Correcting Visual Blur Induced by Attention Distraction to Reduce Hallucinations: Algorithm and Theory
Pith reviewed 2026-06-30 13:04 UTC · model grok-4.3
The pith
Object hallucinations in multimodal models arise from attention distraction shown as spatial inconsistency across heads and temporal fading on image tokens, which AFIP corrects at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
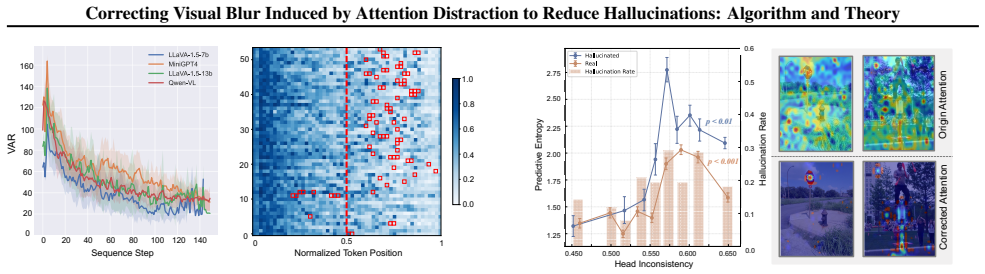
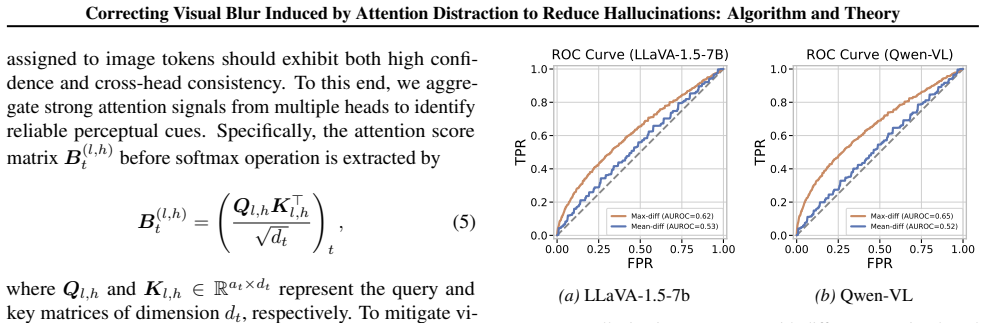
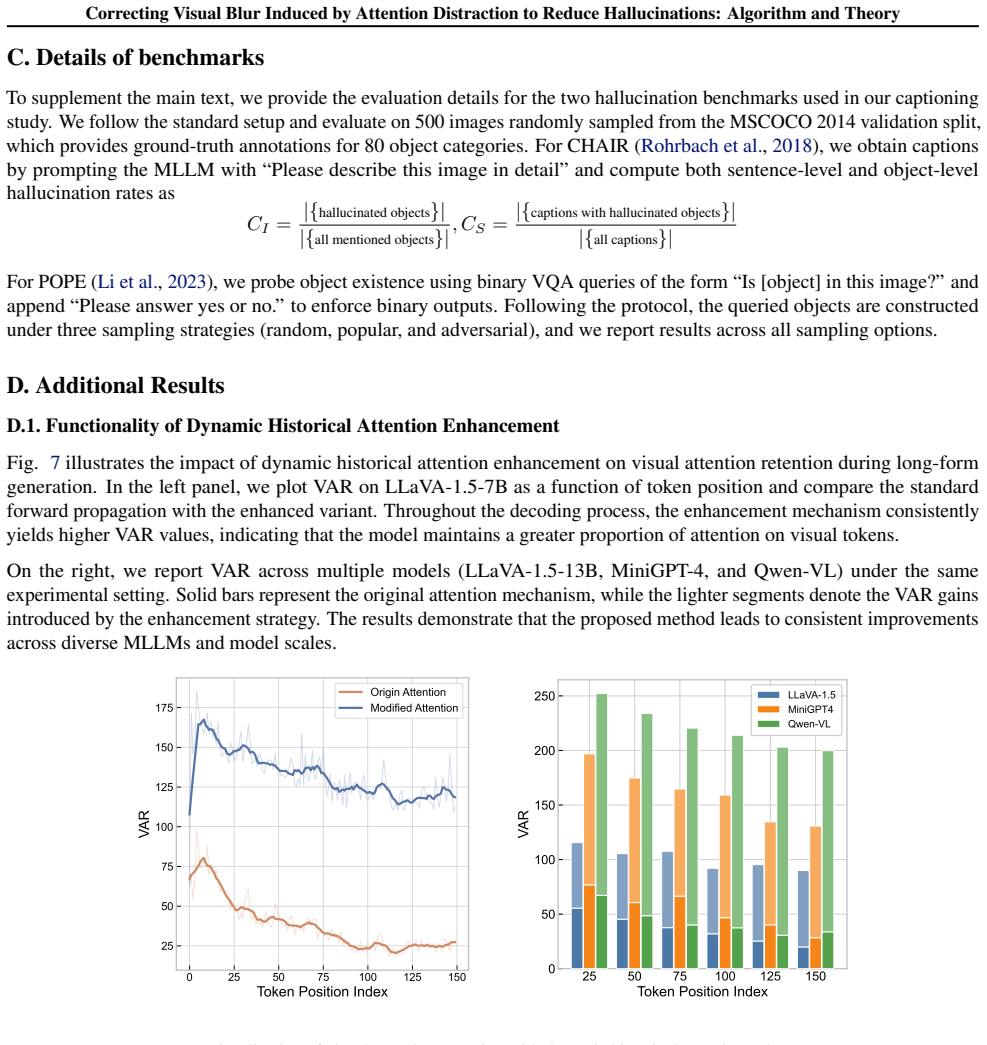
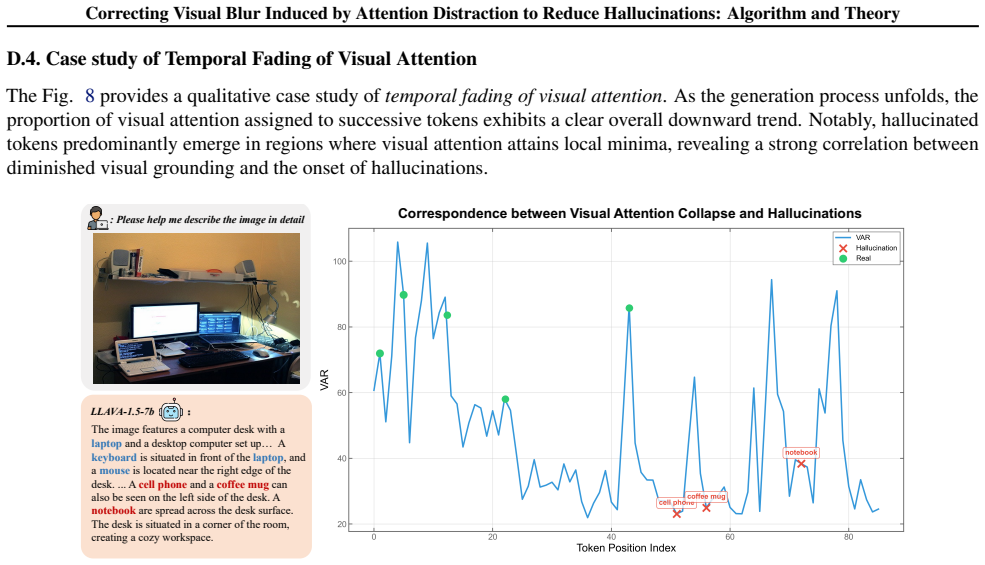
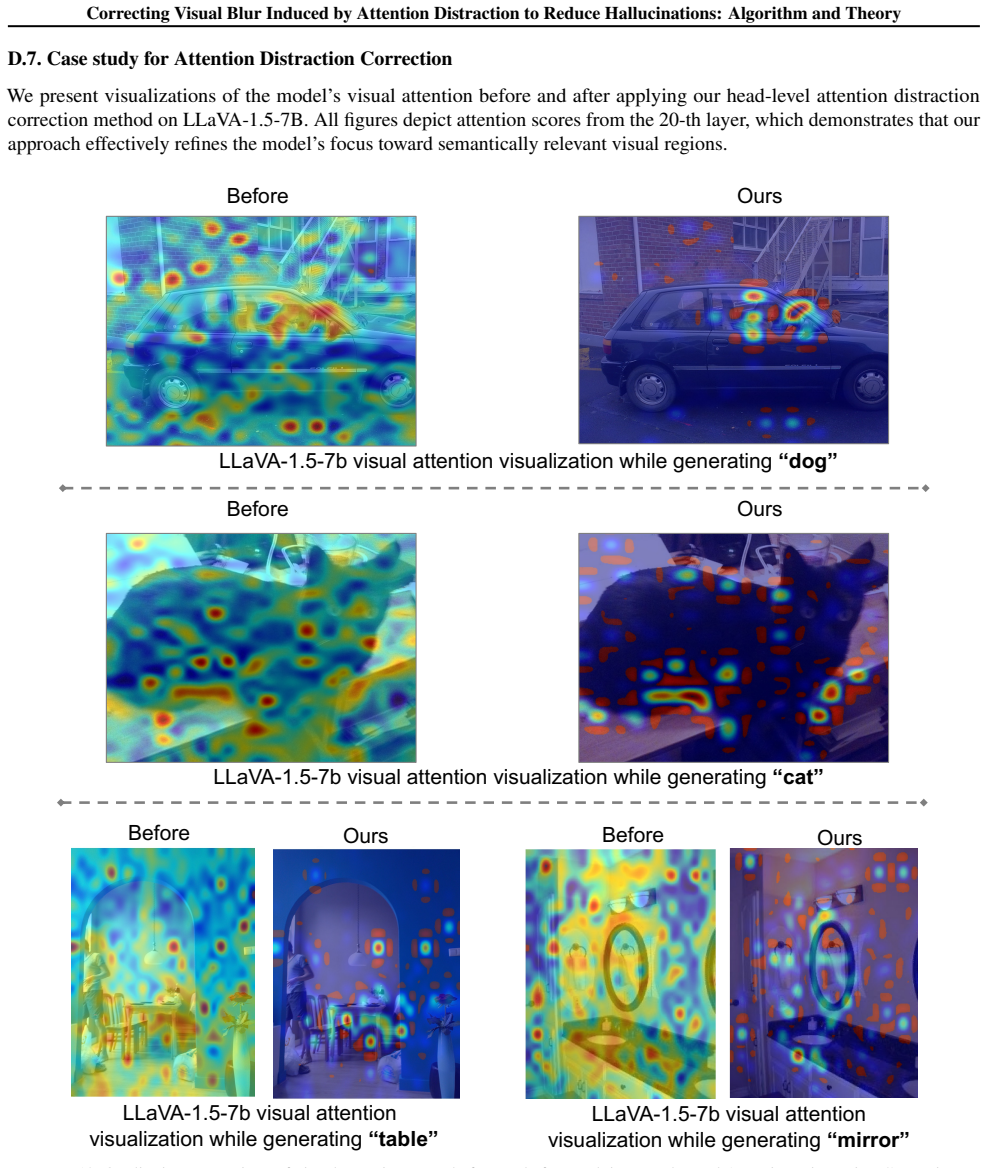
Hallucinations are strongly associated with attention distraction manifested as spatial inconsistency in multi-head attention and temporal fading of attention to image tokens during decoding. Attention dispersion increases model complexity and degrades classification generalization. AFIP corrects this distraction via cross-head attention enrichment and dynamic historical attention enhancement, improving visual perception at inference time without additional training.
What carries the argument
Attention-Focused Approach for Improved Image Perception (AFIP), which corrects attention distraction through cross-head attention enrichment and dynamic historical attention enhancement.
If this is right
- Correcting attention distraction at inference time reduces object hallucinations on multiple benchmarks and models without retraining.
- Enriching cross-head attention improves spatial consistency and visual grounding.
- Dynamic historical attention enhancement counters temporal fading of focus on image tokens.
- Attention dispersion raises model complexity and lowers generalization performance on classification tasks.
Where Pith is reading between the lines
- If attention distraction proves causal, monitoring attention metrics during decoding could serve as an early detector for hallucination risk.
- The method's success at inference time suggests similar attention-modulation interventions could address other perceptual failures in multimodal models.
- The parallel drawn to human divided attention may encourage experiments that test whether human-like perceptual interventions transfer to model behavior.
Load-bearing premise
The observed patterns of attention distraction are the direct cause of hallucinations rather than a correlated symptom, and fixing them at inference time will reduce hallucinations in untested settings.
What would settle it
A controlled test in which attention distraction is induced while measuring whether hallucination rates rise, or in which distraction is prevented while checking whether hallucinations remain unchanged.
Figures











read the original abstract
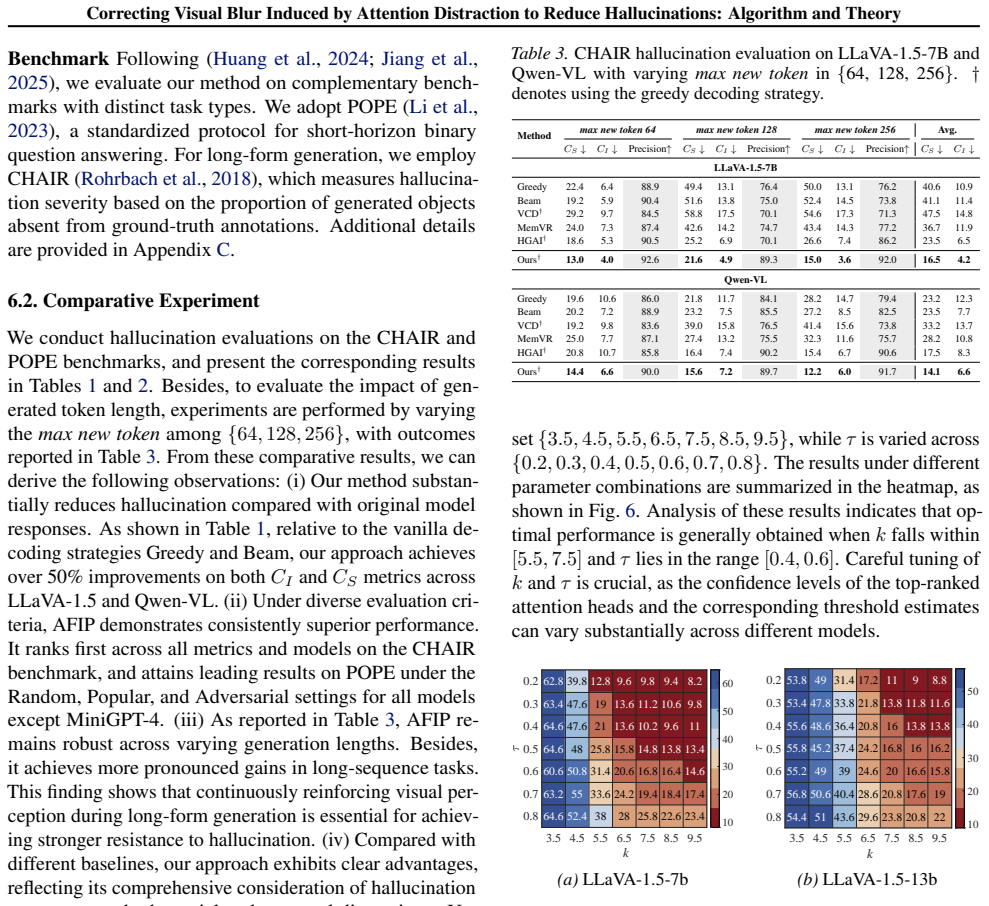
Multimodal large language models (MLLMs) frequently suffer from object hallucinations, yet the visual perceptual mechanism underlying this failure remains poorly understood. In this work, we reveal that hallucinations are strongly associated with a human-like attention distraction phenomenon, where humans under divided focus experience degraded visual clarity and produce inaccurate descriptions, while in models the same mechanism manifests as spatial inconsistency in multi-head attention and temporal fading of attention to image tokens during decoding. We further provide theoretical insights that attention dispersion increases model complexity and degrades classification generalization. Motivated by these findings, we propose an Attention-Focused Approach for Improved Image Perception (AFIP), which corrects attention distraction via cross-head attention enrichment and reinforces visual grounding through dynamic historical attention enhancement. Extensive experiments on multiple benchmarks and models validate the effectiveness of AFIP without additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that object hallucinations in multimodal LLMs arise from an attention distraction mechanism analogous to human visual blur under divided focus, manifesting as spatial inconsistency across multi-head attention maps and temporal decay of attention to image tokens during decoding. It supplies a theoretical argument that attention dispersion increases model complexity and harms generalization, and introduces the training-free AFIP method that applies cross-head attention enrichment plus dynamic historical attention boosting to restore focused visual grounding, with empirical validation across benchmarks and models.
Significance. If the proposed causal link holds and the interventions act specifically by restoring the identified attention statistics, the work would supply a lightweight, inference-only technique for improving visual grounding in MLLMs. The theoretical component on dispersion and complexity would be a useful contribution if it yields a concrete, testable relation between attention statistics and hallucination rates.
major comments (2)
- [§4] §4 (Theory): the argument that attention dispersion increases complexity and degrades generalization is stated as supporting the hallucination-reduction claim, yet no explicit derivation, bound, or equation is supplied that connects the dispersion metric to either complexity or to object-level hallucination rates; without this link the theory does not establish that correcting the two attention statistics will causally reduce hallucinations.
- [§5] §5 (Experiments): the reported gains from AFIP are consistent with association but do not include an interventional control (e.g., random perturbation of the same attention statistics or a counterfactual attention map) that would isolate whether the reduction in hallucinations is produced by restoring spatial consistency and temporal persistence rather than by incidental side-effects of the enrichment operations.
minor comments (1)
- [Abstract] The abstract and introduction use “strongly associated” and “manifests as” interchangeably with causal language; a single clarifying sentence distinguishing correlation from the claimed mechanism would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical linkage and experimental controls. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Theory): the argument that attention dispersion increases complexity and degrades generalization is stated as supporting the hallucination-reduction claim, yet no explicit derivation, bound, or equation is supplied that connects the dispersion metric to either complexity or to object-level hallucination rates; without this link the theory does not establish that correcting the two attention statistics will causally reduce hallucinations.
Authors: We agree that an explicit derivation would strengthen the claim. The manuscript currently offers high-level insights linking dispersion to complexity and generalization; in revision we will add a formal connection, e.g., by expressing dispersion via attention entropy and deriving a PAC-style generalization bound that also correlates with object hallucination rates. revision: yes
-
Referee: [§5] §5 (Experiments): the reported gains from AFIP are consistent with association but do not include an interventional control (e.g., random perturbation of the same attention statistics or a counterfactual attention map) that would isolate whether the reduction in hallucinations is produced by restoring spatial consistency and temporal persistence rather than by incidental side-effects of the enrichment operations.
Authors: We acknowledge the value of stronger causal isolation. While current results show consistent gains, we will add an interventional ablation in the revision that applies controlled random perturbations to the same attention statistics and compares hallucination outcomes, thereby testing whether restoration of the identified statistics is the operative mechanism. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained
full rationale
The abstract and description present an observational association between attention distraction patterns and hallucinations, followed by independent theoretical claims about dispersion increasing complexity, then a motivated algorithmic intervention. No equations, fitted parameters renamed as predictions, or self-citations are exhibited that reduce the central claims to their own inputs by construction. The proposed AFIP method is described as correcting observed patterns without evidence that its justification loops back definitionally to the same attention maps used to define the problem. This is the common case of a paper whose core argument does not collapse into tautology or self-referential fitting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023a. Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., and Zhou, J. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J
URL https://arxiv.org/ abs/2110.01705. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. NIPS,
-
[4]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., and Zhao, R. Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Halc: Object hallucination reduction via adaptive focal-contrast decoding, 2024
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, pp. 24185– 24198, 2024a. Chen, Z., Zhao, Z., Luo, H., Yao, H., Li, B., and Zhou, J. Halc: Object hallucination reduction via adaptive focal- contrast d...
- [6]
-
[7]
Medgpt: Medical concept prediction from clinical narratives.arXiv preprint arXiv:2107.03134,
Kraljevic, Z., Shek, A., Bean, D., Bendayan, R., Teo, J., and Dobson, R. Medgpt: Medical concept prediction from clinical narratives.arXiv preprint arXiv:2107.03134,
-
[8]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Li, F., Zhang, R., Zhang, H., Zhang, Y ., Li, B., Li, W., Ma, Z., and Li, C. Llava-next-interleave: Tackling multi- image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Evaluating Object Hallucination in Large Vision-Language Models
Li, Y ., Du, Y ., Zhou, K., Wang, J., Zhao, W. X., and Wen, J.-R. Evaluating object hallucination in large vision- language models.arXiv preprint arXiv:2305.10355,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y ., and Wang, L. Mitigating hallucination in large multi-modal models via robust instruction tuning.arXiv preprint arXiv:2306.14565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Docllm: A layout-aware generative language model for multimodal document understanding
Wang, D., Raman, N., Sibue, M., Ma, Z., Babkin, P., Kaur, S., Pei, Y ., Nourbakhsh, A., and Liu, X. Docllm: A layout-aware generative language model for multimodal document understanding. InACL, 2024a. Wang, J., Zhou, Y ., Xu, G., Shi, P., Zhao, C., Xu, H., Ye, Q., Yan, M., Zhang, J., Zhu, J., et al. Evaluation and analysis of hallucination in large visio...
-
[12]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024b. Wen, W., Gong, T., Dong, Y ., Yu, S., and Zhang, W. Towards the generalization of multi-view learn- ing: An information-theoretical...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Wu, J., Liu, Q., Wang, D., Zhang, J., Wu, S., Wang, L., and Tan, T. Logical closed loop: Uncovering object hallucinations in large vision-language models.arXiv preprint arXiv:2402.11622,
-
[14]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, B., Niu, Y ., Lee, S., Hur, M., and Zhang, H. Debi- ased fine-tuning for vision-language models by prompt regularization. InAAAI, 2023a. Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023b. Zou, X., Wang, Y ., Yan, Y ., Lyu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
nX i=1 ∥vi∥2 # 1 2 ≤
12 Correcting Visual Blur Induced by Attention Distraction to Reduce Hallucinations: Algorithm and Theory A. Proof of The Theorem 5.1 We begin the proof of Theorem 5.1 by introducing the following lemmas: Lemma A.1((Edelman et al., 2022)).For vectorsθ 1, θ2 ∈R p, we have ∥softmax (θ1)−softmax (θ 2)∥1 ≤2∥θ 1 −θ 2∥∞ .(15) Lemma A.2((Lust-Piquard & Pisier, 1...
2022
-
[16]
Please describe this image in detail
Then, for any ϵ >0 , the following inequality holds: P kX i=1 ¯ai pi − Xi m > ϵ ! ≤exp − mϵ2 β , whereβ= 2 Pk i=1 ¯a2 i pi. Lemma B.2.For anyy∈ Y, if the loss functionl(·, y)isL l-Lipschitz, the following inequality exists: |l(u, y)−l(v, y)| ≤L l∥u−v∥ 2,∀u, v∈R.(41) Lemma B.3.If the functionψisL l-Lipschitz, with respect to the Euclidean norm∥ · ∥ 2, the ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.