing these safeguards for immediate visibility. revision: yes
-
Referee: [Abstract] Abstract (adjudication paragraph): The finding that most apparent missed-harm cases are benchmark mislabels indicates that the reported F1 may partly reflect label noise or distributional overlap with the 2,940 subcategories rather than genuine generalisation. No independent human re-annotation or out-of-distribution test set is described that would falsify this.
Authors: The adjudication protocol is described in the Results section and all adjudicated cases are listed in the appendix. We did not include an independent third-party re-annotation or a dedicated OOD test set in the submitted version. We will add both a small-scale independent re-annotation study and performance on a new OOD adversarial prompt set in the revision. revision: yes
-
Referee: [Abstract] Synthetic data generation description (Abstract): The constitution of 46 policies and 2,940 subcategories, combined with one-to-one counterfactual pairs and multilingual materialisation, creates a risk that evaluation benchmarks share structural artifacts or phrasing patterns; the manuscript provides no explicit check that the benchmarks are free of such overlap with the training corpus.
Authors: The submitted manuscript does not contain an explicit overlap analysis. We will add a new subsection reporting n-gram and semantic similarity statistics between the full synthetic training corpus and each of the seven benchmarks, confirming negligible overlap, in the revised version. revision: yes
Circularity Check
No circularity: empirical performance on external benchmarks with no self-referential derivation
full rationale
The paper presents an empirical model whose training corpus is organized by a fixed constitution (46 policies, 2940 subcategories) and whose performance is measured on seven separate prompt-safety benchmarks. No derivation chain, equation, or first-principles claim is offered that reduces by construction to the inputs; the reported F1, FPR, and FNR are direct measurements on held-out benchmarks rather than fitted quantities renamed as predictions. The note that most remaining misses are benchmark mislabels is an observation about label noise, not a self-definitional loop. No self-citation load-bearing step, uniqueness theorem, or ansatz smuggling appears in the provided text. The result is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
URL https://arxiv. org/abs/2212.08073. Matt Gardner, Yoav Artzi, Victoria Basmov, Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Yanai Elazar, Ananth Gottumukkala, Nitish Gupta, Hannaneh Hajishirzi, Gabriel Ilharco, Daniel Khashabi, Kevin Lin, Jiangming Liu, Nelson F. Liu, Phoebe Mulcaire, Qiang Ning, Sameer Singh, Noah A. Smith, Sanj...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
doi:10.18653/v1/2020.findings-emnlp.117
Association for Computational Linguistics. doi:10.18653/v1/2020.findings-emnlp.117. URLhttps://aclanthology.org/2020.findings-emnlp.117/. Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms,
-
[3]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
URL https://arxiv.org/abs/2406.18495. Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Merve Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: Llm-based input-output safeguard for human-ai conversations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
URLhttps://arxiv.org/abs/2312.06674. Divyansh Kaushik, Eduard Hovy, and Zachary C. Lipton. Learning the difference that makes a difference with counterfactually-augmented data. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2504.04377 , year=
URL https://arxiv.org/abs/ 2504.04377. Zi Lin, Zihan Wang, Yitao Tong, Yuhang Wang, Yuting Guo, Yujia Wang, and Jingbo Shang. Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation,
-
[6]
URLhttps://arxiv.org/abs/ 2310.17389. Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,
-
[7]
URLhttps://arxiv.org/abs/2402.04249. NVIDIA. Nemo guardrails and nemotron content safety dataset,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Red Teaming Language Models with Language Models
URL https://arxiv.org/abs/ 2202.03286. Qwen Team. Qwen3guard technical report,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URLhttps://arxiv.org/abs/2510.14276. 27 HaloGuard 1.0: Open Weights Constitutional ClassifierA PREPRINT Paul Röttger, Hannah Rose Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https://arxiv.org/ abs/2308.01263. Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, Amanda Askell, Nathan Bailey, Joe Benton, Emma Bluemke, Samuel R. Bowman, Eric Christiansen, Hoagy Cunningham, Andy Dau, Anjali Gopal, Rob Gilson, Logan Graham, Logan Howard, Nimit Kalra, Tae...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URL https://arxiv.org/ abs/2501.18837. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https://arxiv.org/abs/ 2212.10560. Wenjun Zeng, Yuchi Liu, Ryan Mullins, Ludovic Peran, Joe Fernandez, Hamza Harkous, Karthik Narasimhan, Drew Proud, Piyush Kumar, Bhaktipriya Radharapu, Olivia Sturman, and Oscar Wahltinez. Shieldgemma: Generative ai content moderation based on gemma,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
ShieldGemma: Generative AI Content Moderation Based on Gemma
URLhttps://arxiv.org/abs/2407.21772. A Example constitution Harmless boundary Harmful constitution Shared harmless • Explaining chemistry education and laboratory safety • Discussing OPCW treaties and chemical-weapons history • Describing public-health, epidemiology, and biosafety concepts • Explaining nuclear physics, reactor safety, and radiation medici...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.